numpy란?
numpy는 행렬이나 일반적으로 대규모 다차원 배열을 쉽게 처리할 수 있도록 지원하는 파이썬의 라이브러리이다.
numpy는 C언어로 만들어졌으며, 데이터 구조 외에도 수치 계산을 위해 효율적으로 구현된 기능을 제공한다.
파이썬을 이용한 데이터 분석에선 꼭 필요한 라이브러리이며, 기본적인 전처리를 위해선 반드시 숙지해야 한다.
numpy 불러오기
import numpy
import numpy as np용어 정의
- Axis : 배열의 각 축
- Rank : 축의 개수(차원)
- Shape : 축의 길이
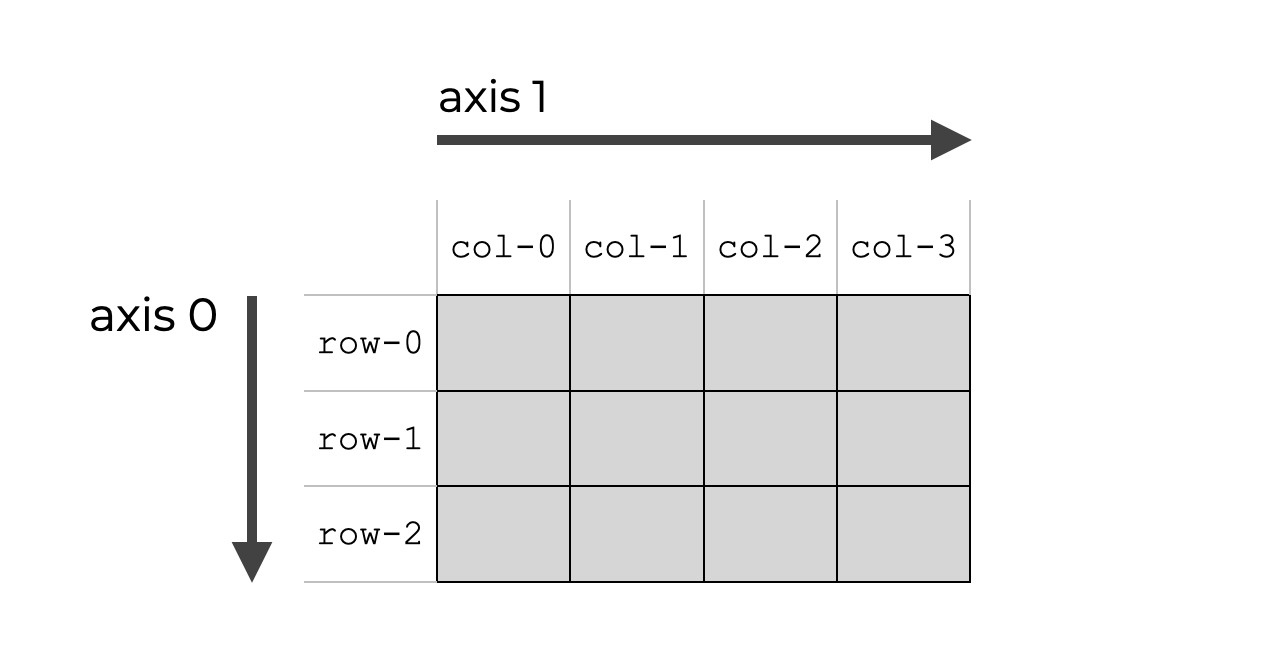
다음은 axis 0과 axis 1을 갖는 2차원 배열이며, 2개의 rank를 가진다.
첫번째 축의 길이는 3, 두번째 축의 길이는 4이므로 shape는 (3, 4)다.
배열 만들기
# 1차원 배열 만들기
a = np.array([1, 2, 3, 4, 5])
print(a) # numpy 배열 출력 : [1 2 3 4 5]
print(type(a)) # numpy 타입 출력 : <class 'numpy.ndarray'>
print(a.ndim) # 차원 수 출력 : 1
print(a.shape) # 배열의 모양 출력 : (5, )
print(a.dtype) # 배열의 데이터 타입 추력 : int32
print(a[0], a[1], a[2]) # 배열의 각 요소 출력 : 1 2 3# 2차원 배열 만들기
a = np.array([[1, 2, 3],
[4, 5, 6]])
print(a.shape) # (2, 3)# 리스트, 딕셔너리, 집합으로 넘파이 배열 만들기
a = np.array([list('python'), list('flower')])
dic = {'a':1, 'b':2, 'c':3}
a = np.array([list(dic.keys()), list(dic.values())])
st = {1, 2, 3}
a = np.array([list(st), list(st)])
리스트는 바로 numpy 배열로 만들 수 있지만, 딕셔너리나 집합은 리스트로 변환 후 numpy 배열로 만든다.
# 3차원 배열 만들기
a = np.array([[[1, 3, 1],
[4, 7, 6],
[8, 3, 4]],
[[6, 2, 4],
[8, 1, 5],
[3, 5, 9]]])
print(a.ndim) # 3
print(a.shape) # (2, 3, 3) 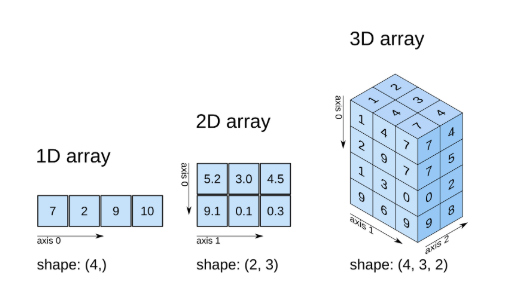
axis의 의미를 헷갈리지 않도록 주의한다.
Aixs 0의 의미
데이터 분석 및 모델링에서 axis 0은 분석 단위를 구성한다
- 2차원 데이터 (2000, 10)이라면 10개의 변수로 구성된 데이터 1000건 존재
- 3차원 데이터 (300, 28, 28)이라면 28x28 크기의 이미지 데이터가 300개 존재
배열 다루기
# 배열 형태 바꾸기
a = np.array([[1, 2, 3],
[4, 5, 6]])
b = np.reshape(a, (6, 1)) # 6 x 1 형태의 2차원 배열로 변환
c = a.reshape(3, 2) # 3, 2 형태의 2차원 배열로 변환
print(a.reshape(3, -1)) # [[1 2] [3 4] [5 6]]
print(a.reshape(-1)) # [1 2 3 4 5 6]
- arr.reshape()의 인자를 -1로 주면 원래 배열의 길이와 남은 차원으로 추정되어 결정된다.
a = np.array([[0, 1, 2],
[3, 4, 5]])
print(a.transpose())
print(a.T) # 배열의 방향을 변환 : [[0 3] [1 4] [2 5]]# 여러가지 형태 배열 만들기
a = np.zeros((2, 2)) # 0으로 채워진 배열
b = np.ones((1, 2)) # 1로 채워진 배열
c = np.full((2, 2), 7.) # 특정 값으로 채워진 배열
d = np.eye(2) # 2x2 단위 행렬
e = np.random.random((2, 2)) # 랜덤값으로 채운 배열a = np.array([[1, 2, 3],
[4, 5, 6]])
print(a.mean()) # 3.5배열 데이터 조회
# 인덱싱과 슬라이싱
a = np.array([[1, 2, 3],
[4, 5, 6]])
print(a[0, 2]) # 3
print(a[0][2]) # 3
print(a[1]) # [4 5 6]
print(a[:, 2]) # [3 6]Score_2d = np.array([[78, 91, 84, 89, 93, 65],
[82, 87, 96, 79, 91, 73]])
Score_2d[Score_2d >= 90] # array([91, 93, 96, 91])
# 반드시 arr[n][arr[n] 조건문] 형태로 전달해야 함
Score_2d[1][score_2d[1] >= 90] # array([96, 91])배열의 연산 및 집계
# 배열의 연산
a = np.array([[1, 2],
[3, 4]])
b = np.array([[5, 6],
[7, 8]])
print(np.add(a, b)) # [[ 6 8] [10 12]]
print(np.subtract(a, b)) # [[-4 -4] [-4 -4]]
print(np.multiply(a, b)) # [[ 5 12] [21 32]]
print(np.divide(a, b)) # [[0.2 0.33333333] [0.42857143 0.5]]
print(np.power(a, b)) # [[1 64] [2187 65536]]
print(np.sqrt(a)) # [[1. 1.41421356] [1.73205081 2.]]# 배열의 집계
a = np.array([[1, 2],
[3, 4]])
print(np.sum(a)) # 10
print(np.sum(a, axis=0)) # 열 기준 합계 : [4 6]
print(np.sum(a, axis=1)) # 행 기준 합계 : [3 7]
# 조건에 따른 집계
a = np.array([1,3,2,7])
np.where(a>2, 1, 0) # [0 1 0 1]
# 인덱스 반환 [np.argmax, np.argmin]
a = np.array([[1, 5, 7],
[2, 3, 8]])
print(np.argmax(a)) # 전체 중 가장 큰 값의 인덱스 : 5
print(np.argmax(a, axis = 0)) # 열 기준 큰 값의 인덱스 : [1 0 1]
print(np.argmax(a, axis = 1)) # 행 기준 큰 값의 인덱스 : [2 2]