
🤔 머신러닝
영상 처리, 번역기, 음성 인식, 스팸 메일 탐지 등 굉장히 많은 분야에서 응용되는 중이다. 특히 머신 러닝의 한 갈래인 딥 러닝은 자연어 처리 엔지니어에게 필수 역량이다.
머신러닝의 방식
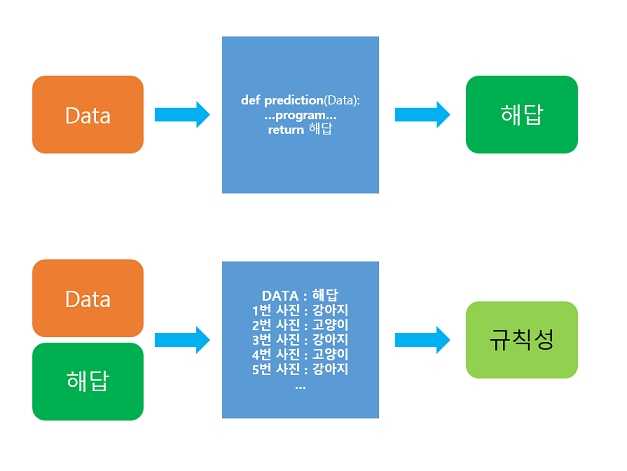
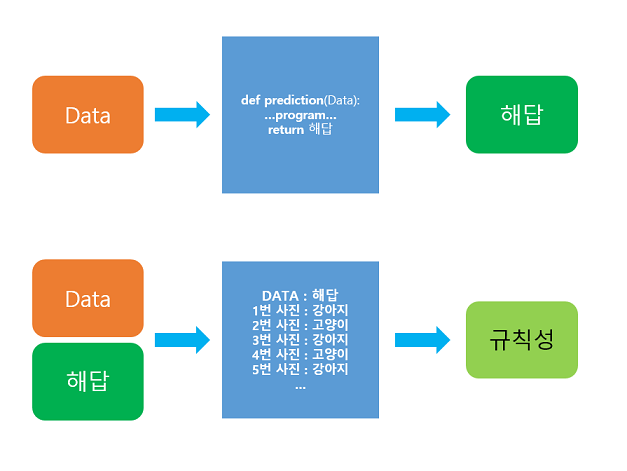
- 위쪽은 기존의 프로그래밍 접근 방식
- 아래쪽은 머신 러닝의 접근 방식
머신 러닝은 데이터가 주어지면, 기계가 스스로 데이터로부터 훈련성을 찾는 것에 집중한다. 주어진 데이터로부터 규칙성을 찾는 과정을 훈련(training) 또는 학습(learning)이라고 한다.
훑어보기

머신 러닝을 위한 데이터: 훈련용 검증용 테스트용
- 훈련: 머신 러닝 모델 학습
- 테스트: 머신 러닝 모델의 성능 평가
- 검증: 과적합이 되고 있는지 판단하거나 하이퍼파라미터의 조정을 위한 용도
- 하이퍼파라미터(초매개변수): 모델의 성능에 영향을 주는 사람이 값을 지정하는 변수
- 매개변수: 가중치와 편향. 학습을 하는 동안 값이 계속 변하는 수
1. 분류(Classification)와 회귀(Regression)
머신 러닝의 많은 문제는 분류 또는 회귀 문제에 속한다.
회귀
- 선형 회귀(Lineare Regression)
- 로지스틱 회귀(Logistic Regression)
분류
- 이진 분류(Binary Classification)
- 다중 클래스 분류(Multi-lable Classification)
- 다중 레이블 분류(Multi-lable Classification)
1) 이진 분류 문제(Binary Classification)
다중 클래스 분류는 주어진 입력에 대해서 세 개 이상의 선택지 중에서 답을 선택해야 하는 경우를 말한다.
- 합/불을 판단하는 문제, 메일을 보고 정상메일, 스팸 메일인지 판단하는 문제
2) 다중 클래스 분류(Multi-class Classification)
다중 클래스 분류는 주어진 입력에 대해서 세 개 이상의 선택지 중에서 답을 선택해야 하는 경우를 말한다.
- 새 책이 입고되었을 때, 다섯 개의 분야의 책장 중에서 적절한 분야에 책을 넣는 문제
3) 회귀 문제(Regression)
회귀 문제는 어떠한 연속적인 값의 범위 내에서 예측값이 나오는 경우를 말한다.
- 역과의 거리, 인구 밀도, 방의 개수를 입력하면 부동산 가격을 예측하는 머신 러닝 모델이 있다고 했을 때, 특정 값의 범위 내에서 어떤 숫자도 나올 수 있는 문제
- 시계열 데이터(Time Series Data)를 이용한 주가 예측, 생산량 예측, 지수 예측 등이 있다.
2. 지도 학습과 비지도 학습
1) 지도 학습(Supervised Learning)
레이블(Lable)이라는 정답과 함께 학습하는 것(자연어 처리는 대부분 지도 학습에 속한다)
레이블이라는 말 이외에도 y, 실제값 등으로 부르기도 한다.
기계는 예측값과 실제값의 차이인 오차를 줄이는 방식으로 학습을 하게 되는데 예측값을 ^y과 같이 표현하기도 한다.
2) 비지도 학습(Unsupervised Learing)
별도의 레이블 없이 학습하는 것을 말한다.
3) 자기지도 학습(Self-Supervised Learning, SSL)
레이블이 없는 데이터가 주어지면, 모델이 학습을 위해서 스스로 데이터로부터 레이블을 만들어서 학습하는 경우
3. 샘플(Semple)과 특성(Feature)
많은 머신 러닝 문제는 1개 이상의 독립 변수x를 가지고 종속 변수y를 예측하는 문제다.
인공 신경망은 독립 변수, 종속 변수, 가중치, 편향 등을 행렬 연산을 통해 연산하는 경우가 많다. 앞으로 인공 신경망을 배우게되면 훈련 데이터를 행렬로 표현하는 경우를 많이 보게 된다.
- 독립 변수 x의 행렬을 X라고 하였을 때, 독립 변수의 개수가 n개이고 데이터의 개수가 m인 행렬 X는 다음과 같다
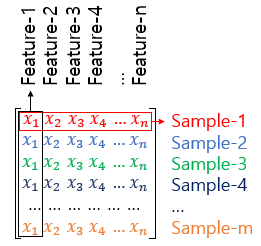
이때 머신 러닝에서는 하나의 데이터. 행렬 관점에서는 하나의 행을 샘플(Sample)이라고 부른다. 그리고 종속 변수 y를 예측하기 위한 각각의 독립 변수 x를 특성(Feature)이라고 부른다. 행렬의 관점에서는 각 열에 해당된다.
4. 혼동 행렬(Confusion Matrix)
- 맞춘 문제수를 전체 문제수로 나눈 값을
정확도(Accuracy)라고 한다. - 정확도는 맞춘 결과에 대한 세부적인 내용을 알려주지 않기 때문에
혼동 행렬(Confusion Matrix)를 사용한다.
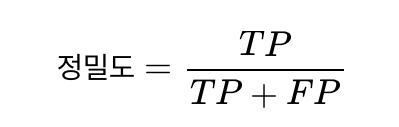
- True Positive(TP) : 실제 참인 정답을 참이라 예측 (정답)
- False Positive(FP) : 실제 거짓인 정답을 참이라고 예측 (오답)
- False Negative(FN) : 실제 참인 정답을 거짓이라고 예측 (오답)
- True Negative(TN) : 실제 거짓인 정답을 거짓이라고 예측 (정답)
이 개념을 사용하면 정밀도(Precision)와 재현율(Recall)이 된다.
1) 정밀도(Precision)
모델이 True라고 분류한 것 중에서 실제 True인 것의 비율
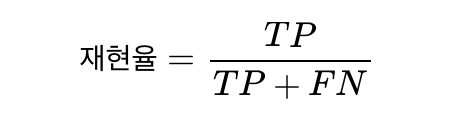
2) 재현율(Recall)
실제 True인 것 중에서 모델이 True라고 예측한 것의 비율
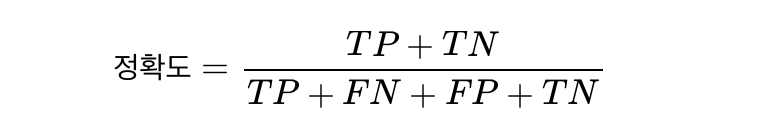
😳 정밀도나 재현율은 모두 실제 Ture인 정답에 모델이 True라고 예측한 경우, 즉 TP에 관심이 있다. 두식 모두 분자가 TP임에 주목해야한다.
3) 정확도(Accuaracy)
전체 예측한 데이터 중에서 정답을 맞춘 것에 대한 비율
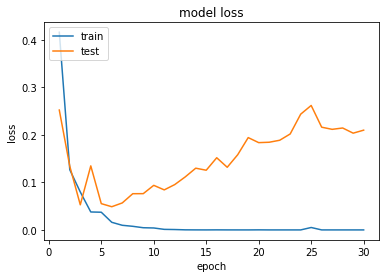
5. 과적합(Overfitting)과 과소 적합(Underfitting)
훈련 데이터를 과하게 학습한 경우
훈련 데이터에 대해서만 과하게 학습하면 성능 측정을 위한 데이터인 테스트 데이터나 실제 서비스에서 정확도가 좋지 않은 현상이 발생한다

과소적합(Underfitting)
훈련 자체를 너무 적게한 상태: 훈련 자체를 너무 적게한 상태
훈련 데이터에 대해서도 정확도가 낮다.
적합(Fitting)과정
적합 과정을 거쳐서 모델이 주어진 데이터에 대해서 적합하도록...
