사용하는 이유
LLM(Large Language Model)은 다음과 같은 약점이 있습니다. :
-
지식 컷오프: 학습 데이터 이후의 정보를 알지 못함.
-
환각(Hallucination): 모르는 것을 그럴듯하게 지어냄.
-
출처 불투명: "어디서 나온 정보인지 추적하기 어려움.
-
등등...
주기적으로 LLM을 재학습시킨다면 약점을 일부 보완할 수 있겠지만, 비용이 매우 큽니다.
이 문제를 해결하기 위해 등장한 것이 RAG (Retrieval-Augmented Generation) 입니다. LLM에게 쿼리를 넘길 때, 정보를 DB에서 미리 찾아 같이 넘겨주는 방식으로 위와 같은 문제를 해결합니다.
RAG란?
RAG = 검색(Retrieval) + 생성(Generation)
질문에 답하기 전에, 먼저 관련 문서를 검색해서 컨텍스트로 제공하고, LLM이 그 문서를 기반으로 생성하게 하는 방법론입니다.
2020년 논문 Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks에서 처음 제안되었습니다.
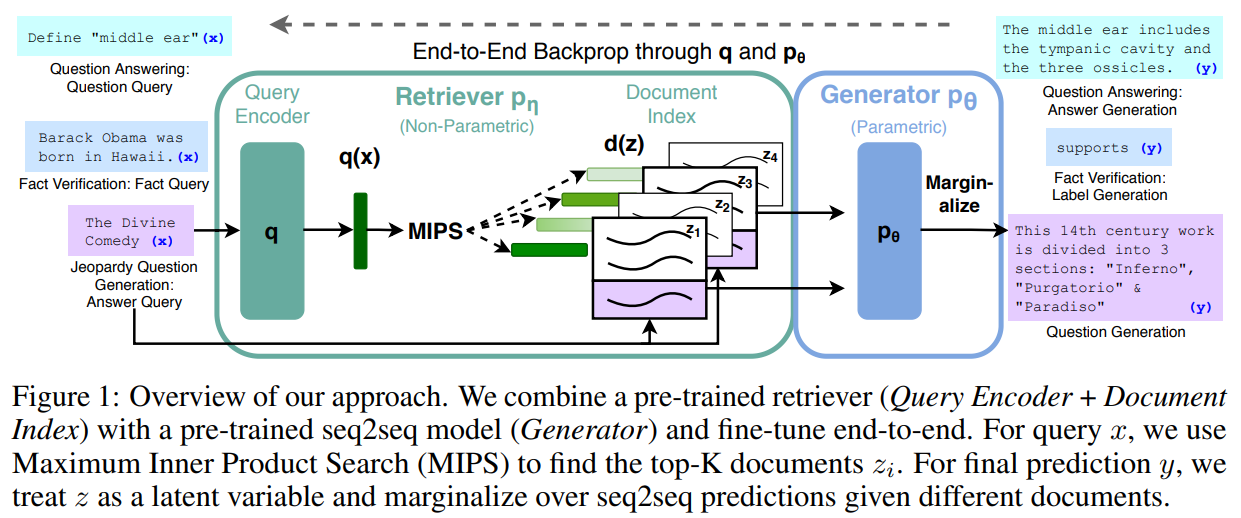 RAG 아키텍처 전체 흐름 (논문 리뷰는 아직 ㅜㅜ)
RAG 아키텍처 전체 흐름 (논문 리뷰는 아직 ㅜㅜ)
최근에는 모델의 학습이 아닌 모델의 Inference 성능을 레버리지하기 위해 주로 사용한다고 합니다.
RAG 아키텍처 구조
RAG는 크게 두 단계로 구성됩니다.
[사용자 질문]
│
▼
┌─────────────────────┐
│ Retriever │ ← 관련 문서 검색
│ (BM25 / DPR / ..)│
└─────────────────────┘
│ Top-K 문서
▼
┌─────────────────────────┐
│ Generator (LLM) │ ← 문서를 참고해서 답변 생성
│ (GPT / BART / ...) │
└─────────────────────────┘
│
▼
[최종 답변]Retriever의 종류
RAG에서 Retriever의 성능이 중요합니다. LLM이 아무리 좋아도, 엉뚱한 문서를 가져오면 답변 품질이 떨어지게 되기 때문입니다.
Retriever의 종류로든 다음과 같은 것들이 있습니다. :
Retriever
├── Sparse Retrieval
│ ├── TF-IDF
│ └── BM25
│
├── Dense Retrieval
└── DPR
| 방법 | 특징 | 장점 | 단점 |
|---|---|---|---|
| TF-IDF | 단어 빈도 기반 | 빠름, 간단 | 의미 파악 불가 |
| BM25 | TF-IDF 개선 | 실용적, 강력 | 의미 파악 불가 |
| DPR | 신경망 임베딩 | 의미 검색 가능 | 학습 필요, 느림 |
RAG 파이프라인 실습
langchain과 faiss를 사용하였습니다.
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
# 1. 문서 로드 및 청킹
loader = TextLoader("sample.txt")
docs = loader.load()
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = splitter.split_documents(docs)
# 2. 임베딩 + 벡터 스토어
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(chunks, embeddings)
# 3. RAG 체인 구성
llm = ChatOpenAI(model="gpt-4o")
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=vectorstore.as_retriever(search_kwargs={"k": 3})
)
# 4. 질의응답
result = qa_chain.run("RAG의 장점은?")
print(result)피드백이나 질문 환영합니다! 😊

컴공탈출