1. Introduction
이 논문에서는 "AI-complte" task 로 Visual Question Answering 에 대해 소개하고 있습니다.
AI-complete task란?
AI 분야에서 가장 어려운 task, 즉 human-level의 intelligence를 요구하는 task입니다.
(은어같은느낌, 공식적으로 쓰이지 않음)
VQA task는 이미지와 그 이미지에 대한 질문(open-ended, free form - 답하는 사람마다 답이 다를 수 있고 형태가 다양한)이 주어졌을 때 올바른 답변을 만들어내는 task 입니다.
open-ended question에 대답하기 위해서는 다양한 AI 능력이 필요합니다.
- fine-grained recognition
: 이 피자에 있는 치즈가 어떤 종류인가 - commonsense reasoning
: 안경을 쓴 남자가 나온 사진 - 이 남자는 시력이 좋은가 - knowledg base reasoning
: 고기가 있는 피자 사진 - 이 피자는 비건피자인가 - activity recognition, object detection
개인적으로 knowledge base reasoning 과 commensense resoning이 가장 흥미로웠습니다. 이러다가 진짜 인간을 대체할 수도 있겠다는 생각
특히 이 능력을 강화하려면 모델 구조를 바꿔야 하는지, 단순히 데이터만 늘리면 되는지가 궁금했습니다.
논문에서도 높은 수준의 추론을 가능하게 하기 위해 COCO 데이터뿐만 아니라 자체적으로 추상적인 데이터를 제작하여 학습에 사용하였습니다.
질문의 형식은 두 가지로 나눌 수 있습니다.
1. open-ended answering (답변의 형태도 다양)
2. multiple-choice task (주어진 선지중에 고르기)
2. Related work
VQA Efforts
이전에도 VQA 관련 연구들이 있었지만 데이터셋이 작고 고정된 단어들로만 만들어진 질문만 고려하였다고 합니다.
본 논문에서는 open-ended, free-form question과 사람이 작성한 답변을 통해 위 문제점을 보완하였습니다.
Text-based Q&A
NLP, test-processing 분야에서 잘 연구되었다고 힙니다.
VQA는 이미지에 기반을 두기 때문에 모델이 text 와 image에 대한 이해가 모두 이해했을 때 정확한 답변이 가능합니다.
Describing Visual Content
image tagging, image captioning, video captioning같이 시각적인 데이터에 설명을 단어나 문장으로 만들어내는 task 와 관련이 있는데요,
캡션은 이미지에 대한 정보가 아니라 비교적 일반적인 경우가 종종 있는 반면 VQA에서는 이미지 특화된 더 자세한 정보가 필요합니다.
3. VQA Dataset Collection

Real Images
MS COCO 데이터를 활용했습니다. 더 다양한 질문을 모으는 것이 중요하기 때문에 여러 개의 객체가 있고 맥락적인 정보를 표함하는 사진들을 모으기 위해 사용했다고 합니다.
Abstract Scenes
단순히 vision task 뿐만 아니라 high-level reasoning도 하기 위해 추상적인 데이터를 만들었습니다.
위 사진에서 맨 아래줄인데, 클립아트를 사용하여 실내인지, 외부인지 표현하였고 다양한 포즈를 연출하기 위해 관절이 꺾여있는 사진도 있습니다.
Captions & Questions
- caption은 image 당 5개씩
MS COCO 데이터는 모든 이미지에 대해 5개의 caption이 있어서 추가로 만든 추상적인 이미지 데이터에 대해서도 caption을 5개씩 만들었습니다. - 적절한 question이 중요합니다.
- low-level computer vision 만으로도 가능한 단순한 질문X
- 장면으로부터 추론할 수 있는 상식이 아니라 그냥 상식만으로 대답할 수 있는 질문 X
사진의 동물이 어떤 울음소리를 내는가 O
콧수염이 무엇으로 만들어 지는가 X
- 총 0.76M 개의 질문 확보
Answers
단답형을 요구하는 질문에 여러 답이 존재할 수 있기 때문에 각 질문에 대해 다른 사람에게 10개의 답을 얻었습니다.
- open-ended task
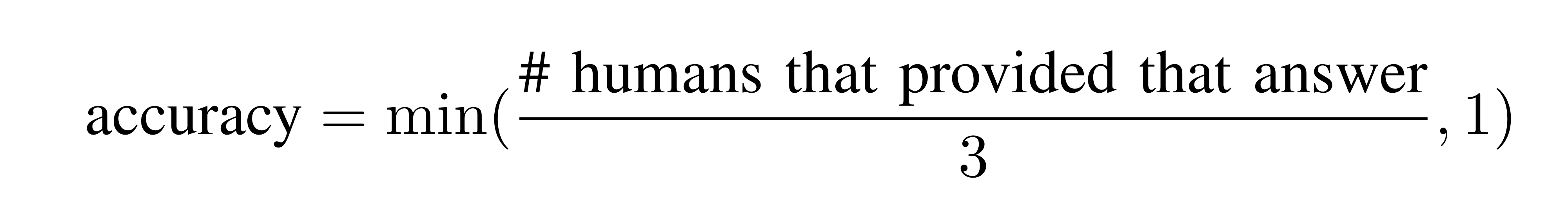
적어도 3명의 답과 같으면 정답으로 간주하는 것입니다. - multiple-choice
18개의 선지로 구성되어있는데 선지는 4종류로 나눌 수 있습니다.- Correct: 정답
- Plausibl: 맞긴 하지만 이미지와는 안맞는 선지
- Popular: yes , no, 2, 1 등 자주 등장하는 선지
- Random: 위의 선지들을 먼저 구성하고 18개가 될 때 까지 데이터셋에서 랜덤하게 고른 선지

4. VQA Data Analysis
위에서 개략적으로 설명한 질문의 길이, 종류, 단어 빈도 등이 자세히 나와있습니다.
| 데이터 | image | question | answer |
|---|---|---|---|
| MS COCO | 20K | 0.6M | 8M |
| abstract scenes | 50k | 150k | 1.9M |
Typical Answers
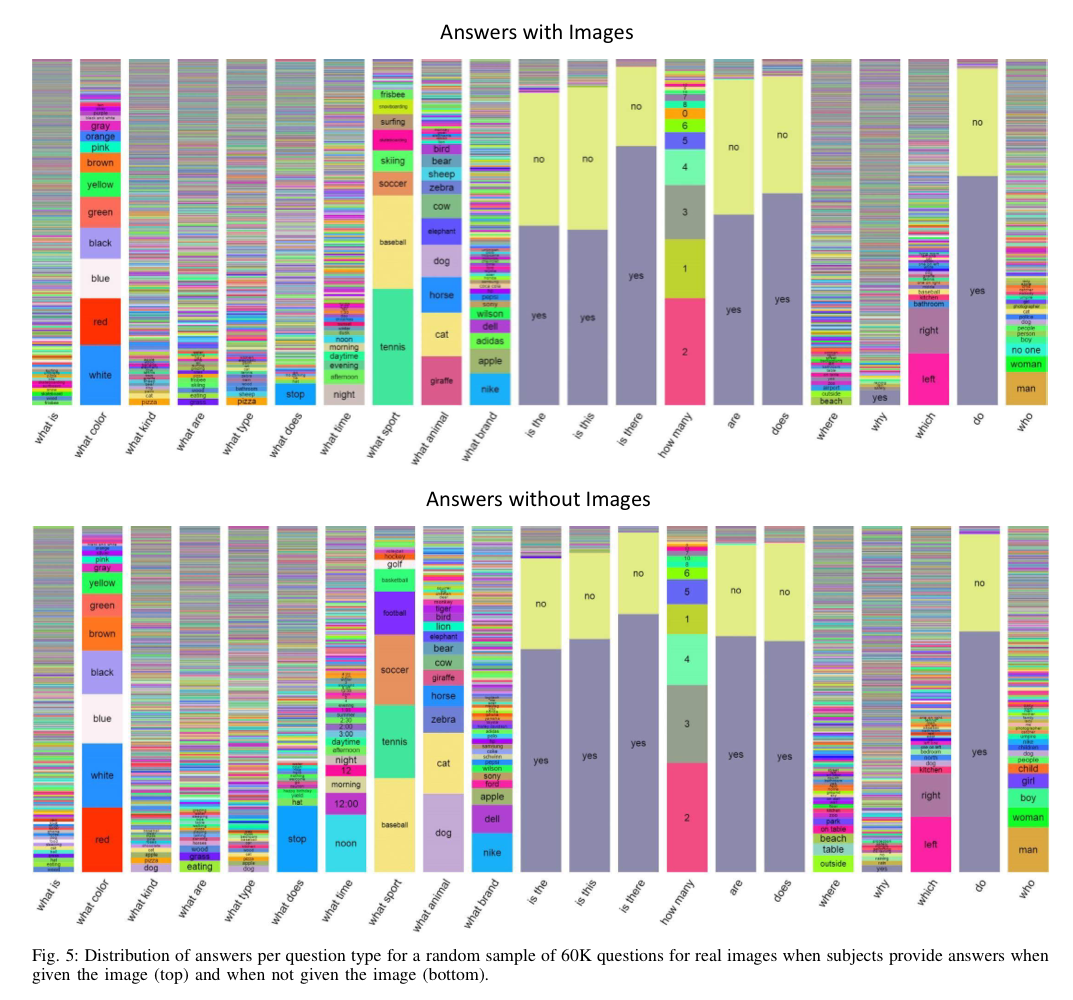
yes/no로 대답할 수 있는 질문에는 "Is the ..." , "Are ...", "Does .." 같은 형태가 많고
다양한 답변이 나올 수 있는 질문에는 "What is ...", "What type..." 같은 질문이 많습니다.
Length
대략 두 데이터 셋의 답변 길이는 비슷합니다.
1단어, 2단어, 3단어 : 90% , 6%, 2.5%
이 외에 데이터에 대한 자세한 설명은 생략하겠습니다.
이미지 없이 QA 할수도 있는데 VQA가 왜 중요한지, Caption과 Question의 차이 등에 대해서도 나와있습니다.
5. VQA Baseline and Methods
Baselines
- random: top 1k 답변 중 랜덤 선택
- prior("yes"): multiple-choices의 답에는 항상 yes가 포함
- per Q-type prior:
open-ended는 최빈값, multiple-choice에서는 코사인 유사도를 통해 이미 고른 선지와 가장 유사한 선지를 선택 - nearest neighbor:유사한 질문의 답변들 중 최빈값 선택
(유사한 질문 고르는 방법은 appendix에)
Method
2-channel vision(image) + language (question) 구조
가능한 output으로 최빈값 1000개의 답변을 만듭니다.(K=1000)
image channel
이미지를 위한 embedding을 제공합니다.
1. I
VGGNet의 마지막 hidden layer의 activations 가 4096-dim image embedding으로 사용됩니다.
2. norm I
VGGNet의 마지막 hidden layer의 l2정규화된 activations 사용
Question Channel
질문을 위한 embedding을 제공합니다.
1. Bag-of-Words-Question(BoW Q)
최빈 단어 1000개 + 30개 => 1030-dim emdedding
질문에서 가장 많이 사용된 단어를 3위까지 10개씩 골라서 30-dim bow 벡터를 만든 후 임베딩 뒤에 concatenate 됩니다.
2. LSTM-Q
하나의 hidden layer가 질문을 위해 1024-dim embedding을 생성하기 사용되었습니다.
질문의 각 단어는 300-dim embedding으로 인코딩되었습니다.
3. deeper LSTM Q
2개의 hidden layer 가 2048-dim embedding을 생성하기 위해 사용되었습니다.LSTM에서 얻은 embedding이 last cell state 와 last hidden state에 concatenate 됩니다.
4. Multi-Layer Perceptron(MLP)
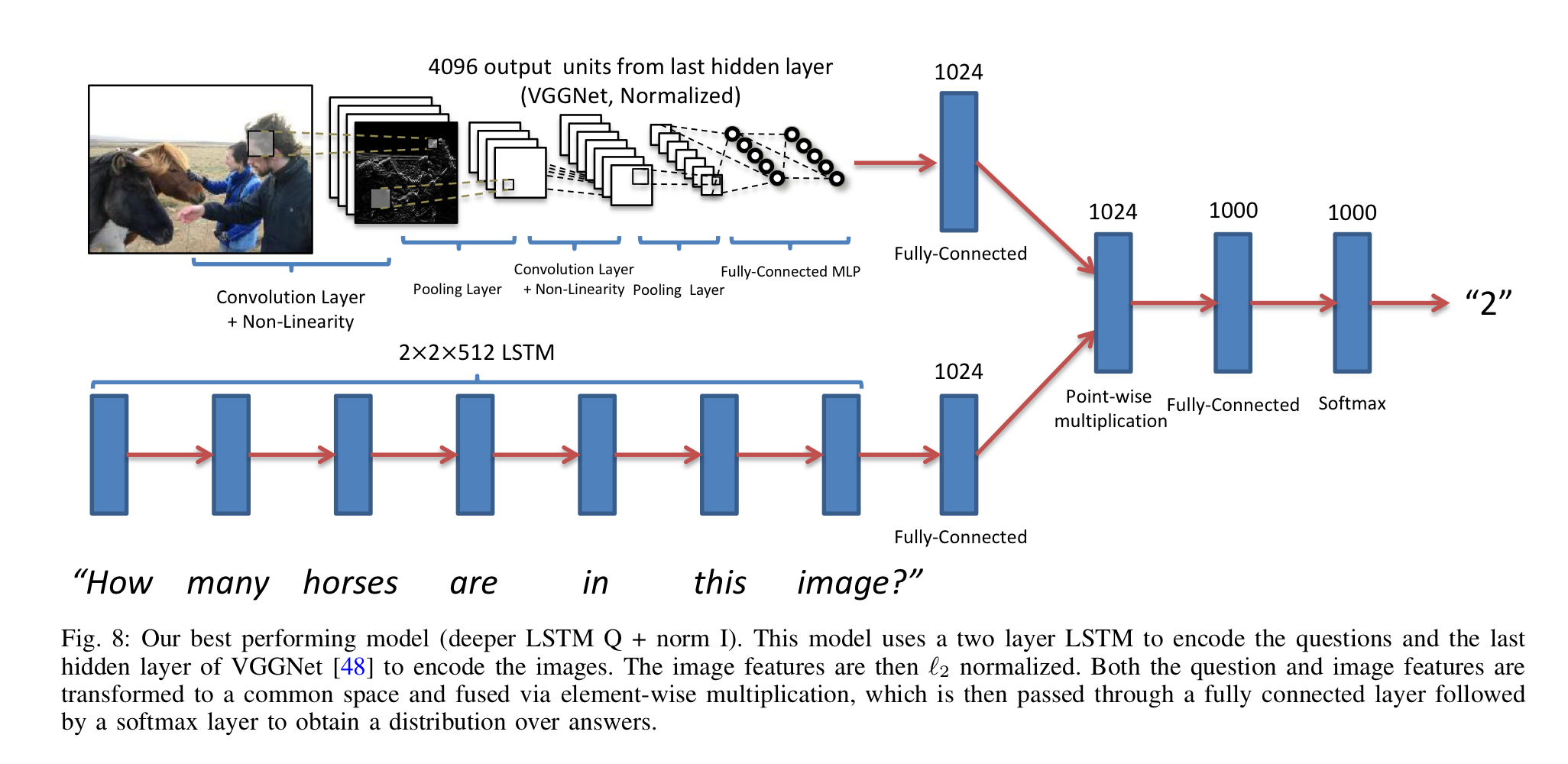
- BoW Q + I : 두 embedding concatenate
- LSTM Q + I , deeper LSTM Q + norm I : image embedding 이 question embedding과 차원을 맞추기 위해 1024-dim으로 변환된 후 LSTM embedding과 element-wise 하게 곱해진다.
Result
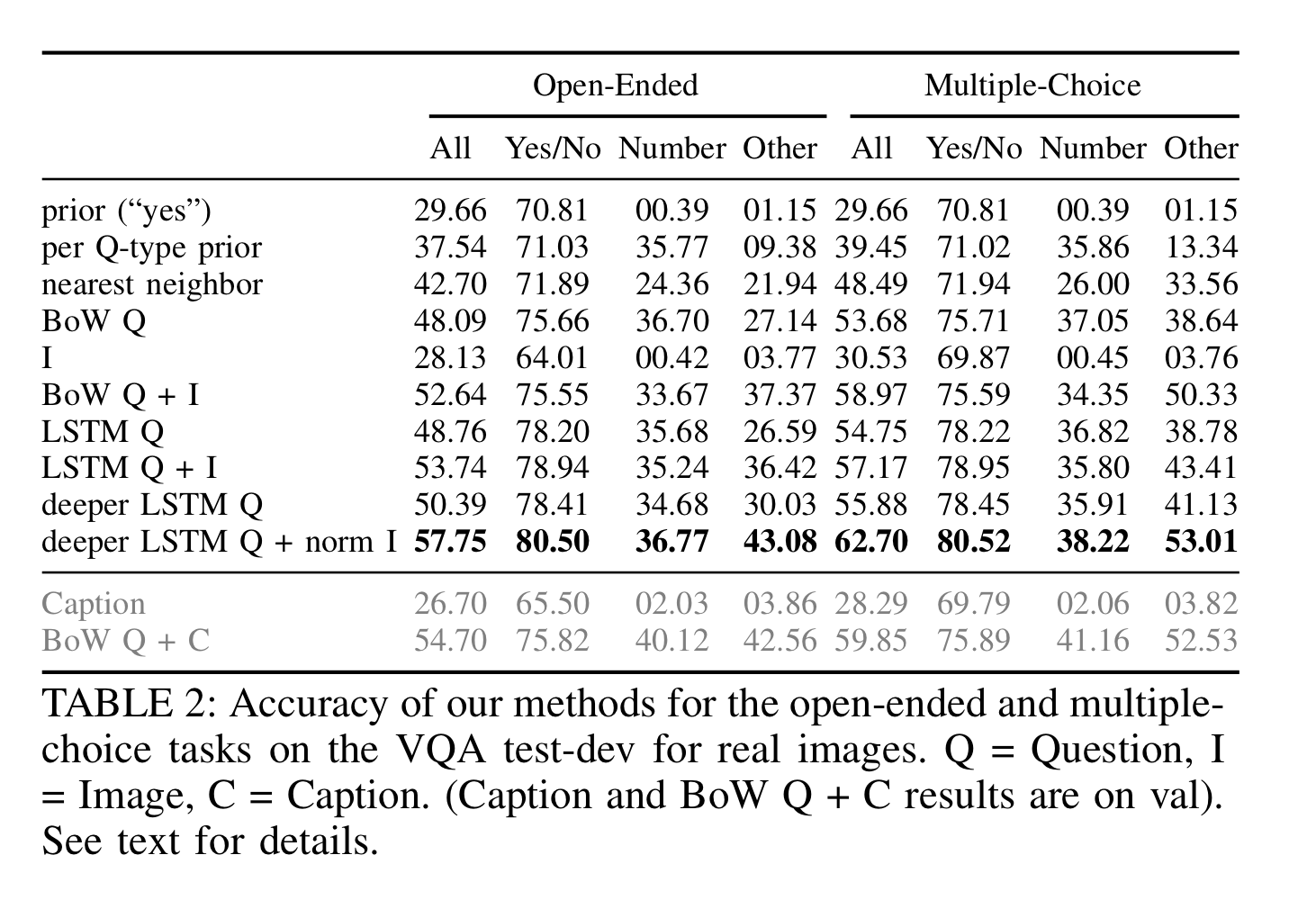
deeper LSTM Q + norm I 를 사용했을 때 가장 정확도가 높았지만 어떤 모델을 사용해도 사람보다는 정확도가 현저히 낮은 것을 알 수 있습니다.
전반적으로 open-ended 보다 multiple-choice task에 대해 정확도가 더 높았습니다.
