결과물은 stripe2933/AdjacencyInfectionSimulation에서 확인하실 수 있습니다.
코로나-19가 발병하자 많은 매체에서 그 해결책으로 사회적 거리두기를 제시하며, 그 효과를 보여주는 영상물을 배포한 적이 있습니다.
Flattening The Curve - Simulating The Effect of Quarantine & Social Distancing
간단한 brute-force를 이용해 로 코드를 짤 수도 있지만, 약간의 알고리즘적 판단을 도입해 좀 더 개선할 수 있습니다( 미만의 시간복잡도로 계산하는 방법으로는 Voronoi Diagram 등을 이용해야 할 것으로 예상됩니다).
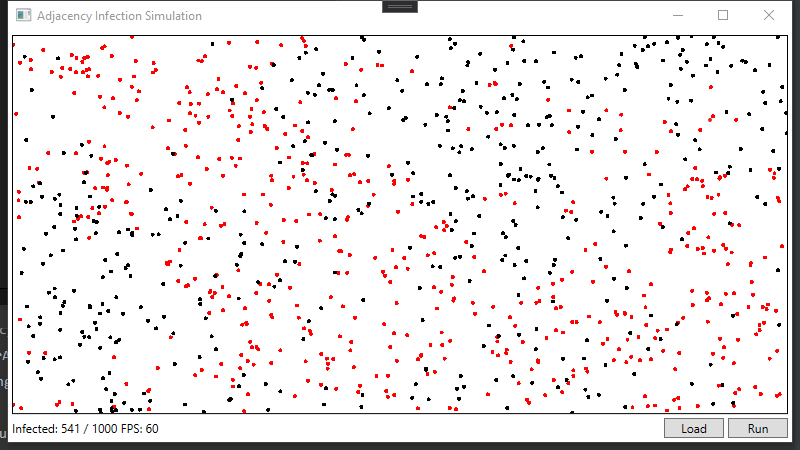
빠른 렌더링을 위해 SkiaSharp 라이브러리를 참조하였습니다. 5천개 이내의 Population에 대해서는 Antialiasing 여부가 크게 성능에 영향을 미치지 않는 것으로 보입니다. SkiaElement의 빠른 렌더링을 위해 Mvvm 구조는 따르지 않았습니다.
파라미터 Parameter
PERIOD:FPS및 이동 속도 업데이트 주기입니다. Update period ofFPSand moving velocity.INITIAL_INFECTEE: 초기 감염자 수입니다. Number of initial infected people.POPULATION: 총 인구수입니다. Total population of group.MOVING_DIST_MEAN: 각 사람의 이동 거리에 대한 정규분포의 평균입니다. Mean for normal distribution of each person's moving distance.MOVING_DIST_STD: 각 사람의 이동 거리에 대한 정규분포의 표준편차입니다. Standard deviation for normal distrubution of each person's moving distance.INFECTION_DIST: 감염되는 최소한의 거리입니다. Minimum distance of infection.INFECTION_DIST_SQUARE: 감염되는 최소한의 거리의 제곱입니다(계산 효율 향상을 위함). Minimum distance square of infection (for improve calculating performance).INFECTION_PROB:INFECTION_DIST내에서 감염될 확률입니다. Probability of infection when each person nears the distance belowINFECTION_DIST.
알고리즘
프로그램의 성능을 좌우하는 가장 큰 함수는 CalculateInfection입니다 (다른 함수는 자잘한 최적화 등을 제외하면 보다 효율적으로 이루어질 수 없습니다).
감염을 시뮬레이팅하기 위해서는 각 감염자들의 주변 비감염인(neighbor)를 찾고, 이들과 각각의 거리를 계산하여 그것이 INFECTION_DIST보다 작은 경우 이들을 감염인으로 만들어야 합니다. 감염인 명에 대해 주변 비감염인을 brute-force로 찾는 경우의 수는 POPULATION 에 대해 이므로, 거리 계산량은 적어도 입니다(실제로는 각각 번의 이중 반복문을 순회하므로 적어도 입니다). 따라서 실시간으로 처리하기에는 (한 번의 loop에 1s/60=16ms) 큰 에 대해 어렵습니다. 이를 해결하는 방법으로는 다음을 생각할 수 있습니다.
개의 기준점을 가지는 점(X와 Y를 가지는 자료형) 배열에 대하여 각 기준점에서 보다 가까운 점을 찾는 방법은
- 배열을 X에 대해 오름차순이 되도록 정렬합니다:
- 근접한 점을 찾기 위한 기준점 에서 X가 내에 있는 이웃 후보 점을 찾습니다: (이진 탐색)
- 후보들에 대해 각각의 기준점과의 거리를 계산합니다:
이므로 총 시간복잡도는 입니다. 물론 가 을 향해감에 따라 시간이 지날수록 수행 속도가 점차 감소합니다. 하지만, 프로그램의 가정에 따라 더 낮은 계산량을 가집니다. 인구는 전역적으로 균등하게 분포하여 있고, 무작위적으로 움직입니다. 또한 감염 거리(INFECTION_DIST)는 지역 전체를 포함하지 않고 국소적이므로 이웃 후보 점의 수를 크게 줄일 수 있습니다.
또한 프로그램적 기법에 따라 이를 더 최적화 할수도 있는데요.
더 나은 최적화 방법 performance optimizing 1. 줄어드는 정렬량 decreasing sorting calculation
모델(Person)은 다음과 같은 프로퍼티를 가집니다.
X,YVx,VyInfected
감염인을 기준점으로 비감염인만을 비교하면 되기 때문에, 위의 는 시간이 지날 수록 늘어납니다. 또한 X좌표 정렬은 비감염인에 대해서만 하면 되므로, 정렬이 요구하는 시간복잡도는 입니다.
번의 반복에서
- 이진 탐색에 걸리는 시간: 대략
- 후보 점의 개수:
이므로 총 소요 시간은 단순 합으로 계산하면
입니다(단순 합이므로 실제와는 차이가 나나, 그 경향성을 파악하기 위함입니다). 이를 그래프상으로 비교하면
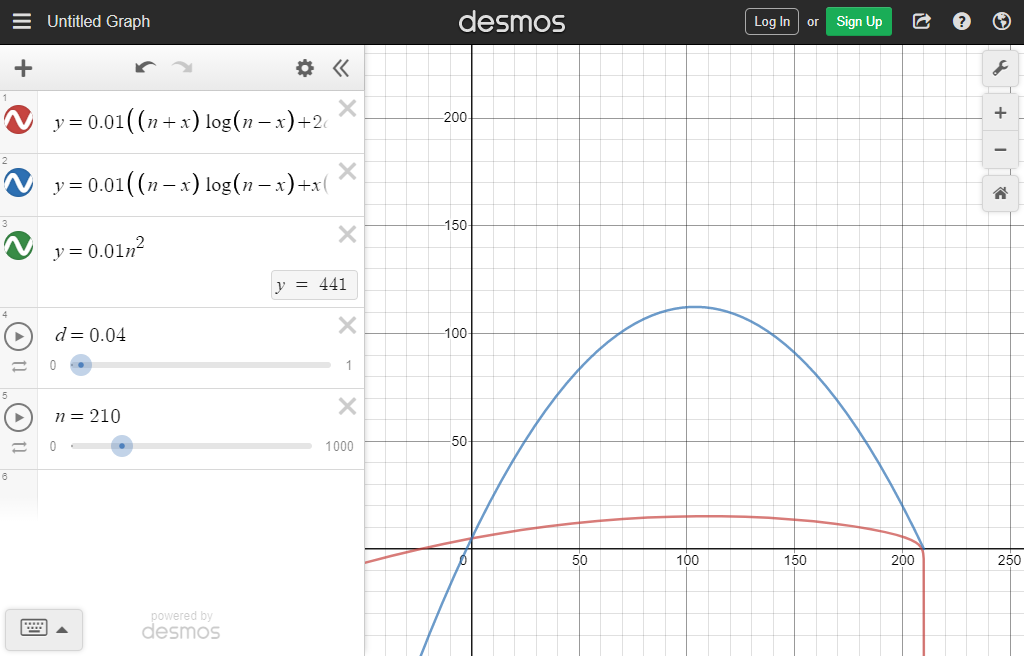
다음과 같습니다(녹색: brute-force, 파란색: 정렬을 동반한 개선된 brute-force, 빨간색: 알고리즘을 이용한 방법).
계산량은 가 에 가까워질수록 늘어나는 최고차항이 음수인 이차 함수의 개형을 가집니다. 그리고 이 방법에서는 가 0에 가까워짐에 따라 빨간색 그래프가 평탄해지는 형태로 계산량이 감소합니다.
더 나은 최적화 방법 performance optimizing 2. GC 발생 방지 prevention of GC
다음 두 코는 동일한 결과를 갖습니다.
// Code 1
double[] peopleX = _people.Select(p => p.X).ToArray(); // Linq를 이용한 방법
// Code 2
double[] peopleX = new double[_people.Length]; // 전역 변수로 설정
for (int i = 0; i < _people.Length; ++i) // 반복문을 이용한 방법
peopleX = _people[i].X;그러나 이를 반복하여 실행할 경우, 첫번째 코드는 GC를 발생시키고, 두 번째 코드는 그렇지 않습니다. Linq의 ToArray 함수는 반환값으로 새로운 double[] 인스턴스를 생성합니다. 이는 GC에 의해 다시 수집되기 전까지는 메모리 상에서 존재하며, 이 수집의 과정에서 코드의 성능 저하가 발생하게 됩니다.
그러나 두 번째 코드는 가독성이 떨어지지만, primitive type만을 발생시키기 때문에 GC가 일어나지 않습니다. 이는 정렬에서도 유사하게 일어납니다.
// Code 1
Person[] peopleSorted = _people.OrderBy(p => p.X).ToArray(); // Linq를 이용한 방법
// Code 2
Array.Sort(_people, (p1, p2) => p1.X.CompareTo(p2.X)); // 반복문을 이용한 방법단, 이 방법은 _people에 대해 in-place한 정렬을 시행해야 할 경우에만 가능합니다.
실제로 이 두 코드를 서로 교환하며 Visual Studio의 메모리 프로파일링을 실행하면, 시뮬레이션 수행 시 GC가 아예 일어나지 않거나, 끊임없이 일어나는 모습을 볼 수 있습니다.
