[DL4CV] Optimization Methods and Regularization

Deep Learning에 대해 본격적으로 공부를 시작할 때 읽었던 책의 내용을 요약하였다.
<책 정보>

제목: Deep Learning for Computer Vision with Python
출간일자: 2018
저자: Dr.Adrian Rosebrock
출판사: pyimagesearch
Gradient Descent
The Loss Landscape and Optimization Surface
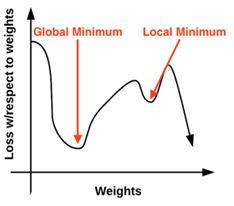
경사하강법은 loss landscape에서 작동하는 반복적인 최적화 알고리즘이다. 위의 그래프를 보면 X축을 따라 가중치가, Y축을 따라 지정된 가중치 set의 loss가 시각화되었음을 볼 수 있다. Loss landscape는 굉장히 굴곡진 모양을 보이는데, 여기서 가장 큰 손실이 발생한 로컬 최대치는 글로벌 최대치이며 반대로, 가장 작은 손실을 갖는 로컬 최소치는 글로벌 최소치가 된다. Land scape는 다차원에 존재하기 때문에, W와 b에 계속 다른 값들을 넣어보면서 loss를 평가하고 최적의 값을 얻어내야 한다.
The "Gradient" in Gradient Descent

W와 b를 가지고는 로스 함수 L만을 계산할 수 있어서 상대적 위치만 계산할 수 있고 방향에 대해서는 값을 낼 수가 없다. 그래서 이때 경사 하강을 적용해야 한다. 위의 공식을 사용하면 모든 차원에서 사용하는 경사도 W를 구할 수 있다.
The Bias Trick
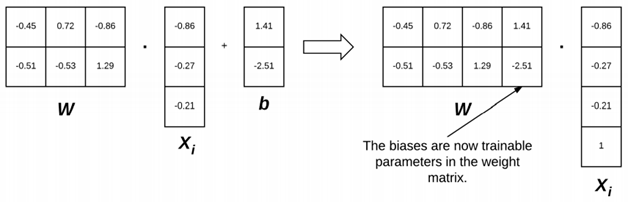
경사 하강에 대해 본격적으로 파고들기에 앞서 가중치 매트릭스 W와 바이어스 벡터 b를 단일 파라미터로 결합하는 방법인 바이어스 트릭에 대해 소개하겠다. 이전 포스트에서 언급한 스코어링 함수를 다시 상기시켜보면, W와 b를 하나로 결합하기 위해 입력 데이터 X에 바이어스 차원에 해당하는 열을 추가한다. 이를 의미하는 그림은 위와 같다. 별도의 파라미터로 취급되던 W와 b였는데 b가 W 매트릭스에 내장되면서 그림이 오른쪽처럼 바뀌었음을 확인할 수 있다. 바이어스 트릭을 적용하면 가중치 매트릭스만 학습하면 되기 때문에 이 같은 방법이 선호된다.
Implementing Basic Gradient Descent in Python
(코드는 저작권 문제 상 기재하지 않음)
활성화 함수로 시그모이드를 정의한다. 이후 predict 함수에서 시그모이드 함수 출력값에 따라 0 또는 1을 반환한다. make_blobs 함수를 호출해 두 클래스로 구분된 1000개의 데이터포인트를 생성하고 바이어스 트릭을 적용시켜 train_test_split을 사용해 데이터를 train용과 test용으로 분할한다. 커맨드라인으로 받아온 epoch만큼 for을 반복하여 train set과 W를 내적해 loss 값을 구한다. Loss를 구하면 gradient를 계산하고 W를 업데이트할 수 있게 되는데, loss와 예측 값에 대한 시그모이드 파생 모델을 곱하고 이를 train set과 내적해서 gradient를 구한다. 경사 하강은 횟수를 만족시킬 때까지 반복한다.
Simple Gradient Descent Results
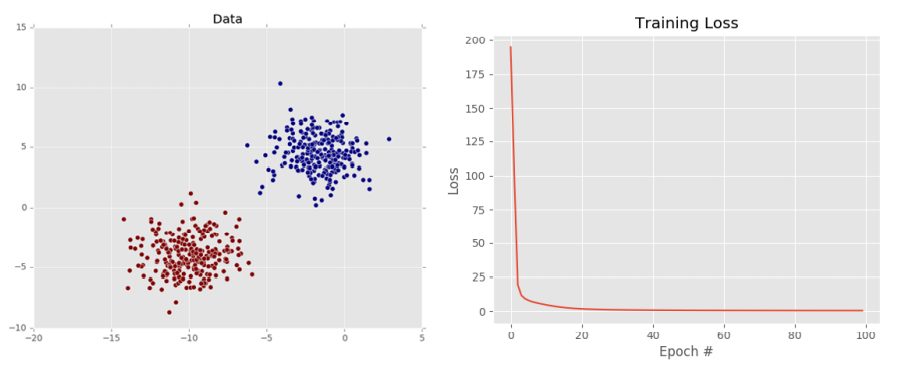
왼쪽의 도표에서 확인할 수 있듯, 데이터셋을 두 개의 클래스로 나누는 선을 그릴 수 있기 때문에 선형적으로 데이터를 분리할 수 있다고 볼 수 있다. 또한 오른쪽 그래프에서는 처음엔 loss가 높지만 100번째 train에선 0.045로 낮은 loss를 가짐을 확인할 수 있다. 즉, 위의 그림을 통해 분류기가 train set에서 학습할 수 있도록 W가 업데이트되고 있음을 알 수 있다.
Stochastic Gradient Descent (SGD)
Mini-batch SGD
앞서 설명한 Python 코드는 바닐라 경사 하강 알고리즘인데, 이는 경사 하강을 반복할 때마다 W를 업데이트하기 전에 트레인 데이터의 각 트레인 포인트에 대한 예측값을 계산해야 해서 대규모 데이터셋에서 매우 느리게 실행된다. 그래서 next_training_batch 함수를 추가해서 SGD로 변환하도록 선언할 수 있다. 전체 데이터셋에서 gradient를 계산하는 대신 데이터를 샘플링해서 함께 처리하게 된다. 이때 새로운 파라미터인 batchsize를 볼 수 있는데, 일반적으로 batchsize는 32, 64, 128, 256을 사용한다. 이렇게 배치 사이즈가 1보다 크면 안정적인 수렴이 가능하고, 2의 n승 형태가 내부 선형대수 최적화 라이브러리를 더 효율적으로 사용할 수 있다.
Implementing Mini-batch SGD
(코드는 저작권 문제 상 기재하지 않음)
SGD를 코드로 구현해보면, 바닐라 경사 하강과 동일하게 우선 sigmoid_activation과 sigmoid_deriv, predict 함수를 정의한다. 그 다음 next_batch 함수를 추가하는데, 파라미터로는 데이터셋, 클래스 라벨, 배치사이즈를 필요로 한다. for문에서 train data들을 반복해서 X와 y의 부분 집합을 미니 배치로 만든다. 마찬가지로 앞 과정과 동일하게 make_blobs 함수 호출 후 tarin과 test 데이터로 분할한 다음, 가중치 매트릭스와 loss 리스트를 초기화한다. 다음으로 첫 번째 for문에서 epochs 수만큼 반복을 돌고, 이중으로 두 번째 for문을 또 돌리게 되는데, 각 배치에 대해 W와의 내적을 계산 한 다음 이를 sigmoid_activation 함수에 전달해서 예측값을 얻는다. 그런 다음 오차를 계산하고 이를 epochLoss에 추가한다. 앞선 방법과 동일하게 gradient를 계산한 후 W를 업데이트한다. 다만 차이가 있다면 에폭마다 여러 번의 업데이트가 있다는 점이다.
SGD Results
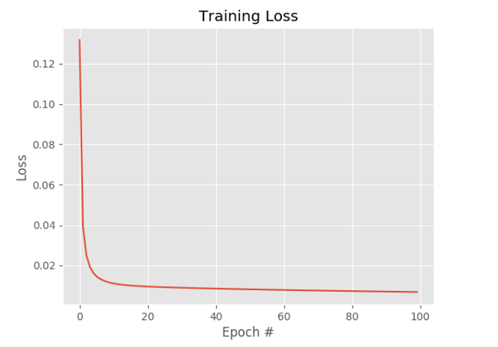
결과를 보면 100번째 훈련에 도달했을 때 앞선 바닐라 경사 하강 알고리즘으로는 0.447이였던 것에 반해 여기서는 0.006의 결과를 얻어냈기에 loss가 더 낮음을 알 수 있다. 이만큼의 차이는 에폭당 가중치 업데이트가 여러 번 있었기 때문에 W에 대한 업데이트를 통해 더 많은 정보를 얻을 수 있다.
Extensions to SGD
Momentum
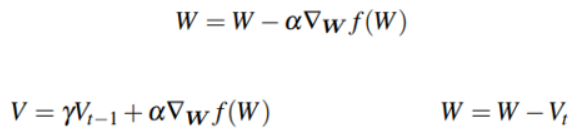
SGD에 대한 확장된 내용으로 두 가지가 있다. 첫 번째로 모멘텀, 즉 추진력이다. 모멘텀을 사용해 모델이 더 적은 시간 동안 더 낮은 loss를 얻을 수 있도록 한다. 그렇기에 이 모멘텀 텀은 동일한 방향의 gradient 포인트의 업데이트 정도는 증가시키고, 반대로 방향을 전환하는 gradient에 대해선 정도를 감소시켜야 한다. 위의 식처럼 이전의 가중치 업데이트에서는 그라데이션의 크기를 조정하는 것만 포함되었지만, 이제는 모멘텀 텀 V를 감마로 확장해 두 번째 줄과 같은 식으로 나타낸다. 일반적으로 감마는 0.9로 설정된다.
Nesterov’s Acceleration
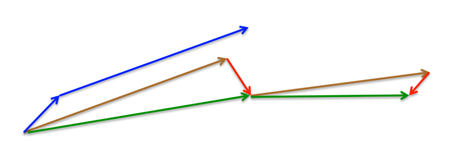
네스테로프 가속은 업데이트 후에 매개 변수가 어디에 배치될지 대략적으로 알 수 있도록 모멘텀에 대해 바로잡는 업데이트를 하는 것으로 정의내릴 수 있다. 그림을 보면, 표준 모멘텀을 사용해서 짧은 파란색 벡터인 그라디언트를 계산한 다음 큰 파란색 벡터에서 보이는 것처럼 그라디언트 방향으로 점프를 수행한다. 네스테로프 가속은 여기서 갈색으로 표시된 이전 그라디언트 벡터 방향으로 점프한 다음, 빨간색 벡터처럼 그라디언트를 측정한 후, 최종 보정 업데이트를 하는데 그것이 녹색 벡터다.
Regularization
What Is Regularization and Why Do We Need It?
정규화를 통해 모델이 트레인되지 않은 데이터 포인트를 더 잘 분류할 수 있도록 한다. 이를 일반화 능력이라고도 한다. 정규화를 적용하지 않으면 분류기가 너무 복잡하고 트레인 데이터에 오버핏될 수도 있지만, 너무 많은 정규화 또한 좋은 것은 아니다. 이때는 반대로 언더피팅의 위험성이 존재하게 된다.
Updating Our Loss and Weight Update To Include Regularization
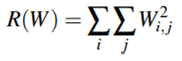
가중치 매트릭스에서 동작하는 정규화 패널티 함수를 정의해야 한다. 그와 관련된 수식은 위와 같다. weight decay라고도 불리는 L2 정규화에 대한 수식이다. 파이썬 코드로 보면, 행렬의 모든 항목에 제곱을 취해 이를 모두 더해주게 된다. L2 정규화 패널티에선 제곱 합을 사용하여 큰 가중치에 대해 패널티를 주게 되는데 이로 인해 오버피팅을 줄임으로써 일반화 능력이 향상된다. 실제로 정규화를 수행하면 트레인 정확도는 약간 떨어지지만 테스트 정확도는 향상된다고 한다.
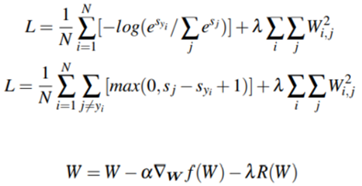
크로스 엔트로피 손실과 멀티 클래스 SVM 손실을 L2 정규화를 포함하도록 확장하면 위와 같은 수식들이 생성된다. 마지막 수식은 알파의 학습 속도로 곱한 그라디언트를 기준으로 업데이트한 가중치를 정규화하는 방정식이다.
Types of Regularization Techniques
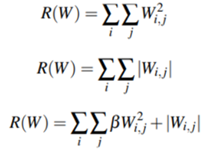
보통 세 가지의 정규화 유형이 있는데, 앞서 소개했듯 첫 번째 수식은 L2 정규화다. 두 번째 수식은 L1 정규화다. 여기서는 절대값을 다룬다. 마지막으로 Elastic Net 정규화는 L1과 L2 정규화를 모두 결합한 형태이다. 그래서 정규화를 해야 할 때 이를 하나의 하이퍼 파라미터라고 간주해서 어떤 방법을 선택할지 결정해야 한다.
