문제 상황 : "추천 프로젝트 조회" API의 낮은 조회 성능
"추천 프로젝트 조회" API는 "좋아요 수"를 기준으로 상위 N개의 프로젝트를 조회하는 기능이다.
처음 API를 구현하고 부하 테스트를 진행했는데 RDS CPU 이용률이 100%에 도달하면서 현재 시스템이 처리할 수 있는 최대 TPS가 20에 불가했다. 추천 프로젝트 콘텐츠는 사용자 홈 화면 상단에 노출되는 콘텐츠로 빠른 응답 속도가 UX에 직접적인 영향을 미치기에 성능 개선이 필요했다.
🧷 발생한 쿼리
SELECT
p.id,
p.title,
COUNT(l.id) AS like_count
FROM
likes l
JOIN
projects p ON p.id = l.project_id
GROUP BY
p.id, p.title
ORDER BY
like_count DESC
LIMIT 10;참고로 users 테이블과 projects 테이블은 각각 likes 테이블과 1:N 관계를 가진다.
📉 부하 테스트 수행
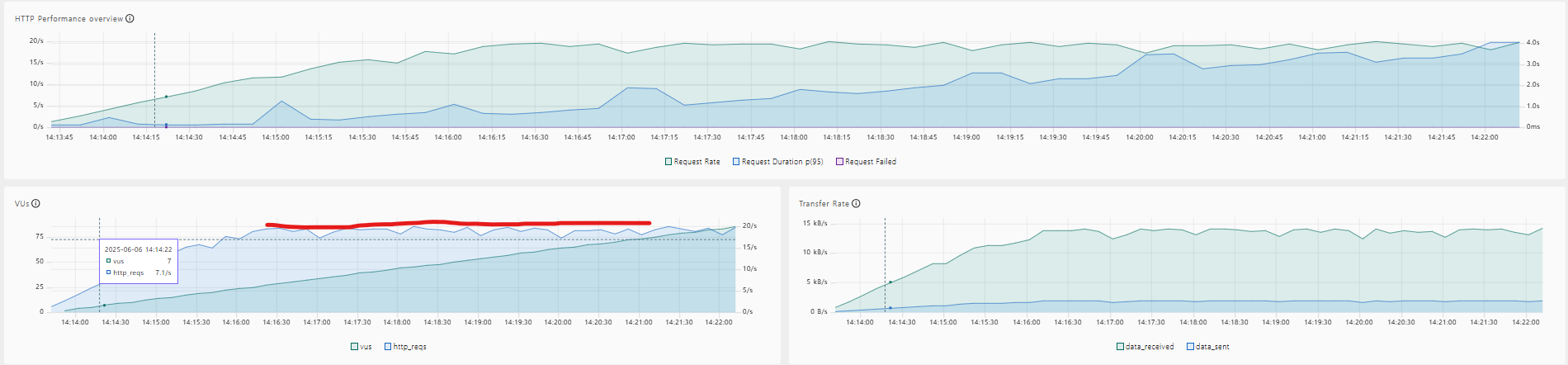
- 테스트 데이터 : users, projects, likes → 총 10만 건의 더미 데이터 구성
- 사용 도구 : K6 (부하 테스트), AWS CloudWatch (모니터링)
- 인스턴스 유형 : K6-server(t3.small), spring-server(t3.small)
- 테스트 환경 : 30분 동안 vuser 300으로 Ramp-up test 진행
- 테스트 결과 :
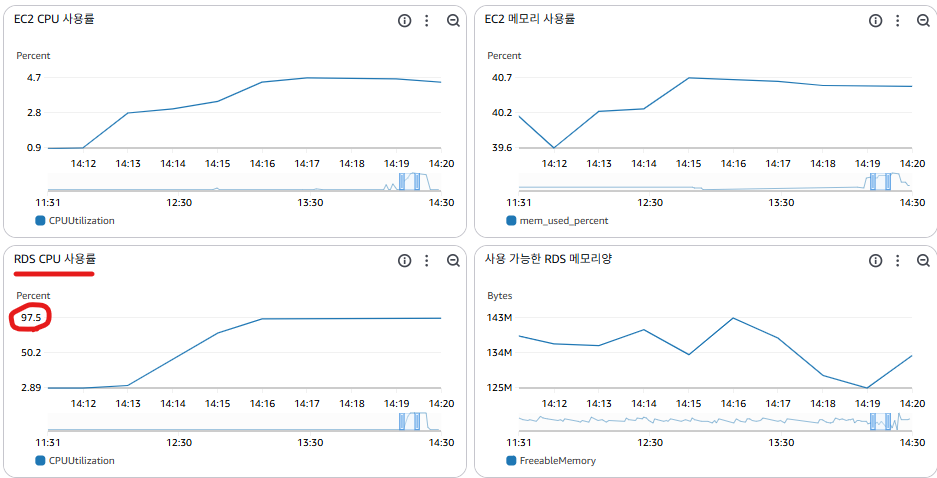
- RDS CPU 이용률이 100%에 도달(병목)
- 현재 시스템이 안정적으로 처리 가능한 최대 TPS : 약 20 (TPS)
원인 분석 : MySQL Explain
성능 저하 원인을 분석하기 위해 MySQL explain 명령어로 쿼리 실행 계획을 분석해 보았다.
- explain :
explain명령어를 사용해 쿼리를 분석해 봤지만, likes 테이블에서 인덱스 풀 스캔이 발생한다는 점 외에는 성능 저하의 명확한 원인을 파악하기 어려웠다.

- explain analyze : 조금 더 구체적인 성능 지표를 확인하기 위해
explain analyze명령어를 사용했다. 실행 계획을 살펴보면, likes 테이블을 인덱스 풀 스캔하며 약 10만 건을 읽어 들이고, 레코드마다 projects 테이블과 조인하는 연산에서 시간이 많이 소요되고 있음을 확인할 수 있다.
-> Limit: 10 row(s)
(actual time=142..142, rows=10, loops=1)
-> Sort: like_count DESC, limit input to 10 row(s) per chunk
(actual time=142..142, rows=10, loops=1)
-> Table scan on <temporary>
(actual time=142..142, rows=1000, loops=1)
-> Aggregate using temporary table
(actual time=142..142, rows=1000, loops=1)
-> Nested loop inner join
(cost=45070, rows=99960)
(actual time=0.515..70.1, rows=100000, loops=1)
-> Filter: (l.project_id IS NOT NULL)
(cost=10084, rows=99960)
(actual time=0.503..32.2, rows=100000, loops=1)
-> Covering index scan on `l`
using FKlwferkdanhslltbk0ikhkip06
(cost=10084, rows=99960)
(actual time=0.502..23.8, rows=100000, loops=1)
-> Single-row index lookup on `p`
using PRIMARY (id = l.project_id)
(cost=0.25, rows=1)
(actual time=0.000161..0.000196, rows=1, loops=100000)문제 해결 : 1. 커버링 인덱스 활용
앞서 쿼리 실행 계획을 분석한 결과를 토대로, 조인 연산에 따른 비용을 어떻게 하면 줄일 수 있을지 고민했다.
그 결과 "좋아요 수" 기준 상위 N개의 프로젝트 id만 먼저 조회하고, 그 결과를 바탕으로 projects 테이블에서 필요한 데이터와 조인하는 방식을 도입했다. MySQL에서는 서브쿼리를 활용해 하나의 쿼리로도 표현할 수 있지만, JPA에서는 이를 효율적으로 처리하기 어려워 두 개의 쿼리로 나누어 구현했다.
- 첫 번째 쿼리 : likes 테이블에서 "좋아요 수" 기준 상위 N개의 프로젝트 id와 "좋아요 수"를 커버링 인덱스로 조회한다.
- 두 번째 쿼리 : projects 테이블에서 in 쿼리로 클러스터드 인덱스(PK)를 활용해서 필요한 프로젝트 데이터를 조회한다.
이렇게 구성함으로써 불필요한 조인 비용을 줄이고, 기존 대비 약 5배의(20 -> 95 (TPS)) 쿼리 성능을 개선할 수 있었다.
🧷 발생한 쿼리
## 첫 번째 쿼리
SELECT
l.project_id,
COUNT(l.id) AS like_count
FROM
likes l
GROUP BY
l.project_id
ORDER BY
like_count DESC
LIMIT 10;
## 두 번째 쿼리
SELECT
p.id,
p.created_at,
p.created_by,
p.title,
p.updated_at,
p.updated_by
FROM
projects p
WHERE
p.id IN (1, 50, 100, 150, 200, 500, 1000, 10000, 40000, 80000);📉 부하 테스트 수행
- 테스트 데이터 : users, projects, likes → 총 10만 건의 더미 데이터 구성
- 사용 도구 : K6 (부하 테스트), AWS CloudWatch (모니터링)
- 인스턴스 유형 : K6-server(t3.small), spring-server(t3.small)
- 테스트 환경 : 30분 동안 vuser 300으로 Ramp-up test 진행
- 테스트 결과 :
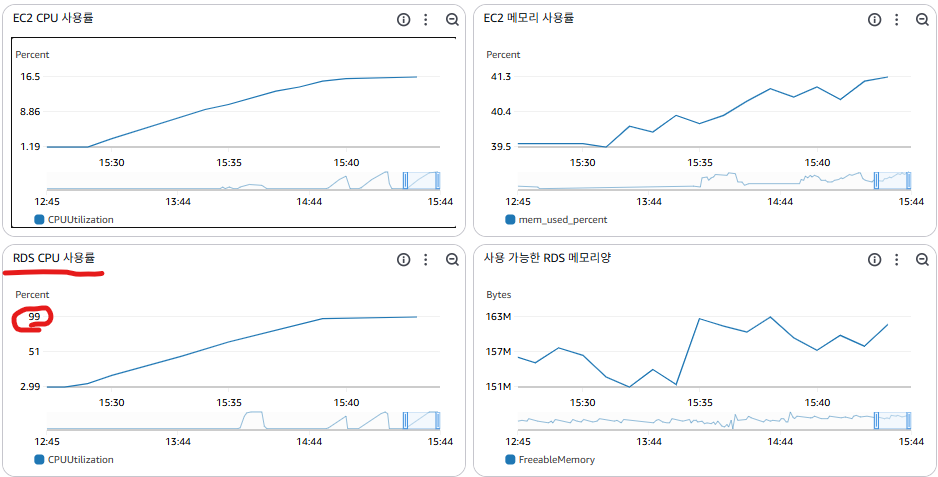
- RDS CPU 이용률이 100%에 도달(병목)
- 현재 시스템이 안정적으로 처리 가능한 최대 TPS : 약 95 (TPS)
한계점 : 커버링 인덱스 적용 후에도 남은 문제
추가적인 개선의 여지가 있는지 확인하기 위해, 쿼리 실행 계획을 다시 한번 분석해보았다.
-
첫 번째 쿼리
likes 테이블을 인덱스 풀 스캔하는 과정에서 첫 번째 쿼리의 대부분의 시간이 소요되고 있음을 확인할 수 있다.
-> Limit: 10 row(s)
(actual time=26.8..26.8, rows=10, loops=1)
-> Sort: like_count DESC, limit input to 10 row(s) per chunk
(actual time=26.8..26.8, rows=10, loops=1)
-> Stream results
(cost=20080, rows=1039)
(actual time=0.616..26.7, rows=1000, loops=1)
-> Group aggregate: COUNT(l.id)
(cost=20080, rows=1039)
(actual time=0.614..26.5, rows=1000, loops=1)
-> Covering index scan on `l`
using FKlwferkdanhslltbk0ikhkip06
(cost=10084, rows=99960)
(actual time=0.590..20.5, rows=100000, loops=1)- 두 번쨰 쿼리
projects 테이블에서는 클러스터드 인덱스(PK) 를 활용해 효율적으로 데이터가 조회되고 있음을 확인할 수 있다.

-> Filter: (p.id IN (1,50,100,150,200,500,1000,10000,40000,80000))
(cost=4.51, rows=10)
(actual time=0.0347..0.063, rows=10, loops=1)
-> Index range scan on `p`
using PRIMARY over (id = 1) OR (id = 50) OR (8 more)
(cost=4.51, rows=10)
(actual time=0.0334..0.0604, rows=10, loops=1)첫 번째 쿼리 + 두 번째 쿼리의 총 실행 시간은:
26.7ms + 0.063ms = 약 26.763ms
이 중, 첫 번째 쿼리에서 likes 테이블의 인덱스 풀 스캔 및 "좋아요 수" 집계 과정에서만 약 26.5ms가 소요되었음을 확인할 수 있다. 앞서 인덱스 풀 스캔 시 매번 발생하던 조인 연산을 제거하여 성능을 개선하긴 했지만, "좋아요 수" 집계 시 likes 테이블 전체 데이터를 읽어야 하는 인덱스 풀 스캔 자체는 여전히 발생하기 때문에, 높은 DB 부하는 근본적으로 피하기 어려운 상황임을 확인할 수 있다.
문제 해결 : 2. Redis Sorted Set 활용
앞서 쿼리 최적화로 일정 수준의 성능 개선은 이루었지만, "좋아요 수"에 따른 랭킹 계산 과정에서 발생하는 성능 병목은 여전히 완전히 해소되지 않은 상태였다. "어떻게 하면 '좋아요 수' 기반 랭킹을 더 빠르게 조회할 수 있을까?" 고민하던 중, Redis의 Sorted Set 자료구조를 활용하는 방안을 도입하게 되었다.
Redis의 Sorted Set은 말 그대로 정렬된 집합을 표현하는 자료구조다. 각 요소는 고유한 member와 score 한 쌍으로 구성되며, score는 member의 정렬 순서를 결정하는데 사용된다. 내부적으로는 ziplist 또는 skiplist + hashtable 구조로 구성되어 있어 대부분의 연산이 O(log n)의 시간 복잡도를 가진다. 주로 실시간 랭킹 시스템을 구현할 때 자주 사용되는 자료구조다.
🧷 비즈니스 로직
- "좋아요 요청/취소" API
기존과 달리 likes 데이터를 Redis에서 관리한다. 그리고 사용자의 좋아요 요청/취소 이벤트 발생 시마다 Redis에 좋아요 정보를 기록하고, Sorted Set에 해당 프로젝트의 "좋아요 수"를 업데이트한다.- Sorted Set의 (member, score) → (projectId, "좋아요 수")
@Transactional
public ReactLikeResponseDto reactLike(Long userId, Long projectId) {
String redisKey = LIKE_KEY_PREFIX + projectId;
boolean isLiked = redisTemplate.opsForSet().isMember(redisKey, userId);
String projectKey = "project_" + projectId;
if (isLiked) {
redisTemplate.opsForSet().remove(redisKey, userId);
redisTemplate.opsForZSet().incrementScore(PROJECT_SCORE_KEY, projectKey, -1);
} else {
redisTemplate.opsForSet().add(redisKey, userId);
redisTemplate.opsForZSet().incrementScore(PROJECT_SCORE_KEY, projectKey, 1);
}
boolean newLikeStatus = !isLiked;
return new ReactLikeResponseDto(newLikeStatus);
}- "추천 프로젝트 조회" API
Redis Sorted Set에서 "좋아요 수" 기준 상위 N개의 프로젝트 ID를 먼저 조회한 뒤, 해당 ID 리스트로 DB에서 프로젝트 상세 정보를 조회한다.
public List<ProjectRecommendResponse> getRecommendProjects() {
ZSetOperations<String, Object> zSetOps = redisTemplate.opsForZSet();
Set<ZSetOperations.TypedTuple<Object>> topProjectsWithScores =
zSetOps.reverseRangeWithScores(PROJECT_SCORE_KEY, 0, 12 - 1);
if (topProjectsWithScores == null || topProjectsWithScores.isEmpty()) {
return List.of();
}
List<Long> projectIds = new ArrayList<>();
Map<Long, Long> scoreMap = new HashMap<>();
for (ZSetOperations.TypedTuple<Object> tuple : topProjectsWithScores) {
String projectIdStr = tuple.getValue().toString().replace("project_", "");
Long projectId = Long.parseLong(projectIdStr);
projectIds.add(projectId);
scoreMap.put(projectId, tuple.getScore().longValue());
}
List<Project> projects = projectRepository.findAllById(projectIds);
return projects.stream()
.map(project -> ProjectRecommendResponse.of(project, scoreMap.get(project.getId())))
.collect(Collectors.toList());
}🧷 발생한 쿼리
Redis로부터 받은 프로젝트 ID 리스트를 기반으로, DB에서는 해당 ID들에 대해 IN 쿼리로 프로젝트 상세 정보를 조회하는 쿼리만 발생한다.
SELECT
p.id,
p.created_at,
p.created_by,
p.title,
p.updated_at,
p.updated_by
FROM
projects p
WHERE
p.id IN ( ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ? );📉 부하 테스트 수행
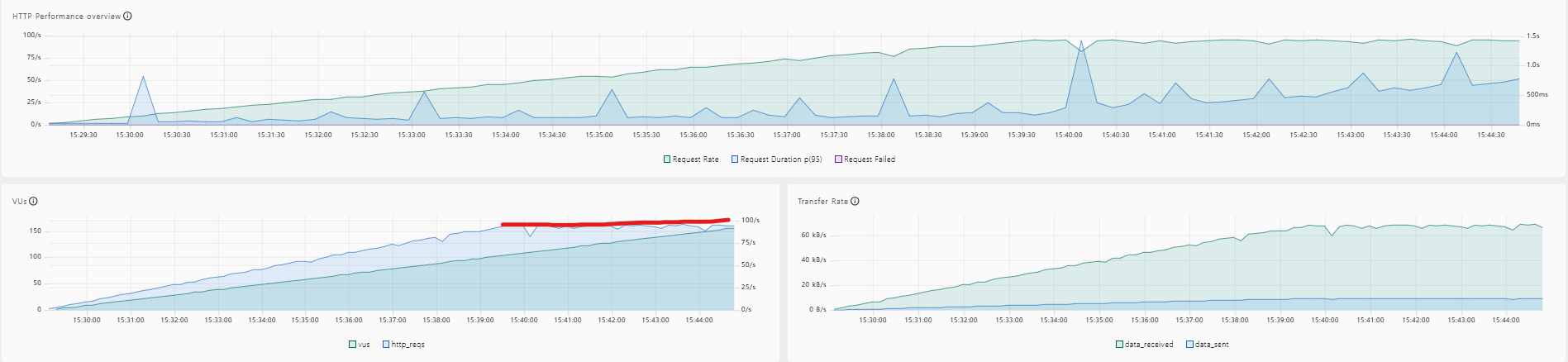
- 테스트 데이터 : users, projects, likes → 총 10만 건의 더미 데이터 구성
- 사용 도구 : K6 (부하 테스트), AWS CloudWatch (모니터링)
- 인스턴스 유형 : K6-server(t3.small), spring-server(t3.small), Redis(cache.t2.micro)
- 테스트 환경 : 30분 동안 vuser 3000으로 Ramp-up test 진행
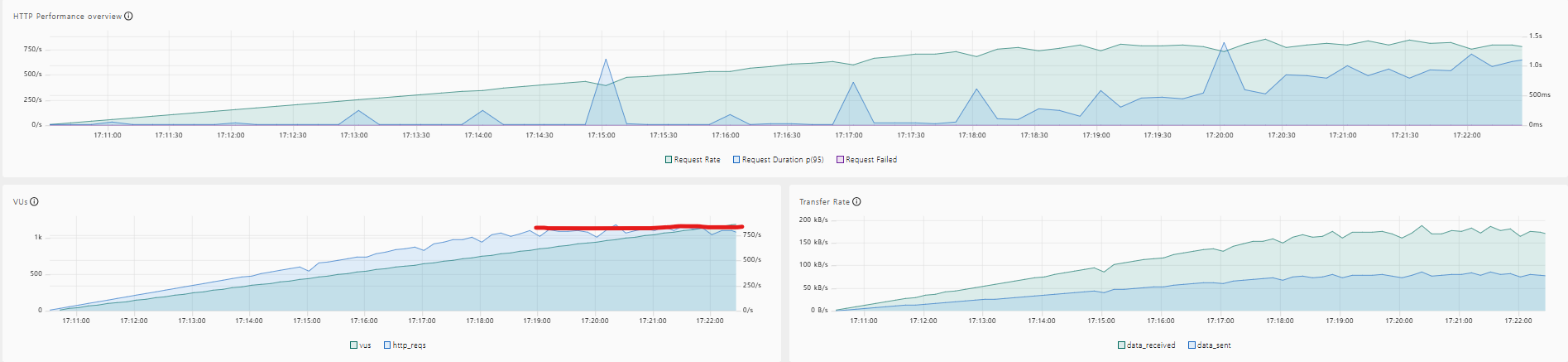
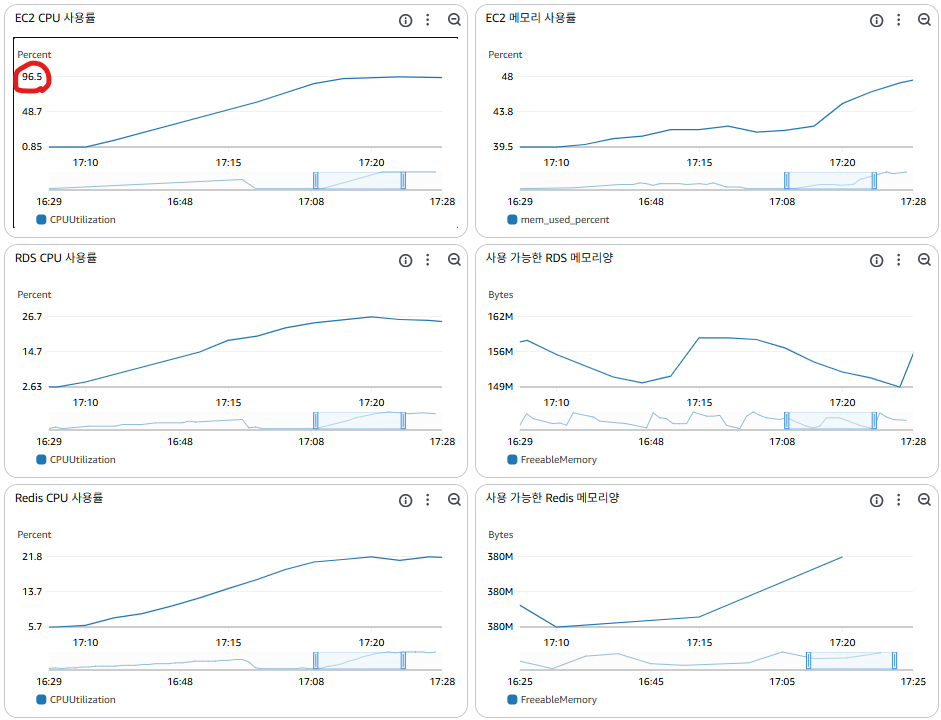
- 테스트 결과 : EC2 CPU 이용률이 100%에 도달(병목), Redis 리소스 추가 사용.
- 현재 시스템이 안정적으로 처리 가능한 최대 TPS : 약 800 (TPS)
고찰
📊 단계별 성능 비교
| 단계 | TPS | EC2 CPU 이용률 | RDS CPU 이용률 | Redis CPU 이용률 |
|---|---|---|---|---|
| 초기 | 약 20 | 4.7% | 97.5% (조인 + 인덱스 풀 스캔) | - |
| 커버링 인덱스 적용 | 약 95 | 16.5% | 99% (인덱스 풀 스캔) | - |
| Redis Sorted Set 적용 | 약 800 | 96.5% | 26.7% | 21.8% |
커버링 인덱스와 Redis Sorted Set을 단계적으로 적용하여 추천 프로젝트 조회 API의 성능을 기존 대비 약 40배 개선할 수 있었다.
개선 과정에서 알 수 있었던 점은, 커버링 인덱스는 별도의 추가 리소스 없이 적용할 수 있지만, Redis Sorted Set은 별도의 Redis 리소스가 필요하다는 것이다. 따라서 Redis 도입 시에는 운영 비용과 성능 향상에 따른 Trade-off를 충분히 고려해야 한다. 이번 사례에서는 성능 개선 효과가 매우 컸기 때문에 Redis 도입이 충분히 가치 있는 선택이었다고 생각한다.
