[논문리뷰]AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE : Vi-T(Vision Transformer)

Paper: https://arxiv.org/abs/2010.11929
Code: https://github.com/google-research/vision_transformer

본 글에서는 Vision-Transformer로 유명한 논문인 "AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE"에 대해서 다루도록 하겠습니다.
0. Abstract
모두가 알다시피 Transformer 아키텍처는 NLP 분야에서 사실상의 표준과도 같았습니다.
Vision 분야에서는 아직 Transformer 구조가 활발하게 적용되는 단계는 아니였는데, 기껏해야 convolution networks와 같이 쓰이거나, 일부 구성요소를 대체하는 정도였습니다.
저자들은 비전 분야에서 CNNs에 의존하는 것이 필수불가결한 것은 아니며, CNN을 사용하지 않는 pure transformer또한 이미지 분류 태스크에서 매우 좋은 성능을 달성할 수 있음을 보여줍니다.
이 때 image patches를 sequence로 바라봅니다.
저자들은 이러한 Vision Transformer(ViT)를 많은 양의 데이터에 사전학습시킨 다음 이를 mid-size 이미지, 혹은 small-size 이미지 인식 태스크(예를 들어 ImageNet, CIFAR-100, VTAB 등)와 같은 다양한 태스크에 전이학습을 시켜 Evaluation을 진행하였습니다.
그 결과, ViT는 기존의 sota성능을 보이는 cnn 기반 네트워크에 필적하는 좋은 결과를 보였습니다.
사실상 ViT 학습에 따르는 연산 resource가 CNNs에 비해 적게 들기 때문에 단순한 성능 자체는 더욱 좋다고 볼 수 있습니다.
1. Introduction
Self-attention기반 아키텍처는 NLP분야의 태스크에서 보편적으로 쓰이는 모델입니다(대표적으로 트랜스포머).
일반적으로 Large text corpus에 사전학습시킨 다음, smaller task-specific dataset에 전이학습을 시키는 접근법이 널리 사용됩니다.
Transformer 기반 모델들은 아래와 같은 장점을 가지기에 더욱 널리 사용되고 있으며, 모델과 데이터셋이 증가함에 따라 성능 또한 포화상태에 이를 기미가 아직은 보이지 않습니다.
Transformer-based 모델의 장점
1. 연산이 효율적이다(computational efficiency).
2. 확장성이 좋다(scalability). 특히 input sequence의 길이에 구애받지 않는다.
하지만, computer vision 분야에서는, 여전히 convolutional-based architecture가 지배적인 상황입니다.
물론 NLP 분야에서의 성공을 참고 삼아 CNN기반 아키텍처를 Self-attention과 결합하거나, CNN을 아예 Attention으로 대체하는 연구들도 존재하긴 했습니다((2018)Wang et al. / (2019)Ramachandran et al.).
이 연구들은 이론적으로 효율적이긴 했지만, GPU(TPU)와 같은 하드웨어 가속기에 보편적으로 적용하지 못하는 상태였습니다.
latter model have not yet been scaled effectively on modern hardward accelerator due to the use of specialized attention pattern.
아무튼, 이런 저런 이유들로 여전히 Res-net기반 아키텍처들이 이미지 분야에서의 SOTA모델인 상황이었다고 합니다.
저자들은 NLP 분야에서 트랜스포머의 scaling successes에 특히 영감을 받아 image에 트랜스포머를 직접적으로 적용할 수 있는 연구를 진행했습니다.
ViT의 과정은 대략적으로 아래와 같이 기술할 수 있습니다.
- 이미지를 image pathces로 쪼갠다.
- 이 patches들을 linear하게 임베딩해 시퀀스를 생성한다.
- 이렇게 생성한 시퀀스를 트랜스포머의 input으로 투입한다.
즉, ViT에서 하나의 이미지 패치는 하나의 token으로 작동합니다.
이런 방식으로 이미지 분류를 지도학습합니다.
ImageNet과 같은 mid-sized dataset에 ViT를 학습시킬 때에는, 강한 규제가 없다면, 비슷한 사이즈를 갖는 ResNet모델에 비해 정확도가 몇 퍼센트 낮은 무난한 결과를 보입니다.
성능 자체는 CNN기반 ResNet보다 낮은데, 그 이유와 의의를 저자들은 아래와 같이 기술하고 있습니다.
- Transformer는 inductive biases*가 없습니다.
- CNN은 inductive biases를 가지고 있습니다.
- 따라서 data가 크지 않다면 Transformer는 일반화하기 쉽지 않습니다.
inductive bias*란,
모든 모델이 지금까지 만나보지 못했던 상황에서 정확히 예측하기 위해 사용하는 추가적인 가정을 말합니다.
가령, 예를 들면 아래와 같습니다.
- CNN : Locality와 translation equivariance.
- RNN : Sequentiality를 사용해 패턴을 예측
즉, CNN은 local한 영역에서 공간정보를 뽑아내고, RNN 역시 시계열 관점에서 시간에 따른 Sequential한 정보를 뽑아내 예측에 사용할 수 있습니다.
Transformer는 이런 가정이 없어서, 많은 데이터로부터 충분한 학습을 하지 않으면 성능이 좋지 못합니다.
반대로 말하면, CNN과 RNN 둘 다 global한 정보를 활용하기는 힘들기 때문에 한계 역시 명확했죠. 이를 보완하기 위한 연구들 또한 굉장히 많았습니다.
(Inductive bias의 예시)
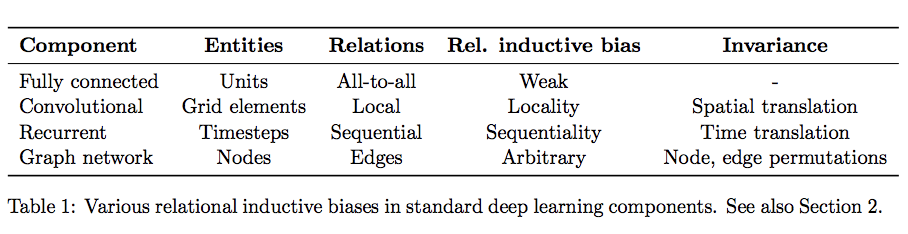
translation equivariance and invariance
- 간단히 말하면, CNN은 convolution 과정을 수행할 때 가중치가 공유되는 filter를 이용해 새로운 이미지를 생성하기 때문에, input image 패턴만 같다면 output representation 또한 같은 패턴을 생성합니다.
- 즉, object를 단순히 translation(이동) 시킨다면 아래와 같이 유사한 output representation을 생성합니다.
- 또한 여기서 [pooling->softmax]를 통한 분류를 수행한다면, representation의 위치는 변화할지 언정 결과적으로 같은 class**를 반환한다는 것을 쉽게 유추할 수 있습니다.
- 이를 translation invariance라고 합니다.
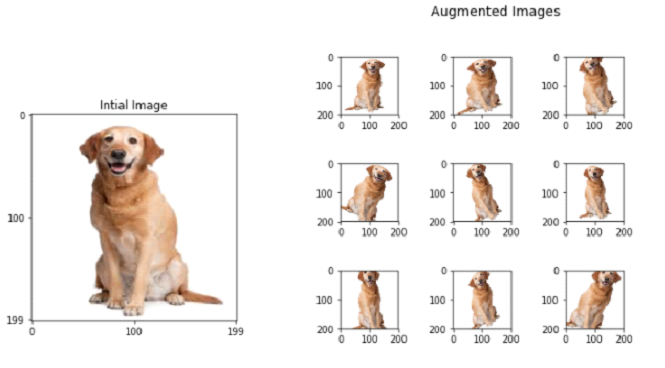
- 반대로 단순 translation(이동)이 아닌 rotation(회전)이나 scale(크기)이 변환한다면 결과 또한 달라질 수 있습니다.
data augmentation- 그렇기 때문에 data augmentation을 적용할 때 단지 Traslation만 적용한다면 사실상 의미가 없습니다(아래에서 scale, rotation 등등 변화시켜주는 모습을 볼 수 있습니다).
출처: https://towardsdatascience.com/translational-invariance-vs-translational-equivariance-f9fbc8fca63a
아무튼, ViT는 이런 CNN에 내재된 inductive bias가 존재하지 않기 때문에, 데이터가 적을 때 성능 자체는 낮을 수 있지만, 데이터가 많다면 상황은 또 달라집니다.
가령, ViT를 larger datasets(14M-300M개의 이미지)에 학습시킨다면, 이런 inductive bias의 효과를 추월할 수 있습니다.
즉, ImageNet-21k나 JFT-300M dataset과 같은 큰 데이터셋에 사전학습 시킨 다음, 각각의 태스크에 전이학습을 시켰을 경우 ViT는 거의 sota성능을 보입니다.
지금까지 많이 나온 scale, scalability 등은 트랜스포머 모델의 태스크 확장성, large dataset 활용능력 등을 뜻하는 부분입니다.
2. Related work
NLP 분야에서는, 트랜스포머 기반 모델들은 보통 large corpora에 사전학습 시킨 다음, 원하는 태스크에 전이학습시켜 사용하곤 합니다.
- BERT : denoising self-supervised pre-training task 사용.
- GPT 계열 : language modeling을 pre-training task로 사용.
이 때 사전학습 방법을 Self-Supervised Learning이라고도 합니다.
Vision 분야에서는, 우선 Attention 기법을 다이렉트하게 이미지에 적용하는 방법을 생각해볼 수 있습니다.
가령, 이미지의 각 픽셀과 모든 픽셀의 어텐션을 계산할 수 있습니다.
다만, 이런 방식은 (픽셀 개수의 제곱에 해당하는 어텐션이 필요한 것을 고려했을 때) 실질적인 input size에는 적용할 수 없는 한계가 있습니다.
이처럼 하나의 픽셀에 곧바로 어텐션을 적용할 수 없는 한계를 해결하기 위해서 근사화를 사용한 연구들 또한 존재하긴 했습니다.
- local multi-head dot-product self attention block : 어텐션을 모든 픽셀에 적용하는 것이 아닌, 하나의 query pixel과 그 근방의 pixel들과의 어텐션만 계산
- 어느 정도 convolution을 대체할 수는 있었습니다.
- Sprase Transformer : global self-attention을 이미지에 적용하기 위해 scalable approximation 사용
- 다양한 사이즈의 블록에 attention을 사용
- 같은 좌표 축에 따라서만 attention 적용
위 연구들은 분명 좋은 성능을 보였으나, 결국 GPU(TPU) 등에 적용하기 위해서는 아주 복잡한 엔지니어링과정이 필요했습니다.
저자들의 모델(ViT)와 가장 유사한 모델은 아래의 연구입니다.
- Jean-Baptiste Cordonnier, Andreas Loukas, and Martin Jaggi. On the relationship between self attention and convolutional layers. In ICLR, 2020
간략히 정리했던 적이 있습니다.↓
[논문리뷰] On The Relationship Between Self-Attention and Convolution Layers
해당 연구는 아래와 같이 full image에 attention을 적용하기 힘든 문제를 image patches를 추출해 어텐션을 적용함으로써 연산량을 조금 낮춥니다.

이는 ViT와도 굉장히 유사하지만, ViT는 pre-training을 이용해 트랜스포머의 성능을 SOTA 성능의 CNNs 모델에 필적하는 것을 보여줬다는 차이점이 있습니다.
기존의 image patch attention과 다르게 small-resolution 이미지 뿐만 아니라 medium-resolution 이미지까지 적용했습니다.
CNN과 self-attention의 결합에 대해 다룬 연구 또한 다양합니다.
- Attention을 이용해 feature maps을 augment하는 연구
. Bello et al, Attention augmented convolutional networks.In ICCV.
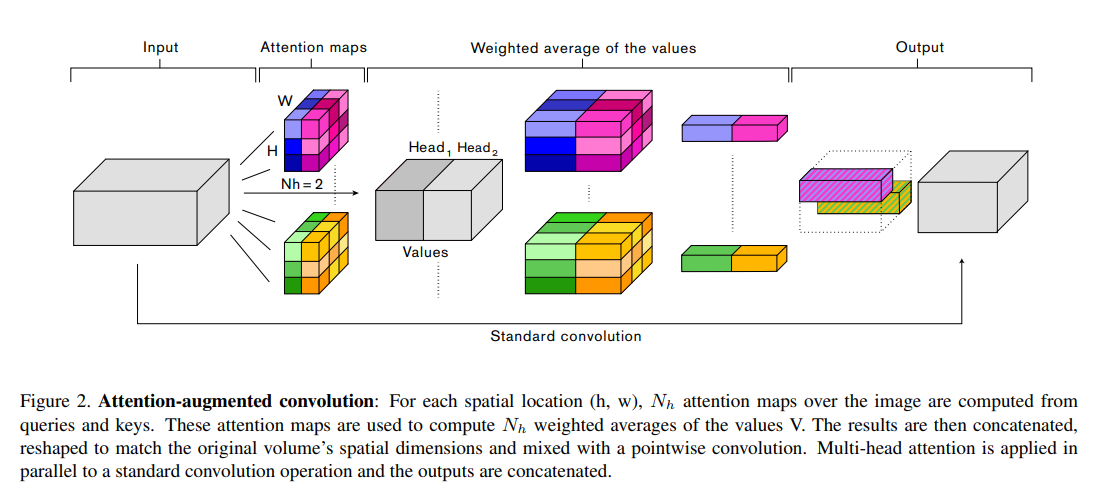
- CNN의 output에 self-attention을 추가적으로 적용하는 연구들
- Object Detection(Relation Networks)
- video processing(Non-local neural networks)
- image classification(Token-based image representation)
- unsupervised object discovery
- unified text-vision tasks
- e.t.c.
*저자들의 모델과 유사한 최근의 모델은 image GPT입니다.
imageGPT(iGPT)는 이미지의 해상도와 색상 차원을 낮춘 뒤 트랜스포머를 픽셀에 적용한 모델입니다.
해당 모델은 생성모델로서 비지도학습을 통해 학습되며, 이를 통해 도출된 representation은 좋은 이미지 분류 성능을 위해 fine-tuning되거나 linearly probed될 수 있습니다.
이 또한 Self-supervised Learning입니다.
largers scale dataset에 대해
본 모델은 모델 구조 자체에도 의의가 있지만, 저자들은 large scale datasets에 대한 강조도 많이 하고 있습니다.
지금껏 CNN에 관해서는 데이터 셋과 CNN의 성능 사이의 관계에 대해 다룬 연구가 많았고, 특히 ImageNet-21k, JFT-300M와 같은 large scale datasets를 이용해 전이학습시킨 CNN의 연구도 있었습니다.
위의 데이터셋에 관한 연구들로부터 영향을 받아, 저자들은 기존의 ResNet-based model(CNNs)에 대한 연구 외에, 저자들이 제안한 ViT에 대한 large scale dataset transfer learning에 대한 부분에 관심을 두고 연구를 진행했습니다.
3. METHOD
ViT는 original Transformer(Attention is all you need 중)의 구조를 대부분 따릅니다.
물론 완벽히 동일한 아키텍처를 구축할 수는 없겠지만, 최대한 기존 transformer와 가깝게하려고 한 이유는 NLP Transformer의 확장성(scalability)과 효율적인 implementations을 가능하게 하기 위함입니다.
3.1. Vision Transformer(ViT)
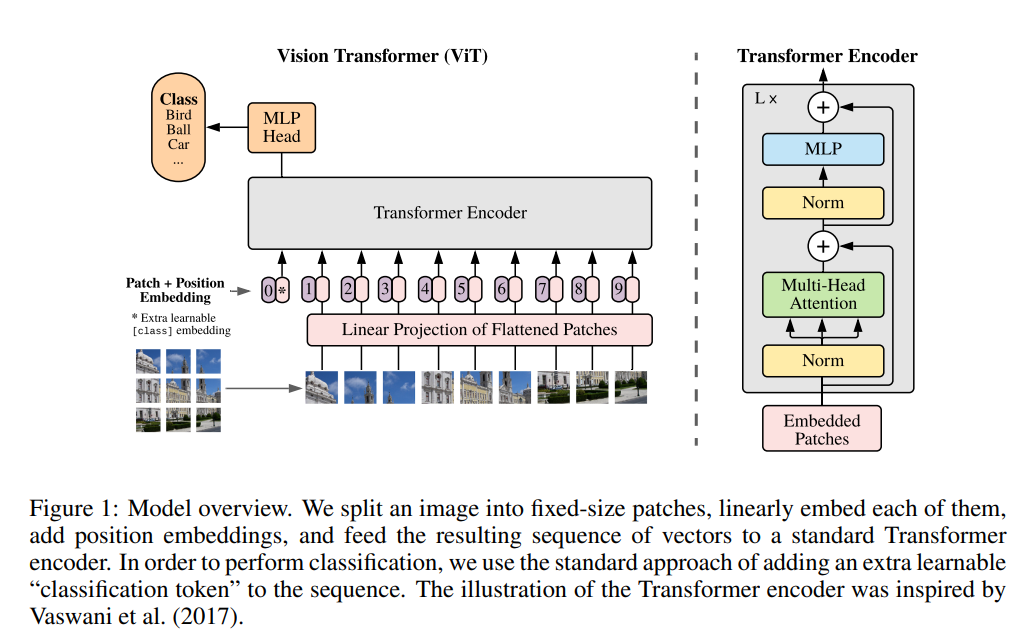
위에서 말했다시피 기본적인 구조는 standard Transformer와 동일합니다.
아키텍처를 조금씩 떼어서 보도록 하겠습니다.
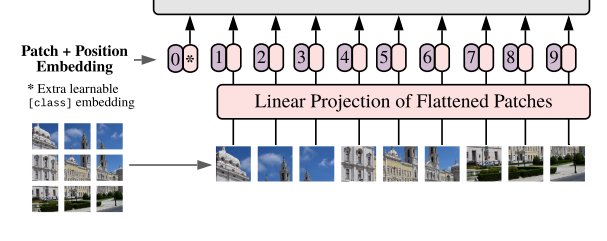
ViT는, standard transformer와 다르게 2d image를 다뤄야하기 때문에 input에 해당하는 위치에서 아래와 같은 작업을 추가적으로 수행해줍니다.
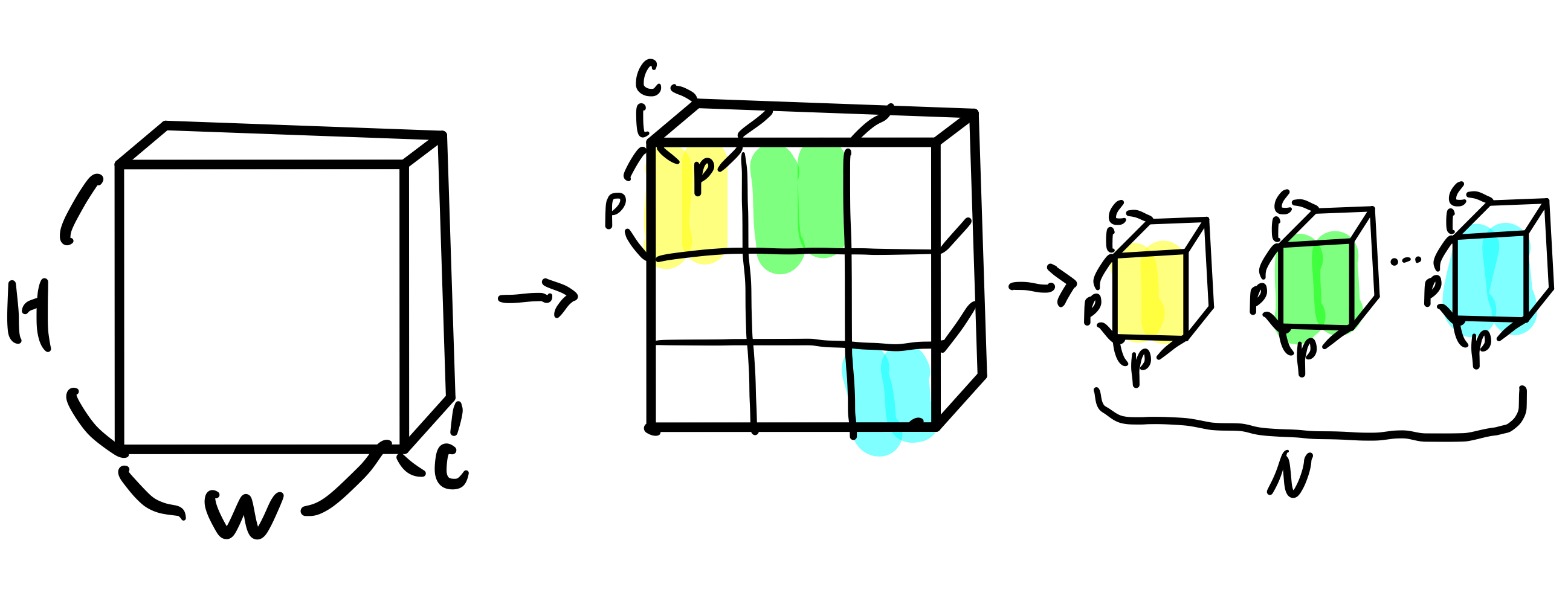
(reshape)
- 크기의 이미지 를 크기의 flattened 2D patches 로 reshape해줍니다.
- : 원본 이미지의 해상도
- : 채널 개수
- : 각 image patch의 해상도
- : reshape 결과 나오게 되는 image patches의 개수
위의 결과를 통해 각 token이 차원의 latent vector를 갖는, 길이 의 효율적인 input sequence(tokens)를 형성할 수 있게 됩니다.
그림을 보면 간단합니다.
참고 : https://baekyeongmin.github.io/paper-review/vision-transformer-review/
하지만, standard transformation에서는 input sequence(그리고 트랜스포머 내에 계속해 전달되는 query)들은 차원의 latent vector를 가집니다.
(projection)
2. 그래서, 위에서 말한 차원의 이미지 패치를 차원으로 매핑시키는 linear projection과정을 추가해줍니다.
-
이 때 나온 output을 patch embeddings라 합니다.
-

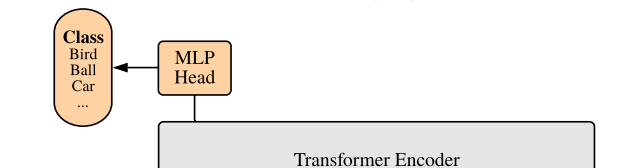
(class embeddings)
또한, 위의 과정을 거쳐 얻은 embeded patches의 좌측에 BERT와 유사하게 학습할 수 있는 [class] embedding을 추가해줍니다.(즉, ).
이 임베딩은 트랜스포머 인코더의 아웃풋 에서 결국 이미지 label 를 반환하는 역할을 합니다(예측이니 이 조금 더 낫겠죠).
classification head
pre-training / fine-tuning 동안에는 classification head가 에 추가로 붙습니다.
- pre-training : MLP with one hidden layer
- fine-tuning : MLP with no hidden layer(only single linear layer)
fine-tuning에서는 과적합을 더욱 조심해야 하기 때문에 모델을 좀 간결하게 해주는 것이라 이해할 수 있습니다.
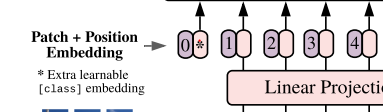
(Positional embeddings)
저자들은 원래 이미지에 맞게 positional embedding도 2D-aware position embeddings(논문 내 APPENDIX)을 사용하려 했으나 성능 향상이 보이지 않아 그냥 standard learnable 1D position을 사용합니다.
즉, Positional embeddings은 patch embeddings과 더해져 트랜스포머 input으로 작동하게 됩니다.
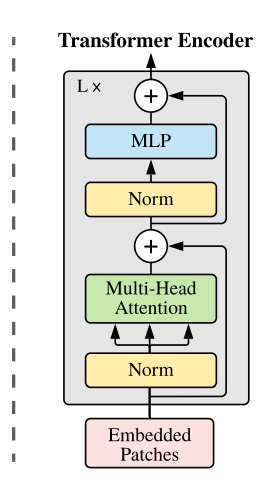
(Multi-head Attention)
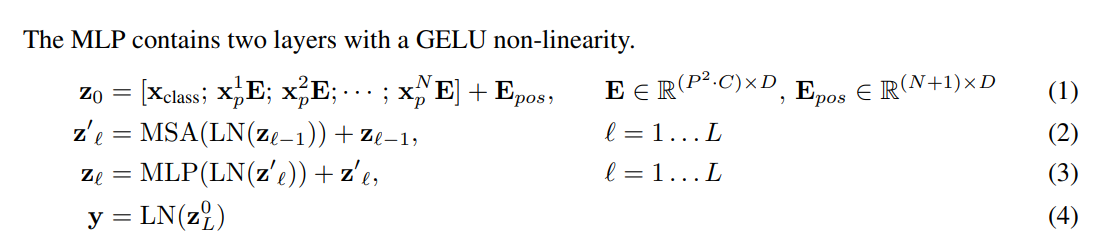
Inductive bias
3.2. Fine-Tuning And Higher Resolution
사실 개인적으로 중요하다고 생각하는 파트입니다. NLP의 성공을 표방하는 만큼요.
저자들 또한 NLP에서 했던 것처럼 ViT를 large dataset에 pre-trained한 다음, down stream tasks에 fine-tuning을 진행합니다.
이런 down stream task에 적용하기 위해서 pre-train 할 때에 prediction head를 없애고, 의 feed forward layer로 변경을 합니다.
이 때 는 downstream task의 class 개수입니다.
다만, 이는 pre-trained할 때의 이미지 해상도보다, 고해상도로 down-stream task에 fine-tuning할 때 효과적입니다.
고해상도 이미지를 사용할 때에는 pre-trained 단계에서 사용했던 patch size와 동일한 size를 사용해 더 긴 sequence length를 사용하게 됩니다.
단, pre-train 단계에서 학습시켰던 positional embedding은 효과가 없어지기 때문에 길이에 맞춰 2D interpolation을 진행한다는 점이 약간 다릅니다.
이 과정에서 해상도(resolution)을 조정하고 패치(patch)를 추출하는 과정이 유일하게(유이하게) Vision Transformer에서 inductive bias가 수동으로 주입되는 부분입니다.
4. Experiments
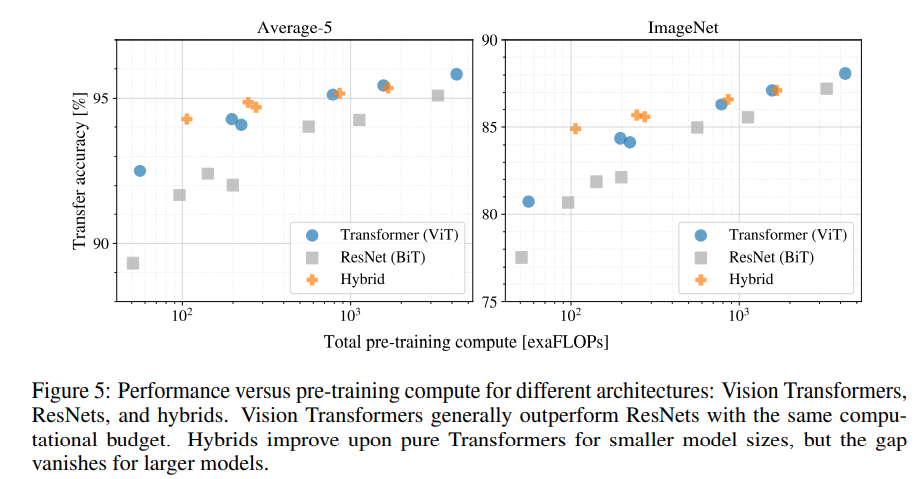
저자들은 본 단락에서 Resnet, ViT, 그리고 혼합 모델에 대한 representation learning 능력을 평가합니다.
Self-supervised learning in Computer Vision(본 블로그)에서 간략하게 다뤘듯이, Self-supervised Learning 기법들은 pre-train할 dataset의 representation을 잘 배우는 것을 목표로 합니다. 다양한 down-stream task에 잘 적용될 수 있도록 large-scale dataset의 기본적인 표현들을 학습하는 거죠.
저자들은 각 모델이 데이터를 얼마나 필요로 하는지 이해하기 위해, 많은 벤치마크 태스크들을 평가하고 다양한 사이즈의 dataset에 대해 pre-train 시켰다고 합니다.
결과적으로, 연산량에 관해서는 ViT가 더욱 낮은 cost로 대부분의 recognition benchmark에서 state of the art를 기록했다고 합니다.
그 후 저자들은 self-supervision을 활용해 약간의 실험을 진행했는데, self-supervised ViT가 미래의 주축 모델이 될 가능성을 가지고 있다는 것을 보여줬다고 합니다.
4.1. Setup
Dataset
저자들은 아래와 같은 large-scael dataset에 pre-trained 한 다음,
- ILSVRC-2012 ImageNet dataset (1.3M images)
- ImageNet-21k(14M images)
- JFT(303M images)
pre-trained 한 모델들을 아래와 같은 벤치마크 task에 transfer했습니다.
- ImageNet(오리지널 validation 라벨과 cleaned-up ReaL 라벨)
- CIFAR-10/100
- Oxford-IIIT Pets
- Oxford Flowers-102
특히, downstream task의 test set에 관해서는 pre-training dataset과 중복되지 않도록(?) 제거했다고 합니다.
(We de-duplicate the pre-training datasets w.r.t. the test sets of the
downstream tasks following Kolesnikov et al. (2020).)
전처리 또한 위의 Kolesnikov et al(2020)의 연구를 참고했습니다.
특히, 19-task VTAB classification suite에도 실험을 했는데, 이 데이터셋은 대표적으로 적은 데이터를 이용한 전이학습을 평가하기 위해 쓰이곤 합니다.
- Natural - Pets, CIFAR, etc.
- Specialized - medicla, satellite imagery
- Structured - geometric..
(VTAB의 테마들)
Model Variants
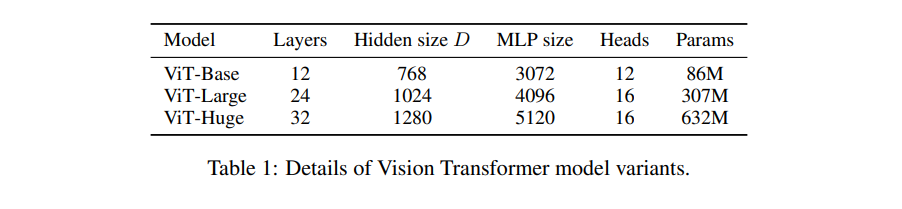
Training & Fine-tuning
- Optimizer : Adam 고정()
- (high)weight decay : 0.1
- linear learning rate warmup and decay(Appendix B.1.1.)
원래 SGD가 Adam보다 Resnet에는 잘 작동한다는 상식이 있었는데, 저자들의 환경에서는 Adam이 더 좋았다고 합니다
Fine-tuning
- SGD(with momentum)
- higher resolution finetuning(512 or 518)
- Polyak & Juditsky averaging(with factor of 0.9999)
Metrics
저자들은 downstream dataset에 대해 아래와 같은 메트릭을 사용했습니다.
-
few-shot accuracy
- training images의 subset에 대한 (frozen) representation을 에 매핑하는, 최소제곱회귀문제
- closed form으로 구할 수 있어서, 간혹 fine-tuning accuracy의 연산량이 부담될 때만 사용했음.
-
fine-tuning accuracy
- 각 dataset에 fine-tuning한 다음 모델의 성능
4.2. Comparison to State of The Art
저자들의 모델은 ViT-H/14, ViT-L/16입니다.
기존의 Sota는 CNNs기반 모델이 잡고 있었는데, 비교 모델들의 포인트는 아래와 같습니다. -
Big Transfer (BiT) : large ResNet을 이용해 supervised transfer learning 수행
-
Noisy Student : large EfficientNet을 이용해 semi-supervised learning 수행(ImageNet과 라벨이 지워진 JFT-300M 데이터셋)
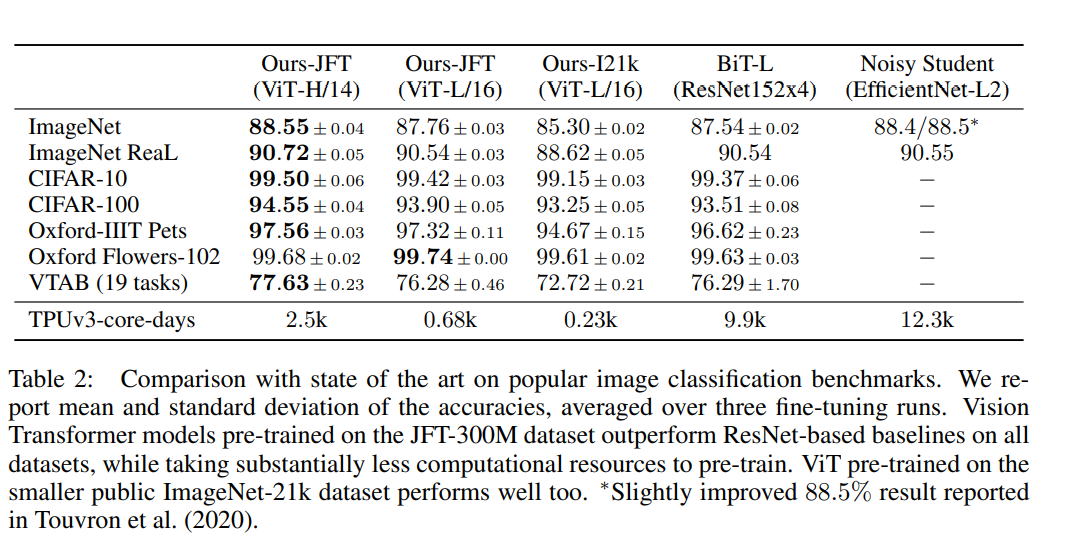
(성능은 fine-tuning 기준입니다)그 결과, JFT-300M dataset에 사전학습시킨 ViT-L/16은 동일한 데이터 셋에 사전학습시킨 BiT-L보다 성능은 좋았고, 연산량은 압도적으로 낮았습니다.
마찬가지로 더 큰 모델인 ViT-H/14도 성능을 일반적으로 높혔습니다.물론 연산 효율성은 아키텍처 뿐만 아니라 training schedule, optimizer, weight decay 등에도 용향을 받긴 합니다.
또한, JFT-300M같은 대용량 데이터는 성능이 좋았지만, 약간 작은 데이터 셋인 I21k : ImageNet-21k dataset에 사전학습 시켰을 때에는 성능이 약간 떨어졌습니다.
(학습 시간을 비교했을 때 충분히 좋은 성능이긴 합니다)위 데이터셋 중 down-stream fine-tuning task에 특화된 VTAB dataset에 대한 성능 비교를 자세히 나타낸 그림은 아래와 같습니다.
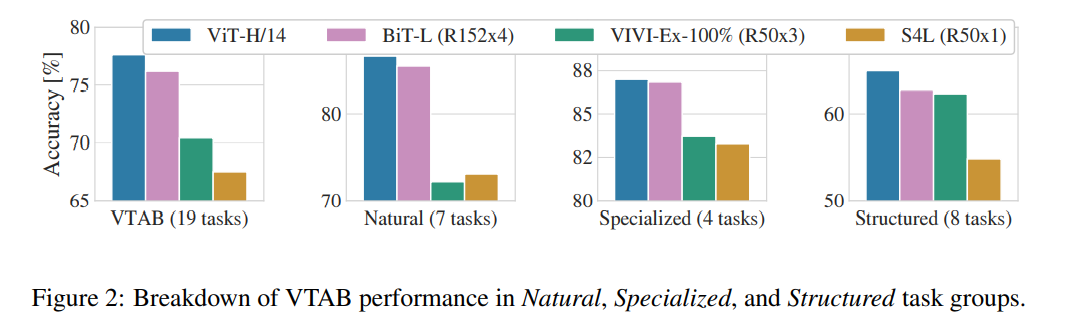
4.3. Pre-Training Data Requirements
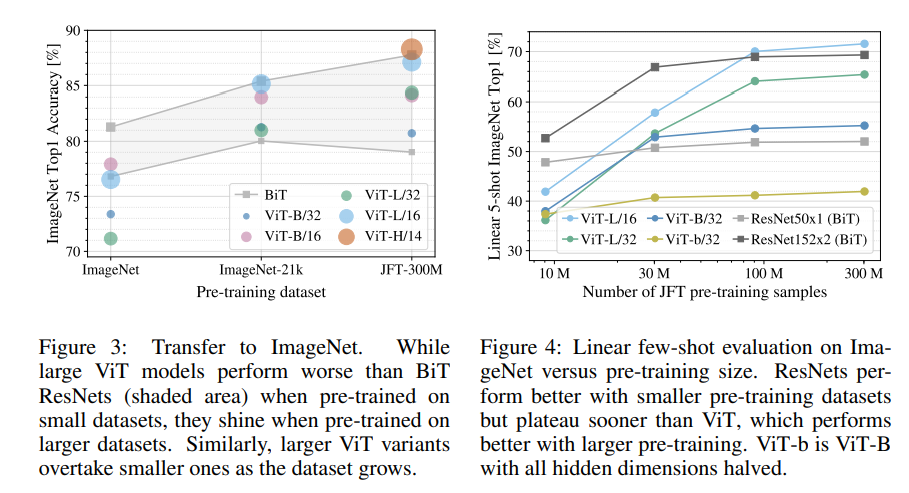
ViT가 CNN 모델들과 가장 다른 점은 바로 낮은 inductive bias를 가진다는 것입니다.
그렇기 때문에 ViT는 데이터가 비교적 적어도 높은 indutive bias로 dataset의 표현을 잘 배우는 CNN보다 데이터가 더 많이 필요합니다.
본 단락에서는 트랜스포머 기반 모델을 활용하기 위해 데이터가 얼마나 더 필요할지에 대한 얘기를 다룹니다.
작은 데이터 셋의 성능을 높히기 위해 weight decay, dropout, label smoothing을 진행했다고 합니다.
아래 그림은 비교적 작은 dataset인 ImageNet에 대해 fine-tuning시킨 결과를 나타냅니다.
4.5. Inspecting Vision Transformer

-
좌측 : ViT의 first layer는 flattened patches를 더욱 낮은 lower-dimenstional space로 project합니다(이에 대해 PCA를 수행한 모습).
-
중앙 : projection 후에 positional embeddings이 더해집니다(이에 대해 임베딩 간 유사도를 계산한 모습).
-
우측 : 이미지 공간에서 평균 거리를, attention weights를 기반으로 나타낸 모습.

- 위 그림처럼 classification에 대해 의미적으로 가까운 image regions에 attend하는 모습을 보여줍니다.
(APPENDIX) D.7 ATTENTION DISTANCE
ViT는 self-attention을 사용해 이미지 간 정보를 통합합니다.
이 과정을 이해하기 위해 다양한 layers들 내에 attention weights를 이용해 span된 average distance를 분석합니다.
이 attention distance는 CNNs내 receptive field와 유사하며, lower layers의 heads 간에 굉장히 가변적입니다.
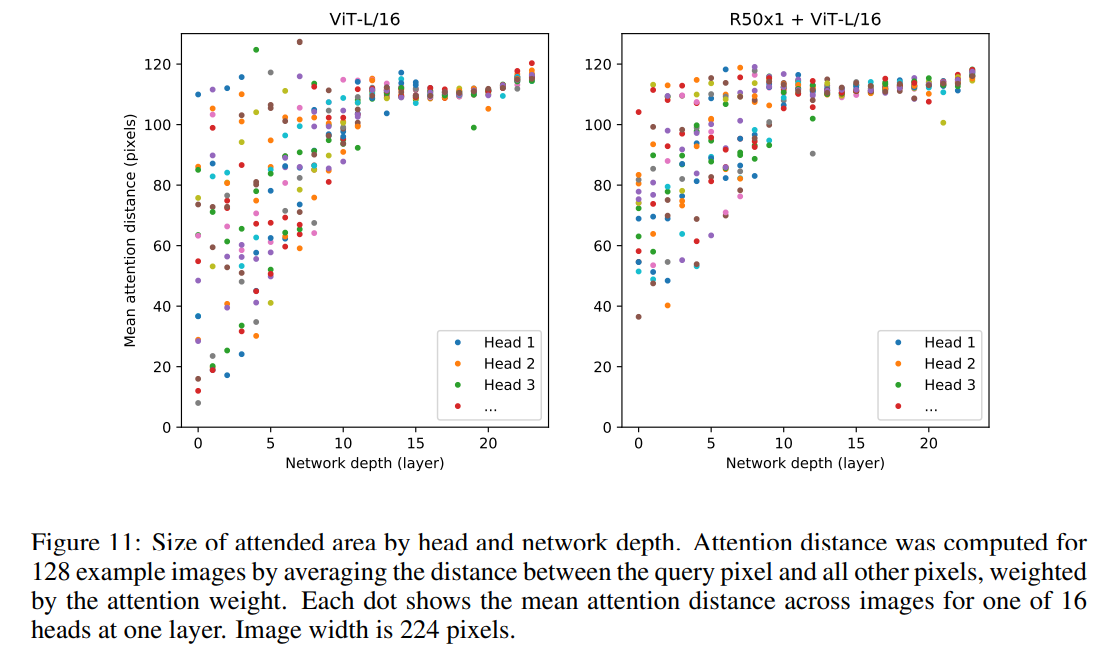
즉, 특정 heads는 image에 넓게 attend하며, 다른 heads는 query location 근처의 영역에 더욱 attend합니다.
또한, depth가 증가할수록, attention distance는 모든 heads를 통해 증가합니다.
네트워크의 second half(깊은 쪽의 레이어 절반)에서는 *대부분의 heads가 대부분의 tokens들 사이에 넓게 attned한 모습을 볼 수 있습니다..
depth 증가한다 layer가 깊어진다.
D.8 ATTENTION MAPS
Attention map을 계산하기 위해서 저자들은 Attention Rollout 방식을 사용했다고 합니다.
간단히, 모든 heads에 대한 ViT-L/16의 attention weights를 평균낸 뒤, 모든 layer의 weight matrix와 재귀적으로 곱해나갑니다.
즉, 모든 layer에 대해 토큰 간 mixing attention을 시각화한 것입니다.

