논문 링크 : https://arxiv.org/pdf/2212.04089
Github : http://github.com/mlfoundations/task_vectors
ICLR 2023, Gabriel Ilharco,Marco Tulio Ribeiro 외 5명
0. Abstract
- Key Idea : Pretrained model의 동작을 task vector 기반의 가중치 산술 연산으로 제어한다. Fine-tuning 결과물인 task vector를 산술적으로 조작함으로써 모델 동작을 효과적으로 제어할 수 있다. (negation / addition / analogy)
1. Introduction
기존 : Pre-trained 모델이 ML system의 backbone으로 활용됨. 모델을 downstream task에서의 성능 향상, update등을 위해 pre-training 이후 모델을 edit한다.
제안 : Task vector기반 neural network editing.
Task Vector
- Pretrained된 모델의 가중치 공간에서의 방향벡터.
- (fine-tuned weights − pre-trained weights)
- 해당 방향으로 이동할수록 특정 task에서의 성능이 향상.
Task Vector는 특정 task를 잘 수행하는데 필요한 정보를 encoding한다. 이 논문에서는 이 task vector에 대한 task arithmetic 연산을 통해 다양한 모델로 edit할 수 있음을 보인다.
- Negation : 원치않는 동작 제거, 특정 task unlearn
- Addition : better multi-task model, 단일 task 성능 향상
- Analogy : data가 부족한 task에서의 성능 향상
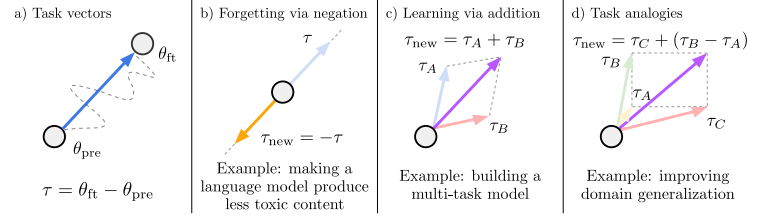
2. Task Vector
Task는 fine-tuning에 사용되는 데이터셋과 손실 함수(loss function) 로 구성된다.
수식 정의
- : 사전학습된 모델의 가중치
- : task 에 대해 fine-tuning된 모델의 가중치
- Task vector :
Task vector는 동일한 architecture의 임의의 model parameter 에 element-wise addition으로 적용할 수 있으며, 선택적 scaling 항 를 포함하여 다음과 같이 표현된다.
Scaling 항 는 held-out validation set을 통해 결정된다. 로 single task vector를 pre-trained model에 더하면 해당 task로 fine-tuning된 모델과 동일해진다.
적용 범위
새로운 parameter 도입 없이 downstream task에 fine-tuning 가능한 open-ended model에 초점을 맞춘다.
- Open-vocabulary image classifier (CLIP 등)
- Text-to-text model (T5 등)
fine-tuning 시 새로운 파라미터가 추가되는 경우(예: classification head)는 논문 연구범위 밖의 내용이다.
Task Arithmetic 연산 정리
| 연산 | 수식 | 효과 |
|---|---|---|
| Negation | pre-trained ↔ fine-tuned 사이를 extrapolate. target task 성능 저하, control task는 유지 | |
| Addition | multi-task model 생성. 개별 fine-tuned 모델 대비 성능 향상 가능 | |
| Analogy | A:B = C:D 관계일 때, 데이터 없이도 task D의 성능 향상 |
모든 연산은 가중치 벡터에 element-wise로 적용되며, 최종 모델 가중치는 동일하게 아래와 같다.
3. FORGETTING VIA NEGATION
특정 task에서 학습된 정보를 forget하는데 이용한다.
Task vector의 forgetting은 다음과 같은 경우에 필요하다:
-
Pre-training과정에서 학습된 bias 완화
-
규제 및 윤리적 이유 (OCR을 통한 개인정보 읽기 방지 등)
3.1 Image Classification
실험 설정
-
모델 : CLIP (ViT-B/32, ViT-B/16, ViT-L/14)
-
Target task (8개) : Cars, DTD, EuroSAT, GTSRB, MNIST, RESISC45, SUN397, SVHN
-
Control task : ImageNet
-
비교 baseline :
- Gradient ascent : loss가 증가하는 방향으로 fine-tuning
- Random vector : task vector와 각 layer의 magnitude는 같지만 방향은 랜덤 (task vector의 방향성이 실제로 의미있는가? 확인 가능)
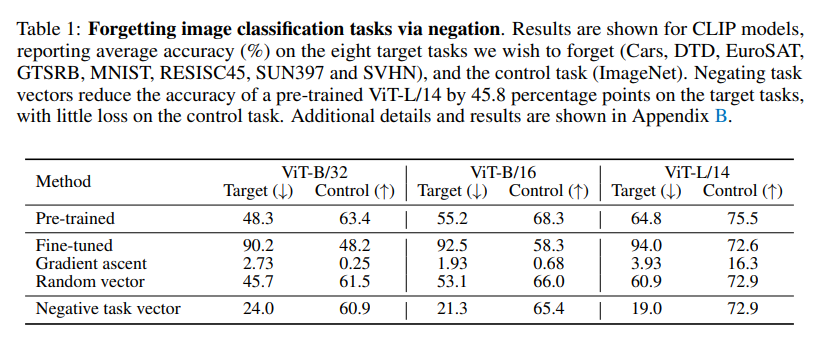
(ViT-L/14 기준)
-
Negative task vector : target 정확도 45.8%p 감소, control(ImageNet) 정확도 거의 유지
-
Gradient ascent : target은 낮추지만 control task 성능이 심각하게 저하
-
Random vector : target / control 모두 거의 변화 없음
3.2 Text Generation
실험 설정
-
모델 : GPT-2 (Large)
-
목표 : toxic generation 비율 감소
-
Task vector 생성 : toxicity score > 0.8인 Civil Comments 데이터로 fine-tuning 후 negation
-
평가 지표 :
- % toxic generations, Avg. toxicity score (↓)
- Control task : WikiText-103 perplexity (↓)
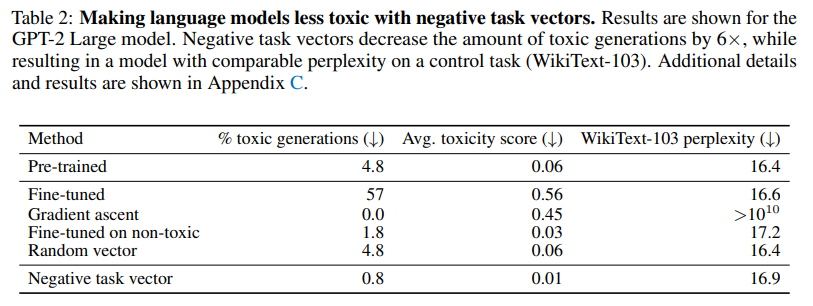
-
Negative task vector : toxic 생성 비율 4.8% → 0.8% (약 6배 감소), perplexity는 pre-trained 대비 0.5 차이로 유지
-
Gradient ascent : toxic은 줄이지만 perplexity가 10¹⁰ 이상으로 붕괴 → 사실상 언어 능력 상실
-
Non-toxic data fine-tuning : task vector보다 toxic 감소 효과도 낮고 perplexity도 더 높음
4. LEARNING VIA ADDITION
Addition 연산을 통해 더 나은 multi-task model을 만들거나 단일 task의 성능을 향상시킬 수 있다. 추가 학습이나 학습 데이터 없이 기존 fine-tuned model의 지식을 재사용/전이할 수 있다.
4.1 Image Classification
실험 설정
- Section 3과 동일한 8개 task (Cars, DTD, EuroSAT, GTSRB, MNIST, RESISC45, SUN397, SVHN)
- 정확도는 각 task의 fine-tuned model 정확도로 normalize (fine-tuned = 1.0 기준)
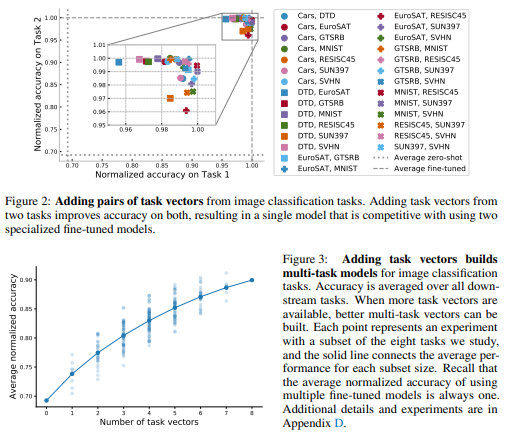
결과
- Task vector 2개를 더한 경우 → 평균 98.9% normalized accuracy (전문 fine-tuned 모델 2개를 사용하는 것과 경쟁력 있는 수준)(참고: Figure 2)
- Task vector 수가 늘어날수록 multi-task model 성능 향상(참고: Figure 3)
- 8개 전부 더했을 때 최고 성능 → 평균 91.2% (여러 모델을 하나로 압축했음에도 불구하고)
4.2 Natural Language Processing
단일 task 성능 향상에도 addition이 유효한지 탐색한다.
실험 설정
- 모델 : T5-base
- Task : GLUE benchmark 4개 (MRPC, RTE, CoLA, SST-2)
- Hugging Face Hub에서 호환 가능한 체크포인트 427개 탐색 → validation 기준으로 최적 task vector 선택
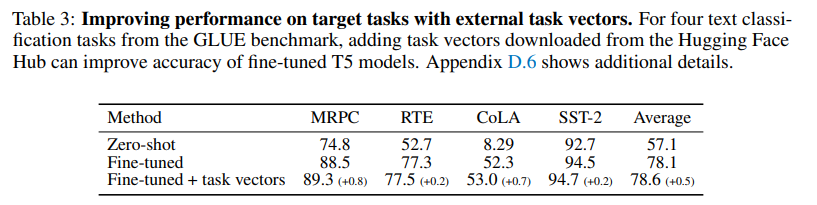
- 외부 task vector를 더하는 것만으로 fine-tuned 모델 대비 모든 task에서 성능 향상
- 추가 학습 없이 Hugging Face Hub의 공개 체크포인트를 활용할 수 있음
5. TASK ANALOGIES
"A와 B의 관계는 C와 D의 관계와 같다"는 형태의 task analogy를 구성할 수 있을 때, 앞의 세 task의 task vector를 조합하면 학습 데이터가 거의 없는 네 번째 task D의 성능도 향상된다.
5.1 Domain Generalization
target task의 labeled data가 없을 때, unlabeled data는 있는 경우에 task analogy를 활용할 수 있다.
예시 : Yelp 감성 분석을 target task로 할 때
- : Amazon 데이터로 fine-tuning한 감성 분석 task vector (auxiliary)
- , : 각 도메인의 unlabeled data로 학습한 language modeling task vector
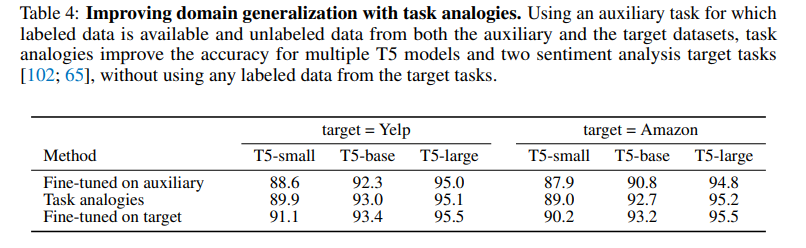
(target = Yelp 기준)
- Task analogy가 auxiliary task fine-tuning보다 모든 모델 크기에서 성능 향상
- Target task labeled data 없이도 fine-tuned on target에 근접한 성능 달성
5.2 Subpopulations with Little Data
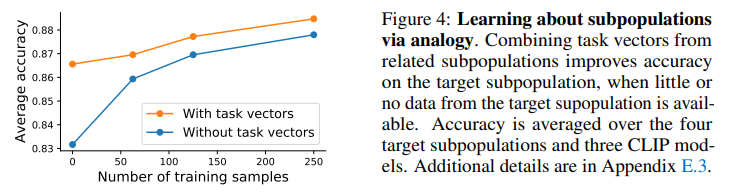
데이터가 부족한 subpopulation에도 analogy를 적용할 수 있다.
예시 : "real dog", "real lion", "sketch dog", "sketch lion" 4개의 subpopulation
결과
- Pre-trained 모델 대비 평균 3.4%p 정확도 향상
- Analogy만으로 얻는 효과 ≈ target subpopulation의 약 100개 학습 샘플을 수집/annotation하는 것과 동일한 효과
- Target subpopulation 데이터가 일부 있는 경우, edited model에서 시작하면 pre-trained model에서 시작하는 것보다 일관되게 높은 정확도 달성
5.3 Kings and Queens
이미지 분류기가 analogy 관계에 있는 세 클래스(예: "queen", "man", "woman")의 데이터만으로 새로운 카테고리(예: "king")를 학습할 수 있는지 탐색한다. Target category의 학습 데이터가 전혀 없음에도 pre-trained model 대비 큰 폭의 정확도 향상을 보인다.
6. DISCUSSION
6.1 Task Vector 간 유사도
Task vector들은 대체로 서로 직교(orthogonal)에 가깝다. 이것이 addition 시 task vector들 간의 간섭(interference)을 최소화하여 multi-task model로의 결합을 가능하게 한다고 추측한다.
의미적으로 유사한 task일수록 cosine similarity가 높게 나타난다.
- MNIST, SVHN, GTSRB : 숫자 인식 능력이 공통적으로 필요한 task → 유사도 높음
- EuroSAT, RESISC45 : 둘 다 위성 이미지 인식 데이터셋 → 유사도 높음

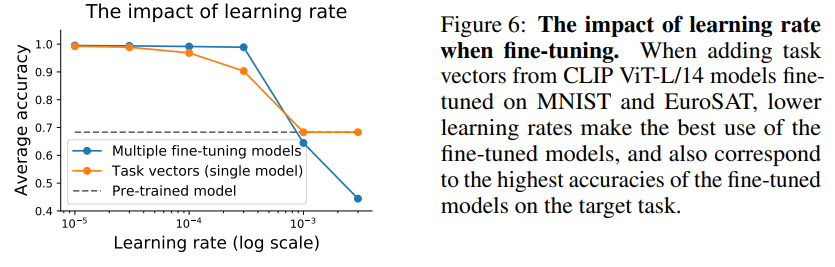
6.2 Learning Rate의 영향
Learning rate가 높아질수록 task vector와 개별 fine-tuning 모두 정확도가 저하되지만, 개별 모델 fine-tuning보다 task vector 사용 시 더 가파르게 저하된다.
- 개별 모델 fine-tuning : 높은 learning rate도 어느 정도 허용 가능
- Task vector 사용 시 : 낮은 learning rate 권장
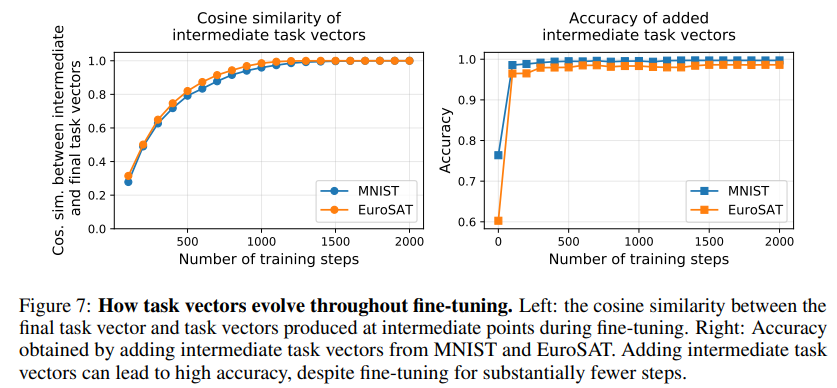
6.3 Fine-tuning 과정에서 Task Vector의 변화
중간 단계의 task vector는 최종 task vector 방향으로 빠르게 수렴한다. 또한 두 이미지 분류 task의 중간 task vector를 더했을 때의 정확도는 수백 step 만에 포화(saturate) 된다.
→ 중간 단계의 task vector를 사용하는 것이 정확도 손실 없이 연산량을 줄이는 방법이 될 수 있다.
6.4 Limitations
- Task vector는 동일한 architecture 모델에만 적용 가능 (element-wise 연산에 의존하기 때문)
- 모든 실험에서 동일한 pre-trained initialization에서 fine-tuning된 모델에만 산술 연산 적용
- 단, 동일 architecture는 실용적으로 큰 제약이 아닐 수 있음
- Hugging Face Hub 기준, 동일한 BERT-base initialization으로 fine-tuning된 모델 3,000개 이상
- 동일한 T5-small initialization 기반 모델 800개 이상
7. RELATED WORK
7.1 Loss Landscape & Weight Interpolation
신경망은 비선형임에도 불구하고, optimization trajectory를 공유하는 두 모델의 가중치를 interpolation하면 높은 정확도를 유지할 수 있음이 실험적으로 밝혀졌다.
Fine-tuning 맥락에서:
- Pre-trained 모델의 가중치를 fine-tuned 방향으로 이동할수록 정확도가 꾸준히 향상
- 동일한 initialization에서 여러 task로 fine-tuning된 모델들의 가중치를 averaging하면 성능 향상 가능
- 본 논문은 단순 interpolation을 넘어 extrapolation 및 추가적인 결합 방식(negation, analogy) 까지 탐구
7.2 Model Interventions
Re-training이 대부분의 경우 비용이 너무 크기 때문에, pre-training 이후 모델 동작을 수정하는 효율적인 방법들이 연구되어 왔다. (patching, editing, aligning, debugging 등)
기존 연구와의 차별점:
- 기존 : hidden state에 벡터를 더하는 방식으로 language model을 steering
- 본 논문 : weight space에서 벡터를 적용하며, 표준 fine-tuning 절차를 수정하지 않음
- 기능을 모듈 방식으로 추가/삭제 가능한 고유한 모델 편집 방식 제안
7.3 Task Embeddings
task를 continuous embedding으로 표현하여 task 유사도, transferability 예측, 분류 체계 생성 등에 활용하는 연구들이 존재한다. Task vector도 유사한 목적으로 활용될 수 있으나, 본 논문의 주목적은 pre-trained model의 동작을 steering하는 도구로 사용하는 것이다. 또한 기존 연구와 달리 model weight의 선형 결합만을 사용한다.
8. CONCLUSION
Task vector에 대한 산술 연산 기반의 새로운 모델 편집 패러다임을 제안한다.
- Addition : 여러 task vector를 더해 단일 multi-task model 생성, 또는 단일 task 성능 향상
- Negation : 독성 생성 등 원치 않는 동작 제거, 또는 특정 task를 완전히 forget하면서도 나머지 성능 유지
- Analogy : 데이터가 부족한 도메인/subpopulation에서 기존 데이터를 활용해 성능 향상
Task vector 연산은 가중치의 덧셈/뺄셈만으로 구성되어 연산이 효율적이며, 결과 모델의 크기가 동일하므로 추가적인 inference 비용이 없다. 공개된 수많은 fine-tuned model로부터 지식을 재활용/전이할 수 있어 실용적이다.
정리
- 추가 학습이나 데이터 없이 가중치 연산으로 모델을 edit할 수 있으면 inference 비용 증가 없이 실용적인 모델 편집이 가능하다.
- 즉 task vector를 만들때 fine-tuning 한 번 하면 이를 활용(edit)할 때는 추가학습이 더이상 필요없다.
