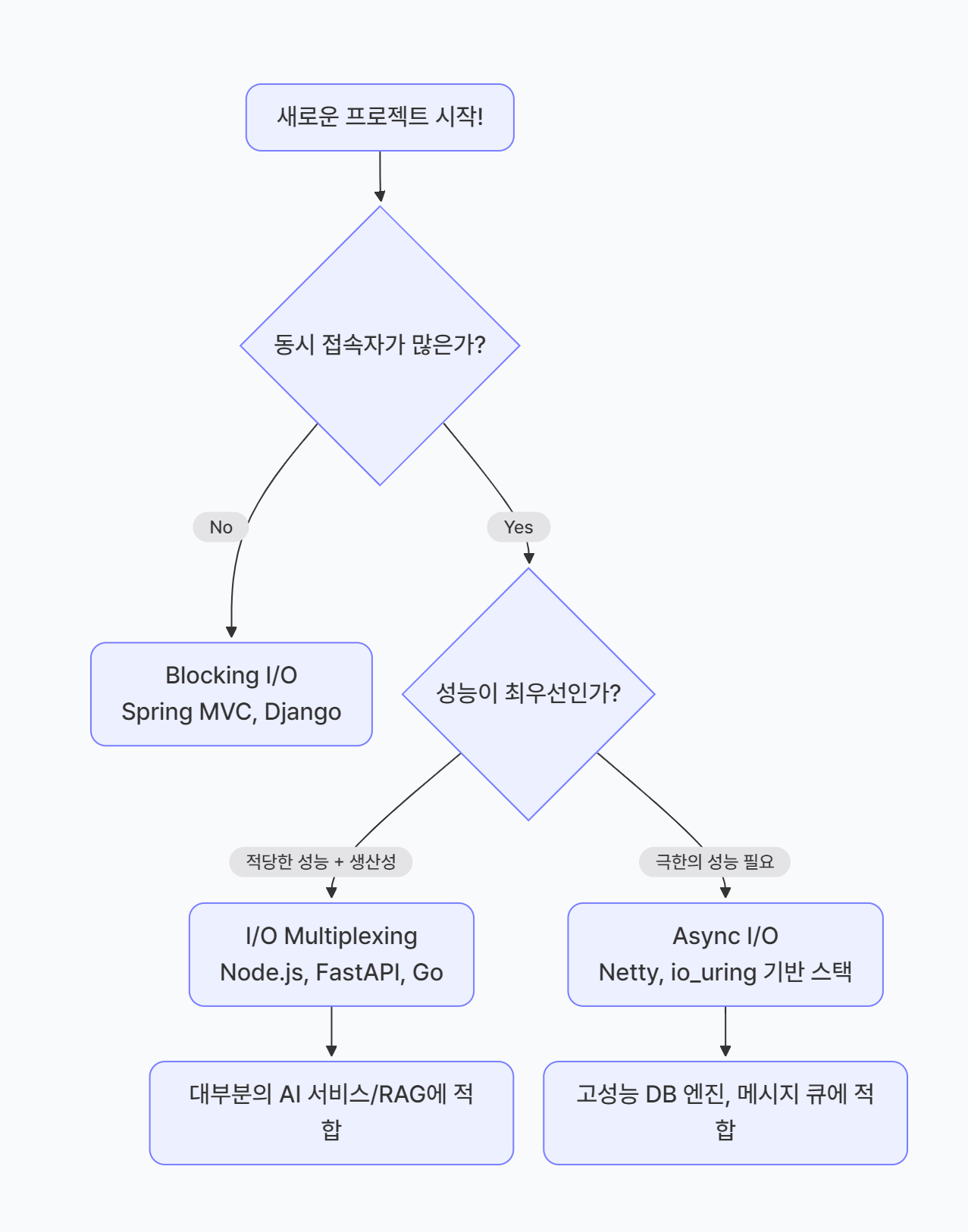
1. 왜 I/O 모델을 이해해야 하는가?
모든 네트워크 서버, 데이터베이스 클라이언트, 파일 시스템 작업의 성능은 I/O를 어떻게 처리하느냐에 달려 있다.
초당 수만 건의 요청을 처리하는 현대 서버(Nginx, Node.js, Netty 등)가 가능해진 핵심 배경이 바로 I/O 모델의 진화이다.
✨ I/O란 무엇인가?
I/O(Input/Output)란 프로세스가 외부 장치나 커널과 데이터를 주고받는 모든 작업을 말한다. 하지만 CPU의 연산 속도에 비해 외부 장치(네트워크, 디스크)의 속도는 수천~수만 배 느리다.
-
I/O Bound vs. CPU Bound: 현대의 많은 서비스(특히 AI, 웹 서버)는 CPU 연산보다 I/O를 기다리는 시간이 훨씬 긴 I/O Bound 특성을 가진다.
-
성능의 핵심: "기다리는 시간(Wait) 동안 CPU가 놀지 않고 다른 일을 할 수 있는가?"가 고성능 서버의 성패를 결정한다.
I/O 종류 예시 특징 Network I/O 소켓 read/write, HTTP 요청/응답 지연 시간 불확실 (ms~sec) Disk I/O 파일 읽기/쓰기, DB 쿼리 HDD 수 ms, SSD 수십 μs Device I/O 키보드 입력, 마우스 이벤트 사용자 의존적, 완전 비예측 IPC 파이프, 메시지 큐, 공유 메모리 커널 중재 필요
✨ User Space vs. Kernel Space
I/O 모델을 이해하려면 두 공간의 분리를 반드시 알아야 한다. OS가 메모리 공간을 둘로 나눈 이유는 안전 때문이다.
┌─────────────────────────────────────┐
│ User Space │
│ ┌────────────┐ ┌────────────┐ │
│ │ Process A │ │ Process B │ │
│ └────┬───────┘ └─────┬──────┘ │
│ │ system call │ │
├────────┼────────────────┼───────────┤ ← 권한 경계 (Ring 3 → Ring 0)
│ ▼ ▼ │
│ Kernel Space │
│ ┌────────────────────────────┐ │
│ │ I/O Subsystem │ │
│ │ ┌───────┐ ┌──────────┐ │ │
│ │ │Socket│ │FileSystem│ │ │
│ │ │Buffer│ │ Cache │ │ │
│ │ └───────┘ └──────────┘ │ │
│ └────────────────────────────┘ │
│ ┌───────────────────────────┐ │
│ │ Device Drivers / NIC │ │
│ └───────────────────────────┘ │
└────────────────────────────────────┘| 구분 | User Space (유저 영역) | Kernel Space (커널 영역) |
|---|---|---|
| 주체 | 우리가 만든 일반 애플리케이션 | OS 핵심 로직, 하드웨어 드라이버 |
| 권한 | 제한적 (Ring 3) | 모든 자원 접근 가능 (Ring 0) |
| I/O 수행 | 직접 수행 불가능 | 커널만이 직접 수행 가능 |
| 안전성 | 프로세스가 죽어도 시스템은 안전함 | 커널이 죽으면 시스템 전체가 멈춤 |
- 핵심 포인트
프로세스는 직접 하드웨어에 접근할 수 없다. 반드시 시스템 콜(system call)을 통해 커널에 I/O를 요청해야 하며, 커널이 작업을 수행한 뒤 결과를 User Space로 복사해 준다.
✨ I/O 작업의 2단계
모든 I/O 모델을 구분하는 가장 중요한 기준이다. 시스템 콜이 발생하면 커널은 다음 두 단계를 거친다.
- Wait 단계 (데이터 준비 단계)
- 네트워크 패킷이 NIC에 도착해 커널 버퍼에 쌓이거나, 디스크의 데이터가 커널 메모리로 올라올 때까지 기다리는 시간이다.
- Blocking/Non-blocking의 차이가 여기에서 발생한다. (기다릴 것인가, 바로 리턴할 것인가)
⭐ NIC (Network Interface Card)
컴퓨터가 네트워크(예: 로컬 네트워크 또는 인터넷)와 통신할 수 있도록 하는 핵심 하드웨어 장치
- Copy 단계 (데이터 복사 단계)
- 커널 버퍼에 준비된 데이터를 유저 프로세스의 메모리 공간으로 복사하는 과정이다.
- 이 과정은 메모리 간 복사라 매우 빠르지만, 대부분의 모델에서 이 단계 동안은 프로세스가 멈춘다(Block).
✨ 컨텍스트 스위칭(Context Switching)의 비용
유저 영역에서 커널 영역으로 넘어가는 시스템 콜은 공짜가 아니다.
- 오버헤드 발생: CPU의 레지스터 상태를 저장하고, 권한을 변경하고, 다시 복구하는 과정에서 많은 자원이 소모된다.
- I/O 모델의 목표: 불필요한 시스템 콜 횟수를 줄이고, 컨텍스트 스위칭으로 인한 낭비를 최소화하는 것이 고성능 아키텍처의 핵심이다.
2. Blocking I/O
✨ 동작 흐름
Blocking I/O의 핵심은 "데이터가 유저 버퍼에 복사될 때까지 프로세스의 제어권이 돌아오지 않는다"는 점이다.
Application Kernel
│ │
│────────── recvfrom() ────────────▶│
│ (system call) │
│ │ 데이터 없음...
│ ⏳ 프로세스 BLOCKED │ NIC에서 패킷 대기 중
│ (Sleep 상태로 전환) │
│ │ ... 시간 경과 ...
│ │
│ │ ✅ 데이터 도착!
│ │ 커널 버퍼에 적재
│ │ 커널 버퍼 → 유저 버퍼 복사
│ │
│◀────────── 데이터 반환 ────────────│
│ │
│ 이제서야 다음 코드 실행 │
▼ ▼✨ 코드로 이해하기
-
C언어 Blocking I/O 소켓 예제
int sockfd = socket(AF_INET, SOCK_STREAM, 0); // ... bind, listen 생략 ... int client_fd = accept(sockfd, NULL, NULL); // Blocking -> 클라이언트 연결까지 멈춤 char buffer[1024]; ssize_t n = read(client_fd, buffer, sizeof(buffer)); // Blocking -> 데이터 올 때까지 멈춤 // 이 줄은 read()가 반환될 때까지 절대 실행되지 않음 printf("Received: %s\n", buffer);- 소켓 생성 (socket)
int sockfd = socket(AF_INET, SOCK_STREAM, 0);- 의미: 네트워크 통신을 할 수 있는 '대문(소켓)'을 하나 만들자는 뜻이다.
SOCK_STREAM은 신뢰성 있는 연결인 TCP를 쓰겠다는 의미이다.
- 의미: 네트워크 통신을 할 수 있는 '대문(소켓)'을 하나 만들자는 뜻이다.
- 연결 대기 (accept) - 첫 번째 Blocking 포인트
int client_fd = accept(sockfd, NULL, NULL);- 의미: 클라이언트가 소켓에 접속할 때까지 대기한다.
- Blocking 발생: 클라이언트가 접속할 때까지 프로그램은 이 줄에서 꼼짝도 안 하고 멈춰 있는다. 접속이 성공해야만 다음 줄로 넘어가며
client_fd라는 전용 통로를 돌려준다.
- 데이터 읽기 (read) - 두 번째 Blocking 포인트
ssize_t n = read(client_fd, buffer, sizeof(buffer));- 의미: 연결된 클라이언트가 보내는 데이터를 읽는다.
- Blocking 발생: 손님이 말을 걸 때까지(데이터가 NIC를 통해 들어올 때까지) 프로그램은 또 여기서 무한 대기에 들어간다.(Wait 상태) 데이터가 다 들어와서 유저 버퍼로 복사(Copy)가 끝나야만 비로소 리턴된다.
- 결과 출력 (printf)
printf("Received: %s\n", buffer);- 의미: 받은 데이터를 출력한다.
- 특징: 앞선
read()가 끝나기 전까지는 이 줄은 절대 실행되지 않는다.
- 소켓 생성 (socket)
-
Python Blocking I/O 예제
import socket server = socket.socket(socket.AF_INET, socket.SOCK_STREAM) server.bind(('0.0.0.0', 8080)) server.listen(5) conn, addr = server.accept() # Blocking: 클라이언트 접속 때까지 정지 data = conn.recv(1024) # Blocking: 데이터 수신까지 정지 print(f"Received: {data}")- 서버 준비 (socket, bind, listen)
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM) server.bind(('0.0.0.0', 8080)) server.listen(5)- 의미: "8080번 포트에서 손님을 받을 준비를 하자"라는 뜻이다.
listen(5)는 대기실(큐)에 최대 5명까지 줄을 세울 수 있다는 설정이다.
- 의미: "8080번 포트에서 손님을 받을 준비를 하자"라는 뜻이다.
- 손님 맞이 (accept) - 첫 번째 Blocking 포인트
conn, addr = server.accept()- 의미: 클라이언트가 소켓에 접속할 때까지 대기한다.
- Blocking 발생: 클라이언트가 접속하기 전까지 파이썬 인터프리터는 이 줄에 멈춰 서서 다음 줄로 넘어가지 않는다. 접속이 일어나는 순간, 손님과 대화할 수 있는 전용 전화기(
conn)와 손님의 주소(addr)를 들고 깨어난다.
- 대화 듣기 (recv) - 두 번째 Blocking 포인트
data = conn.recv(1024)- 의미: 상대방이 데이터를 보낼 때까지 기다린다.
- Blocking 발생: 상대방이 데이터를 보내기 전까지 프로그램은 또 여기서 멈춘다.(Wait 상태) 데이터가 도착해서 커널이 유저 영역으로 복사(Copy)를 끝내줘야만 비로소
data변수에 값을 담고 다음으로 넘어간다.
- 결과 출력 (print)
print(f"Received: {data}")- 의미: 받은 데이터를 출력한다.
- 특징: 앞의
recv()가 끝나기 전까지는 이 출력문은 절대 실행되지 않는다.
- 서버 준비 (socket, bind, listen)
✨ Blocking I/O의 근본적 문제
- 1 Connection = 1 Thread 강제
Client A ──▶ Thread 1 (read에서 Block 중... 아무것도 못 함) Client B ──▶ Thread 2 (read에서 Block 중... 아무것도 못 함) Client C ──▶ Thread 3 (read에서 Block 중... 아무것도 못 함) ... Client N ──▶ Thread N (read에서 Block 중... 아무것도 못 함)문제 요인 설명 실제 수치 아키텍처적 영향 메모리 낭비(고갈) 스레드 하나당 고정된 스택 메모리가 필요함 Linux 기본 thread당 8MB → 1000개 = 8GB 동시 접속자 수의 물리적 한계 발생 컨텍스트 스위칭 스레드가 많아지면 CPU가 실제 일하는 시간보다 스레드를 갈아끼우는 시간이 더 길어짐 수천 스레드 → CPU 시간의 상당 부분을 스위칭에 소모 시스템 전체의 처리량(Throughput)급감 CPU 유휴 (리소스 낭비) I/O 작업은 CPU를 거의 쓰지 않는데, 스레드는 아무것도 못하고 점유만 함 대부분의 시간을 Sleep 상태로 허비 하드웨어 자원(CPU, RAM)의 낮은 가동률 확장성 한계 (연쇄 지연) 하나의 작업이 늦어지면 해당 스레드를 기다리는 다른 작업들도 줄줄이 지연됨 전통적 Apache prefork 방식의 한계 서비스 전체의 응답성(Responsiveness) 저하
-
Thread Pool로도 한계가 있다: 스레드 기아(Starvation)
Thread Pool을 쓰면 무한정 스레드가 늘어나는 건 막을 수 있지만, 더 큰 문제가 생긴다.-
상황: Thread Pool 크기가 200개인데, 200명의 사용자가 아주 느린 네트워크 환경에서 접속했다.
-
결과: 200개의 스레드가 모두
read()에서 Block 되어버린다. -
현상: 201번째 사용자는 아주 가벼운 요청을 보내도, 빈 스레드가 없어서 큐에서 무한 대기하게 된다. 이걸 스레드 기아 상태라고 부른다.
-
결론: 결국 Blocking 방식은 "기다리는 행위" 자체가 스레드를 점유하기 때문에, 풀을 아무리 잘 관리해도 근본적인 확장성 문제를 해결할 수 없다.
-
코드 예시
// Java Thread Pool 방식 - 개선되었지만 여전히 Blocking ExecutorService pool = Executors.newFixedThreadPool(200); while (true) { Socket client = serverSocket.accept(); pool.submit(() => { InputStream in = client.getInputStream(); byte[] buf = new byte[1024]; int n = in.read(buf); // 여전히 Blocking (풀의 스레드를 점유) // ... }); } // 동시 접속이 200개를 넘으면? → 큐에서 대기 → 응답 지연 시작- 일꾼 200명 고용 (Thread Pool)
ExecutorService pool = Executors.newFixedThreadPool(200);- 의미: "우리 가게에 일 잘하는 직원(스레드) 200명을 미리 뽑아두자."
- 장점: 손님이 올 때마다 매번 직원을 새로 뽑는(스레드 생성) 비용을 아낄 수 있다.
- 손님 맞이 (accept) - 메인 스레드의 Blocking
Socket client = serverSocket.accept();- 의미: 사장님(메인 스레드)은 문앞에서 손님이 올 때까지 기다린다.
- 특징: 손님이 오면 사장님은 직접 서빙하지 않고, 미리 뽑아둔 직원 중 한 명에게 손님을 맡긴다(
pool.submit). 그리고 사장님은 바로 다음 손님을 맞으러 간다. 이건 개선된 점이다.
- 데이터 읽기 (read) - 직원 스레드의 Blocking
int n = in.read(buf);- 의미: 사장님에게 손님을 넘겨받은 직원(스레드)이 손님을 말을 듣는다.
- 여전한 Blocking: 직원은 손님이 말을 할 때까지(데이터가 올 때까지) 그 자리에서 꼼짝도 못 하고 멈춰 있는다.
- 일꾼 200명 고용 (Thread Pool)
-
3. Non-Blocking I/O
✨ 동작 흐름
Non-blocking의 핵심은 커널이 데이터가 준비되지 않았더라도 프로세스를 WAIT 큐에 넣지 않고 즉시 리턴시킨다는 점이다.
Application Kernel
│ │
│────── recvfrom() ────────────────▶│
│ │ 데이터 없음
│◀───── EWOULDBLOCK 즉시 반환 ──────│
│ │
│ 다른 작업 수행 가능! ✅ │
│ │
│────── recvfrom() ────────────────▶│
│ │ 아직 데이터 없음
│◀───── EWOULDBLOCK 즉시 반환 ──────│
│ │
│ 다른 작업 수행 ✅ │
│ │
│────── recvfrom() ────────────────▶│
│ │ ✅ 데이터 준비됨!
│ │ 커널 버퍼 → 유저 버퍼 복사
│◀───── 데이터 반환 (n bytes) ──────│
│ │
▼ ▼✨ 코드로 이해하기
-
C언어 Non-Blocking I/O 설정
#include <fcntl.h> int sockfd = socket(AF_INET, SOCK_STERAM, 0); // 소켓을 Non-Blocking 모드로 설정 int flags = fcntl(sockfd, F_GETFL, 0); fcntl(sockfd, F_SETFL, flags | O_NONBLOCK); char buffer[1024]; while (1) { ssize_t n = read(sockfd, buffer, sizeof(buffer)); if (n > 0) { // 데이터를 성공적으로 읽음 process_data(buffer, n); } else if (n == -1 && errno == EWOULDBLOCK) { // 아직 데이터 없음 → 다른 작업 수행 do_other_work(); } else if (n == 0) { // 연결 종료 break; } }- 소켓의 성격 바꾸기 (fcntl)
int flags = fcntl(sockfd, F_GETFL, 0); fcntl(sockfd, F_SETFL, flags | O_NONBLOCK);- 의미: 원래 소켓은 만들면 기본적으로 Blocking 모드이다.
fcntl함수를 써서O_NONBLOCK플래그를 꽂아주면, 이제 이 소켓은 데이터가 없어도 절대 멈추지 않는 성격을 갖게 된다.
- 의미: 원래 소켓은 만들면 기본적으로 Blocking 모드이다.
- 멈추지 않는 읽기 (read)
ssize_t n = read(sockfd, buffer, sizeof(buffer));- 의미: "데이터 있으면 가져오고, 없으면 바로 말해줘."
- 차이점: Blocking 코드였다면 여기서 데이터가 올 때까지 프로그램이 멈췄겠지만, 이제는 데이터가 있든 없든 0.00001초 만에 결과를 듣고 다음 줄로 넘어간다.
- 세 가지 경우의 수 처리 (if-else)
read()가 즉시 리턴한 결과(n)에 따라 세 가지 길로 나뉜다.- 데이터가 온 경우 (
n > 0)- "오, 데이터가 왔네! 얼른 처리하자(
process_data)."
- "오, 데이터가 왔네! 얼른 처리하자(
- 데이터가 아직 없는 경우 (
n == -1 && errno == EWOULDBLOCK)- 핵심: 이게 바로 Non-blocking의 묘미이다. 커널이 "지금은 데이터가 없어서 원래라면 널 멈추게(Block) 해야 하는데, 네가 그러지 말라며? 그래서 대신 EWOULDBLOCK이라는 에러를 줄게"하고 답하는 것이다.
- 결과: 프로그램은 멈추지 않고
do_other_work()를 실행하며 댜른 일을 할 수 있게 된다.
- 연결이 끊긴 경우 (
n == 0)- "상대방이 전화를 끊었네. 루프를 나가자(
break)."
- "상대방이 전화를 끊었네. 루프를 나가자(
- 데이터가 온 경우 (
- 소켓의 성격 바꾸기 (fcntl)
-
Python Non-Blocking I/O 예제
import socket server = socket.socket(socket.AF_INET, socket.SOCK_STREAM) server.setblocking(False) # Non-Blocking 모드 설정 server.bind(('0.0.0.0', 8080)) server.listen(5) while True: try: conn, addr = server.accept() except BlockingIOError: # 아직 연결 요청 없음 → 다른 작업 수행 가능 do_other_work() continue- "기다리지 마!" 설정 (setblocking)
server.setblocking(False)- 의미: 원래
accept()는 손님이 올 때까지 무한정 기다리지만(Blocking), 이 설정을 하면 "손님이 없으면 기다리지 말고 바로 나한테 알려줘!"라고 명령하는 것이다.
- 의미: 원래
- 일단 시도해보기 (try-accept)
try: conn, addr = server.accept()- 의미: "지금 문앞에 손님 와 있어? 있으면 바로 들여보내줘."
- 결과
- 손님이 있으면?
conn과addr를 들고 기분 좋게 다음 줄로 넘어간다. - 손님이 없으면? 파이썬은
BlockingIOError라는 예외를 즉시 발생시킨다. (이게 바로 Non-blocking의 신호이다.)
- 손님이 있으면?
- "아직 없네? 딴 일 하자" (except BlockingIOError)
except BlockingIOError: do_other_work() continue- 의미: "아, 손님이 아직 안 왔구나? 그럼 멍하니 있지 말고 청소나 하자(
do_other_work)." - 핵심: 프로그램이 멈추지(Block) 않고 예외 처리 구문으로 넘어오기 때문에, CPU는 다른 작업을 수행할 수 있는 자유를 얻게 된다.
- 무한 반복:
continue를 통해 다시while루프의 처음으로 돌아가서 손님이 왔는지 또 확인한다.
- 의미: "아, 손님이 아직 안 왔구나? 그럼 멍하니 있지 말고 청소나 하자(
- "기다리지 마!" 설정 (setblocking)
✨ EWOULDBLOCK과 EAGAIN
Non-Blocking 소켓에서 데이터가 아직 준비되지 않았을 때 커널에 반환하는 에러 코드이다.
이 에러 코드들은 진짜 에러가 아니라 "지금은 데이터가 없으니 나중에 다시 시도해줘"라는 커널의 친절한 메시지이다.
| 에러 코드 | 의미 | 비고 |
|---|---|---|
EWOULDBLOCK | "이 작업은 Block이 필요한데, Non-Blocking 모드라서 대신 에러를 반환할게." | POSIX 표준 |
EAGAIN | "지금은 리소스가 없어. 나중에 다시 시도해." | Linux에서 EWOULDBLOCK과 동일 값(11) |
Linux에서는 EAGAIN == EWOULDBLOCK == 11이므로 사실상 같다. 하지만 이식성을 위해 둘 다 체크하는 것이 관례이다.
if (errno == EAGAIN || errno == EWOULDBLOCK) {
// 데이터 미준비 → 나중에 재시도
}✨ Non-Blocking의 숨겨진 진실: Copy 단계는 여전히 멈춘다
- 1단계 (Wait): 데이터가 올 때까지 기다리는 건 Non-blocking이다. (즉시 리턴)
- 2단계 (Copy): 하지만 커널 버퍼에서 유저 버퍼로 데이터를 복사하는 동안은 CPU가 복사 작업을 수행해야 하므로 아주 짧은 시간 동안 프로세스가 멈춘다.
- 결론: 순수 Non-blocking I/O도 "완전한 비동기"는 아니다.
✨ Non-Blocking I/O의 문제점: Busy Waiting
데이터가 준비되지 않았는데도 계속 시스템 콜을 호출한다.
이는 CPU 사이클을 낭비하며, 시스템 콜 자체도 User → Kernel 모드 전환 비용이 발생한다.
while (true) {
result = read(fd); // 시스템 콜 호출
if (result == EAGAIN) // 데이터 없으면
continue; // 또 호출, 또 호출, 또 호출...
}- CPU 점유율 폭발
데이터가 언제 올지 모르니while루프를 계속 돌리게 된다. 이때 CPU는 "데이터 왔니?"라는 질문을 초당 수백만 번 던지며 100% 가동률을 찍게 된다. - 시스템 콜 오버헤드
read()를 호출할 때마다 User Mode ↔ Kernel Mode 전환(Context Switch)이 일어난다. 데이터도 없는데 이 전환을 반복하는 건 엄청난 자원 낭비이다.
| 관점 | Blocking I/O | 순수 Non-Blocking I/O (Polling) |
|---|---|---|
| CPU 활용 | Sleep 상태로 낭비 | Busy loop로 낭비 |
| 응답 속도 | 데이터 오면 즉시 깨어남 | 폴링 주기에 따라 약간의 지연 발생 가능 |
| 시스템 콜 횟수 | 1회 (대기 후 반환) | N회 (반복 호출) |
| 다른 작업 가능? | ❌ 불가 | ⭕ 가능 (루프 사이에) |
| 효율성 | 스레드 낭비가 심함 | CPU 자원 낭비가 심함 |
이 문제를 해결하기 위해 등장한 것이 I/O 멀티플렉싱이다.
4. I/O 멀티플렉싱 (I/O Multiplexing)
Blocking의 스레드 낭비 문제와 Non-Blocking의 Busy Waiting 문제를 동시에 해결하는 방법이다.
- 핵심 아이디어: 여러 개의 I/O를 하나의 스레드에서 감시하고, 일꾼(스레드) 한 명이 수천 명의 손님을 일일이 찾아다니며 물어보는 게 아니라, "누구든 용건 있는 사람 생기면 나한테 한꺼번에 알려줘"라고 OS에게 맡기는 방식이다.
- 효율성:
epoll_wait()를 호출하면 데이터가 올 때까지 프로세스는 잠들지만(Sleep), 데이터가 도착하는 순간 OS가 깨워주기 때문에 CPU 낭비가 전혀 없다.
✨ select / poll / epoll 비교
┌─────────────────────────────────────────────────────┐
│ I/O Multiplexing │
│ │
│ "야, 이 소켓들 중에 읽을 수 있는 거 있으면 알려줘" │
│ │
│ select()/poll()/epoll_wait() │
│ │ │
│ │ ← 준비된 FD가 있을 때까지 Block │
│ │ (CPU를 낭비하지 않음!) │
│ ▼ │
│ "소켓 #3, #7이 읽기 가능해!" │
│ │ │
│ ├── read(fd_3) → 바로 데이터 획득 │
│ └── read(fd_7) → 바로 데이터 획득 │
└─────────────────────────────────────────────────────┘| 특성 | select | poll | epoll |
|---|---|---|---|
| 최대 FD 수 | 1024 (FD_SETSIZE) | 제한 없음 | 제한 없음 |
| FD 전달 방식 | 매번 전체 FD 집합 복사 | 매번 전체 배열 복사 | 커널에 등록, 변경분만 전달 |
| 이벤트 탐색 | O(n) 순회 | O(n) 순회 | O(1) 콜백 방식 |
| 대규모 연결 성능 | 매우 나쁨 | 나쁨 | 우수 |
| 지원 OS | 거의 모든 OS | 거의 모든 OS | Linux 전용 |
✨ epoll의 마법: O(1)의 비밀
select나 poll은 손님이 1만 명이면 1만 명을 다 훑어야 한다. 하지만 epoll은 다르다.
- 관심 리스트 (Interest List): 커널 내부에 레드-블랙 트리(Red-Black Tree) 구조로 감시할 소켓들을 등록해둔다. 추가/삭제가 매우 빠르다.
- 준비 리스트 (Ready List): 데이터가 도착한 소켓들만 따로 모아두는 연결 리스트(Linked List)이다.
- 동작: 데이터가 도착하면 커널이 해당 소켓을 '준비 리스트'에 쏙 넣어준다. 유저 프로세스는 이 리스트만 가져가면 되니까 손님이 몇 명이든 상관없이 O(1)의 속도가 나오는 것이다.
✨ epoll 동작 원리
// epoll 사용 예제 (Linux)
int epfd = epoll_create1(0);
// 감시할 소켓 등록
struct epoll_event ev;
ev.events = EPOLLIN; // 읽기 이벤트 감시
ev.data.fd = client_fd;
epoll_ctl(epfd, EPOLL_CTL_ADD, client_fd, &ev);
// 이벤트 대기 (Block - 하지만 CPU 낭비 없음)
struct epoll_event events[MAX_EVENTS];
int nfds = epoll_wait(epfd, events, MAX_EVENTS, -1);
for (int i = 0; i < nfds; i++) {
if (events[i].events & EPOLLIN) {
// 이 소켓에 읽을 데이터가 있음 → 바로 read
read(events[i].data.fd, buffer, sizeof(buffer));
}
}- epoll 인스턴스 생성 (
epoll_create1)int epfd = epoll_create1(0);- 의미: 커널 안에 "나 이제 여러 소켓을 한꺼번에 감시할 거야!"라고 선언하며 감시 전용 컨트롤 타워(epoll 인스턴스)를 만든다.
- 결과:
epfd라는 파일 디스크립터(번호표)를 돌려받는다. 앞으로 모든 감시 설정은 이 번호를 통해 이루어진다.
- 감시할 소켓 등록 (
epoll_ctl)struct epoll_event ev; ev.events = EPOLLIN; // 읽기 이벤트(데이터 도착)을 감시할게 ev.data.fd = client_fd; // 이 소켓(client_fd)을 감시해줘 epoll_ctl(epfd, EPOLL_CTL_ADD, client_fd, &ev);- 의미: 컨트롤 타워에 "이 소켓에 데이터가 들어오는지(EPOLLIN) 잘 지켜봐 줘"라고 등록하는 과정이다.
- 핵심 포인트:
select와 달리, 한 번만 등록해두면 커널이 계속 기억하고 있다. 이걸 관심 리스트(Interest List)라고 부른다. 매번 전체 목록을 커널에 넘길 필요가 없어서 엄청나게 효율적이다.
- 이벤트 발생 대기 (
epoll_wait)struct epoll_event events[MAX_EVENTS]; int nfds = epoll_wait(epfd, events, MAX_EVENTS, -1);- 의미: 실제로 데이터가 올 때까지 기다리는 단계이다.
- 동작
- 데이터가 온 소켓이 하나도 없으면? 프로세스는 Sleep 상태로 들어가서 CPU를 전혀 쓰지 않는다.
- 데이터가 도착하면? 커널이 즉시 깨워주며, 데이터가 준비된 소켓들의 목록을
events배열에 쏙 담아준다.
- 반환값 (
nfds): "지금 바로 읽을 수 있는 소켓이 총 몇 개인지" 알려준다.
- 준비된 소켓만 골라 처리 (
for루프)for (int i = 0; i < nfds; i++) { if (events[i].events & EPOLLIN) { // 이 소켓은 100% 데이터가 준비된 상태 read(events[i].data.fd, buffer, sizeof(buffer)); } }- 의미: 커널이 "얘네들 데이터 왔어!"라고 찍어준 녀석들만 골라서 실제 데이터를 읽는 과정이다.
- 왜 빠른가? (O(1)의 비밀)
select는 1만 개 중 누가 보냈는지 몰라서 1만 번을 다 확인해야 했다.epoll은 커널이 준비된 녀석들만 따로 모아서(events배열) 주기 때문에, 딱nfds만큼만 루프를 돌면 된다. 1만 개 연결 중 2개만 데이터가 왔다면 딱 2번만 돌면 된다.
✨ Level-Triggered vs. Edge-Triggered
| 구분 | Level-Triggered (LT) | Edge-Triggered (ET) |
|---|---|---|
| 알림 조건 | 버퍼에 데이터가 조금이라도 있으면 계속 알림 | 데이터가 새로 들어오는 순간에만 딱 한 번 알림 |
| 안전성 | 높음 (데이터를 다 안 읽어도 다음에 또 알려줌) | 낮음 (한 번 놓치면 다음 데이터 올 때까지 알림 없음) |
| 성능 | 보통 (반복적인 알림으로 인한 오버헤드) | 매우 높음 (불필요한 시스템 콜 최소화) |
| 구현 방식 | 일반적인 read() 호출 | 반드시 Non-blocking 소켓 + 루프 돌며 EAGAIN까지 읽기 |
LT 모드:
데이터 100byte 도착 → 이벤트!
50byte만 읽음
→ 다음 epoll_wait에서도 이벤트! (50byte 남아있으니까)
ET 모드:
데이터 100byte 도착 → 이벤트!
50byte만 읽음
→ 다음 epoll_wait에서 이벤트 없음! (새로운 데이터가 오기 전까지)
→ 반드시 EAGAIN이 나올 때까지 읽어야 데이터 유실 방지- 왜 ET는 Non-blocking과 찰떡궁합일까?
- ET는 딱 한 번만 알려주기 때문에, 한 번 알림이 왔을 때 버퍼에 있는 데이터를 몽땅 다 읽어야 한다.
- 만약 Blocking 소켓으로 읽다가 데이터가 다 떨어지면 프로그램이 거기서 멈춰버릴 것이다.
- 그래서 "데이터 없을 때까지 다 읽고, 없으면 바로 리턴해!"라는 Non-blocking 방식이 필수이다.
5. 데이터 복사 관점: 커널 버퍼의 역할
✨왜 커널 버퍼를 거치는가?
네트워크 데이터가 도착하면 다음 경로를 따른다.
NIC(네트워크 카드)
│ DMA로 데이터 전송
▼
Kernel Socket Receive Buffer (recvBuffer)
│ ← 여기가 핵심!
│ 커널 메모리 → 유저 메모리 복사 (memcpy)
▼
User Application Buffer| 작업 | 속도 | 설명 |
|---|---|---|
| 네트워크 → 커널 버퍼 | 느림 (ms) | 물리적 I/O, NIC 대기 |
| 커널 버퍼 → 유저 버퍼 | 매우 빠름 (μs) | RAM 내 메모리 복사(memcpy) |
데이터를 직접 유저 메모리로 쏘면 빠를 것 같은데, 번거롭게 커널 버퍼(recvBuffer)를 거치는 이유는 다음과 같다.
- 안전과 격리
유저 프로세스가 하드웨어(NIC, 디스크)에 직접 접근하게 두면, 실수로 다른 프로세스의 데이터를 건드리거나 시스템을 망가뜨릴 수 있다. 커널에 중간에서 '검문소' 역할을 해주는 것이다. - 속도 차이의 완충 (Buffering)
네트워크 데이터는 아주 느리게(ms 단위) 들어온다. 이걸 유저 프로세스가 매번 직접 받으려고 대기하면 너무 비효율적이다. 커널이 일단 자기 버퍼에 '우체통'처럼 모아 두었다가, 다 차면 한꺼번에 유저에게 넘겨주는 게 훨씬 효율적이다. - Memory Copy의 속도
네트워크에서 데이터를 가져오는 건 '물리적 이동'이라 느리지만, 커널 버퍼에서 유저 버퍼로 옮기는 건 '메모리 간 복사(memcpy)'라 비교할 수 없을 만큼 빠르다.
✨ Zero-Copy 기법
커널 버퍼 → 유저 버퍼 복사마저 줄이려는 최적화 기법이다.
- 전통적인 방식 (Read + Write, 4번 복사)
- 경로: Disk → 커널 버퍼 → 유저 버퍼 → 소켓 버퍼 → NIC
- 문제: 유저 공간은 데이터를 가공하지 않고 그냥 전달만 할 뿐인데, 굳이 여기까지 데이터를 복사해오는 오버헤드가 발생한다.
- Zero-Copy 방식 (
sendfile(), 2번 복사)- 경로: Disk → 커널 버퍼 → NIC (유저 공간을 거치지 않음)
- 혁신: 커널 안에서 데이터를 바로 쏴버린다. 유저 프로세스는 "이 파일 좀 저 소켓으로 보내줘"라고 명령만 내리고 빠진다.
| 항목 | 전통적 방식 (Read+Write) | Zero-Copy (sendfile) |
|---|---|---|
| 데이터 복사 횟수 | 4회 | 2회 (하드웨어 간 이동만) |
| 컨텍스트 스위칭 | 4회 | 2회 |
| CPU 사용량 | 높음 (복사하느라 바쁨) | 매우 낮음 |
| 주요 사용처 | 데이터 가공이 필요한 경우 | 대용량 파일 전송 (Kafka, Nginx) |
✨ 실무 사례: Kafka가 미친 듯이 빠른 이유
Kafka가 초당 수백만 건의 메시지를 처리하는 비결이 바로 이것이다.
- Sequential I/O: 디스크를 순차적으로 읽어서 물리적 속도를 높인다.
- Zero-Copy: 읽어온 데이터를 유저 영역으로 복사하지 않고
sendfile()을 통해 바로 네트워크로 쏴버린다.
덕분에 CPU는 복사 작업에서 해방되어 다른 중요한 연산에 집중할 수 있는 것이다.
6. 5가지 I/O 모델 종합 비교
Unix 네트워크 프로그래밍(Stevens)에서 정의한 5가지 모델은 다음과 같다.
Wait 단계 Copy 단계
(데이터 준비) (커널→유저 복사)
───────────── ──────────────
1. Blocking I/O ██████████ ████
(Block) (Block)
2. Non-Blocking I/O ░░░░░░░░░░ ████
(Polling/반복체크) (Block)
3. I/O Multiplexing ██████████ ████
(select/epoll) (select에서 Block) (Block)
4. Signal-Driven I/O ────────── ████
(비동기 알림대기) (Block)
5. Async I/O (AIO) ────────── ────
(완전 비동기) (완전 비동기)
██ = Block(프로세스 멈춤)
░░ = Polling(반복 체크, CPU 소모)
── = 프로세스 자유(다른 작업 가능)- Blocking I/O: 처음부터 끝까지 멈춤
- Wait: 데이터가 올 때까지 멈춘다.
- Copy: 커널에서 유저로 복사할 때도 멈춘다.
- 특징: 가장 단순하지만, 스레드 하나가 통째로 묶여버려 리소스 낭비가 가장 심하다.
- Non-blocking I/O: 기다리진 않지만, 계속 물어봄
- Wait: 멈추지 않고 즉시 리턴한다. 대신 데이터가 왔는지 계속 확인(Polling)해야 한다.
- Copy: 데이터가 준비된 걸 확인하고
read()를 호출하는 순간, 복사가 끝날 때까지는 멈춘다. - 특징: CPU를 많이 쓰지만(Busy-waiting), 제어권을 바로 돌려받는다는 장점이 있다.
- I/O Multiplexing (select/poll): 감시할 때만 멈춤
- Wait:
select나epoll_wait호출 시, 감시하는 소켓 중 하나라도 준비될 때까지 멈춘다. - Copy: 준비된 소켓을 찾아
read()를 호출하면, 복사하는 동안은 멈춘다. - 특징: "감시" 단계에서 블로킹되지만, 한 번에 수천 개를 감시할 수 있어 매우 효율적이다.
- Wait:
- Signal-Driven I/O: 준비되면 알려줘, 하지만 복사는 내가 함
- Wait: 멈추지 않고 자기 일을 한다. 데이터가 준비되면 커널이 시그널(SIGIO)로 알려준다.
- Copy: 시그널을 받고 데이터를 읽으러(
read)가면, 복사하는 동안은 멈춘다. - 특징: 비동기 알림을 받지만, 실제 데이터를 가져오는 과정(Copy)은 여전히 동기적이다.
- Asynchronous I/O (AIO): 다 되면 알려줘, 복사까지 끝내줘
- Wait: 멈추지 않는다. 커널에게 "데이터 오면 복사까지 다 해서 내 메모리에 넣어줘"라고 부탁한다.
- Copy: 멈추지 않는다. 커널이 백그라운드에서 복사까지 다 끝내고 "진짜 다 끝났어!"라고 통보한다.
- 특징: 진정한 의미의 비동기이다. 프로세스는 I/O 작업의 시작부터 끝까지 단 1초도 멈추지 않는다.
| 모델 | Wait 단계 (준비) | Copy 단계 (복사) | 동기/비동기 구분 |
|---|---|---|---|
| Blocking | Block | Block | Synchronous |
| Non-blocking | Polling | Block | Synchronous |
| I/O Multiplexing | Block | Block | Synchronous |
| Signal-Driven | Async Notification | Block | Synchronous |
| Asynchronous I/O | Async | Async | Asynchronous |
7. 실무에서의 I/O 모델 적용
✨ 주요 서버/프레임워크의 I/O 모델
| 기술 | I/O 모델 | 핵심 메커니즘 |
|---|---|---|
| Apache (prefork) | Blocking I/O | 프로세스당 1 연결 |
| Apache (worker) | BLocking I/O | 스레드풀, 스레드당 1 연결 |
| Nginx | I/O Multiplexing | epoll (Linux) + Event Loop, ET 모드 |
| Node.js | I/O Multiplexing + AIO | libuv (epoll/kqueue 래핑) + 이벤트 루프 |
| Netty (Java) | I/O Multiplexing | Java NIO (Selector = epoll 래핑) |
| Go net/http | Blocking 스타일 코드 + 내부 Non-Blocking | goroutine + netpoller (epoll 래핑) |
| Redis | I/O Multiplexing | 싱글 스레드 + epoll, 이벤트 루프 |
✨ C10K → C10M 문제
| 세대 | 목표 | 해결책 |
|---|---|---|
| C10K (1999) | 동시 1만 연결 | select → epoll 전환, 이벤트 기반 아키텍처 |
| C100K | 동시 10만 연결 | epoll + Non-Blocking + Connection Pooling |
| C1M | 동시 100만 연결 | 커널 바이패스 (DPDK, io_uring), Zero-Copy |
| C10M | 동시 1000만 연결 | 유저 스페이스 네트워크 스택, 하드웨어 오프로딩 |
동시 접속자 수가 늘어날수록 병목 지점이 이동하는 과정이 다르다.
- C10K (1만): 스레드 생성 비용과 컨텍스트 스위칭이 문제 ➡️ epoll(이벤트 기반)로 해결
- C1M (100만): 커널의 네트워크 스택 자체가 너무 복잡해서 느려짐 ➡️ Zero-Copy, io_uring 도입
- C10M (1000만): 커널을 거치는 것 자체가 사치 ➡️ Kernel Bypass (DPDK). 데이터를 커널을 거치지 않고 유저 영역의 애플리케이션이 직접 NIC에서 읽어버린다.
✨ Linux io_uring (최신 기술)
Linux 5.1에서 도입된 진정한 비동기 I/O 인터페이스이다.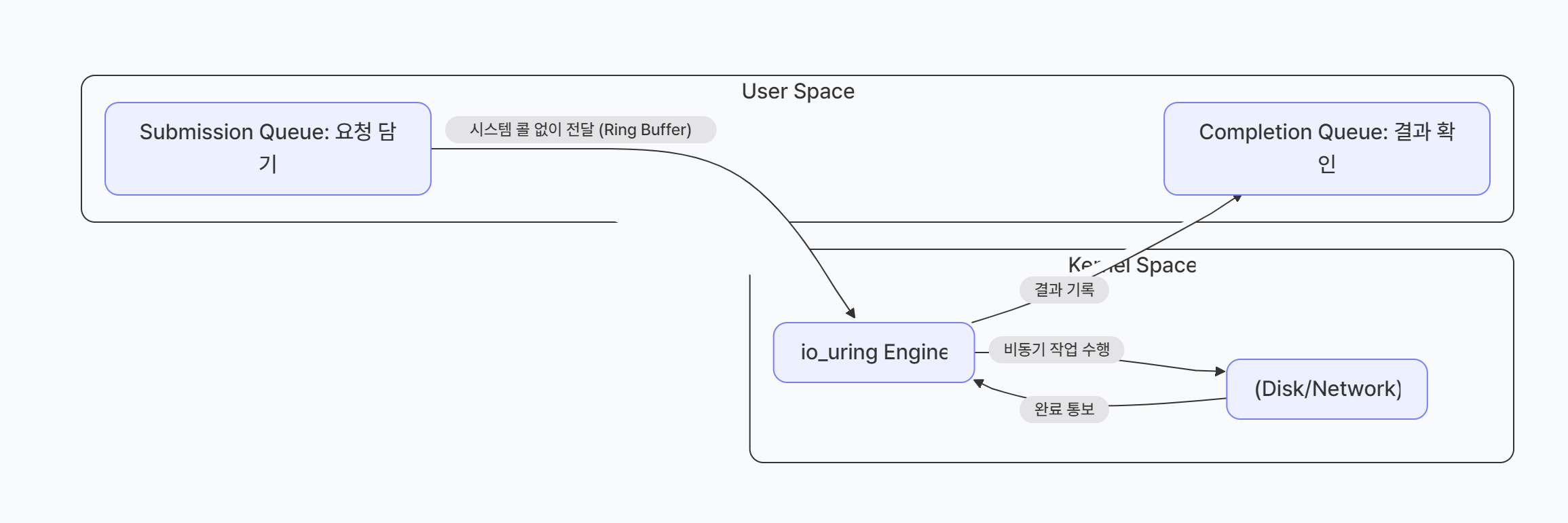
기존 epoll:
epoll_wait() → "읽을 수 있어!" → read() 호출 (여전히 시스템 콜)
io_uring:
제출 큐(SQ)에 I/O 요청 등록
→ 커널이 비동기로 처리
→ 완료 큐(CQ)에서 결과 수확
→ 시스템 콜 최소화 (배치 처리)- 주요 장점: 시스템 콜 오버헤드 대폭 감소, 진정한 비동기 지원, 네트워크 + 디스크 I/O 통합 인터페이스
- epoll보다 압도적인 이유
- Ring Buffer 방식: 유저와 커널이 공유하는 원형 큐(Ring Buffer)를 써서, 데이터를 주고받을 때 발생하는 시스템 콜(Context Switch)을 0에 가깝게 줄인다.
- 통합 인터페이스:
epoll은 네트워크 전용이었지만,io_uring은 파일 읽기/쓰기까지 완벽하게 비동기로 처리한다. - 결과: 기존
epoll기반 서버보다 처리량이 20~30% 이상 향상되는 놀라운 결과를 보여준다.
8. 혼동하기 쉬운 개념 정리
✨ Blocking/Non-Blocking vs. Sync/Async
이 두 개념은 관점이 다르다.
| 구분 | 관점 | 질문 |
|---|---|---|
| Blocking/Non-Blocking | 제어권 | "내가 기다려야 해, 말아야 해?" |
| Synchronous/Asynchronous | 완료 통지 방식 | "내가 결과를 확인해야 해, 알려줘?" |
-
2×2 조합 매트릭스
Blocking Non-Blocking Sync [Sync-Blocking]
가장 일반적인 모델. 결과가 올 때까지 멈춰서 기다림. (예: JDBC, 전통적 API 호출)[Sync-Non-blocking]
제어권은 바로 받지만, 결과가 나왔는지 계속 물어봄(Polling). (예: Java NIO 초기 모델)Async [Async-Blocking]
안티패턴. 비동기로 호출했는데 내부에서 블로킹 요소가 있어 결국 멈춤. (예: Node.js에서 동기 DB 드라이버 사용)[Async-Non-blocking]
가장 이상적. 제어권도 바로 받고, 완료 통보도 나중에 콜백으로 받음. (예: Node.js, WebFlux)
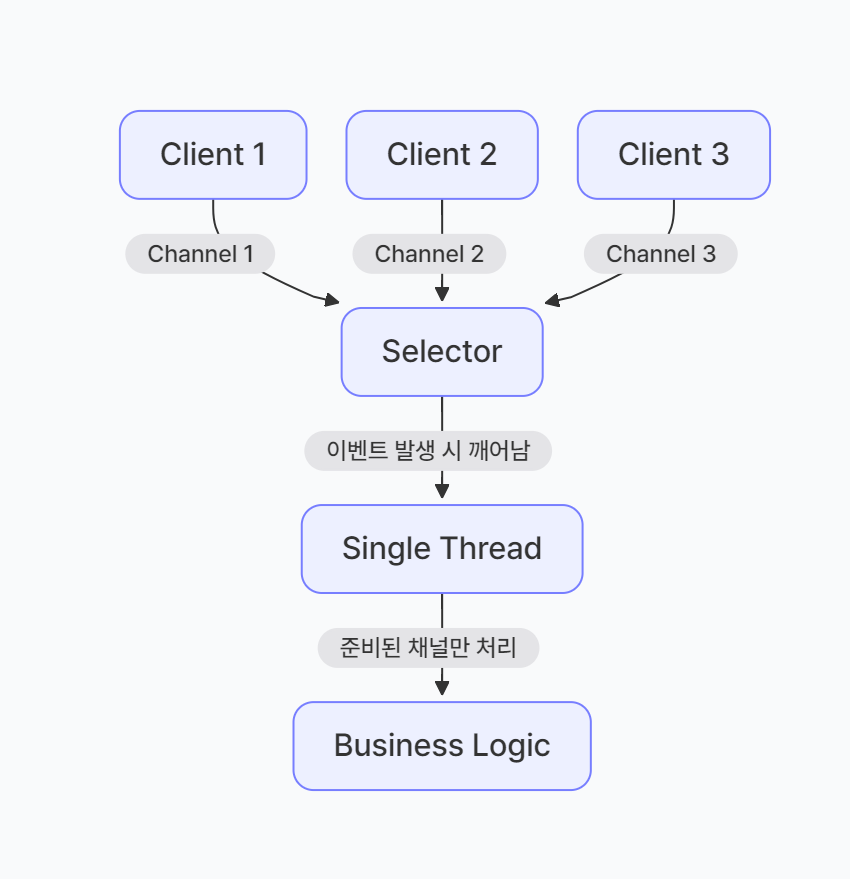
✨ Java NIO: Non-Blocking과 Multiplexing의 조화
// Java NIO: Non-Blocking + I/O Multiplexing 조합
Selector selector = Selector.open();
ServerSocketChannel server = ServerSocketChannel.open();
server.configureBLocking(false); // Non-Blocking 모드
server.register(selector, SelectionKey.OP_ACCEPT);
while (true) {
selector.select(); // 이벤트 발생까지 Block (하지만 하나의 스레드로 다수 채널 관리)
Set<SelectionKey> keys = selector.selectedKeys();
for (SelectionKey key : keys) {
if (key.isAcceptable()) { /* 새 연결 */ }
if (key.isReadable()) { /* 데이터 읽기 가능 */ }
}
}- 감시자(Selector)와 통로(Channel) 준비
Selector selector = Selector.open(); ServerSocketChannel server = ServerSocketChannel.open();- Selector (감시자): 여러 개의 채널을 한꺼번에 지켜보며 "어디 데이터 왔나?"를 확인하는 '눈' 역할을 한다. 리눅스의
epoll을 자바에서 쓸 수 있게 만든 것이다. - ServerSocketChannel (서버 통로): 클라이언트의 접속을 받는 메인 대문이다.
- Selector (감시자): 여러 개의 채널을 한꺼번에 지켜보며 "어디 데이터 왔나?"를 확인하는 '눈' 역할을 한다. 리눅스의
- Non-blocking 모드 설정
server.configureBlocking(false); // Non-Blocking 모드- 의미: "이제부터 이 대문은 손님이 없어도 멈춰 서서 기다리지마!"라고 설정하는 것이다.
- 왜 필요한가?: Selector에 채널을 등록하려면 반드시 Non-blocking 모드여야 한다. 그래야 감시자가 여러 채널을 훑어볼 때 어느 한 곳에서 발이 묶이지 않는다.
- 감시 대상 등록 (Register)
server.register(selector, SelectionKey.OP_ACCEPT);- 의미: 감시자(Selector)에게 "이 대문에 새로운 손님이 오는지(OP_ACCEPT) 잘 지켜봐 줘"라고 부탁하는 것이다. 이제 사장님(스레드)은 문앞에 서 있을 필요 없이 감시자에게 맡기고 딴 일을 할 수 있다.
- 이벤트 루프와 감시 (
select)while (true) { selector.select(); // 이벤트 발생까지 Block }- 의미: 감시자가 "자, 이제 지켜본다!"하고 업무를 시작하는 단계이다.
- 반전 (Blocking): 여기서
select()는 블로킹(Block)되어 멈춘다. 이것은 '효율적인 멈춤'이다. - 이유: 아무 일도 없는데 루프를 돌며 CPU를 낭비(Busy-waiting)하는 대신, 등록된 수천 개의 채널 중 하나라도 일이 생길 때까지 얌전히 기다리는 것이다.
- 준비된 녀석들만 골라내기 (Selected Keys)
Set<SelectionKey> keys = selector.selectedKeys(); for (SelectionKey key : keys) {- 의미: 감시자가 "사장님! 지금 용건 있는 손님이 몇 명 왔어요!"라고 리스트(
keys)를 넘겨준다. - 효율성: 전체 손님을 다 뒤질 필요 없이, 딱 용건 있는 손님들만 모아서 처리하니까 엄청나게 빠르다. (epoll의 O(1) 원리)
- 의미: 감시자가 "사장님! 지금 용건 있는 손님이 몇 명 왔어요!"라고 리스트(
- 용건에 따른 처리 (Dispatch)
if (key.isAcceptable()) { /* 새 연결 처리 */ } if (key.isReadable()) { /* 데이터 읽기 처리 */ }- 의미: 손님의 용건이 "새로 왔어요"인지, "할 말이 있어요(데이터 전송)"인지 확인해서 각각의 로직을 실행한다.
- Java NIO의 3대 핵심 요소
- Channel (통로): 양방향으로 데이터를 흘려보낼 수 있는 통로이다. (Non-blocking 설정 가능)
- Buffer (바구니): 데이터를 담아두는 메모리 공간이다. 채널에서 읽은 데이터는 무조건 버퍼에 담긴다.
- Selector (감시자): 여러 채널을 한꺼번에 감시하는 '눈'이다.
- 왜
selector.select()는 블로킹되어도 괜찮은가?- 현상:
select()호출 시, 감시하는 채널 중 하나라도 이벤트(연결, 읽기 등)가 발생할 때까지 스레드는 멈춘다. - 이유: 하지만 이 스레드 하나가 수천 개의 채널을 동시에 감시하고 있다.
- 결과: 수천 명의 손님을 위해 수천 명의 직원을 뽑는 대신(Blocking), 단 한 명의 유능한 지배인(Selector)이 모든 테이블을 감시하다가 용건 있는 손님이 생길 때만 움직인다. 그래서 스레드 낭비가 없다.
- 현상:
9. 성능 영향 요인 총정리
- Context Switch 비용
CPU가 실행 중인 프로세스/스레드를 바꾸는 건 생각보다 훨씬 무거운 작업이다.- 오버헤드의 실체: CPU 레지스터 상태 저장/복구, 페이지 테이블 교체, CPU 캐시 초기화가 일어난다.
- User ↔ Kernel 전환: 시스템 콜을 호출할 때마다 발생하는 이 전환은 '권한 변경'이라는 절차가 필요해서 일반적인 함수 호출보다 훨씬 느리다.
- 해결책: 스레드 수를 CPU 코어 수에 맞게 최소화하고, 이벤트 루프를 써서 한 스레드가 오래 일하게 만든다.
- 메모리 복사 비용
데이터가 네트워크 카드에서 우리 프로그램까지 오는 동안 여러 번 복사된다.- CPU와 대역폭 낭비:
memcpy는 CPU가 직접 데이터를 옮겨야 하므로 CPU 점유율을 높이고 메모리 대역폭을 잡아먹는다. - 해결책: Zero-Copy 기술(
sendfile,mmap)을 써서 커널 영역에서 유저 영역으로의 복사 단계를 아예 건너뛴다.
- CPU와 대역폭 낭비:
- 스레드 생성 및 메모리 비용
스레드는 생성하는 것도 일이지만, 존재하는 것만으로도 자원을 먹는다.- Stack Memory: 스레드당 약 8MB의 스택이 할당된다. 스레드가 1,000개라면 8GB를 소모하게 된다.
- 해결책: Thread Pool로 미리 만들어둔 일꾼을 재사용하거나, 아예 스레드 하나가 수만 개를 처리하는 이벤트 기반 모델을 선택한다.
- 캐시 효율
현대 CPU 성능의 핵심은 L1/L2/L3 캐시를 얼마나 잘 쓰느냐에 달려 있다.- 캐시 미스 (Cache Miss): 스레드가 너무 많아서 자주 바뀌면, CPU 캐시에 담아둔 데이터가 무용지물이 된다. 새로 바뀐 스레드는 다시 느린 RAM에서 데이터를 읽어와야 한다.
- 해결책: 소수의 스레드가 같은 메모리 영역을 계속 참조하며 일하는 이벤트 루프 방식이 캐시 적중률이 훨씬 높다.
- 시스템 콜 오버헤드
시스템 콜은 유저와 커널 사이의 '국경'을 넘는 것과 같다.- 비효율의 극치:
select는 매번 "누가 왔니?"라고 물어볼 때마다 전체 명단을 커널에 복사해서 넘겨줘야 한다. (O(n)) - 해결책:
epoll은 한 번만 등록하고 바뀐 것만 통보받는다(O(1)). 최신io_uring은 여러 요청을 한 바구니에 담아 한 번에 국경을 넘는 '배치 처리'로 시스템 콜 횟수 자체를 획기적으로 줄였다.
- 비효율의 극치:
✨ 성능 최적화의 진화 단계

10. 핵심 요약
| 모델 | 핵심 동작 | 장점 | 단점 | 대표 사용처 |
|---|---|---|---|---|
| Blocking | 호출 시 응답까지 대기 | 구현 단순, 직관적 | 스레드 낭비, 확장성 한계 | 전통적 서버, 간단한 CLI 도구 |
| Non-Blocking | 즉시 반환 + 반복 확인 | 스레드 점유 없음 | Busy Waiting으로 CPU 낭비 | 단독 사용은 드묾 |
| I/O Multiplexing | 다수 FD를 하나의 호출로 감시 | 소수 스레드로 대량 연결 처리 | 이벤트 기반 프로그래밍 복잡 | Nginx, Redis, Node.js |
| Async I/O | 요청 후 완료 시 통지 | 가장 효율적, 진정한 비동기 | 구현 복잡, OS 지원 필요 | io_uring, Windows IOCP |
✨ 아키텍처 선택을 위한 의사결정 트리