Pandas란?
pandas는 데이터 조작 및 분석을 위한 파이썬 프로그래밍 언어 용으로 작성된 소프트웨어 라이브러리이다.
pandas 숫자 테이블과 시계열을 조작하기 위한 데이터 구조와 연산을 제공한다.
pandas는 numpy와 더불어 데이터 분석에서 필수적인 라이브러리라고 할 수 있다.
판다스 불러오기
import pandas
import pandas as pd데이터프레임(DataFrame)과
데이터프레임은 데이터 분석에서 사용하는 데이터 구조로 관계형 데이터베이스의 테이블 또는 엑셀과 같은 형태
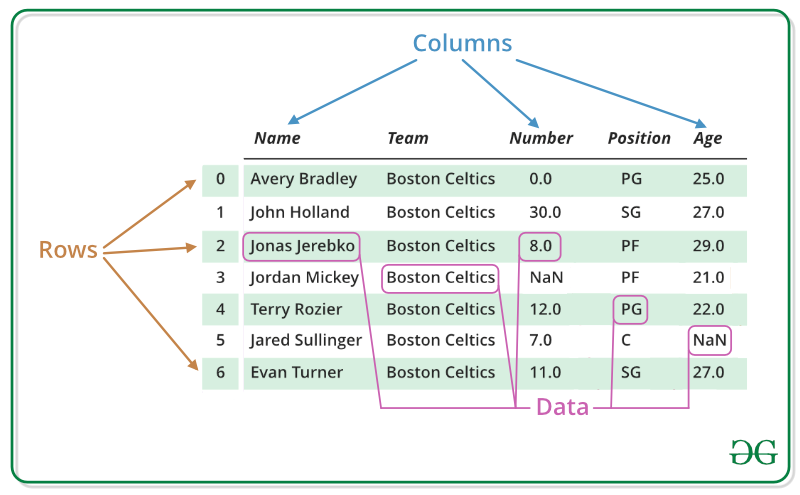
- 행 : 분석 단위
- 열 : 정보, 변수(feature, target)
시리즈(Series)
하나의 정보에 대한 데이터들의 집합으로, 데이터프레임에서 하나의 열을 떼어낸 것
csv파일에서 데이터 읽어오기
path = 'csv 파일 경로'
data = pd.read_csv(padh)데이터프레임 정보 확인
df.head() # 상위 5개 데이터 확인 (default)
df.head(3) # 상위 3개 데이터 확인
df.tail() # 하위 5개 데이터 확인 (default)
df.tail(3) # 하위 3개 데이터 확인
df.shape # 데이터프레임 모양 확인df.columns # 열 이름 확인
df.columns() # 열 정보 확인
df.dtypes() # 열 확인df.info() # 인덱스, 값 개수, 데이터 형식 정보 등 확인
df.columns() # 기초 통계 정보 확인데이터프레임 정렬 및 고유값 확인
# 데이터 정렬
df.sort_index(ascending=False) # 인덱스 기준 정렬
df.sort_values(by='열 이름', ascending=False) # 단일 열 정렬
df.sort_values(by=['열 이름1', '열 이름2'], ascending=[False, True]) # 복합 열 정렬# 고유값 확인
df['열 이름'].unique() # day 열 고유값 확인
df['열 이름'].value_counts() # 특정 열 고유값 개수 확인데이터프레임 조회
# 특정 열 조회
df['열 이름'] # 시리즈 열 조회
df.열이름
df[['열 이름']] # 데이터프레임 열 조회, 칼럼 이름을 리스트로 입력한 것.loc 사용
df.loc[df.['열 이름'] > 0.5] # 열 이름의 값이 0.5보다 큰 행 조회
df.loc[(df.['열 이름1'] > 0.5) & (df.['day'] == 'Sat')] # and로 여러 조건 사용
df.loc[(df.['열 이름1'] > 0.5) | (df.['day'] == 'Sat')] # or로 여러 조건 사용
df.loc[ : , ['열 이름1', '열 이름2']] # 특정 열의 모든 행 조회
df.loc[df['day'].isin(['Sat', 'Sun'])]데이터프레임 집계
dataframe.groupby('집계기준변수', as_index= )['집계대상변수'].집계함수
- 집계기준변수 : 범주형 변수
- 집계대상변수 : 집계함수로 집계할 변수 혹은 리스트
- as_index = True : 집계기준변수를 인덱스로 사용
df.groupby('day', as_index=True)['열 이름'].sum() # 시리즈용 groupby
df.groupby('day', as_index=True)[['열 이름']].sum() # 데이터프레임용 groupby# day별 열 이름 합계 (데이터프레임)
df.groupby('day', as_index=False)['열 이름'].sum()
df_sum = df.groupby('day', as_index=False)['열 이름'].sum()# 열 이름1, 열 이름2 합계 조회
df.groupby('day', as_index=False)[['열 이름1', '열 이름2']].sum()
# day별 나머지 열들 합계 조회
df.groupby('day', as_index=False).sum()
# day + age별 나머지 열들 합계 조회
df.groupby(['day', 'age'], as_index=False).sum() # day별 열 이름 합계, 평균, 최댓값, 최솟값
df.groupby('day')['열 이름'].agg(['sum', 'mean', 'max', 'min'])
# day별 열 이름1, 열 이름2 합계, 평균
df.groupby('day')['열 이름1', '열 이름2'].agg(['sum', 'mean'])
# day별 열 이름1 평균, 열 이름2 합계
df.groupby('day', as_index=False).agg({'열 이름1':'mean', '열 이름2':'sum'})데이터프레임 변경 (중요)
# 열 이름 변경
df.columns = ['열 이름1', '열 이름2', '열 이름3', ... 열 이름n,]
# rename() 메소드 사용
df.rename(columns={'열 이름1': '새로운 열 이름1',
'열 이름2': '새로운 열 이름2',
'열 이름3': '새로운 열 이름3',
'열 이름4': '새로운 열 이름4',
'열 이름5': '새로운 열 이름5'}, inplace=True)# 열 추가
df['열1+열2'] = df['열 이름1'] + df['열 이름2'] # 열 이름1과 열 이름2를 더한 값 추가
df.insert(1, ‘열1/열2', df['열 이름1'] / df['열 이름2'])# 열 추가
df['열1+열2'] = df['열 이름1'] + df['열 이름2'] # 열 이름1과 열 이름2를 더한 값 추가
df.insert(1, ‘열1/열2', df['열 이름1'] / df['열 이름2'])drop() 메소드를 사용해 열 삭제
- axis=0: 행 삭제(기본 값)
- axis=1: 열 삭제
- inplace=True: 삭제 결과를 현재 데이터프레임에 적용
# 열 삭제
df.drop('열 이름', axis=1, inplace=True)
df.drop(['열 이름1', '열 이름2'], axis=1, inplace=True)df[‘열 이름’] = 0 # 열 이름의 모든 값을 0을 바꾸기
# 열 이름의 값이 10보다 작을 경우 0으로 바꾸기
df.loc[tip[‘열 이름’] < 10, ‘열 이름’] = 0
# 열 이름이 10보다 작을 경우 0, 아니면 1로 바꾸기
df[‘열 이름’] = np.where(tip[‘열 이름’] < 10, 0, 1) df['sex'] = df['sex'].map({'Male': 1, 'Female': 0}) # 범주형 값을 변경할 때 사용
# 크기에 따라 3등분하여 등급을 부여 (숫자형 변수를 범주형으로 변경)
df['열 이름'] = pd.cut(tip['열 이름’], 3, labels=['a', 'b', 'c'] )데이터프레임 결합
- pd.concat()
- 매핑 기준 : 인덱스(행), 칼럼이름(열) - pd.merge()
- 매핑 기준 : 특정 칼럽(key)의 값 기준으로 결합- sql의 조인과 같은 기능
concat
- 방향 선택
- axis=0 : 세로(행)로 합치기- axis=1 : 가로(열)로 합치기
- 방법 선택
- join = 'outer' : 모든 행과 열 합치기 (매핑되지 않은 값은 NaN로 처리)- join = 'inner' : 매핑되는 행과 열만 합치기
df_con = pd.concat([df1, df2], join='outer', axis=1)
df_con = pd.concat([df1, df2], join='inner', axis=1)merge
- merge() 함수를 사용해 두 데이터프레임을 지정한 키 값을 기준으로 병합할 수 있다.
- 무조건 열 방향으로 진행하며, concat보다 많이 사용됨
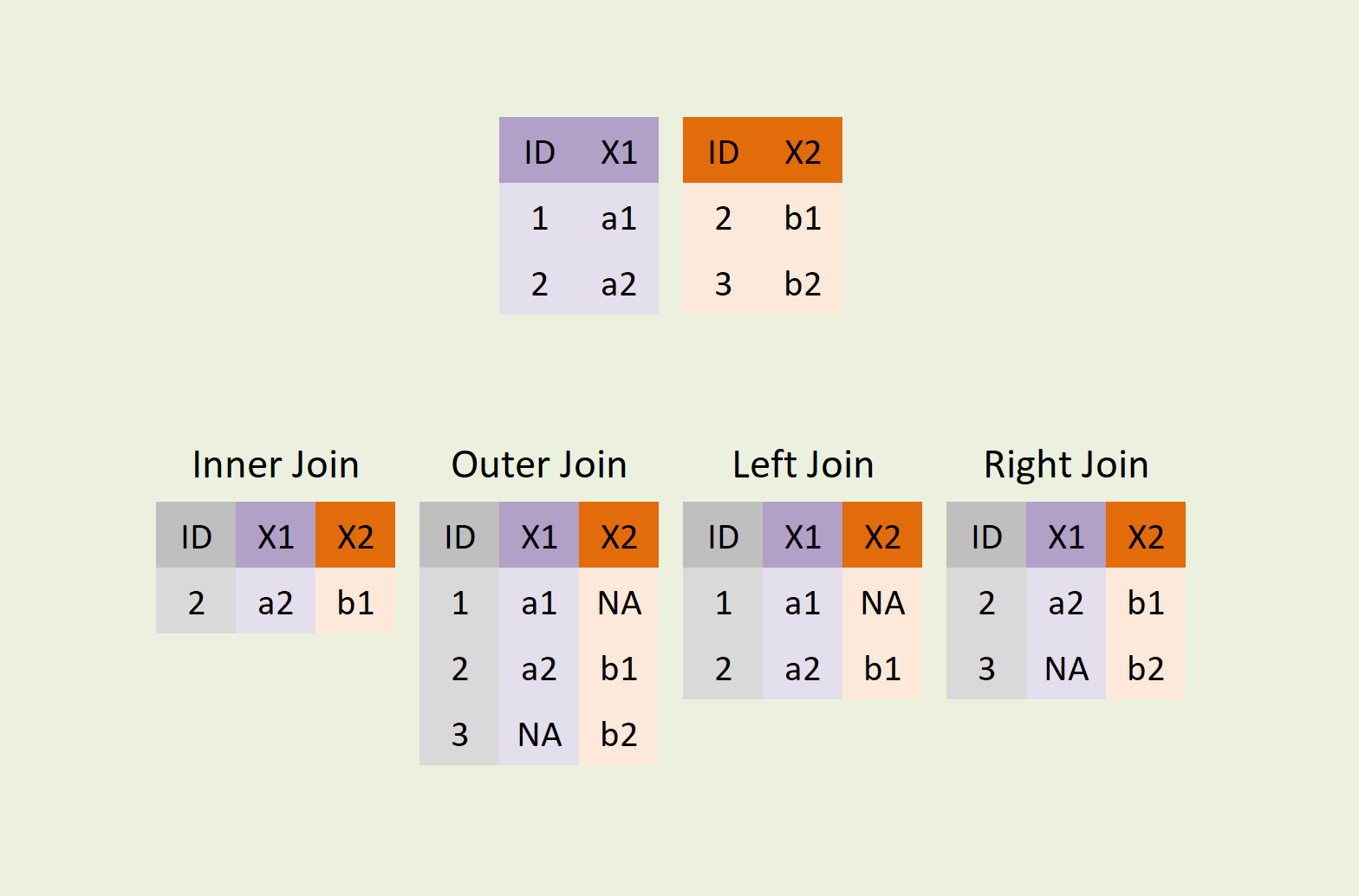
df_merge = pd.merge(df1, df2, on='열 이름', how='inner')
df_merge = pd.merge(df1, df2, on='열 이름', how='inner') pivot
- Pivot 함수를 이용하여 집계된 데이터를 재구성할 수 있다.
df.pivot(index, column, values)시계열 데이터 처리
- 시계열 데이터란 행과 행의 시간의 순서(흐름)가 있고, 시간 간격이 동일한 데이터
- 날짜 타입의 변수로부터 날짜의 요소를 뽑을 수 있음
df['date'].df.date # YYYY-MM-DD(문자)
df['date'].df.year # 연(4자리 숫자)
df['date'].df.month # 월(숫자)
df['date'].df.month_name() # 월(문자)
df['date'].df.day # 일(숫자)
df['date'].df.time # HH:MM:SS(문자)
df['date'].df.hour # 시(숫자)
df['date'].df.minute # 분(숫자)
df['date'].df.second # 초(숫자)
df['date'].df.quarter # 분기(숫자)
df['date'].df.day_name() # 요일이름(문자)
df['date'].df.weekday # 요일숫자(0-월, 1-화...) (=dayofweek)
df['date'].df.weekofyear # 연 기준 몇주째(숫자) (=week)
df['date'].df.dayofyear # 연 기준 몇일째(숫자)
df['date'].df.days_in_month # 월 일수(숫자) (=daysinmonth).shift()
- 시계열 데이터에서 시간의 흐름 전후로 정보를 이동시킬 때 사용
# day기준 전 날 데이터를 가져옴 (첫 번째 index는 NaN)
df['date_shift1'] = df['date'].shitf()
# day기준 이틀 전 데이터를 가져옴 (첫 번째, 두 번째 index는 NaN)
df['date_shift2'] = df['date'].shitf(2)
# day기준 다음 날 데이터를 가져옴 (첫 번째, 두 번째 index는 NaN)
df['date_shift-1'] = df['date'].shitf(-1).rolling().mean()
- 시간의 흐름에 따라 일정 기간 동안 평균을 이동하면서 구하기
# 당일 포함 전 날과 이틀 전 데이터의 평균을 추가 (전 날과 이틀 전 데이터 NaN)
df['date_roll_mean_3'] = df['date'].rolling(3).mean()
# 당일 포함 전 날과 이틀 전 데이터 중 가장 큰 값 추가 (전 날과 이틀 전 데이터 NaN)
df['date_roll_max_3'] = df['date'].rolling(3).max()
# min_periods=1 : 최소 1개의 데이터에서 mean을 추가 (NaN없이 모든 데이터 값 추가)
df['date_roll_mean_3'] = df['date'].rolling(3, min_periods=1).mean().diff()
- 특정 시점 데이터, 이전 시점 데이터와의 차이 구하기
# 당일 데이터 - 전 날 데이터
df['date_diff1'] = df['date'].diff()
# 당일 데이터 - 이틀 전 데이터
df['date_diff2'] = df['date'].diff(2)