문제 상황
진행 중인 프로젝트에서 nginx와 docker를 활용해 blue/green 무중단 배포 환경을 구축했다. 하지만 부하 테스트를 통해 정상적으로 트래픽이 전환되는지 확인하는 과정에서 downtime(일시적인 서비스 중단)이 발생했다.
현재 blue/green 무중단 배포 프로세스는 다음과 같다.
- 새로운 버전의 컨테이너 실행.
- 헬스 체크를 통해 컨테이너 구동 상태 확인.
- 헬스 체크 성공 시 nginx 설정을 변경하여 트래픽을 신규 컨테이너로 전환.
- 기존 컨테이너 종료.
트래픽이 새로운 컨테이너로 전환되는 순간, 일부 요청이 실패했다.
문제 해결
Nginx reload 적용
nginx 설정 변경 사항을 반영하는 방법에는 다음 두 가지 명령어가 있다.
service nginx restart
service nginx reload먼저 restart는 nginx 프로세스를 완전히 중단 후 재시작하므로 서비스에 downtime이 발생한다.
반면 reload는 다음과 같은 절차를 통해 무중단으로 설정을 반영한다.
reload명령은 nginx의 master process에HUP(Hang Up) 시그널을 보낸다.- master process는 변경된 설정 파일의 문법을 검사한다. 오류가 있다면 변경 사항은 반영되지 않는다.
- 문법에 문제가 없다면, 새로운 worker process를 생성한다.
- 기존 worker process는
shutdown시그널을 받아서 현재 처리 중인 요청을 모두 완료한 후 종료한다.
이러한 구조 덕분에 reload 명령을 사용하면 설정 변경 시에도 트래픽 유실 없이 서비스를 지속할 수 있다.
Graceful Shutdown 설정
Spring Graceful Shutdown
graceful shutdown은 애플리케이션이 종료될 때, 새로운 요청은 받지 않고, 현재 처리 중인 요청만 정상적으로 마친 뒤 종료되도록 하는 기능이다. spring boot 2.3 이상에서는 다음과 같이 설정할 수 있다.
application.yml
server:
shutdown: gracefulgraceful shutdown이 활성화되어 있을 때, 만약 애플리케이션이 deadLock(교착 상태) 등에 빠지면, 종료되지 못한 구버전 프로세스가 무한정 대기 상태에 머무를 수 있다. 이를 방지하기 위해 timeout을 설정할 수 있으며, 기본값은 30초이다.
spring:
lifecycle:
timeout-per-shutdown-phase: 30sLinux 프로세스 종료 방식
하지만 spring의 application.yml 설정만으로는 graceful shutdown이 동작하지 않는다. 먼저 Linux에서 process를 종료할 때 사용하는 kill 명령어를 알아보자.
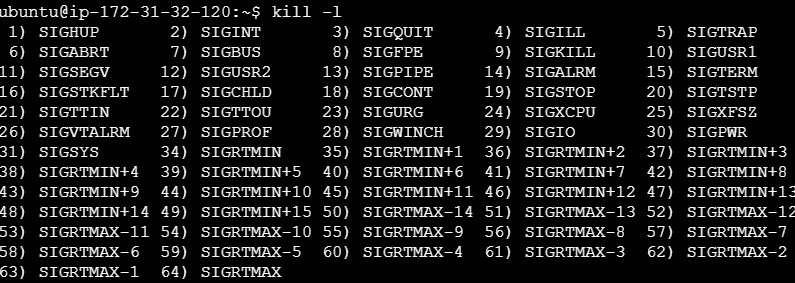
대표적인 옵션으로 -9와 -15가 있다. graceful shutdown을 설정하기 위해서는 SIGTERM(kill -15)을 함께 사용해야 한다.
-9(SIGKILL): 처리 중이던 작업의 유무에 관계없이 즉시 종료.-15(SIGTERM): 프로세스를 정상적으로 종료.
Docker 프로세스 종료 방식
배포 스크립트에서 linux의 kill 명령어를 직접 사용할 수도 있지만, 일반적으로 docker를 사용하고 있다면, docker 명령어를 사용하는 것이 더 안전하고 직관적이다.
컨테이너 종료 시에는 아래 두 가지 명령어를 사용할 수 있다.
docker kill <container_id>
docker stop <container_id>먼저 docker kill 명령은 컨테이너에 즉시 SIGKILL 신호를 보내므로 graceful shutdown이 동작하지 않는다.
반면 docker stop 명령은 내부적으로 다음과 같은 절차를 따른다.
SIGTERM신호를 컨테이너 내부 애플리케이션 프로세스에 전달한다. (graceful shutdown이 설정되어 있다면 적용)- 기본적으로 10초간 종료를 대기한다.
- 해당 시간 내 종료되지 않으면
SIGKILL을 보내 강제 종료한다.
💡 따라서 무중단 배포 시 zero downtime을 위해서는 SIGTERM(or docker stop)을 사용하고, spring boot의 application.yml에 graceful shutdown 설정을 함께 적용해야 한다.
배포 스크립트
...
# 1. 새 컨테이너 실행
docker compose -f temp-compose.yml up -d
echo "🟡 새 컨테이너 실행됨 → 헬스체크 시작..."
# 2. 헬스체크 수행
MAX_RETRIES=45
SLEEP_INTERVAL=2
HEALTH_URL="http://localhost:$NEXT_PORT/actuator/health"
echo "🔍 헬스체크 시작 (최대 ${MAX_RETRIES}회, ${SLEEP_INTERVAL}초 간격)"
for ((i=1; i<=MAX_RETRIES; i++)); do
sleep $SLEEP_INTERVAL
RESPONSE=$(curl -s --max-time 2 "$HEALTH_URL")
HTTP_STATUS=$(echo "$RESPONSE" | jq -r '.status' 2>/dev/null)
echo "🔎 시도 $i → 응답 상태: $HTTP_STATUS"
if [[ "$HTTP_STATUS" == "UP" ]]; then
echo "✅ 헬스체크 통과: 애플리케이션이 정상입니다."
break
fi
if [[ $i -eq $MAX_RETRIES ]]; then
echo "❌ 헬스체크 실패: ${MAX_RETRIES}회 시도했으나 상태가 UP이 아닙니다."
echo "📦 로그 보기: docker logs $NEXT_NAME"
echo "📦 상태 보기: docker ps -a"
rm temp-compose.yml
exit 1
fi
done
# 3. Nginx 설정 전환
echo "🔁 Nginx 포트 전환: $NGINX_SCRIPT"
bash $NGINX_SCRIPT | sudo tee /etc/nginx/conf.d/app.conf > /dev/null
sudo systemctl reload nginx
echo "✅ Nginx 설정 적용 및 reload 완료"
# 4. 이전 컨테이너 제거
echo "🛑 이전 컨테이너 종료 중 (docker stop + rm)"
# docker stop $OLD_NAME
docker stop --time=30 $OLD_NAME
docker rm $OLD_NAME
...
고찰
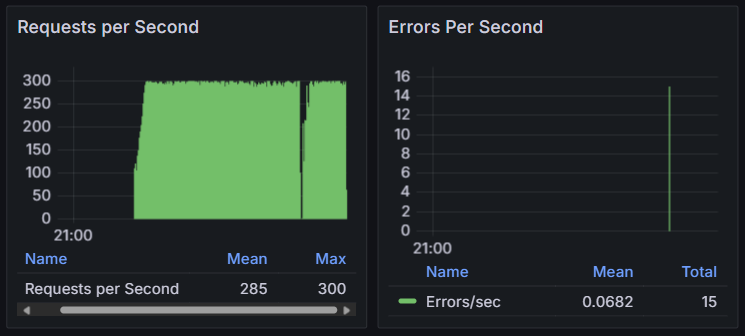
nginx reload 명령과 spring boot의 graceful shutdown 기능을 적용한 후, 무중단 배포 시나리오를 다시 테스트했다. 그 결과 k6 + grafana 조합에서는 downtime 없이 트래픽이 전환되었지만, jmeter에서는 일부 요청이 에러를 반환했다.
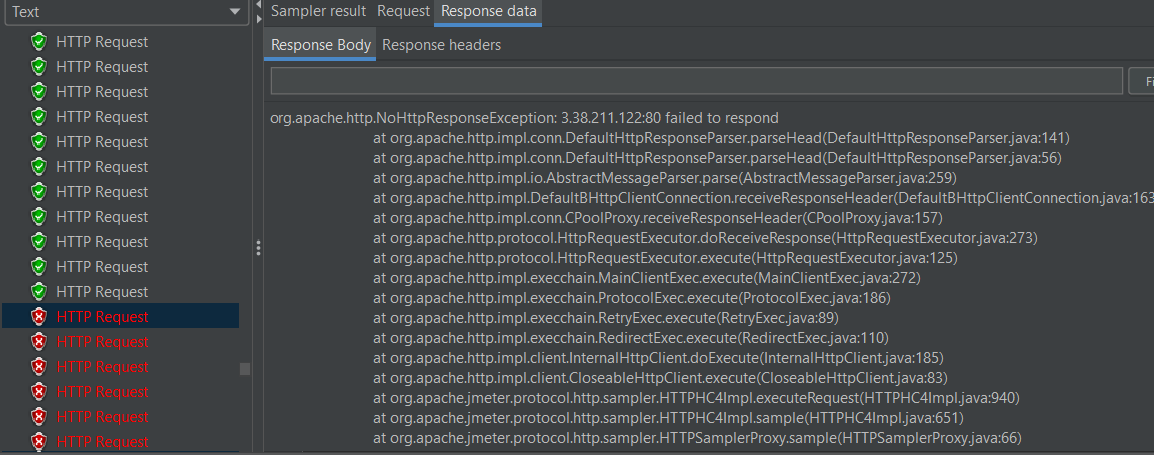
에러가 발생한 이유
일반적인 네트워크 환경이나 부하 테스트 도구는 http 요청 시 기본적으로 Connection: keep-alive 헤더를 사용한다. 이는 클라이언트가 일정 시간 동안 기존 tcp 커넥션을 재사용하도록 한다.
하지만 nginx에서 reload 명령을 실행하면 새로운 worker process가 생성되면서 기존 worker process는 현재 요청받은 작업을 모두 완료한 후 기존 커넥션을 함께 끊어(종료)버린다. 여기서 클라이언트가 이미 끊긴 커넥션을 통해 http 요청을 보내면 jmeter 등 일부 도구에서는 에러를 반환한다.
Connection : close 헤더와 클라이언트 재시도 전략
클라이언트와 서버는 언제든 tcp 커넥션을 끊을 수 있으며, 이 경우 Connection : close 헤더를 통해 상대방에게 tcp 커넥션을 끊겠다는 의도를 명시적으로 전달해야 한다. 이를 응용하면, 클라이언트가 요청 시 Connection: close 헤더를 명시함으로써 매 요청마다 새 커넥션을 맺도록 강제할 수 있다.
실제로 jmeter에서 keep-alive 설정을 끄고 테스트해본 결과, 에러 없이 모든 요청이 정상 처리되며 downtime이 발생하지 않았다. 하지만 Connection : close를 사용하면 매 요청마다 tcp 커넥션을 맺어야 하는 것에 따른 오버헤드가 발생한다.
대신 http/1.1 스펙에 따르면 클라이언트와 서버는 예기치 못한 tcp 커넥션 close로부터 적절한 복구 작업을 수행해야 한다고 한다. 즉 서버가 Connection : close 헤더 없이 일방적으로 커넥션을 끊을 경우 클라이언트는 요청을 재시도하는 등의 액션이 필요할 수 있다. 앞서 k6는 내부적으로 자동 재시도 기능을 제공하기 때문에 커넥션이 끊기더라도 요청을 다시 보내 에러 없이 처리할 수 있었다.
