[DL4CV] Neural Network Fundamentals

Deep Learning에 대해 본격적으로 공부를 시작할 때 읽었던 책의 내용을 요약하였다.
<책 정보>

제목: Deep Learning for Computer Vision with Python
출간일자: 2018
저자: Dr.Adrian Rosebrock
출판사: pyimagesearch
Neural Network Basics
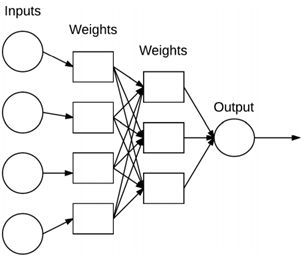
위 그림은 본격적인 내용을 서술하기에 앞서 대략적인 구조를 소개하고 넘어가고자 첨부하였다. 매우 단순화된 신경망 구조다. 입력 내용이 네트워크에 표시되고, 각각의 커넥션들은 네트워크의 두 히든 레이어를 통해 신호를 전송하게 돼서 최종 함수는 출력 클래스라벨을 계산하게 되는 구조이다.
Introduction to Neural Networks
[Artificial Neural Network]
딥러닝에 쓰이는 인공 신경망은 무엇일까. 인공 신경망은 인간의 신경계의 신경 연결에서 영감을 받아 비롯된 연산 시스템이다. ANN이나 NN이라는 약어를 사용한다. 어떠한 시스템이 NN으로 간주되려면 위의 그림처럼 각 노드가 라벨로 향하는 방향 그래프 구조여야 한다. 각 노드가 간단한 계산을 수행해서 한 노드에서 다른 노드로 시그널을 전달하게 되는데, 이 과정에서 시그널의 증폭 또는 감소 정도를 나타내는 가중치로 라벨링된다.
주목하고 넘어가야 할 점이 하나 있는데, 신경계에서 시그널의 전달은 2진법에 의해 이루어진다. 즉, 일정 임계치를 넘으면 그 수치가 구체적으로 무엇이든 상관없이 다음 대상으로 시그널을 전달하게 된다.
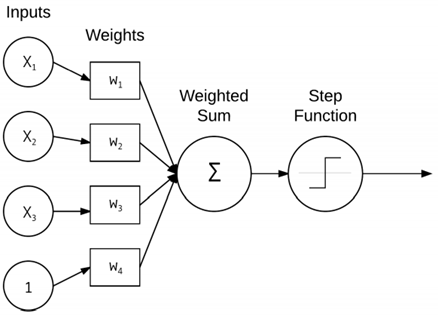
입력에 대한 간단한 가중치 합을 수행하는 기본 NN에 대한 구조이다. 3개의 x값은 영상의 raw pixel 강도에 대한 input data들이고, 상수 1은 지난 포스트에서 언급한 바이어스 트릭에 의한 상수값이다. 각 x는 관련 가중치 w를 갖게 되고, 출력 노드에서 취해지는 가중치 합이 적용되는 활성화 함수에 의하여 앞서 말씀드린 대로 이진법에서 0이 될지 1이 될지의 기준이 되어 다음 단계로의 값의 전달 여부를 결정하게 된다.
[Activation Functions]
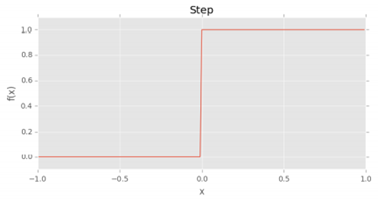
가장 간단한 활성화 함수는 퍼셉트론 알고리즘에 의해 사용되는 스텝 함수이다. 가중치 합계가 0보다 크면 1을 출력하고 그 외의 경우 0을 출력하게 된다. x축을 따라 입력값을 표시하고, y축을 따라 출력을 표시한 결과이다. 굉장히 직관적이라 사용하기엔 쉽지만 출력값이 0또는 1뿐이라 트레인 시키고자 하는 네트워크에 경사 하강을 적용했을 때 문제가 발생할 수 있다.
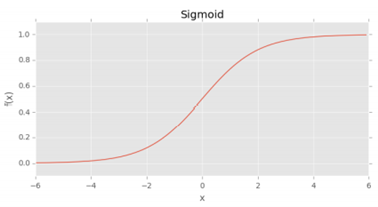
그래서 이전 포스트에 언급했듯, 일반적인 활성화 함수로 시그모이드 함수를 사용한다. S자 모양으로 이루어져 있어 학습 알고리즘을 쉽게 고안해낼 수 있지만 출력이 0 중심이 아니라는 점, 무엇보다 좌우로 접선의 기울기가 0이 되는 지점에 의해 후에 소개할 backpropagation 알고리즘으로 편미분을 할 때, 가중치 업데이트가 없어지는 saturation 현상이 발생한다는 치명적인 단점이 있다.
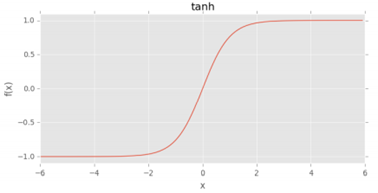
그래서 고안된 탄젠트 함수는 결과값이 0 중심이긴 하지만 마찬가지로 saturation 현상이 발생해 도입된 것이 ReLU(Rectified Linear Unit)이다.
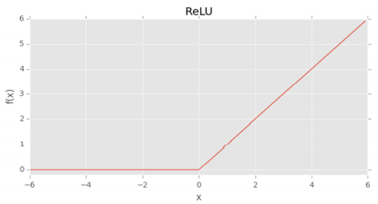
음의 입력에 대해서는 0이지만 양의 값에 대해서는 선형적으로 증가하는 모양을 가진다. ReLU는 딥러닝에서 사용되는 인기 있는 활성화 함수이지만, 값이 0일 때 gradient를 측정할 수 없다는 단점이 있어 이를 변형시킨 함수가 등장하게 된다.
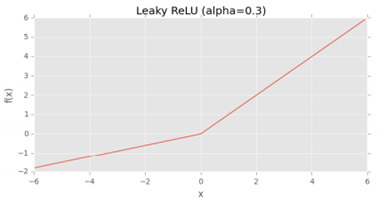
Leaky ReLU 함수는 음의 입력값들에 0이 아닌 작은 gradient를 허용한다.
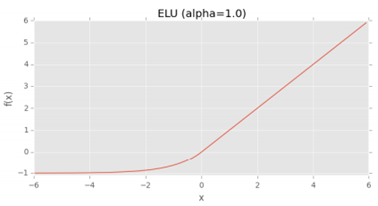
마지막으로 ELU(Exponential Linear Unit_지수 선형 단위) 함수이다. 보통 알파는 1로 설정하고, 표준 ReLU 함수보다 성능이 나쁜 경우는 거의 없다고 한다.
[Feedforward Network Architectures]
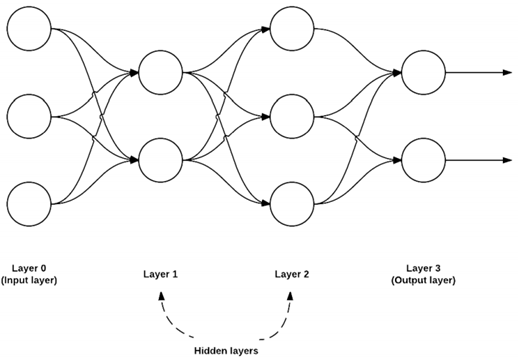
다음으로 넘어가, 구조에 관한 이야기이다. 여러 NN 구조가 있지만 가장 일반적인 구조는 피드포워드 네트워크입니다. 피드포워드라는 용어에서 유추할 수 있듯, 역방향이나 계층간 연결은 안되며 i번째 레이어의 노드에서 i+1번째 레이어의 노드간의 연결만 가능하다.
The Perceptron Algorithm
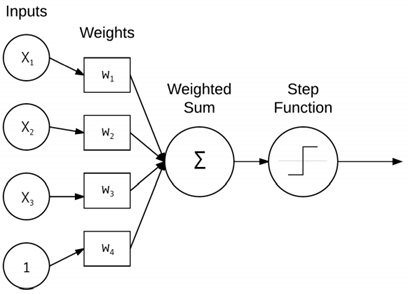
지금까지 NN의 기본적인 요소들에 대해 소개했고, 다음으로 소개할 내용은 Perceptron 알고리즘이다. 결론부터 말하자면, 퍼셉트론 알고리즘은 비선형인 XOR 데이터를 분류하지 못한다. 그럼에도 이 알고리즘은 딥러닝을 알아가는 입장에서 중요하기 때문에 빼놓지 않고 공부하면 좋다. 위의 그림은 퍼셉트론 구조에 대한 그림이다. 앞서 첨부한 그림과 같은데, 피처 벡터의 라벨링된 예(지도 학습)를 사용해서 입력을 해당 출력 클래스라벨에 매핑하는 시스템으로 정의된다. 가중치 합에 step 함수를 적용시켜 0또는 1을 출력하게 된다.
[Perceptron algorithm training procedure]
구현 목표는 트레이닝 셋의 인스턴스를 정확하게 분류하는 w 집합을 얻는 것이다. 그래서 퍼셉트론을 훈련시키기 위해 epoch 값을 이용해 반복적으로 트레인 셋을 모델에 제공한다. 이후 내적을 통해 출력값을 구한 다음 w를 업데이트하면서 올바른 분류에 근접할 수 있도록 한다. 하지만 앞서 말했듯, XOR 함수에 대해 비선형으로 올바르게 모델링할 수 없다. 그래서 딥러닝에서는 비선형 활성화 함수가 있는 더 많은 레이어를 필요로 하게 된다. 그래서 지금부터 소개할 내용은 backpropagation(역전파)와 multi-layer network이다. backpropagation 알고리즘은 두 단계로 구성되는데, 바로 이어서 자세히 짚어보겠다.
Backpropagation and Multi-layer Networks
[Forward Pass]
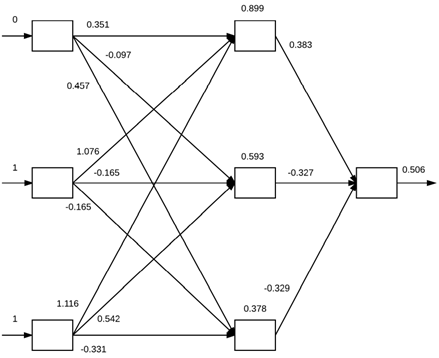
포워드 패스의 목적은 출력 계층에 도달할 때까지 내적과 활성화를 이용해 입력 정보를 전달하는 것이다. XOR 데이터셋으로 예를 들어보겠다. 각 데이터 포인트는 2차원으로 표시된다. 높은 분류 정확도를 얻기 위해선 피드포워드 신경망이 필요로 해서 2-2-1 구조를 갖게 되지만 바이어스 트릭도 적용시킬 것이기 때문에 실제로는 3-3-1 구조라고 볼 수 있다. 그래서 위의 그림처럼 포워드 패스는 가중치를 0 1 1로 초기화하고, 백프로포션 단계를 거치며 소수자리까지 표기된 것처럼 가중치는 업데이트된다. 내적한 값들을 시그노이드 활성화 함수에 적용해 0.506는 최종적으로 1의 결과값을 가짐을 알 수 있다. 하지만 0.506은 임계치와 매우 가까운 결과로, 이상적인 예측인 0.9 이상의 값을 얻으려면 백워드 패스를 적용해야 한다.
[Backward Pass]
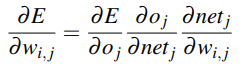
백워드 패스 알고리즘을 적용하려면, 주어진 가중치 w와 loss, 노드 출력 결과 o와 네트워크 출력 결과 net과 관련된 오류 편미분을 계산할 수 있도록 활성화 함수가 서로 달라야 한다. 첫 단계로, 예측한 라벨과 그라운드 트루스 라벨의 차이를 계산한다. 다음으로 알파에 따라 조정되는 가중치 매트릭스를 갱신하는 데 사용되는 델타 리스트를 만들기 위해 체인 룰을 적용한다. 이러한 방법으로 역방향으로 반복적인 작업을 거쳐 가중치를 업데이트하게 되면 최적의 gradient를 도출할 수 있게 된다.
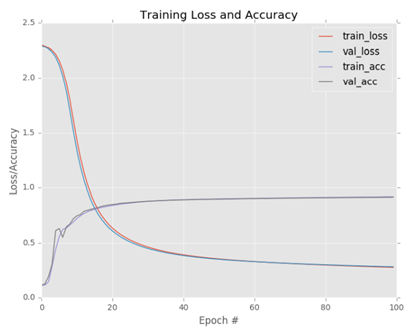
Keras와 같은 전용 신경망 라이브러리를 사용하여 결과를 구해보면 92%의 정확도를 얻고 있음을 확인할 수 있다. 또한, 트레인 및 테스트 곡선은 거의 일치하며 트레인 과정에 오버핏과 같은 문제가 없음을 확인할 수 있다.
