
회고 리스트
1. 제약 조건의 종류 5가지 는?
1) NOT NULL : NULL 입력 불가
CREATE TABLE products (
product_id INT PRIMARY KEY,
product_name VARCHAR(50) NOT NULL -- 반드시 값이 있어야 함
);2) UNIQUE : 유니크 키(중복X, NULL 가능)
CREATE TABLE employees (
id INT PRIMARY KEY,
email VARCHAR(100) UNIQUE -- 이메일 중복 불가
);3) PRIMARY KEY : 기본 키(중복X, NULLX)
CREATE TABLE students (
id INT PRIMARY KEY, -- 기본 키 설정 (중복X, NULLX)
name VARCHAR(50)
);4) FOREIGN KEY : 다른 테이블의 기본 키 참조
CREATE TABLE department (
dept_id INT PRIMARY KEY,
dept_name VARCHAR(50) NOT NULL
);
CREATE TABLE employees (
emp_id INT PRIMARY KEY,
name VARCHAR(50),
dept_id INT,
FOREIGN KEY (dept_id)
REFERENCES department(dept_id) ON DELETE CASCADE
);5) CHECK : 특정 조건을 만족해야 함
CREATE TABLE employees (
id INT PRIMARY KEY,
age INT CHECK (age >= 18) -- 18세 이상만 가능
);2. 아래의 테이블에서 age 컬럼은 20세 이상, gender 컬럼에 (남, 여)만 들어 가도록 제약조건을 주시오.
create table employees(
id int auto_increment primary key, # unique + not null
name varchar(50),
age int check(age >= 18),
gender char(1) CHECK(gender IN('M', 'F'))
);create table employees(
id int auto_increment primary key, # unique + not null
name varchar(50),
age int check(age >= 20), # 20세 이상만 가능
gender char(1) CHECK(gender IN('M', 'F')) # 'M' 또는 'F'만 허용
);3. 기본키와 외래키에 대하여 설명하시오.
- 기본키 (Primary Key)
: 테이블에서 각 행(Row)을 고유하게 식별하는 컬럼
: NOT NULL + UNIQUE (중복 X / NULL값 X)
: 한 테이블에 한 개만 존재할 수 있다.
: AUTO_INCREMENT와 함께 사용하면 자동 증가 가능.
CREATE TABLE students (
student_id INT AUTO_INCREMENT PRIMARY KEY, -- 기본 키 설정
name VARCHAR(50) NOT NULL,
age INT
);- 외래키 (Foreign Key)
: 다른 테이블의 기본키를 참조하는 키
: 테이블 간의 관계를 설정하는 역할
: 부모 테이블의 값만 참조 가능 → 참조 무결성 유지
: 부모 데이터가 삭제되거나 변경될 때의 동작을 ON DELETE / ON UPDATE 옵션으로 설정 가능하며 ON DELETE CASCADE(데이터가 삭제되면 관련 데이터도 자동 삭제)를 자주 사용한다.
4.int 의 범위는?
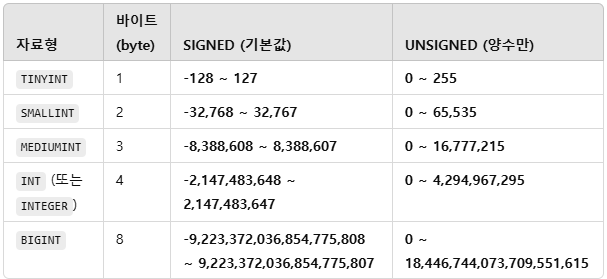
기본적으로 int는 signed이기 때문에 int의 범위는 -2,147,483,648 ~ 2,147,483,647 (약 -21억 ~ 21억)이다.
5. pymysql 을 활용하여, dept 테이블을 출력하시오.
import pymysql
import pandas as pd
import numpy as np
# MySQL Connection 연결
conn = pymysql.connect(
host = 'localhost',
user = 'scott',
password = 'tiger',
db = 'scott', charset = 'utf8')
sql = "select * from dept"
df_dept = pd.read_sql(sql, conn)
print(df_dept)
# df_dept.to_csv("dept.csv") # csv 파일에 적음
# df_dept.to_excel("dept.xlsx") # 엑셀 파일에 적음
# 단 엑셀로 저장하고 싶을 경우
# pip install openpyxl
import pymysql
# MySQL Connection 연결
conn = pymysql.connect(
host = 'localhost',
user = 'scott',
password = 'tiger',
db = 'scott', charset = 'utf8')
# Connection으로부터 Cursor 형성
# cursor 객체 생성 -> cursor 객체의 역할은 SQL 문장을 실행하고 결과를 가져오는 역할
curs = conn.cursor()
# SQL문 실행
sql = "select * from dept"
curs.execute(sql)
# 데이터 Fetch
rows = curs.fetchall()
for row in rows :
print(row)
conn.close()네줄요약)
1. int 는 4바이트, 32 비트, -21억 ~ 21억 이다.
2.delete , trucate, drop을 구분하여 쓰자
3. 트랜잭션은 일련의 작업 단위이다.
4. DB 연결시 connetion 객체 와 cursor 객체를 활용하여, 데이터를 CRUD 할수 있다.
오늘 배운 내용
DDL vs DML
- DDL (Data Definition Language)
: 데이터 정의어
: 테이블을 생성/수정/삭제하는 SQL 명령어
: CREATE, ALTER, DROP, TRUNCATE
: 자동 반영되지만 롤백 불가
: 테이블 구조 자체를 변경
- DML (Data Manipulation Language)
: 데이터 조작어
: 테이블의 데이터를 삽입 / 수정 / 삭제하는 SQL 명령어
: commit 필요하지만 롤백 가능 (커밋하기 전의 변경 내용을 되돌리기 가능)
: 테이블의 데이터만 변경
Delete / Truncate / Drop
-
Delete : 기본적인 뼈대는 남아있고 롤백 가능
-
Truncate : 기본적인 뼈대는 남아있고 롤백 불가능
-
Drop : 흔적도 없이 삭제됨
table을 drop한 후 다시 select로 보려고 하면 에러가 남
피도 눈물도 없는 drop임...
외래키 옵션
1) On Delete
- Cascade : 부모 데이터 삭제 시 자식 데이터도 삭제
- Set null : 부모 데이터 삭제 시 자식 테이블의 참조 컬럼을 Null로 업데이트
- Set default : 부모 데이터 삭제 시 자식 테이블의 참조 컬럼을 Default 값으로 업데이트
- Restrict : 자식 테이블이 참조하고 있을 경우, 데이터 삭제 불가
- No Action : Restrict와 동일, 옵션을 지정하지 않았을 경우 자동으로 선택된다.
2) On Update
- Cascade : 부모 데이터 업데이트 시 자식 데이터도 업데이트
- Set null : 부모 데이터 업데이트 시 자식 테이블의 참조 컬럼을 Null로 업데이트
- Set default : 부모 데이터 업데이트 시 자식 테이블의 참조 컬럼을 Default 값으로 업데이트
- Restrict : 자식 테이블이 참조하고 있을 경우, 업데이트 불가
- No Action : Restrict와 동일, 옵션을 지정하지 않았을 경우 자동으로 선택된다.
트랜잭션 (Transaction)
트랜잭션은 여러 개의 SQL 작업을 하나의 논리적인 단위로 묶는 것이다.
중간에 문제가 발생하면 변경사항을 취소(Rollback)할 수 있다.
Commit하면 변경내용이 확정되며 Rollback 할 수 없다.
-
START TRANSACTION; : 트랜잭션 시작
-
ROLLBACK; : 변경사항 취소 (되돌리기)
-
COMMIT; : 변경사항 확정 (저장)
-
SAVEPOINT 지점명; : 특정 지점 저장 (부분 롤백 가능)
-
SELECT @@autocommit; : 1이면 자동 커밋 모드이기 때문에 SQL 실행 즉시 저장되고 0이면 수동 커밋 모드이기 때문에 COMMIT 해야 저장된다.

