KPMG Future Academy AI 활용 데이터 분석가 3기 13일차 수업을 2024년 12월 4일에 참석했다. 오전에는 프로젝트 관리 수업이 이어서 진행되었고 WBS 작성 등의 실습이 진행됐다. (병가)
오후에는 인공지능 개론 및 실습이 진행되었다.
- 인공지능 개론
1.1. 생성형 인공지능
1.2. Pre-trained
1. 인공지능 개론
1.1. 생성형 인공지능
기존 인공지능 : 예측과 분류에 초점을 둠
새로운 데이터를 생성하는 것에 초점을 둠
개발 문서 자동 생성으로도 많이 활용되고 있음
뤼튼 : 문서 작업 보조
viodio.io : AI가 만든 음원 (BGM)
copilot
클로바더빙
github copilot
novelAI
CAPTCHA캡차에 대한 개인적인 관심을 조사하였음.

패턴 인식 기능이란? (출처 : https://blog.naver.com/dbal12365/221832197184)
Pattern Recognition
(with Linear Discriminant Analysis)
다차원 공간 내에서 밀도함수를 추정하고 공간을 카테고리 혹은 클래스 영역으로 나누는 문제.
복잡한 신호의 몇 가지 표본과 이들에 대한 정확한 결정이 주어질 때, 연이어 주어지는 미래 표본들에 대하여 자동적으로 결정을 내리게 하는 것
측정의 설명 혹은 분류(인식)과 관련된 과학.
관측치 x에 이름 w를 부여하는 과정.
패턴인식은 다음 질문에 답하는 것이다. '이것이 무엇인가?'
특징 벡터(feature vector) - 인식률에 중요한 영향을 줌 : 특징이 하나 이상의 수치 값을 가질 경우, d-차원의 열 벡터로 표현.
특징 공간(feature space) : 특징 벡터가 정의되는 d-차원 공간.
분산 플롯 (scatter plot) : 인식 대상이 되는 객체들을 특징 공간에서 특징 벡터가 형성하는 점으로 표현된 그림.
오메가 : 라벨 혹은 클래스. 즉 x가 어떤 클래스에 속한다고 라벨까지 붙인 변수쌍.
패턴의 유형
- 선형 분리 가능한 유형 : 선형적으로 클래스들의 분류가 가능할 때
- 비선형 분리 가능한 유형 : 비선형적으로 클래스들의 분류가 가능할 때
- 높은 상관을 가진 유형 : 겹쳐있지는 않지만 관련도가 굉장히 높아 분표하는 것이 비슷할 때
- 멀티 모달 : 하나의 덩어리가 아닌, 다중으로 덩어리가 분표할 때
판별 분석 (Discriminant Analysis, DA)
출처 : https://syj9700.tistory.com/22
판별분석은 일종의 분류(classification)의 문제로, 두 개 또는 그 이상의 그룹(또는 군집 또는 모집단)이 사전에 알려져 있을 때, 새로운 관측값을 특성에 기초하여 이미 알려진 모집단 가운데 하나로 분류하는 기법. 1) 분류기(classifier)를 찾아 2) 새로운 관측값을 분류.
판별분석에서는 모집단에 대한 다변량 정규성, 그룹-내 공분산행렬의 동일성, 변수들 간의 낮은 다중공선성의 가정이 요구된다.
일반화(regularized) - 과적합(overfitting)을 방지하여 새로운 데이터셋에 대한 예측 성능 향상. 주로 머신러닝 모델의 일반화 성능을 개선하는 데 사용.
LDA와 QDA 간의 타협적인 방법으로 QDA의 구분된 공분산을 LDA의 공통인 공분산 쪽으로 축소(shrink)를 허용하는 것.
두 번째는 데이터의 중심 간에 최대의 분리가 일어나고 동시에 데이터의 각 그룹 내의 변동을 최소화하는 예측변수들의 선형결합(판별식)을 찾는 것이다. 이 방법은 Fisher가 제안한 그룹-내(within-class)공분산 대비 그룹-간(between-class) 공분산을 최대로 하는 예측변수들의 선형결합을 찾는 것과 동일하다.
주요 방법:
L1 규제(Lasso): 가중치의 절대값 합을 제한
L2 규제(Ridge): 가중치의 제곱합을 제한
드롭아웃(Dropout): 신경망에서 일부 뉴런을 무작위로 제거
일반화와 정규화 차이
일반화: 모델의 복잡성 제어 (학습 과정)
정규화: 데이터의 스케일 조정 (전처리 과정)
퍼지시스템
: 유전알고리즘과 FCM 기반 퍼지시스템
: 바이러스-진화 유전 알고리즘을 이용한 퍼지 모델링
1.2. Pre-trained
MLP(다층 퍼셉트론)에서 weight와 bias 잘 초기화 시키는 방법
매개변수를 pre-trained를 통해 정확도 개선
Transfer Learning : pre-training + Fine-tuning
Transformer
확률론으로 맥락을 처리.
시퀀스 투 시퀀스 방식.
SFT : Supervised Fine Tuning
설명 데이터를 수집, 지도 정책을 학습 -> 비교 데이터를 수집, 보상 모델을 학습 -> 강화학습을 사용하여 보상 모델(Reward Model, RM)에 대한 정책 최적화
정책 강화 모델 (Proximal Policy Optimization, PPO)를 통해 리워드 모델 정책 최적화
데이터 수집 전략
- 크라우드소싱 플랫폼 활용
- 합성 데이터 생성
- 전이 학습(Transfer Learning)
- 액티브 러닝(Active Learning)
기타 비공개 데이터 수집 방법
- OSINT(오픈 소스 인텔리전스, Open Source Intelligence) : 공개적으로 접근 가능한 정보를 수집하고 분석하여 정보를 얻는 과정.
- 공개된 메타데이터 분석.
- 데이터 마스킹 및 암호화 기술 적용.
- 차등 정보보호(Differential Privacy) 기법 : 차등 프라이버시는 인공지능 학습용 데이터에 포함된 개인정보를 보호하기 위해 해당 데이터세트(data set)에 임의의 노이즈(noise)를 삽입함으로써 개인정보가 제3자에게 노출되지 않도록 보호하는 기법.
기계학습 기반 데이터 선별
- 자동 데이터 분류 알고리즘
- 데이터 클러스터링
- 앙상블 학습 기법
- 메타 러닝(Meta-Learning) : 1) 예시 1 - 딥러닝을 하다보면 Learning rate를 조절하면서 Loss가 떨어지는 것을 비교하는 경우가 있으며 이 경우도 Meta Learning에 해당. 이는 모델을 훈련하는 learning보다 한 단계 위인, Hyperparameter에 대해서 적합한 값을 찾는 Learning을 진행하는 과정. 2) 예시 2 - Model을 Ensemble. 이미 learning이 된 모델들을 가지고, 모델들의 예측을 기반으로 결정하는 새로운 모델을 Stacking으로 학습시킨다면, 1차적인 학습을 넘어서 학습을 진행하기 때문에 Meta-Learning에 해당.
(출처 : https://jrc-park.tistory.com/257)
Llama3 사용 실습
transformers 설치
pytorch 설치
huggingface 로그인

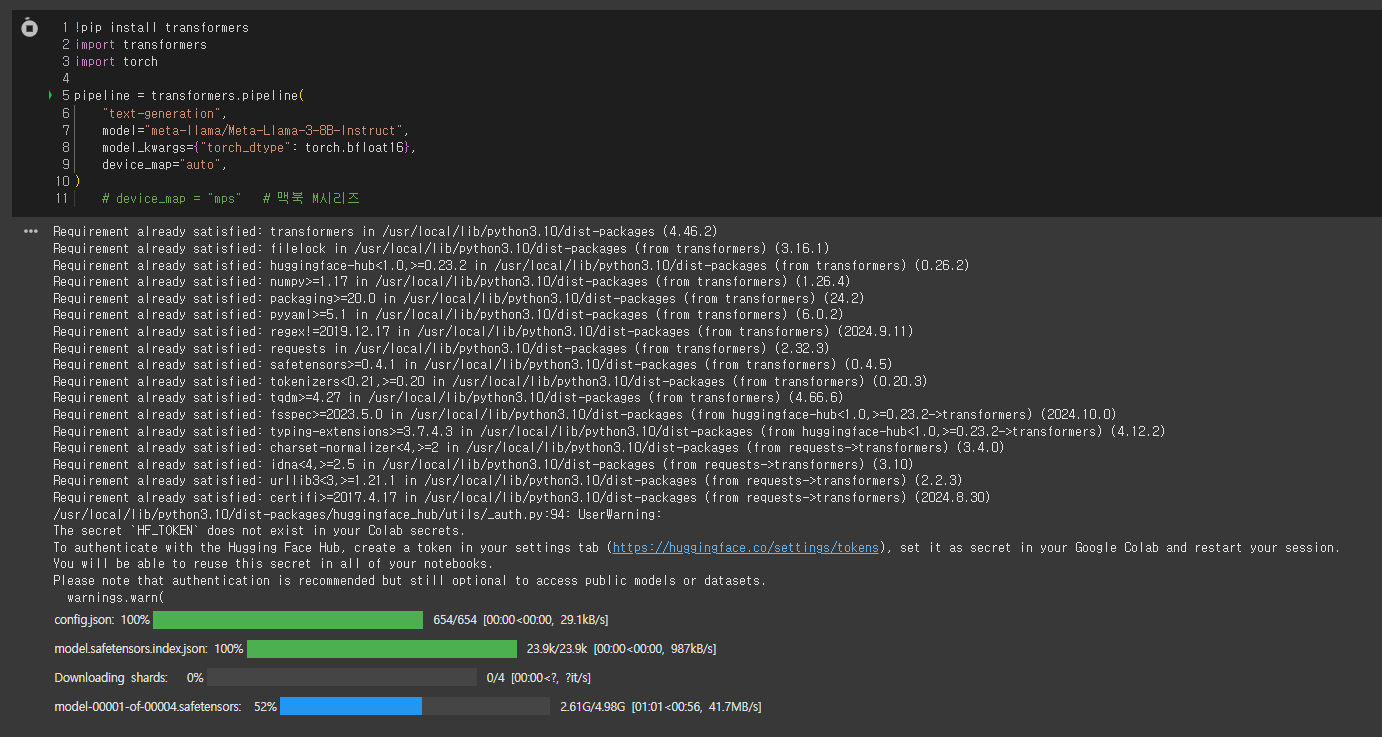
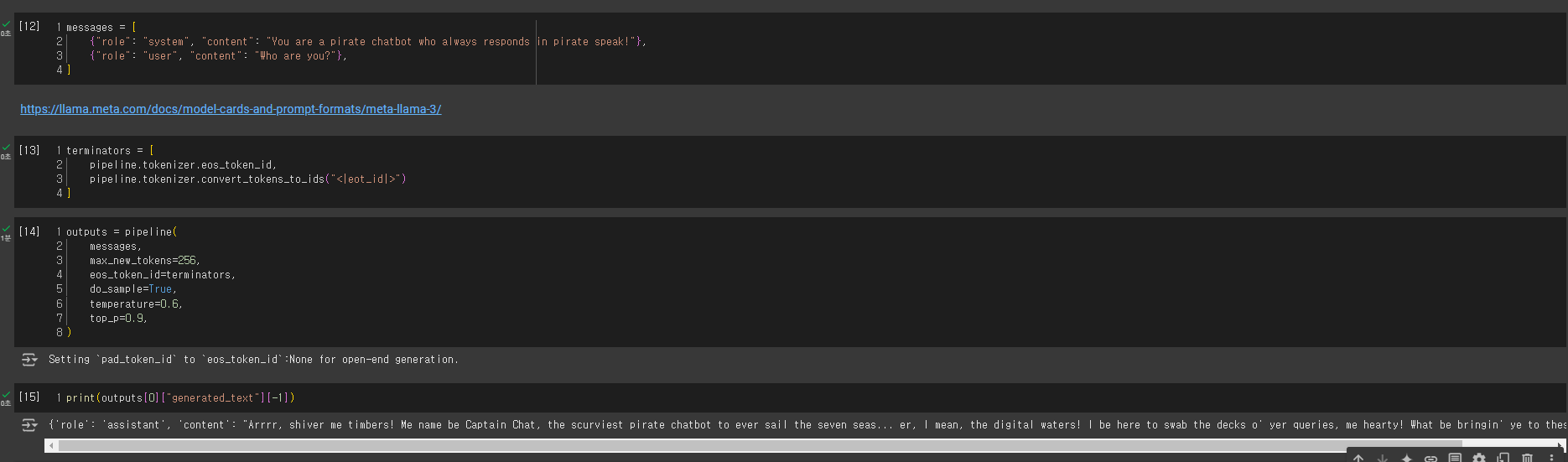
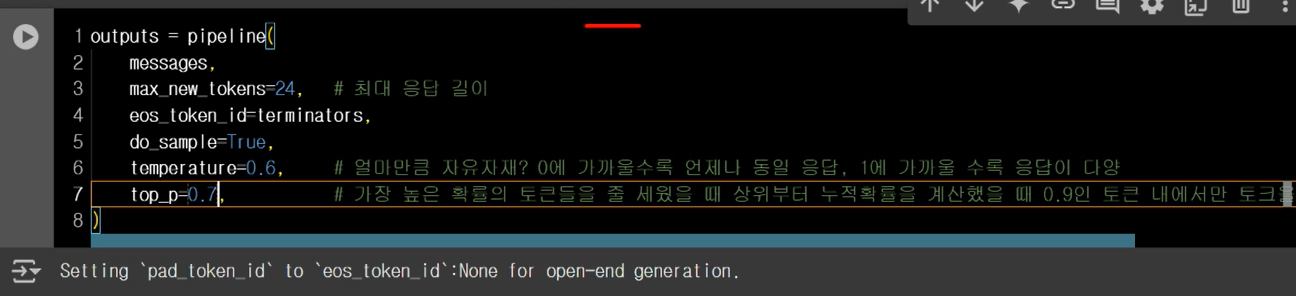
Llama 3 공식 문서 : https://llama.meta.com/docs/model-cards-and-prompt-formats/meta-llama-3/
Llama finetuning한 모델 : stanford 연구팀의 alpaca
https://crfm.stanford.edu/2023/03/13/alpaca.html
