[DL4CV] Parameterized Learning

Deep Learning에 대해 본격적으로 공부를 시작할 때 읽었던 책의 내용을 요약하였다.
<책 정보>

제목: Deep Learning for Computer Vision with Python
출간일자: 2018
저자: Dr.Adrian Rosebrock
출판사: pyimagesearch
An Introduction to Linear Classification
Four Components of Parameterized Learning
Parameterization(매개변수화)은 주어진 모델의 필요한 매개변수를 정의하는 프로세스이다. 매개변수화는 4개의 주요 구성 요소로 문제를 정의하는 것을 포함한다.
-
Data
학습할 입력 데이터를 의미한다. 이 데이터에는 데이터 포인트, 즉 영상의 raw pixel 강도나 추출된 특징과 연관된 클래스 라벨이 모두 포함된다. 이 데이터를 다차원적 디자인 매트릭스로 나타낸다. 각 행은 데이터 포인트를 나타내고 각 열은 서로 다른 특징을 나타낸다. -
Scoring Function
데이터를 입력으로 받아들이고 데이터를 예측 클래스 라벨에 매핑한다. -
Loss Function
예측된 클래스 라벨이 실제 정답 라벨과 얼만큼 일치하는지를 정량화한다. 두 라벨 간의 일치율이 높을수록 손실을 감소시킬 수 있다. -
Weights and Biases
실제로 최적화할 분류기의 가중치 또는 파라미터를 의미한다. 스코어링 함수와 로스 함수의 결과에 기초해 분류 정확도를 높이기 위해 이 값들을 수정하게 된다.
Linear Classification: From Images to Labels
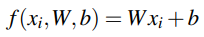
위에서 요약한 기본 구성 요소들이 선형 분류기에서 어떻게 작용하는지를 살펴보겠다. train dataset이 각 이미지에 연결된 클래스 라벨 yi가 있는 xi로 표시되어 있다고 가정해보겠다. 이러한 변수를 고려할 때, 선형 매핑을 사용한 함수 f는 위의 수식과 같다.
바로 이전 포스팅에서 언급한 Animals 데이터셋에 적용해보면 각 xi는 [3072 x 1] 모양의 픽셀값 리스트로 나타난다. RGB 이미지이기 때문에 W는 [3 x 3072]의 형태를 가지며, 바이어스 벡터 b는 [3 x 1]의 형태를 띈다. b는 W에 실제로 영향을 주진 않고 스코어링 함수의 방향을 전환 및 변환할 수 있게 해준다.
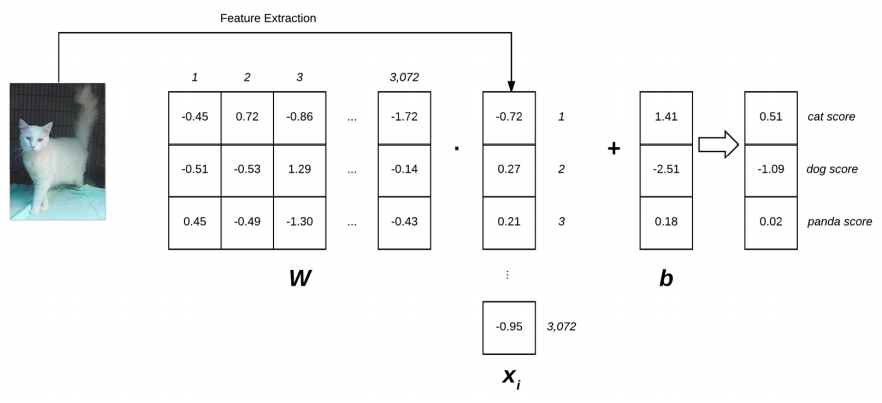
위 그림은 선형 분류 스코어링 함수 f를 나타낸다. 왼쪽에 32 x 32 x 3 형태의 입력 이미지가 있고, W는 3개의 행과 3072개의 열을 포함한다. W와 xi를 내적한 후 b를 더하여 개, 고양이, 팬더 라벨과 연관된 3가지 점수 값을 산출한다.
그림과 방정식을 보면 알 수 있듯, xi와 yi는 고정되어 있고 분류기에서 통제할 수 있는 유일한 매개변수는 W와 b이다. 따라서 이 2가지 변수를 최적화해야 한다.
Advantages of Parameterized Learning and Linear Classification
파라미터화 학습은 2가지 장점이 있다. 첫 번째는, 모델 훈련을 마치면 입력 데이터를 삭제하고 W와 b만 유지함으로써 모델의 크기를 크게 줄일 수 있게 된다는 점이다. 두 번째는, 새로운 테스트 데이터의 분류가 빠르다는 점이다. 분류를 수행하기 위해 스코어링 함수를 적용하게 되는데 이는 앞서 포스팅한 k-NN 알고리즘과 같이 모든 트레이닝 예들과 비교할 필요가 없기에 훨씬 빠르다.
A Simple Linear Classifier With Python
(코드는 저작권 문제 상 기재하지 않음)
먼저, Animals 데이터셋에 대한 클래스 라벨 리스트를 초기화하고 가중치 행렬과 바이어스 백터를 초기화한다. 다음으로 분류하고자 하는 이미지를 로드하고 전처리 과정을 거친 후 스코어링 함수를 적용해 출력 클래스 라벨 점수를 계산한다.
The Role of Loss Functions
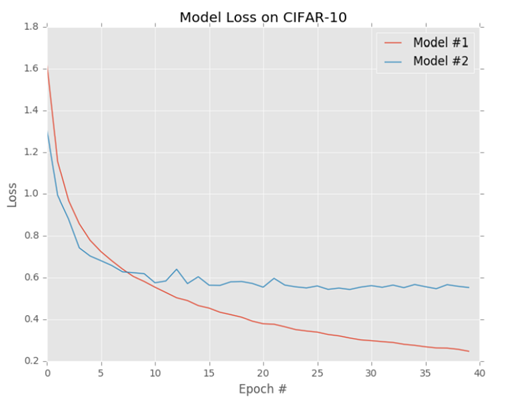
다음 내용으로 넘어와 로스 함수의 역할에 대해 알아보기에 앞서 로스 함수란 무엇인지에 대해 짚어볼 필요가 있다. 로스 함수는 주어진 예측 변수가 데이터셋의 입력 데이터 포인트를 분류할 때 얼마나 "좋은가" 또는 "나쁜가"를 정량화한다. CIFAR-10 데이터셋에 훈련된 두 개의 모델에 대해 시간에 따라 표시된 로스 함수의 값을 시각화한 결과는 위의 그림과 같다. 손실이 작을수록 분류기가 입력 데이터와 출력 클래스 라벨 사이의 관계를 모델링하는 것이 더 좋고, 반대로 손실이 클수록 분류 정확도를 높이기 위해 더 많은 작업을 수행해야 한다. 분류 정확도를 향상시키기 위해선 앞서 언급했듯 W 또는 b의 매개변수를 조정해야 한다. 위 예에서는 모델 #1이 시간이 지날수록 전반적인 손실을 줄이고 있기 때문에 CIFAR-10 데이터셋에서 다른 이미지를 분류하는 데 모델 #2보다 더 바람직하다고 볼 수 있다.
Cross-entropy Loss and Softmax Classifiers
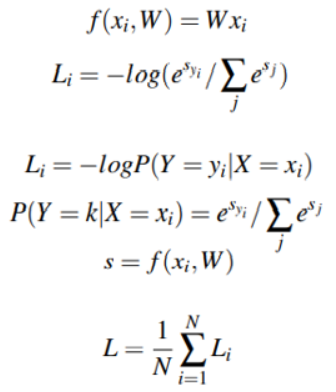
힌지 로스 함수도 매우 유명하지만, 딥러닝과 CNN에서는 크로스 엔트로피 로스와 소프트맥스 분류기가 훨씬 더 많이 사용된다. 그 이유는 소프트맥스 분류기가 각 클래스 라벨에 대한 확률을 알려주어 사람이 결과를 가지고 해석하기 더 용이하기 때문이라고 한다. 소프트맥스 분류기는 로지스틱 회귀의 이항 형태를 일반화하는 것이다. 매핑 함수 f는 데이터 xi의 입력 set을 가져와서 내적을 통해 출력 클래스 라벨에 매핑되도록 정의된다. 힌지 로스와 달리 점수를 각 클래스 라벨에 대한 비정규화된 로그 확률로 해석한다.
