Cache Stampede란
"상영 중인 영화 조회" API에 Redis 기반 캐시를 적용하면서, 대표적인 캐시 문제인 Cache Stampede를 경험했다. Cache Stampede는 캐시가 만료되는 시점에 다수의 요청이 DB로 집중되어 시스템 부하가 일시적으로 급격히 증가하는 현상을 말한다.
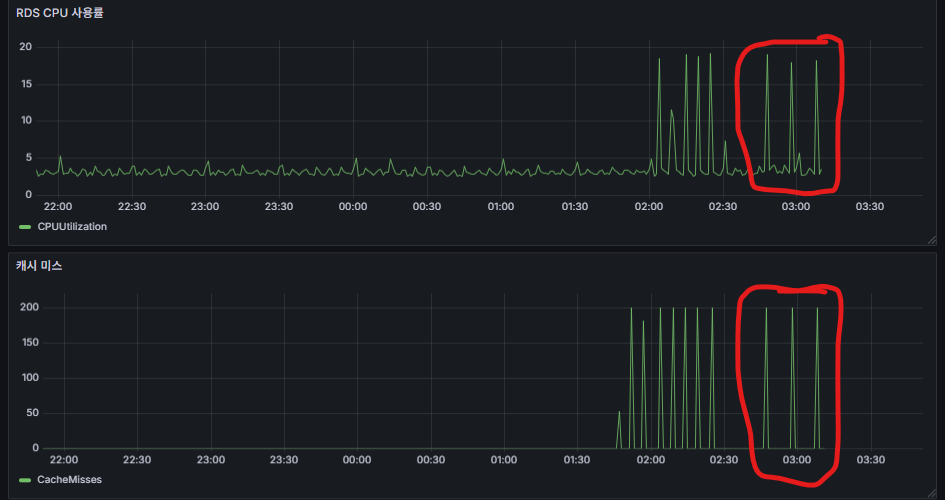
TTL이 만료된 시점에 RDS CPU 사용률이 급격히 치솟는 것을 확인할 수 있다.
Cache Stampede 해결책
1. 주기적 갱신 (Pre-warming)
캐시가 만료되기 전에 백그라운드에서 주기적으로 데이터를 갱신한다. Spring에서는 @Scheduled를 활용하거나 별도의 배치 서버를 통해 구현할 수 있다.
-
장점 : 응답 지연 없이 높은 캐시 적중률 유지가 가능하다.
-
단점 : 별도의 배치 인프라가 필요하고, 갱신 주기를 정하기가 까다롭다.
2. 락 사용 (Mutual Exclusion)
캐시 미스 시 첫 번째 요청자만 DB에 접근하고, 나머지는 락 해제까지 대기한다. Redis의 분산 락을 활용해 구현할 수 있다.
-
장점 : 동시 다발적인 DB 접근을 막아 단일 요청만 처리하므로 DB 부하를 효과적으로 줄일 수 있다.
-
단점 : 락을 획득하지 못한 요청은 대기해야 하므로 응답 지연 가능성이 존재한다.
3. PER 알고리즘
PER(Probabilistic Early Recomputation)은 2015년 VLDB 컨퍼런스에 소개된 Cache Stampede를 방지하기 위한 알고리즘이다. PER 알고리즘은 데이터가 캐시에서 만료되기 전에 확률적으로 미리 재연산함으로써, 동시에 여러 요청이 DB에 접근하는 상황을 방지한다.
-
장점 : 별도의 배치 작업이나 락이 필요없고 사용자 응답 지연이 발생하지 않는다.
-
단점 : TTL이 남았음에도 확률적으로 갱신하므로, 불필요한 DB 접근이 발생할 수 있다.
PER 알고리즘으로 문제 해결
나는 주기적 갱신, 락 사용에 대한 단점이 크다고 생각해 PER 알고리즘을 선택했다.
Pseudo Code
function x-fetch(key, ttl, beta=1) {
value, delta, expiry ← cache_read(key)
if (!value || (currentTime() - delta * beta * log(rand(0,1))) ≥ expiry) {
start ← currentTime()
value ← recompute_value()
delta ← currentTime() – start
cache_write(key, (value, delta), ttl)
}
return value
}
value: 캐싱 된 데이터 값
delta: 이전 재계산(recompute)에 소요된 시간
expiry: 캐시 만료 시각
beta: 확률 조절 파라미터로써 beta 값을 높이면 캐시 갱신이 더 자주 일어남(default=1.0)
-
먼저 캐시에서 해당 키(key)에 대한 데이터를 조회한다. 이때 데이터는 (value, delta, expiry)로 구성되어 있다.
-
만약 value가 없거나 아래 수식을 만족하면 캐시 갱신이 필요한 상태로 판단하여 새 값을 가져온다.
(currentTime() - delta * beta * log(rand(0,1))) ≥ expiry해당 수식을 간단히 설명하자면, 현재 시각이 만료 시점에 가까워질수록, 이전 재계산 시간이 길수록, beta 값이 클수록 캐시를 조기에 갱신할 확률이 높아진다.
-
캐시에 새롭게 갱신된 value, delta, ttl을 기록해준다.
로직
기존에는 @Cacheable을 사용해 캐시를 간편하게 적용했지만, PER 알고리즘은 확률 기반 갱신 로직과 TTL, delta 계산이 필요하기 때문에 별도의 로직이 필요하다. 이를 위해 PerCacheService를 직접 구현했으며, Redis에 Lua Script를 활용해 캐시 조회 및 갱신을 원자적으로 처리하도록 구성했다.
참고로 Lua Script를 사용하면 다음과 같은 이점이 있다.
- 여러 Redis 명령을 Redis 측에서 원자적으로 실행할 수 있어 Race Condition 방지
- 클라이언트 ↔ Redis 간 네트워크 왕복을 단 1회로 줄임
PerCacheService
public T get(String key, Supplier<T> recompute, TypeReference<T> typeRef, int ttlMillis) throws JsonProcessingException {
String deltaKey = key + ":delta";
List<Object> result = redisTemplate.execute(getScript, List.of(key, deltaKey));
Object deltaObject = result.get(1);
String cachedJson = String.valueOf(result.get(0));
Long delta = deltaObject==null ? null : Long.parseLong(deltaObject.toString());
Long ttl = ((Number) result.get(2)).longValue();
if(cachedJson == null || delta == null || ttl == null || -1 * delta * BETA * Math.log(Math.random())>=ttl){
long start = System.currentTimeMillis();
T recomputed = recompute.get();
long recomputationTime = System.currentTimeMillis() - start;
List<String> keys = List.of(key, deltaKey);
String json = objectMapper.writeValueAsString(recomputed);
String deltaString = String.valueOf(recomputationTime);
String ttlString = String.valueOf(ttlMillis);
redisTemplate.execute(setScript, keys, json, deltaString, ttlString);
return recomputed;
}
return objectMapper.readValue(cachedJson, typeRef);
}per_get.lua
local valueAndDelta = redis.call('mget', KEYS[1], KEYS[2])
local ttl = redis.call('pttl', KEYS[1])
-- 평탄화된 리스트로 반환
return { valueAndDelta[1], valueAndDelta[2], ttl }per_set.lua
local ttl = tonumber(ARGV[3])
redis.call('mset', KEYS[1], ARGV[1], KEYS[2], ARGV[2])
redis.call('pexpire', KEYS[1], ttl)
redis.call('pexpire', KEYS[2], ttl)
return 1결과
테스트 환경
| 항목 | 스펙 |
|---|---|
| EC2 | t3.small (2vCPU, 2GB RAM) |
| Redis | ElastiCache cache.t2.micro |
| RDS | MySQL db.t4g.micro |
| 테스트 도구 | K6 (vus: 800, duration: 20분) |
| 캐시 TTL | 1분 |
비교
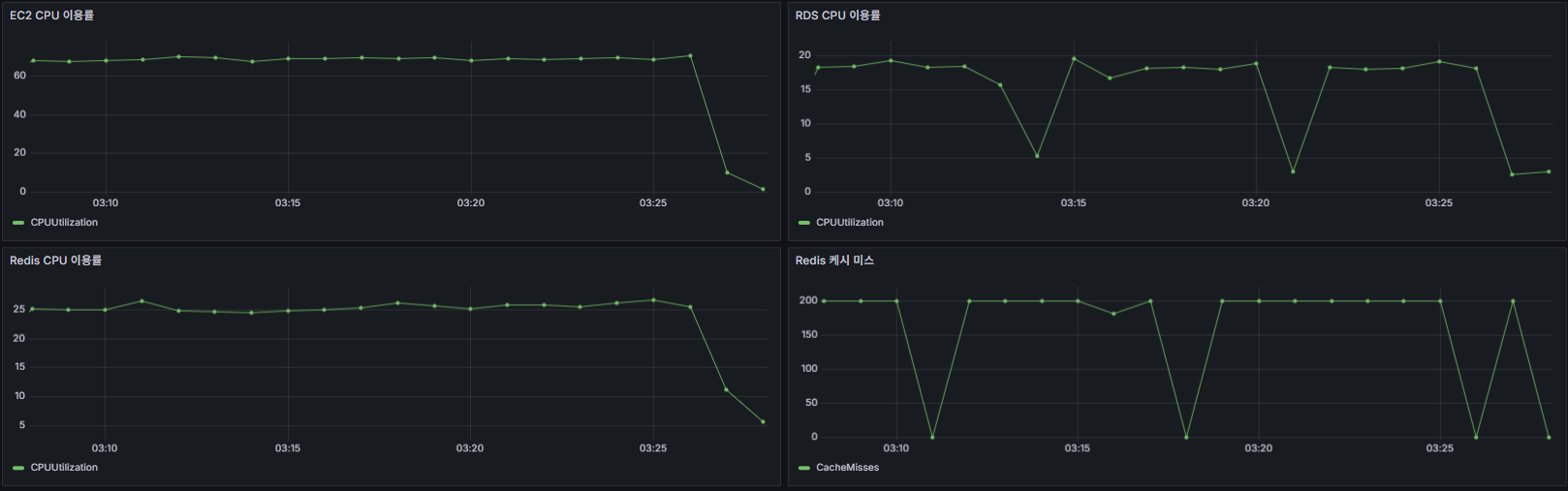
📉 PER 알고리즘 적용 전
- EC2 CPU 사용률 : 69.0%
- RDS CPU 사용률 : Cache miss시 18%까지 치솟음.
- Redis CPU 사용률 : 25.2%
- Cache Status : TTL 만료 시 다수의 cache miss 발생
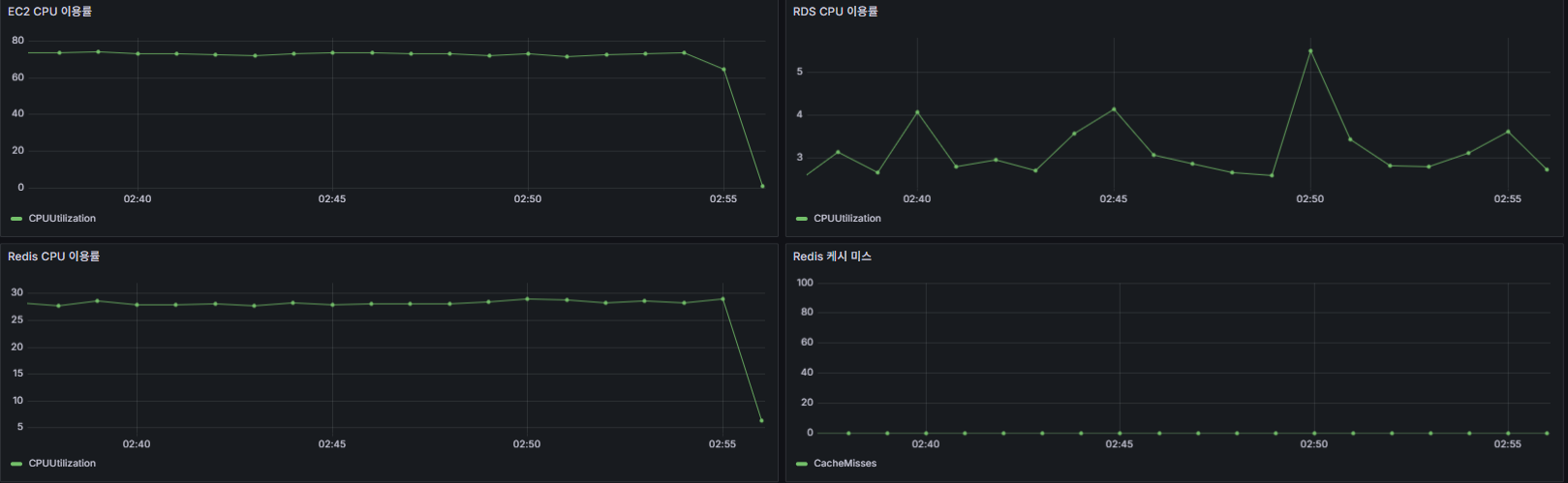
📈 PER 알고리즘 적용 후
- EC2 CPU 사용률 : 73.0%
- RDS CPU 사용률 : 3.89%
- Redis CPU 사용률 : 28.2%
- Cache Status : cache miss가 발생하지 않음
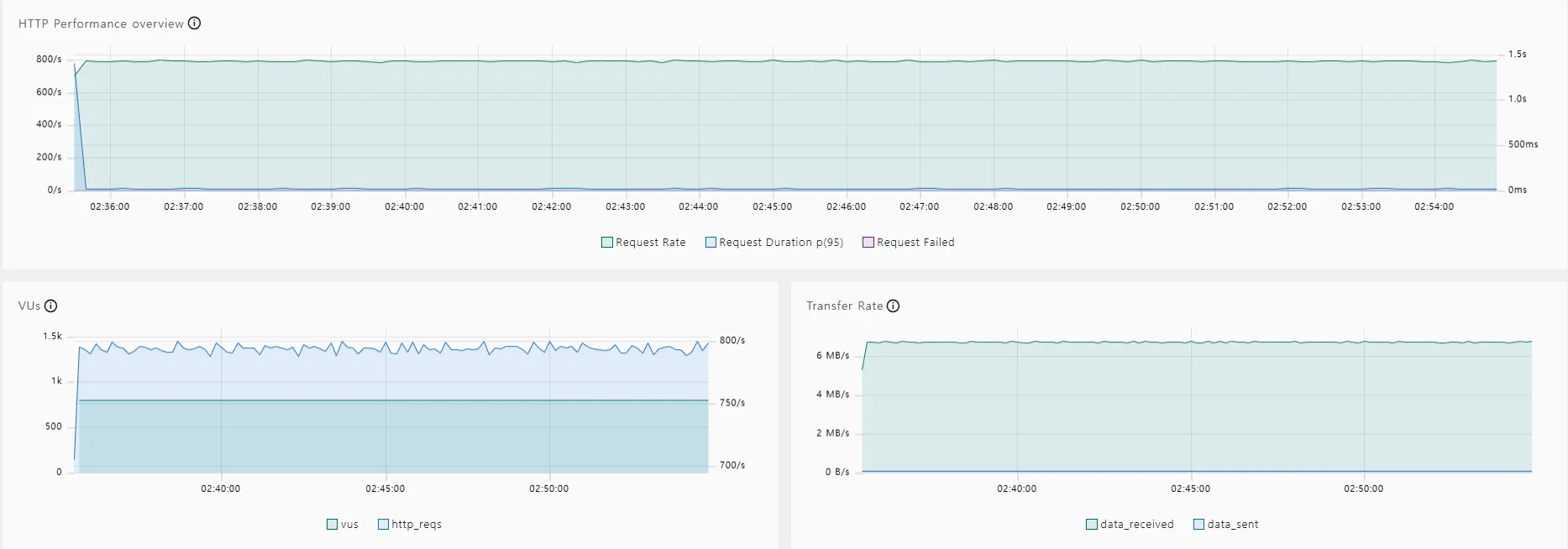
해석
-
EC2의 CPU 사용률은 69.0%에서 73.0%로 다소 증가했다. 이는 PER 알고리즘이 추가 연산을 EC2측에서 수행하기 때문이다.
-
Redis의 CPU 사용률은 25.2%에서 28.2%로 소폭 증가했다. 이는 PER 알고리즘 적용 후, 매 요청마다 Lua Script가 실행되며 단순 GET/SET보다 더 많은 Redis 명령어(MGET, PTTL, MSET 등)를 처리하게 되었기 때문이다.
-
기존에는 캐시 미스 발생 시마다 RDS CPU 사용률이 최대 18% 가까이 급등했으나, PER 적용 후 이러한 급등 현상이 사라졌다. 이는 RDS의 가용성과 안정성 측면에서 큰 개선이다.
