
Thumbnail image from DALL-E
✔ 프로젝트 소개
요즘은 많은 사람들이 Google, NAVER 지식인 뿐만 아니라 YouTube 영상으로도 정보를 많이 검색합다다. 저와 팀원은 이렇게 영상으로 정보를 검색할 때 항상 느낀 점이 있다는 걸 알아차리게 되었습니다! 💭
"영상 속 내용을 이해하는 것보다, 제대로 된 영상을 찾는 것이 어렵다!"
임의의 채널에서 사용자가 원하는 정보를 쉽게 검색할 수 있는 유튜브 검색 서비스를 제작할 순 없을까? 🤭 라는 생각으로 나를 포함한 개발자 2명이서 팀 프로젝트 를 시작하게 되었습니다. 애자일 프로세스를 따르고 있습니다.
Linux 클라우드 서버에서 Flask, mongoDB, SQLite, 그리고 GPT API를 사용하여 관리자 페이지를 구현했습니다. 대량의 자막 JSON 정보를 저장하고 빠르게 조회하기 위해 mongoDB를, 그리고 유튜브 채널 정보를 저장하기 위해 SQLite를 사용해 CRUD기능을 처리했습니다. 현재는 작업의 자동화를 위한 REFTful API를 기반으로 작업하고 있습니다.
두서 없지만 맡은 부분에서 사용한 기술들과 경험들을 자유로운 개발 일지의 형식으로 정리하고자 합니다! ✍🏻
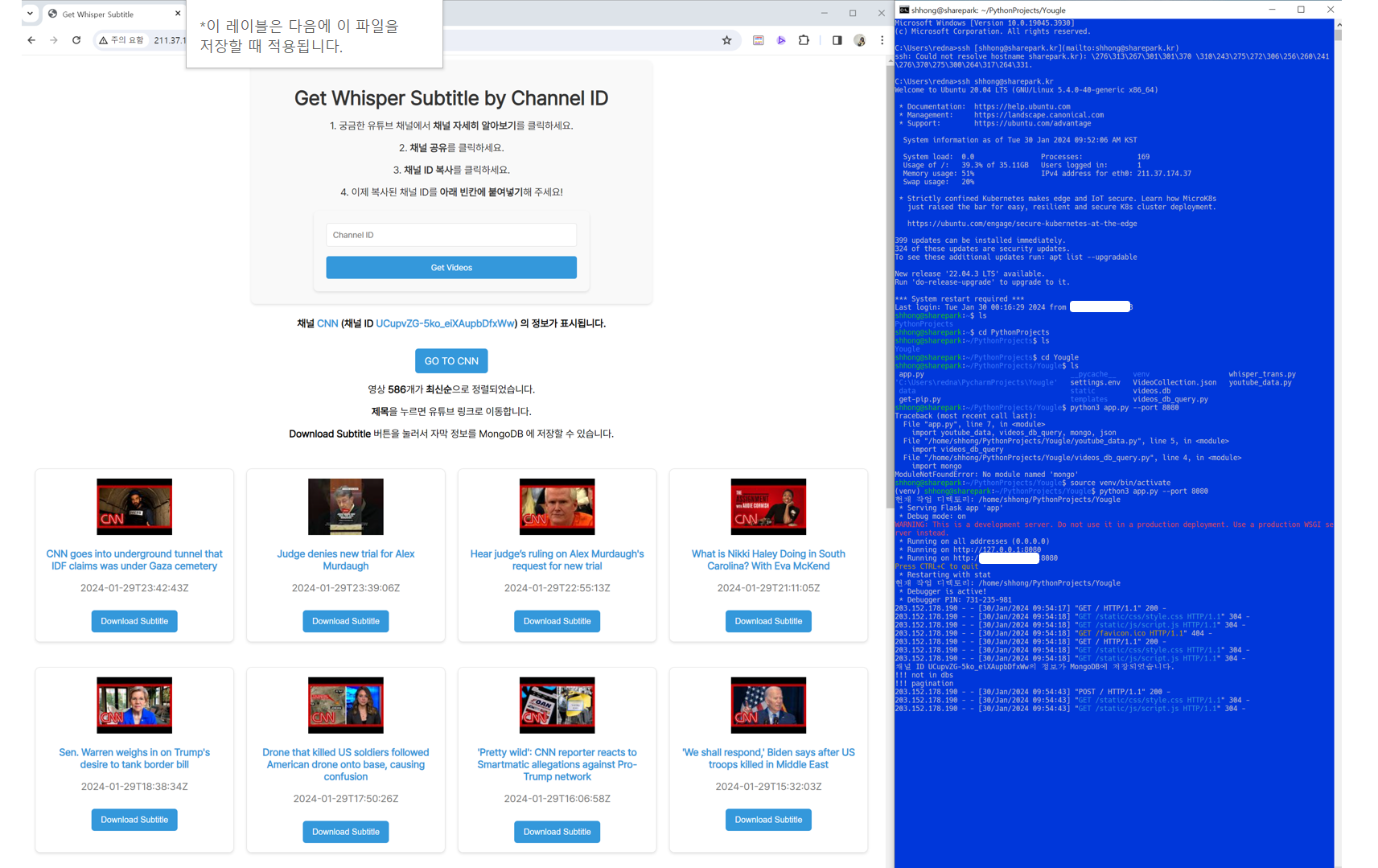
리눅스 클라우드 (SSH) 실행 화면 📌
Linux (SSH) 실행 영상 보기: https://youtu.be/iGzXvx3lXDg
담당한 기능 📌
- Schema 설계, 데이터 저장 (SQLite, MongoDB)
- Youtube 정보 처리 (Google YouTube Data API)
- Whisper 이용한 Subtitle 데이터 처리 (OpenAI Whisper)
- 관리자 페이지 구성 (HTML, CSS, Javascript)
- 관리자 페이지 (수동 버전) 실행 영상 보기 : https://youtu.be/u--PyyFtTIQ
- GPTs Action Schema, API 설계
- 현재 데이터 저장 자동화 기능을 구현 중에 있습니다.
사용 skill 📌
- Linux(Ubuntu), SSH, Vim
- Python3.9
- SQLite
- MongoDB
- Google YouTube Data API
- OpenAI Whisper
Git repository 📌
https://github.com/strurao/Yougle
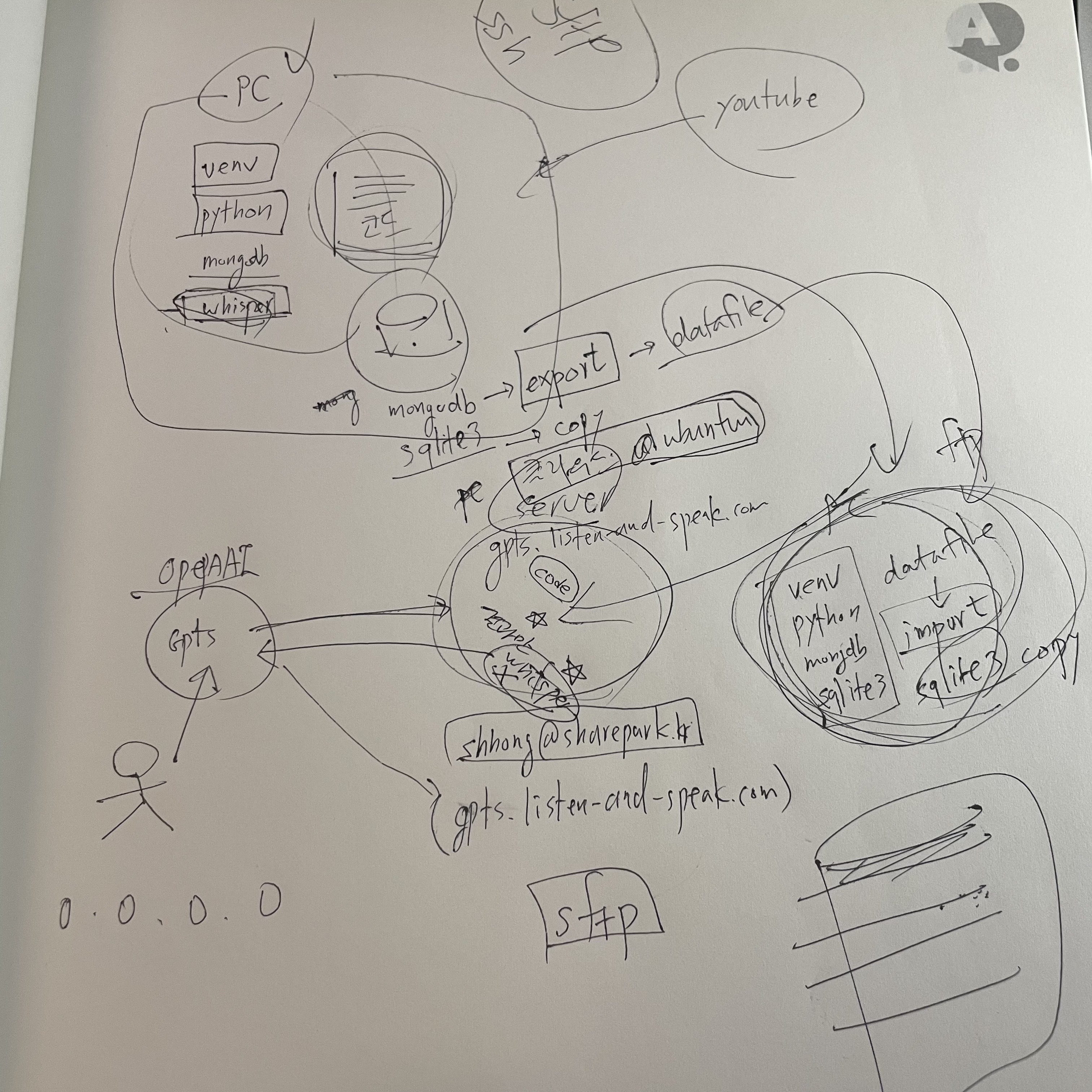
✔ 개발 회의
프로젝트를 시작하기 앞서서 전체적인 틀을 잡기 위해서, 회의를 하며 메모를 해보았습니다 :D
✔ 개발 시작! 첫 기능 구현
내가 맡은 첫 기능은 유튜브의 자막을 다운받는 것인데, 영상의 아이디값으로 입력받아서 JSON 파일로 다운받는 모듈이었다.
그래서 찾아본 API가 바로 pip install youtube-transcript-api 이다.
홈페이지에는 아래와 같은 설명이 있는데,
This is an python API which allows you to get the transcripts/subtitles for a given YouTube video. It also works for automatically generated subtitles, supports translating subtitles and it does not require a headless browser, like other selenium based solutions do!
여기서 '무헤드 브라우저(headless browser)'는 사용자 인터페이스 없이 백그라운드에서 작동하는 웹 브라우저를 의미한다. 이 API는 그러한 브라우저 없이도 YouTube 동영상의 자막을 추출할 수 있다는 장점을 강조하고 있다.
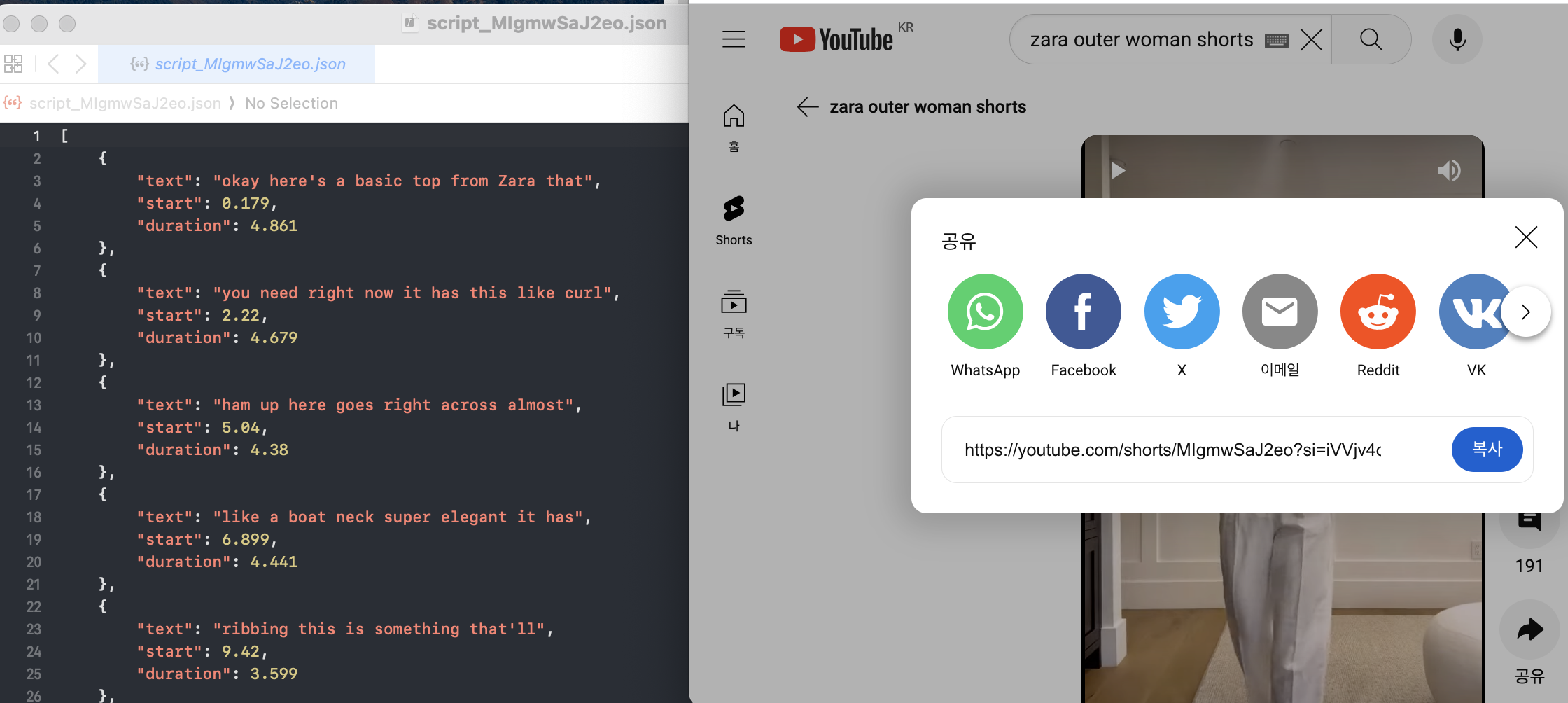
이를 활용해서아이디.json 파일로 다운받은 것을 확인할 수 있다. 한국어 자막용 예시 영상은 이 동영상에서, 그리고 영어 자막용 예시 영상은 이 동영상을 이용했다. 짧은 쇼츠 영상이라 예시로 쓰기 적당했다.
from youtube_transcript_api import YouTubeTranscriptApi
import json
def download_script_json():
video_id = input() # 예시 한글 아이디: vDXDAKh8eyo, 영어 아이디: MIgmwSaJ2eo
transcript = YouTubeTranscriptApi.get_transcript(video_id, languages=['ko', 'en'])
# 자막 데이터를 JSON 파일로 저장
with open(f'script_{video_id}.json', 'w', encoding='utf-8') as json_file:
json.dump(transcript, json_file, ensure_ascii=False, indent=4)
print(f"자막 데이터가 'script_{video_id}.json' 파일로 저장되었습니다.")
if __name__ == '__main__':
download_script_json()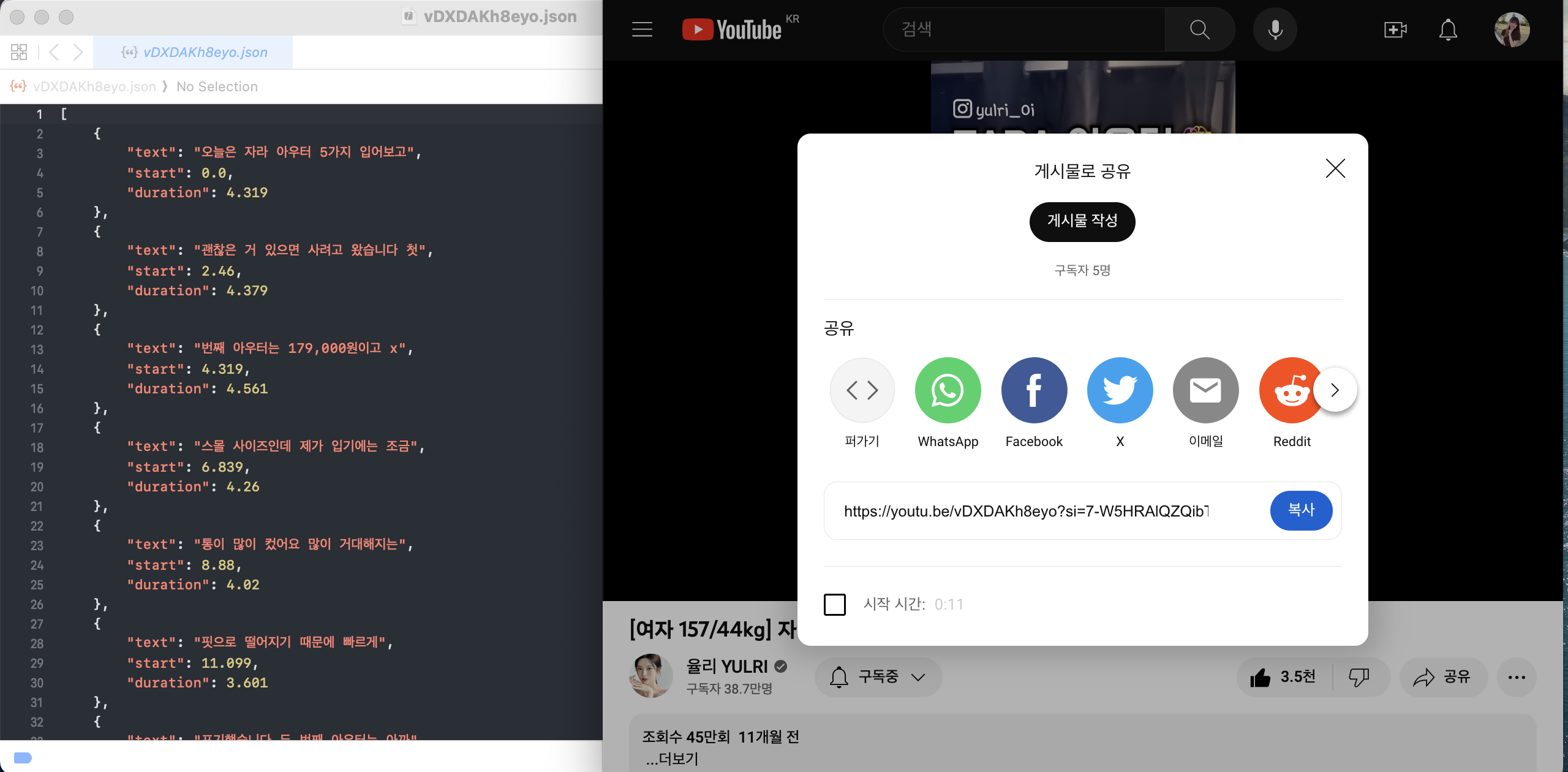
그렇다면 이제는 이 자막들이 한 문장씩 구분될 수 있도록 바꿔줘야 한다.
어떻게 해야할까? 수많은 고민 끝에.
위의 방법 대신 OpenAI의 Whisper 를 사용하기로 했다. 문장 인식이 훨씬 더 우수해서 문장 구분에 용이하기 때문.
(추가) Whisper 기능과 관련한 부분은 포스트: Whisper 설치 와 포스트: Whisper 기능 구현에서 확인해주세요!
