1. 왜 이 개념이 중요한가?
서버 개발, 시스템 프로그래밍, 프레임워크 선택 등 거의 모든 소프트웨어 설계에서 이 네 개념의 조합이 등장한다.
Node.js는 싱글 스레드인데 빠른 이유, Java의 NIO 개념, Spring WebFlux와 MVC의 차이 모두 이 개념을 정확히 이해해야 설명할 수 있다.
- Node.js가 빠른 이유
싱글 스레드임에도 불구하고 Async-Non-blocking I/O를 사용해 I/O 작업(파일 읽기, 네트워크 요청 등)을 기다리지 않고 다음 요청을 바로 받기 때문이다. - Java NIO
하나의 스레드가 Selector를 통해 여러 개의 연결(채널)을 동시에 감시하며, 데이터가 준비된 것만 골라 처리하는 버퍼 기반의 논블로킹 I/O 방식 - Spring WebFlux vs. MVC
MVC는 요청당 스레드 하나를 할당하는 Blocking 방식인 반면, WebFlux는 Non-blocking 기반으로 적은 리소스로 더 많은 처리량(Throughput)을 뽑아낼 수 있다.
✨ 핵심 혼동 포인트
Blocking ≠ Synchronous, Non-blocking ≠ Asynchronous.
이 둘은 관심사 자체가 다르다.
| 구분 | 핵심 관심사 | 판단 기준 |
|---|---|---|
| Blocking / Non-blocking | 제어권 (Control Flow) | 호출된 함수가 제어권을 즉시 돌려주는가? |
| Synchronous / Asynchronous | 완료 통보 (Completion Notification) | 호출한 함수가 작업 완료를 직접 확인하는가, 콜백으로 통보받는가? |
2. Blocking vs. Non-blocking: 제어권의 관점
 이 둘을 가르는 핵심 질문은 "호출된 함수가 제어권을 바로 돌려주는가?"이다.
이 둘을 가르는 핵심 질문은 "호출된 함수가 제어권을 바로 돌려주는가?"이다.
✨ Blocking
- 개념
호출된 함수(B)가 자신의 작업이 완전히 끝날 때까지 제어권을 붙잡고 있는다.
호출한 함수(A)는 그동안 아무것도 하지 못하고 대기한다.A: ──호출──▶ B: ████████████████ (작업 중) (대기 중...) │ ◀──리턴──────────────┘ (작업 완료 후 리턴)
-
코드 예시 (Python)
import socket sock = socket.socket(socket.AF_INEF, socket.SOCK_STREAM) sock.connect(('example.com', 80)) data = sock.recv(4096) # 이 줄에서 데이터가 올 때까지 프로세스가 멈춤 (Blocking) print(data) # recv()가 리턴해야 여기에 도달
- OS 레벨에서 일어나는 일
recv()시스템 콜 호출- 커널이 해당 프로세스를 WAIT 큐에 넣음
- 네트워크 버퍼에 데이터가 도착하면 커널이 프로세스를 READY 큐로 이동
- 스케줄러가 CPU를 할당하면
recv()가 데이터와 함께 리턴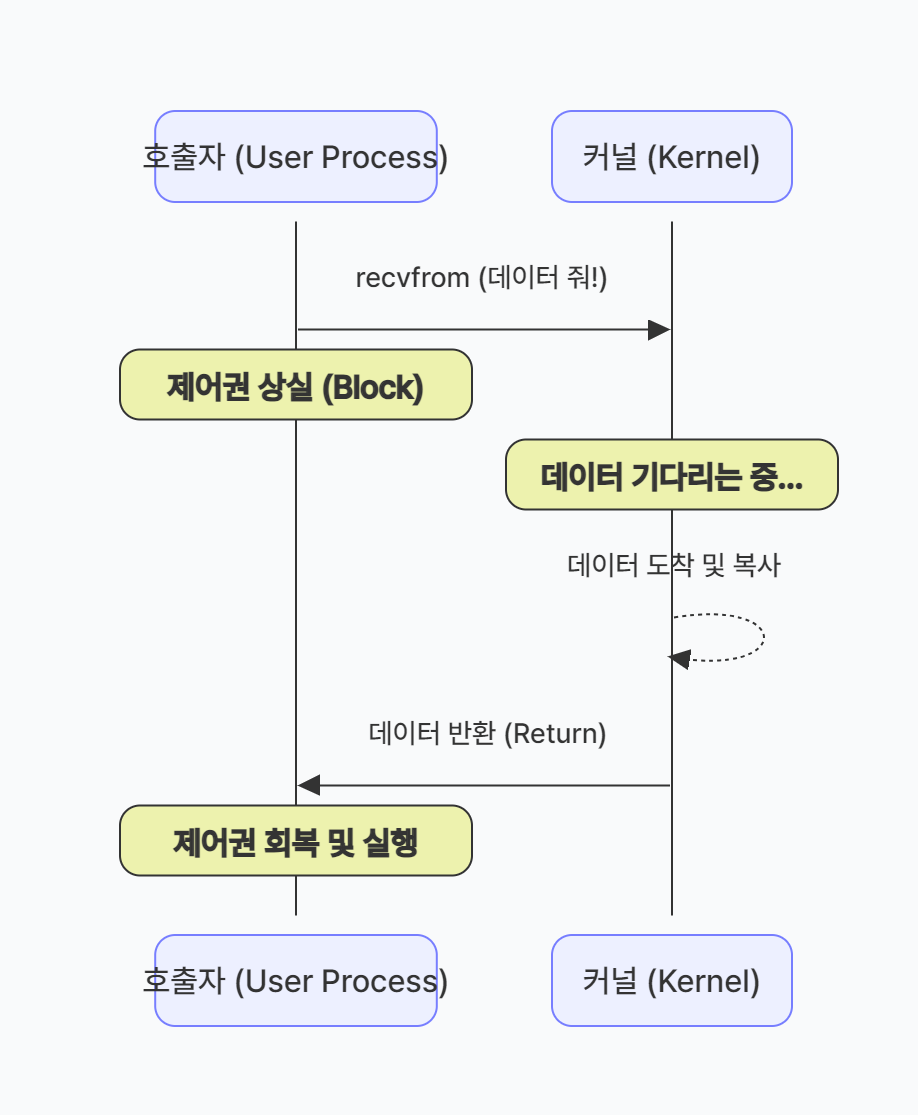
- 핵심 문제점
I/O 작업은 CPU를 거의 쓰지 않는데, 프로세스는 아무 일도 못하고 멈춰 있어 리소스 낭비가 심하다. (Resource Waste)
- 멀티 스레드의 함정
여러 클라이언트를 처리하려고 스레드를 늘리면, 대기 중인 스레드가 많아져 컨텍스트 스위칭(Context Switching) 비용이 눈덩이처럼 불어나게 된다.
✨ Non-blocking
- 개념
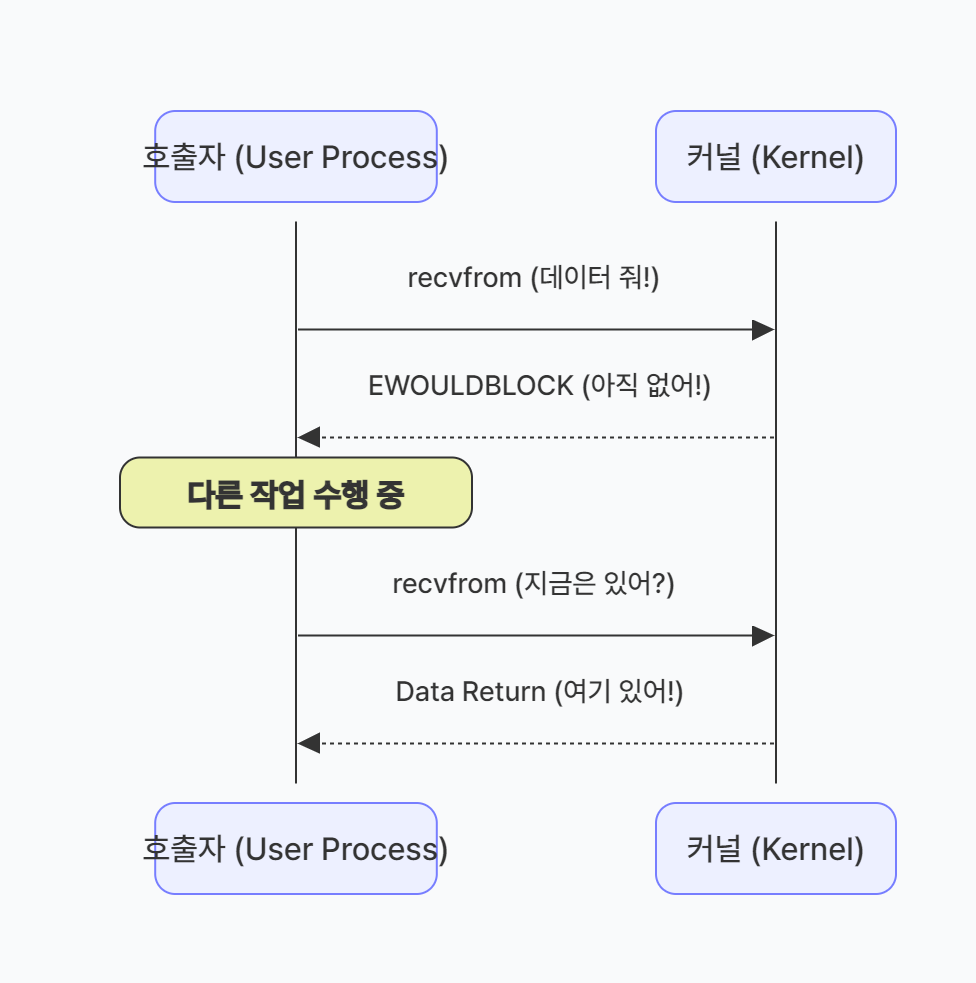
호출된 함수(B)가 작업 완료 여부와 무관하게 즉시 제어권을 리턴한다.
호출한 함수(A)는 다른 작업을 계속 진행할 수 있다.A: ──호출──▶ B: 즉시 리턴 (아직 완료 아님) ◀──리턴──┘ (다른 작업 수행 가능)
-
코드 예시 (Python)
import socket sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sock.setblocking(False) # Non-blocking 모드 설정 sock.connect(('example.com', 80)) try: data = sock.recv(4096) except BlockingIOError: # 데이터가 아직 없으면 예외 발생 → 하지만 프로그램은 멈추지 않음 print("데이터 아직 없음, 다른 일 수행 가능")
- OS 레벨에서 일어나는 일
recv()시스템 콜 호출 (O_NONBLOCK 플래그)- 커널 버퍼에 데이터가 없으면 즉시 EAGAIN/EWOULDBLOCK 에러를 리턴
- 프로세스는 WAIT 큐에 들어가지 않고 계속 실행
- 데이터가 있으면 즉시 복사하여 리턴
- 효율적인 데이터 수신
커널 버퍼에 데이터가 준비되면, 메모리 간 복사(Memory Copy)를 통해 I/O보다 훨씬 빠른 속도로 데이터를 받아올 수 있다.
✨ Blocking vs. Non-blocking 비교 정리
| 항목 | Blocking | Non-blocking |
|---|---|---|
| 제어권 반환 시점 | 작업 완료 후 | 즉시 |
| 호출자의 상태 | 중단(Suspended) 및 대기 | 중단 없이 계속 실행 |
| 프로세스 상태 | WAIT 큐 → READY 큐 | 항상 READY 또는 RUNNING |
| 주요 단점 | 컨텍스트 스위칭 오버헤드 | 잦은 상태 확인(Polling)으로 인한 CPU 소모 |
| 리소스 효율 | 스레드 낭비 (대기 중에도 점유) | 스레드 재활용 가능 |
| 구현 복잡도 | 낮음 (순차적) | 높음 (상태 관리 필요) |
| 대표 API | read(), recv(), accept() | read() + O_NONBLOCK, fcntl() |
| 적합한 상황 | 단순한 로직, 적은 동시 접속 | 고성능, 대규모 동시 접속 처리 |
3. Synchronous vs. Asynchronous: 완료 확인의 관점
 이 둘을 가르는 핵심 질문은 "작업이 끝났는지 누가 확인하고, 결과 처리를 누가 담당하는가?"이다.
이 둘을 가르는 핵심 질문은 "작업이 끝났는지 누가 확인하고, 결과 처리를 누가 담당하는가?"이다.
✨ Synchronous (동기)
- 개념
호출한 함수(A)가 호출된 함수(B)의 작업 완료를 직접 확인(또는 대기)한다.
A가 B의 결과에 관심을 갖고, B가 끝났는지를 A가 체크한다.A: B야 일 해줘 → (A가 B의 완료를 직접 확인) B 끝났나? → 아직 B 끝났나? → 아직 B 끝났나? → 완료! → 결과 처리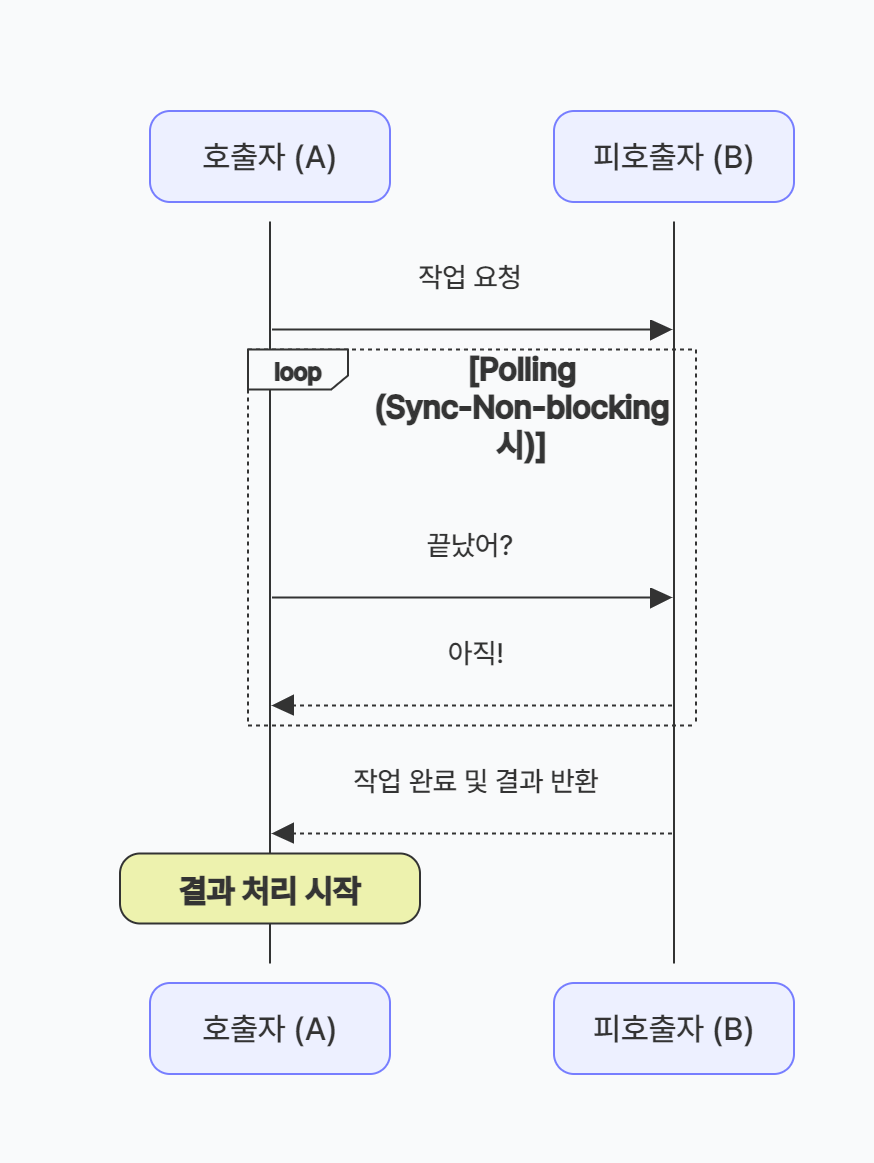
- 관심의 대상
호출자(A)는 피호출자(B)가 리턴하는 결과값에 직접적인 관심을 가진다.
- 작업의 순차성
A는 B의 작업이 끝나야만 다음 단계로 넘어가기 때문에, 전체적인 로직의 흐름이 코드의 순서와 일치한다.
- Sync-Non-blocking의 경우
제어권은 바로 돌려받지만, 결과가 나왔는지 계속 물어보는 Polling 방식이 여기에 해당된다.
✨ Asynchronous (비동기)
- 개념
호출한 함수(A)가 호출된 함수(B)의 작업 완료에 신경쓰지 않는다.
B가 끝나면 B 스스로 콜백(Callback), 이벤트(Event) 또는 시그널(Signal)을 통해 통보한다.A: B야 일 해줘, 끝나면 이 콜백 실행해 → (A는 다른 일 수행) ... (시간 경과) ... B → 콜백 호출: "끝났어, 결과는 이거야"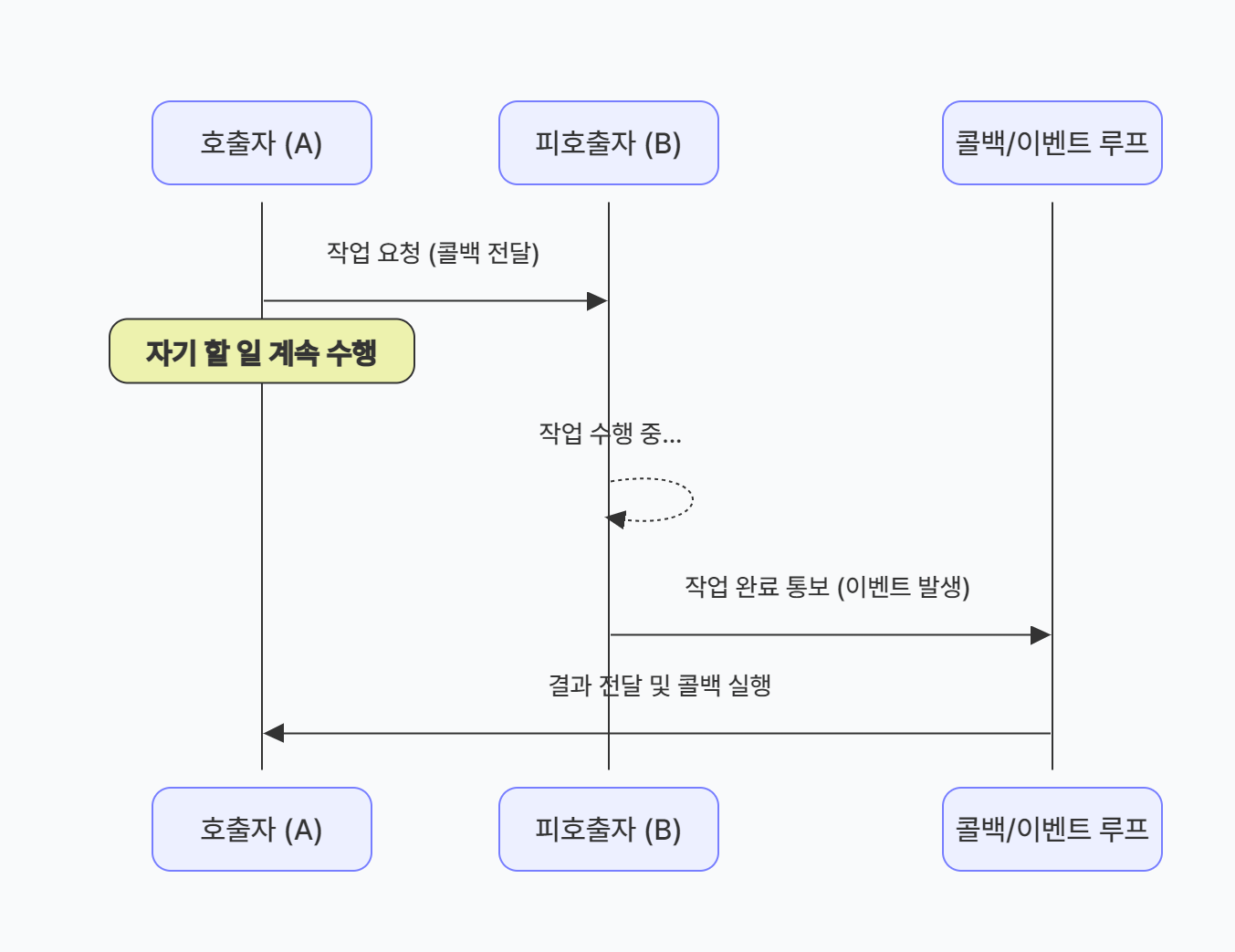
- 위임(Delegation)
호출자(A)는 작업을 맡기면서 "끝나면 이 콜백(Callback)을 실행해줘"라고 부탁하고 자기 할 일을 한다.
- 관심의 분리
A는 B의 작업 완료를 기다리지 않는다. 결과 처리는 나중에 통보가 왔을 때 별도의 흐름에서 진행된다.
- 현대적 패턴
단순 콜백을 넘어Promise,Future,Async/Await,Reactive Streams등이 이 비동기 흐름을 우아하게 처리하기 위해 등장했다.
✨ Synchronous vs. Asynchronous 비교 정리
| 항목 | Synchronous | Asynchronous |
|---|---|---|
| 완료 확인 주체 | 호출자(A)가 직접 | 피호출자(B) 또는 시스템이 통보 |
| 작업 흐름 | 직렬적 (Sequential) | 병렬적 (Parallel) |
| 완료 통보 메커니즘 | 리턴값, 폴링 | 콜백, Promise, Future, 이벤트, 시그널 |
| 실행 순서 | 호출 순서 = 완료 순서 | 완료 순서 보장 안됨 |
| 데이터 정합성 | 보장하기 쉬움 | 복잡한 동기화(Synchronization) 필요 |
| 코드 가독성 | 높음 (순차적) | 낮을 수 있음 (콜백 지옥 가능) |
| 에러 핸들링 | try-catch 직관적 | 콜백 체인, .catch(), try-await 등 |
| 실제 기술 | JDBC, 일반적인 함수 호출 | CompletableFuture(Java), Promise(JS) |
4. 2×2 매트릭스
이것이 이 주제의 핵심이다. Blocking/Non-blocking과 Sync/Async는 독립적인 축이므로 4가지 조합이 모두 존재한다.
✨ Sync-Blocking (Blocking + Synchronous)
-
정의: 호출한 함수가 제어권을 잃고 대기하며, 동시에 작업 완료를 직접 확인한다.
-
치킨집 비유: 카운터 앞에 서서 치킨 튀기는 걸 지켜보며 기다린다.
-
실제 사례
- 전통적인 파일 I/O
with open('large_file.txt', 'r') as f: content = f.read() # 파일 읽기 완료까지 이 줄에서 멈춤 # read()가 리턴한 후에야 다음 줄 실행 process(content) - JDBC 데이터베이스 호출
ResultSet rs = statement.executeQuery("SELECT * FROM users"); // DB 쿼리가 완료될 때까지 이 스레드는 Block while (rs.next()) { // 결과 처리 }
- 전통적인 파일 I/O
-
사용처: 전통적인 서블릿 기반 웹서버(Tomcat + Spring MVC), 쉘 스크립트, 단순 CLI 프로그램
-
장점: 코드가 직관적이고 디버깅이 쉽다.
-
단점: 스레드가 I/O 대기 중 놀게 되면, 동시 처리를 위해 스레드를 많이 만들어야 하고, 결국 컨텍스트 스위칭 오버헤드가 증가한다.
- 실무 포인트
- Thread-per-Request: 요청 하나당 스레드 하나를 할당하는 방식
- 한계: 동시 접속자가 1,000명인데 스레드 풀이 500개라면, 나머지 500명은 앞선 작업이 끝날 때까지 아무것도 못하고 대기하게 된다.
✨ Async-Blocking (Blocking + Asynchronous)
-
정의: 호출한 함수가 제어권을 잃고 대기하는데, 완료 통보는 콜백으로 온다. 즉, 어차피 블로킹되어 기다리는데 콜백 메커니즘을 쓰는 비효율적 조합이다. (안티패턴)
-
치킨집 비유: "다 되면 알려줄게요"라고 했는데, 어차피 가게 앞에 발이 묶여서 못 간다.
-
실제 사례
- Node.js에서 비동기 함수인데 내부에서 동기적으로 블로킹하는 라이브러리를 호출하는 경우
const result = syncHeavyLibrary.process(data); // 이 안에서 블로킹 발생 callback(result); // 콜백 패턴이지만 실질적으로 Blocking + Async - Linux의
select()+ 비동기 I/O의 조합:select()가 블로킹되면서 기다리지만, I/O 자체는 비동기 통보 방식
- Node.js에서 비동기 함수인데 내부에서 동기적으로 블로킹하는 라이브러리를 호출하는 경우
- 왜 안티패턴인가?
- Blocking이므로 대기 시간에 다른 일을 못 한다.
- 그런데 Async이므로 콜백 관리 복잡도까지 추가된다.
- 두 방식의 단점만 결합된 최악의 조합이다.
- 보통 의도적으로 사용하지 않고, 설계 실수로 발생한다.
- 발생하는 대표적 상황
- Node.js에서 이벤트 루프를 블로킹하는 동기 라이브러리 사용
- Linux의
select()/poll()호출 시 내부적으로 비동기 I/O를 사용하지만select()자체는 블로킹 - 비동기 프레임워크 안에서 동기 블로킹 DB 드라이버를 호출하는 경우
- 실무 포인트
- 가장 위험한 상황: Node.js나 Spring WebFlux 같은 비동기 환경에서 동기식 라이브러리(예: bcrypt 암호화, 동기 DB 드라이버)를 호출할 때 발생한다.
- 결과: 이벤트 루프가 멈춰버려서 서비스 전체가 먹통이 될 수 있다. 비동기 환경에서는 반드시 모든 라이브러리가 Non-blocking인지 확인해야 하는 이유이다.
✨ Sync-Non-blocking (Non-blocking + Synchronous)
-
정의: 호출된 함수가 즉시 제어권을 돌려주지만, 호출한 함수가 작업 완료 여부를 반복적으로 직접 확인(polling)한다.
-
치킨집 비유: 다른 볼일을 보면서 5분마다 "제 치킨 됐나요?" 하고 물어본다.
-
실제 사례
-
Python의 Non-blocking 소켓 + 폴링
import socket sock = socket.socket() sock.setblocking(False) while True: try: data = sock.recv(4096) # Non-blocking: 즉시 리턴 if data: process(data) break except BlockingIOError: # 데이터 없음 → 다른 일 수행 후 다시 확인 do_other_work() # 다음 루프에서 다시 확인 (= Synchronous 폴링) -
Java NIO의 Selector.selectNow()
while (true) { int readyChannels = selector.selectNow(); // Non-blockinig, 즉시 리턴 if (readyChannels == 0) { doOtherWork(); // 다른 작업 수행 continue; // 다시 확인 (polling) } // 준비된 채널 처리 Set<SelectionKey> keys = selector.selectedKeys(); // ... } -
C언어 Non-blocking 소켓 + 폴링
int flags = fcntl(fd, F_GETFL, 0); fcntl(fd, F_SETFL, flags | O_NONBLOCK); while (1) { ssize_t n = read(fd, buf, sizeof(buf)); if (n > 0) { process(buf, n); break; } else if (errno == EAGAIN) { // 아직 데이터 없음 → 다른 일 하고 다시 체크 do_something_else(); } }
-
-
장점: 대기 중 다른 작업을 할 수 있다.
-
단점: 폴링 주기 설정이 어렵다. 너무 자주하면 CPU 낭비가 심하고, 너무 드물게 하면 응답이 지연된다. 이른바 busy-waiting 문제가 발생한다.
-
사용처: 게임 루프(프레임마다 입력 확인), 하드웨어 폴링, 일부 임베디드 시스템
- 실무 포인트
- Busy-Waiting: "됐어?" → "아니", "됐어?" → "아니" ... 이 과정에서 CPU가 쉴 새 없이 돌아가며 자원을 낭비할 수 있다.
- 최적화: 보통은
sleep을 주거나, OS의select/poll같은 멀티플렉싱 기술을 써서 효율을 높인다.
✨ Async-Non-blocking (Non-blocking + Asynchronous)
-
정의: 호출된 함수가 즉시 제어권을 돌려주고, 작업이 완료되면 시스템이 콜백/이벤트로 통보한다. 호출한 함수는 그 사이에 완전히 자유롭다.
-
치킨집 비유: "볼일 보시다 오세요, 다 되면 문자 드릴게요." → 다른 가게 구경하다가 문자 받고 픽업
-
실제 사례
-
Node.js의 핵심 모델
const fs = require('fs'); // readFile은 즉시 리턴 (Non-blocking) // 파일 읽기가 끝나면 콜백 실행 (Asynchronous) fs.readFile('large_file.txt', 'utf8', (err, data) => { console.log('파일 읽기 완료!', data.length); }); console.log('이 줄이 먼저 실행됨!'); // readFile보다 먼저 출력 -
Python의 asyncio
import asyncio async def fetch_data(): reader, writer = await asyncio.open_connection('example.com', 80) writer.write(b'GET / HTTP/1.0\r\nHost: example.com\r\n\r\n') data = await reader.read(4096) # Non-blocking await return data async def main(): # 여러 작업을 동시에 실행 (Non-blocking + Async) results = await asyncio.gather( fetch_data(), fetch_data(), fetch_data() ) -
Java의 CompletableFuture
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> { return callExternalAPI(); // 별도 스레드에서 실행 }); future.thenAccept(result -> { System.out.println("완료: " + result); // 콜백으로 결과 수신 }); System.out.println("다른 작업 수행 중..."); // 즉시 실행
-
-
장점: 최소 스레드로 최대 동시성, I/O 대기 시간 활용 극대화
-
단점: 코드 복잡도 증가, 디버깅 난이도 상승, 콜백 지옥(Callback Hell) 가능
-
사용처: Node.js, Nginx, Redis, Spring WebFlux, Python asyncio, Go goroutine
- 실무 포인트
- Event-Driven: 적은 수의 스레드로 수만 개의 동시 연결을 처리할 수 있는 비결이다.
- AI 아키텍처 적용: LLM API 호출처럼 응답이 오래 걸리는 작업을 처리할 때 가장 이상적이다.
✨ 네 가지 방식 비교하기
| 조합 | 제어권 | 완료 확인 | 비유 | 핵심 키워드 |
|---|---|---|---|---|
| Sync-Blocking | 피호출자가 가짐 | 호출자가 대기 | 카운터 앞 대기 | Thread-per-Request, 직관적 |
| Async-Blocking | 피호출자가 가짐 | 피호출자가 통보 | 가게 안에서 대기 | 안티패턴, 성능 저하 주범 |
| Sync-Non-blocking | 호출자가 가짐 | 호출자가 확인 | 5분마다 재방문 | Polling, Busy-waiting |
| Async-Non-blocking | 호출자가 가짐 | 피호출자가 통보 | 진동벨/문자 알림 | Event-driven, 확장성 최강 |
5. OS 레벨 I/O 모델과의 매핑
I/O 작업은 크게 1) 데이터가 커널에 도착하기를 기다리는 단계와 2) 커널의 데이터를 유저 프로세스 메모리로 복사하는 단계로 나뉜다.
UNIX/Linux에서는 5가지 I/O 모델을 정의하며, 위 4가지 조합과 직접 연결된다.
| I/O 모델 | 조합 | 설명 | 핵심 특징 |
|---|---|---|---|
| Blocking I/O | Blocking + Sync | read() 호출 → 커널 대기 → 데이터 복사 완료 후 리턴 | 데이터가 올 때까지 + 복사될 때까지 프로세스가 완전히 멈춤 |
| Non-blocking I/O | Non-blocking + Sync | read() + O_NONBLOCK → 즉시 리턴, 폴링으로 확인 | 데이터가 없으면 즉시 리턴. 데이터가 있을 때까지 계속 물어봄(Polling) |
| I/O Multiplexing | Blocking + Sync (select/poll 자체가 블로킹) | select(), poll(), epoll() → 여러 fd를 한 번에 감시 | select/poll/epoll 호출 자체는 블로킹. 하지만 한 번에 여러 파일 디스크립터(fd)를 감시할 수 있음 |
| Signal-driven I/O | Non-blocking + Async | SIGIO 시그널로 데이터 준비 통보 | 데이터가 준비되면 시그널(SIGIO)을 받음. 단, 데이터 복사 단계에서는 블로킹될 수 있음 |
| Asynchronous I/O | Non-blocking + Async | aio_read() → 커널이 데이터 복사까지 완료 후 통보 | 진정한 비동기. 커널이 데이터 복사까지 다 끝내고 프로세스에 알려줌 (Linux의 io_uring 등) |
✨ I/O Multiplexing 상세: 왜 epoll인가?
select/poll epoll
┌──────────────────────────┐ ┌────────────────────────────┐
│ 매번 전체 fd 목록을 전달 │ │ 커널에 fd를 등록해두고 │
│ O(n)으로 전체 스캔 │ │ 이벤트 발생 fd만 O(1) 통보 │
│ fd 개수 제한 (1024) │ │ fd 개수 제한 없음 │
└──────────────────────────┘ └─────────────────────────────┘- select / poll: 전수 조사 방식
- 문제점: 관리하는 fd(연결)가 10,000개라면, 데이터가 하나만 와도 커널은 10,000개를 처음부터 끝까지 다 훑어서 누가 보냈는지 찾아야 한다.
- 오버헤드: 매번 전체 fd 목록을 유저 공간에서 커널 공간으로 복사해야 해서 메모리 부하가 크다.
- epoll: 이벤트 알림 방식
- 혁신: 커널 내부에 관심 리스트(Interest List)를 만들어 두고, 데이터가 도착한 fd만 준비 리스트(Ready List)에 따로 담아준다.
- 효율성: 유저 프로세스는 준비 리스트에 있는 녀석들만 바로 처리하면 되니까 O(1)의 속도가 나오는 것이다.

✨ select vs. poll vs. epoll
| 항목 | select | poll | epoll |
|---|---|---|---|
| fd 전달 방식 | 매 호출마다 배열 복사 | 매 호출마다 배열 복사 | 커널에 한 번 등록 |
| 준비된 fd 탐색 (효율성) | O(n) (전체 순회) | O(n) (전체 순회) | O(1) (이벤트 기반) |
| 최대 fd 수 | FD_SETSIZE (보통 1024) | 제한 없음 | 제한 없음 |
| 주요 특징 | 오래된 표준, 이식성 좋음 | select의 fd 제한 해결 | 리눅스 고성능 서버의 표준 |
| 대표 사용처 | 레거시 시스템 | 이식성 필요 시 | Nginx, Redis, Node.js(libuv) |
6. 실무 프레임워크/기술 스택 매핑
✨ 웹 서버 아키텍처
| 서버 | I/O 모델 | 조합 | 동시 처리 방식 |
|---|---|---|---|
| Apache (Prefork) | Blocking I/O | Blocking + Sync | 프로세스 당 1 요청 |
| Apache (Worker) | Blocking I/O | Blocking + Sync | 스레드 당 1 요청 |
| Nginx | epoll + Event-driven | Non-blocking + Async | 이벤트 루프 (소수 워커 프로세스) |
| Node.js | libuv (epoll/kqueue) | Non-blocking + Async | 싱글 스레드 이벤트 루프 |
| Netty (Java) | Java NIO + epoll | Non-blocking + Async | 이벤트 루프 그룹 |
전통적인 Apache는 "연결 하나당 프로세스/스레드 하나"를 할당한다. 하지만 접속자가 1만 명(C10K)이 넘어가면 스레드가 너무 많아져서 서버가 컨텍스트 스위칭만 하다가 지쳐버린다.
Nginx는 Async-Non-blocking 기반의 이벤트 루프를 사용한다. 소수의 워커 프로세스가 수만 개의 연결을 '이벤트'로 처리하기 때문에, 메모리 사용량이 적고 동시 처리에 압도적으로 유리하다.
✨ Java 생태계: MVC vs. WebFlux
Java 진영에서는 "안정성의 MVC"와 "성능의 WebFlux"가 공존하고 있다.
Spring MVC (Blocking + Sync)
└─ Tomcat → 스레드 풀 → 요청 당 1 스레드 점유
└─ JDBC → Blocking DB 호출
Spring WebFlux (Non-blocking + Async)
└─ Netty → 이벤트 루프 → 소수 스레드로 다수 요청 처리
└─ R2DBC → Non-blocking DB 호출
└─ Mono/Flux → Reactive Streams- Spring MVC (Blocking + Sync)
- 특징: 요청이 들어오면 스레드 풀에서 스레드를 하나 꺼내서 끝까지 책임진다. DB 결과가 나올 때까지 스레드는 멈춰 있는다.
- 한계: 대규모 트래픽이 몰리면 스레드 풀이 금방 고갈된다.
- Spring WebFlux (Non-blocking + Async)
- 특징: Netty라는 고성능 네트워크 엔진 위에서 돌아간다. I/O 작업(DB, API 호출)을 던져 놓고 스레드는 바로 다른 요청을 받으러 간다.
- 주의점: 전 구간이 Non-blocking이어야 한다. 만약 WebFlux에서 Blocking 방식의 JDBC를 쓰면, 소수의 이벤트 루프 스레드가 멈춰버려서 서버 전체가 마비되는 Async-Blocking 안티패턴이 발생한다.
✨ Python 생태계: Flask/Django vs. FastAPI
AI 분야에서 FastAPI가 대세가 된 이유가 바로 여기에 있다.
Flask/Django (Blocking + Sync, WSGI 기반)
└─ 요청 당 1 스레드/프로세스
└─ DB 호출 시 블로킹
FastAPI (Non-blocking + Async, ASGI 기반)
└─ uvicorn → asyncio 이벤트 루프
└─ async def 핸들러 → Non-blocking
└─ asyncpg, aiohttp → Async DB/HTTP 호출⭐ WSGI (Web Server Gateway Interface)
동기 기반의 파이썬 웹 애플리케이션과 서버 간 통신을 위한 전통적 프로토콜이며, 단일 요청 처리에 최적화되어 있다.
⭐ ASGI (Asynchronous Server Gateway Interface)
WSGI의 상위 버전으로 비동기 처리를 지원하며, 웹소켓, HTTP/2 등 현대적인 네트워크 기능도 가능하다.
- FastAPI (Non-blocking + Async)
- 특징: Python의
asyncio를 기반으로 한다. LLM API 호출처럼 대기 시간이 긴 작업을 처리할 때await를 사용하면, 그동안 다른 사용자의 요청을 처리할 수 있다. - RAG에서의 강점: 여러 개의 벡터 DB 검색이나 외부 API 호출을
asyncio.gather()로 묶어서 병렬(Parallel)로 처리할 수 있기 때문에 전체 응답 속도를 획기적으로 줄일 수 있다.
- 특징: Python의
7. 핵심 혼동 포인트 정리
✨ 혼동 1: Non-blocking이면 무조건 Asynchronous?
-
정답: 아니다.
-
이유:
Non-blocking + Synchronous가 존재한다.
Non-blocking은 "즉시 리턴"을 의미하고, Synchronous는 "완료를 직접 확인"을 의미한다. 즉시 리턴받고도 반복적으로 완료를 폴링하면 Non-blocking + Sync가 된다. -
실무 예시:
Java NIO의 초기 모델, 데이터가 올 때까지while문을 돌며 소켓을 체크하는 코드
✨ 혼동 2: Blocking이면 무조건 Synchronous?
-
정답: 거의 그렇지만 반드시 그렇지는 않다.
-
이유:
보통 블로킹되면 결과가 나올 때까지 기다리니 동기(Sync)로 작동한다. 하지만 Async-Blocking(Blocking + Asynchronous)이라는 안티패턴이 존재한다.
예를 들어select()는 자체가 블로킹이지만, I/O 이벤트를 다중으로 기다린다는 점에서 비동기적 요소가 있다. -
실무 예시:
비동기 프레임워크(Node.js)에서 실수로 동기식 DB 드라이버를 호출하는 경우가 이에 해당한다.
호출자는 비동기적으로 결과를 받고 싶어 하지만(Async), 실제로는 그 구간에서 스레드가 멈춰버려(Blocking) 전체 시스템에 민폐를 끼치게 된다.
✨ 혼동 3: Callback을 쓰면 무조건 Asynchronous?
-
정답: 절대 아니다.
-
이유:
콜백 함수는 단순히 함수를 인자로 넘기는 패턴일 뿐이다. 동기적으로 실행되는 콜백도 있다.// 동기 콜백 (Synchronous) - map은 즉시 실행 [1, 2, 3].map(x => x * 2); // 비동기 콜백 (Asynchronous) - 나중에(1초 후에) 실행 setTimeout(() => console.log('나중에!'), 1000);
✨ 혼동 4: 멀티스레드 = Asynchronous?
-
정답: 아니다.
-
이유:
비동기는 완료 통보 메커니즘에 관한 것이지, 스레드 수와 직접적인 관계는 없다. 이건 '일꾼의 수'와 '일하는 방식'을 혼동하는 것이다.- Multi-thread + Sync: 일꾼은 많지만, 각 일꾼은 자기 일이 끝날 때까지 멍하니 기다려야 한다. (전통적인 Tomcat/Spring MVC)
- Single-thread + Async: 일꾼은 한 명뿐이지만, 일이 진행되는 동안 다른 일을 계속 받아 처리한다. (Node.js)
-
결론: 비동기는 적은 수의 일꾼으로도 효율적으로 일하기 위한 전략이지, 일꾼의 수 자체가 아니다.
8. Node.js 이벤트 루프 실전 예시
Node.js는 Non-blocking + Async의 대표적 구현체이다. Node.js의 핵심은 "JS를 실행하는 스레드는 하나지만, I/O를 처리하는 시스템은 멀티 스레드다"라는 점이다.
어떻게 싱글 스레드인데 수만 개의 동시 연결을 처리하는지 이해해 보자.
✨ 주요 단계
┌───────────────────────────┐
┌─▶│ timers │ (setTimeout, setInterval 콜백)
│ └─────────────┬─────────────┘
│ ┌─────────────▼─────────────┐
│ │ pending callbacks │ (시스템 콜 콜백)
│ └─────────────┬─────────────┘
│ ┌─────────────▼─────────────┐
│ │ idle, prepare │ (내부 용도)
│ └─────────────┬─────────────┘
│ ┌─────────────▼─────────────┐
│ │ poll │ (I/O 이벤트 수집, I/O 콜백 실행)
│ └─────────────┬─────────────┘ ← epoll_wait() 여기서 호출
│ ┌─────────────▼─────────────┐
│ │ check │ (setImmediate 콜백)
│ └─────────────┬─────────────┘
│ ┌─────────────▼─────────────┐
│ │ close callbacks │ (socket.on('close') 등)
│ └─────────────┬─────────────┘
└──────────────────────────────┘- 동작 원리
- 파일 읽기, DB 쿼리 등 I/O 요청이 들어오면 OS 커널(또는 libuv 스레드풀)에 위임
- 메인 스레드는 즉시 다음 작업 처리 (Non-blocking)
- I/O 완료 시 이벤트 큐에 콜백 등록
- 이벤트 루프가 큐를 순회하며 콜백 실행 (Async 통보)
- 상세 설명
- Timers:
setTimeout()이나setInterval()로 예약된 콜백이 실행된다. 정확히는 "지정된 시간 이후"에 실행되도록 보장하는 단게이다. - Poll: 이벤트 루프의 심장이다. 여기서 새로운 I/O 이벤트를 가져오고 콜백을 실행한다.
만약 처리할 콜백이 없다면, 다음 단계로 넘어가지 않고 여기서epoll_wait를 하며 잠시 대기한다. - Check:
setImmediate()콜백이 여기서 실행된다. Poll 단계가 끝나자마자 바로 실행하고 싶은 로직이 있다면 여기에 둔다. - Close callbacks:
socket.on('close', ...)같은 리소스 정리 콜백들이 처리된다.
- Timers:
- 주의: CPU 집약적 작업(암호화, 이미지 처리)은 이벤트 루프를 블로킹하므로 Worker Thread를 사용해야 한다.
✨ libuv의 비밀: 커널 vs. 스레드 풀
모든 비동기 작업이 똑같이 처리되는 건 아니다.
- Network I/O: OS 커널(epoll, kqueue 등)이 직접 처리한다. 스레드가 필요 없다. 그래서 수만 개의 연결을 가볍게 처리할 수 있다.
- File I/O, DNS: OS마다 비동기 API가 제각각이라, libuv가 내부적으로 스레드 풀(기본 4개)을 사용해서 비동기처럼 보이게 처리한다.
✨ 숨겨진 복병: Microtask Queue
이벤트 루프의 각 단계 사이사이에는 Microtask Queue가 끼어든다.
- 구성:
process.nextTick()과 Promise 콜백이 여기에 해당된다. - 특징: 이벤트 루프의 현재 단계가 끝나면, 다음 단계로 넘어가기 전에 Microtask Queue에 쌓인 모든 작업을 먼저 싹 비운다.
- 주의: 만약 Promise 콜백 안에서 계속 새로운 Promise를 생성하면 이벤트 루프가 Poll 단계로 가지 못하고 갇혀버릴 수 있다.
✨ 실전 주의사항
- 문제 상황: 만약
bcrypt로 암호를 해싱하거나, 엄청나게 큰 JSON을 파싱하는 CPU 집약적 작업을 메인 스레드에서 하면 어떻게 될까? - 결과: 이벤트 루프가 그 작업에 매여서 다음 단계(Poll)로 못 간다. 그럼 다른 사용자의 네트워크 요청도, 타이머도 모두 멈춰버린다.
- 해결책
- Worker Threads: 별도의 스레드에서 CPU 작업을 수행한다.
- 외부 서비스: 이미지 처리나 복잡한 연산은 별도의 서버(Python 등)에 맡기고 비동기로 결과를 받는다.
