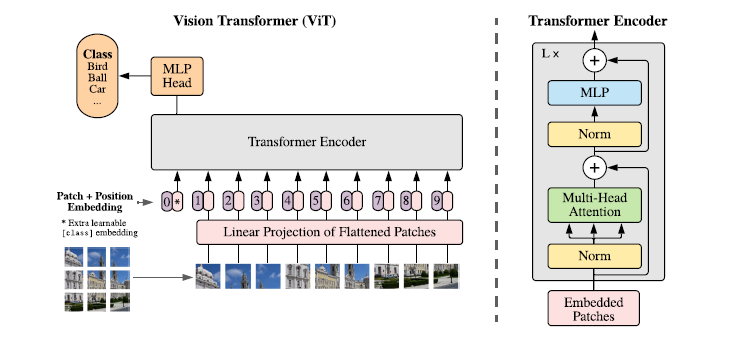
1. Introduction
Transformer 같은 self-attentention 기반 구조가 NLP에서 좋은 성능을 내고 있다.
→ 이미지에 적용 시도
본 논문에서는 표준 tranformer 를 최대한 변형 없이 직접 이미지에 적용
🧪 Tranformer 만을 이용하여 이미지 분류 테스크 수행 실험1. image를 patch 단위로 쪼갬
2. patch 들의 linear embeding 시퀀스를 transformer에 input 으로 ⇒ image의 patches = NLP에서 token(word)
3. ImageNet 정도 크기의 데이터 셋로 학습했을 때는 ResNet보다 성능이 조금 떨어짐.
그러나 대량의 데이터에 대해 사전 학습한 후 작은 이미지 인식 벤치마크(이미지넷, CIFAR-100, VTAB)에 적용
기존의 SOTA CNN기반 모델보다 성능 좋게 나옴
위 실험 결과 분석
-
실험에서 데이터 셋이 더 적었을때 더 결과가 안나온 건 Tranformer가 inductive bias가 부족해서,
충분한 양의 데이터가 없을 때는 제대로 일반화 하지 못했기 때문이다.
⇒ 대량의 훈련 데이터가 이 문제를 해결
참고 : https://re-code-cord.tistory.com/entry/Inductive-Bias란-무엇일까
- inductive bias
모델이 학습 데이터이외의 데이터들에 대해서도 정확히 예측하기 위해 사용하는 추가적인 가정
ex, translation equivariance
: input의 위치가 다르면 output도 달라짐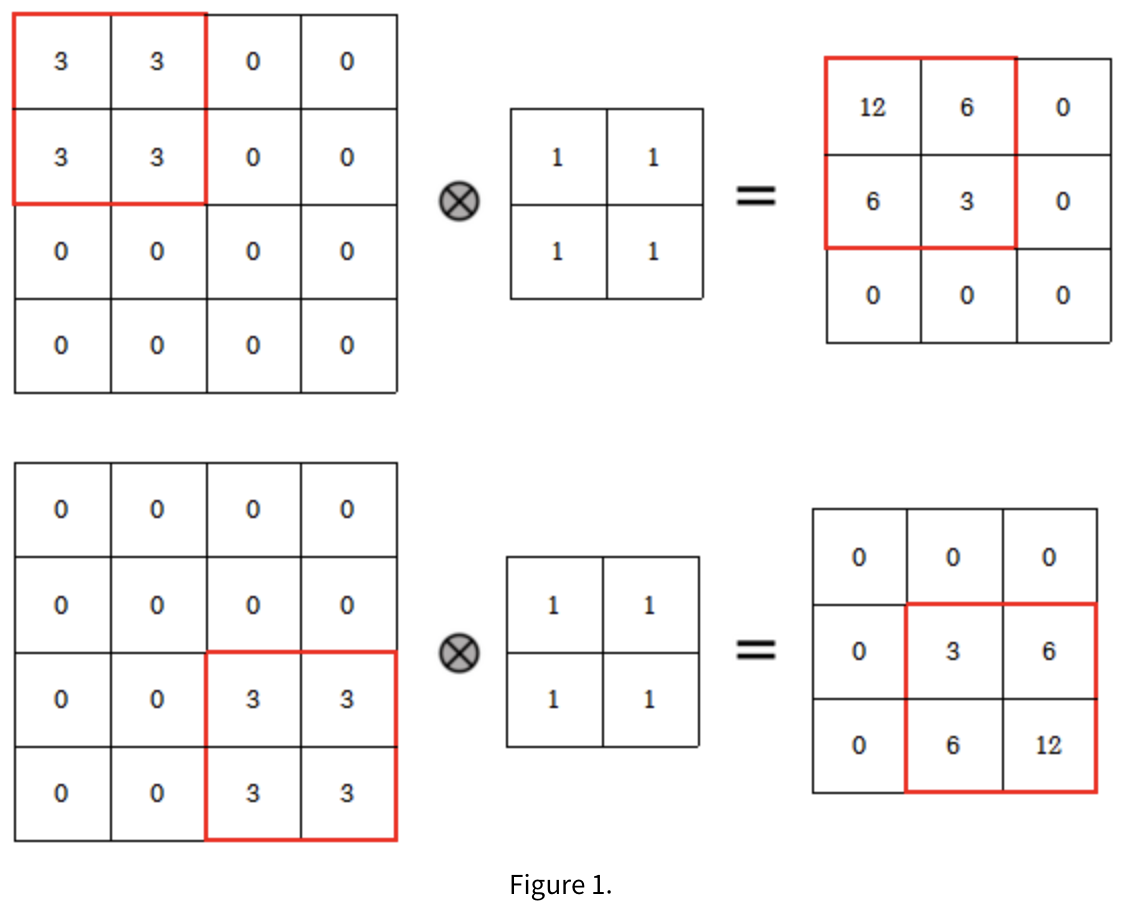
사실 CNN 네트워크 자체의 특성은 translation equivariance 한데,
max pooling과 CNN 특징 + Softmax과정을 통해 Classification은 translation invariance한 성질을 갖게 된다.
즉, CNN은 local한 영역에서 공간정보를 뽑아내고, RNN 역시 시계열 관점에서 시간에 따른 Sequential한 정보를 뽑아내 예측에 사용할 수 있다. 하지만 Transformer 는 이런 가정이 없어서,
많은 데이터로부터 충분한 학습을 하지 않으면 성능이 좋지 못한 것,
2. Related Work
1. Approximations for applying Transformer in image processing
순수 self-attention이 이미지에 적용되면 각 픽셀에서 모든 픽셀의 어텐션 값을 계산하게 된다.
⇒ pixel 수의 제곱으로 비용이 늘어나기 때문에 실제 입력 크기에는 적용 블가
이를 해결하기 위해 근사 하기 위한 연구들도 있었으나 GPU(TPU)등에 적용하기에는 부족
: local multi-head dot-product self attention block , Sparse Tranformer, 같은 좌표축에 따라서만
attention적용
저자의 모델(ViT)와 가장 유사한 모델
On the Relationship between Self_attention and Convolution Layers
논문 링크 : https://arxiv.org/abs/1911.03584
full image 에 attention을 적용하기 힘든 문제를 이미지로부터 2*2 크기의 patch들을 추출하여 selt-attention의 top에 적용함으로써 해결하였으나 해상도 낮은 이미지에만 적용 가능
ViT는 pre-training을 이용해 트랜스포머의 성능을 SOTA 성능의 CNNs 모델에 필적하는 것을 보여줬다는 차이점이 있다.
2.Combination with CNN and self-attention
CNN과 self-attention의 결합에 대한 연구들
- feature map 을 augmentation
- Attention augmented convolutional network
- CNN 의 output을 self attention을 적용
- Relation Networks - object detection
- Non-local neural networks - video processing
- Token-based image representation - image classification ..
기존의 최신 모델 중 가장 유사한 모델
Generative Pretraining from Pixels - image GPT
논문 링크 : https://paperswithcode.com/paper/generative-pretraining-from-pixels
모델 특징
- NLP 모델인 GPT에 적용하기 위해 고차원의 이미지 데이터를 낮은 해상도의 벡터로 resize
- 색상 차원을 낮추고 raster order을 이용하여 이미지를 token과 같이 sequential data로 처리
ImageNet 데이터에서 72% 정확도 보임
3. Method
자연어처리 Transformer 의 좋은 scalability 와 효율적인 implement 를 활용하기 위해 기존 transformer 와 구조를 최대한 비슷하게 함
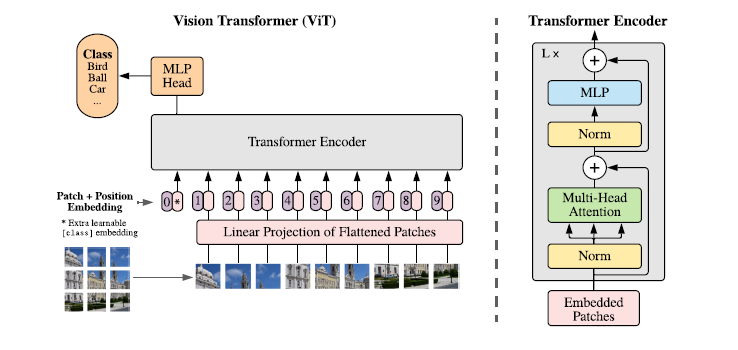
3.1 Vision Transformer(ViT)
reshape input
토큰 임베딩의 1차원 시퀀스를 input 으로 받는 일반적인 transformer와 달리 2D 이미지를 다뤄야 하기 때문에 추가적인 작업이 필요하다.
크기의 이미지 → 크기의 flattened 2D patches
: 원본 이미지의 해상도
: 채널 개수
: 각 image path의 해상도
reshape 결과 나오게 되는 image patch 의 개수
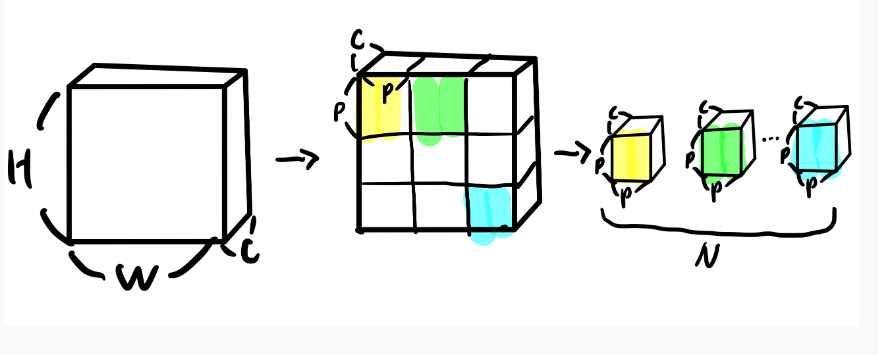
그림 출처 : https://baekyeongmin.github.io/paper-review/vision-transformer-review/
Transformer은 모든 레이어에서 고정된 벡터 크기 D를 사용하기 때문에 이미지 패치는 펼친 다음 D차원 벡터로 linear projection 시킨다.
bert의 [CLS] 토큰 처럼 임베딩 된 패치의 시퀀스에 z0 = x_class 임베딩을 추가로 붙여 넣고,
이후 이 패치에 대해 나온 인코더 아웃풋은 이미지 representation으로 해석하여 분류에 사용한다.
Position Embedding
patch 의 위치 정보를 유지하기 위해 추가하였으며 학습 가능한 1D 임베딩 사용한다.
2차원도 사용해보았지만 유의미한 성능 향상은 없었다고 한다.
위 과정에서 만들어진 입력()이 Transformer 인코더의 입력으로 들어가게 되고, 인코더는 MSA(multiheaded self-attention)과 LN(LayerNorm), MLP(multi layer perceptron, 2-layer GELU non-linearity) residual connection 연산으로 구성된다.
결과적으로 이미지의 representation(y, 마지막 layer 출력값의 시퀀스에서 첫번째 값)을 얻음.
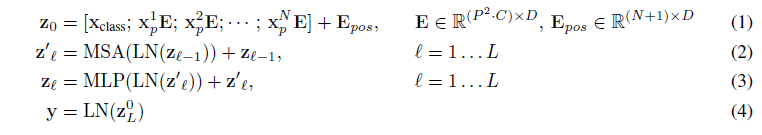
모델 특징
- CNN에 비해 inductive bias 부족
- hybrid architecture 시도
raw image patch 대신 CNN의 피쳐맵을 Transformer 인코더의 입력 시퀀스로 넣는 방법.
즉, CNN 위에 Transformer encoder를 쌓은 구조
3.2 Fine-Tuning And Higher Resolution
저자는 대량의 데이터 셋으로 pre-train한 후 작은 다운스트림 테스크에 fine-tuning했다.
이를 위해 pre-train 된 prediction head를 제거하고 0으로 초기화 된 D * K 크기의 feedforward layer를 추가
사전학습에 이용된 이미지보다 더 높은 해상도의 이미지를 처리해야 할 경우, 이미지 패치 크기를 동일하게 유지함으로써 더 긴 패치 시퀀스를 사용할 수 있다.
단, 이 경우 시퀀스의 길이가 달라지기 때문에 사전 학습된 위치 임베딩이 의미없어진다.
⇒2D interporation 방법으로 원래 이미지의 위치에 따라 사전학습된 position embedding을 늘려줌
4. Experiments
ResNet , Vision Transformer(ViT), hybrid 3가지 모델 구조를 비교
각 모델별 데이터 요구량을 파악하기 위해 다양한 크기의 데이터로 사전학습 후 평가
4.1 Set-Up
Datasets
pre-train dataset
- ILSVRC-2012 ImageNet(1k class , 1.3M image)
- ImageNet-21K (21k class , 14M image) ; ImageNet 포함
- JFT(18k class ,303M 고화질 이이미지)
transfer learning dataset
- ImageNet(오리지널 validation 라벨과 cleaned-up ReaL 라벨)
- CIFAR-10/100
- Oxford-IIIT Pets
- Oxford Flowers-102
- Fine-Tuning 과 Transfer learning 차이 ☝ Fine-Tuning vs Transfer Learning - Fine-Tuning - 출력층 등을 변경한 모델을 학습된 모델을 기반으로 구축한 후 직접 준비한 데이터로 신경망 모델의 결합 파라미터 학습 - 결합 파라미터의 초깃값은 학습된 모델의 파라미터 사용 - 전이학습과 달리 모든 층의 파라미터 재학습 - Transfer-Learning - 학습된 모델을 기반으로 최종 출력층을 바꿔서 학습 - 학습된 모델의 최종 출력층을 보유 중인 데이터에 대응하는 출력층으로 바꾸고, 교체한 출력층의 결합 파라미터(+앞 층의 결합 파라미터)를 소량의 데이터로 다시 학습 - 입력층에 가까운 부분의 결합 파라미터를 변화시키지 않음
Model variants
1) ViT
BERT의 설정과 유사
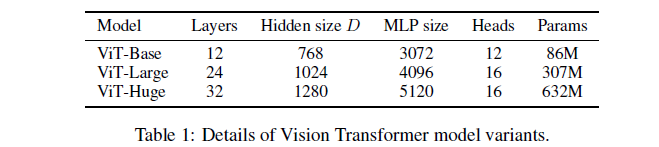
2) CNN
CNNs baseline 으로 ResNet을 조금 바꿔서 사용
- Batch Normalization layers → Group Normalization , standardized convolution
3) hybrids
ResNet50의 intermediate 피쳐맵을 ViT의 입력 시퀀스로 이용 = 1 pixel을 하나의 패치로 이용
Training & Fine-tuning
사전학습
- Optimizer : Adam 고정 (β1=0.9,β2=0.999,weight decay : 0.1)
- batch size : 4096
Fine-Tuning
- Optimizer : Adam + SGD
- Batch size : 512
보통 Adam이 Resnet 에서 SGD보다 성능이 좋은데 본 논문에서는 아니었다고 한다.
Metrics
- few-shot accuracy : fine tuning 이 너무 오래 걸리는 경우에만 사용
- fine-tuning accuracy
4.2 Comparison to SOTA
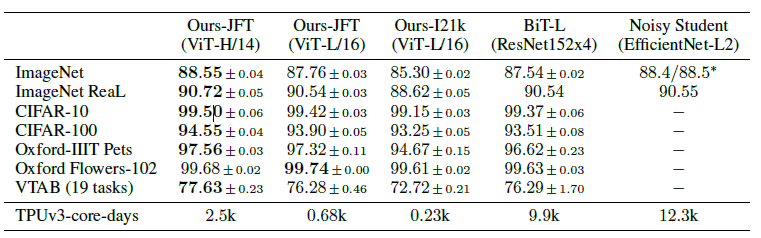
JFT-300M dataset으로 사전학습된 ViT모델이 모든 데이터셋에 대해 ResNet 기반의 baseline 모델보다 뛰어남
4.3 Pre-Training Data Requirements
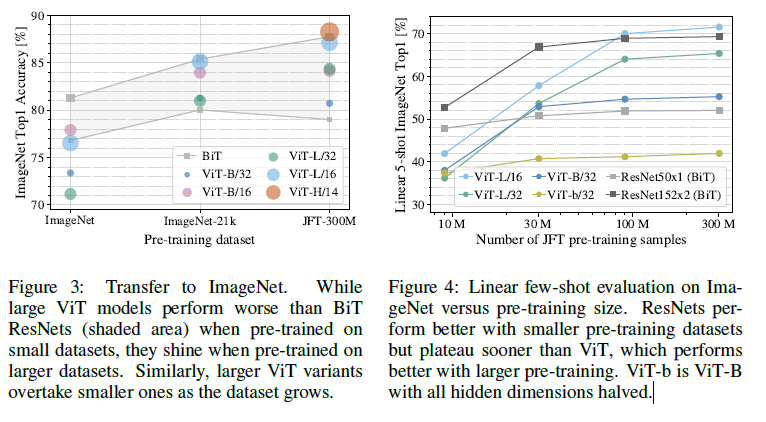
ImageNet 에서는 BiT CNNs모델이 더 성능이 좋았지만 더 큰 데이터셋에서는 ViT가 훨씬 좋게 나왔고, 작은 데이터 셋에 대해 ViT가 ResNet보다 더 overfit 되었다
→ 데이터 셋의 크기가 작을 때는 inductive bias 가 유용하지만 클떄는 데이터로 부터만 패턴 학습 하는 것으로 충분한 것으로 추론
4.5 Inspecting vision transformer

- 왼쪽 : ViT 의 첫 layer가 patch 들을 flattened patch 들을 더 낮은 차원으로 projection
- 중간 : 그 후 학습된 position embedding 을 patch repreentation에 추가
model이 이미지 내의 거리 개념을 인코딩하여 position embedding 유사성을 계산 가까운 거리에 있는 패치는 비슷한 위치 임베딩을 가지게 된다.
⇒ 같은 열이나 행에 위치한 임베딩이 비슷하다.
- 오른쪽 : 이미지 공간에서 attention weights를 기반으로 나타낸 평균 거리
self-attention을 통해 ViT는 가장 낮은 layer 이미지 정보도 통합적으로 고려
또 다른 attention head는 밑단 레이어에서 일관적으로 작은 거리의 패치에 집중
이러한 지역적인 attention은 하이브리드 모델에서는 좀처럼 나타나지 않았다.
즉, 이 attention head는 CNN의 밑단에서 일어나는 것과 비슷한 작용을 하는 것이라고 유추할 수 있다.
- classfication task를 위해 의미적으로 관계있는 부분을 attend 하는 경향을 확인할 수 있다.

5. Conclusion
Transformer를 image recognition에 적용
image-specifi한 inductive bias를 추가하는 대신 image 를 patch sequence 로 만들어 NLP transformer 의 인코더로 처리할 수 있도록 했다.
그 결과, image 분류 데이터셋에서는 SOTA 에 이상의 성능을 보였지만,
ViT를 detection이나 segmentation에 적용하는 것과 사전학습에서 selfsupervised방식으로 하는 것에 대한 연구가 더 필요하다.
참고
https://littlefoxdiary.tistory.com/70
https://velog.io/@sjinu/논문리뷰AN-IMAGE-IS-WORTH-16X16-WORDS-TRANSFORMERS-FOR-IMAGE-RECOGNITION-AT-SCALE-Vi-TVision-Transformer
https://baekyeongmin.github.io/paper-review/vision-transformer-review/
