1. 로드 밸런싱이란?
✨ 정의 및 목적
- 정의
- 네트워크 트래픽이나 작업 부하(Load)를 여러 컴퓨팅 자원(서버/CPU/저장장치 등)에 고르게 분산(Balancing)시키는 기술
- 클라이언트와 백엔드 서버 사이에 위치하는 로드 밸런서(Load Balancer)가 요청을 수신하여 적절한 서버로 라우팅해주며, 특정 서버의 과부하나 장애 시 자동으로 다른 서버로 우회시키는 역할을 한다.
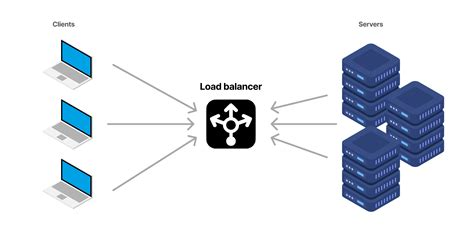
- 목적
- 단일 서버에 부하가 집중되는 것을 방지한다.
- 시스템 전체의 가용성(Availability), 응답성(Responsiveness), 확장성(Scalability)을 확보한다.
✨ 왜 필요한가?
- 고가용성(High Availability): 서버 1대가 장애가 나도 다른 서버가 요청을 처리하여 무중단 서비스가 가능하다.
- 확장성(Scalability): 트래픽 증가 시 서버를 추가하는 것만으로도 수평 확장이 가능하다.
- 성능 최적화: 요청을 분산하여 각 서버의 응답 시간을 단축한다.
- 자원 효율성: 모든 서버가 고르게 일하므로 유휴(idle) 서버를 최소화할 수 있다.
- 보안 강화: 클라이언트가 실제 서버 IP를 직접 알 수 없어 DDoS 공격 방어에 유리하다.
⭐ DDoS (Distributed Denial of Service, 분산 서비스 거부 공격)
여러 대의 컴퓨터가 동시에 특정 서버나 사이트에 엄청난 양의 요청을 보내서 정상적인 사용자가 서비스를 이용하지 못하게 만드는 공격
✨ Scale-Up vs. Scale-Out
| 구분 | Scale-Up (수직 확장) | Scale-Out (수평 확장) |
|---|---|---|
| 방식 | 기존 서버의 하드웨어 성능 향상 | 서버 대수를 늘려 부하 분산 |
| 비용 | 고사양으로 갈수록 급격히 상승 | 저사양 서버 추가로 선형 증가 |
| 한계 | 물리적 한계 존재 (CPU, RAM 상한) | 이론상 무한 확장 가능 |
| 장애 대응 | 단일 장애점 (SPOF) | 무중단 서비스 용이 |
| 적합 상황 | DB 서버, 레거시 시스템 | 웹 서버, API 서버, MSA |
| 예시 | CPU 8코어→16코어 업그레이드 | EC2 인스턴스 2대→8대로 증설 |
⭐ SPOF (Single Point of Failure, 단일 장애 지점)
한 부분이 고장 나면 전체 서비스나 시스템이 멈출 수 있는 핵심 지점
⭐ EC2 인스턴스
AWS에서 빌려 쓰는 가상 서버
- EC2 = Amazon Elastic Compute Cloud
- 인스턴스 = 그 EC2 서비스 위에서 실제로 만들어서 실행 중인 가상 컴퓨터 1대
🔑 핵심 포인트
실무에서는 Scale-Up과 Scale-Out을 혼합 사용한다.
DB는 Scale-Up 위주, 애플리케이션 서버는 Scale-Out 위주로 구성하는 것이 일반적이다.
2. 로드 밸런서의 유형
✨ OSI 계층별 분류
로드 밸런서는 동작하는 OSI 계층에 따라 크게 L4와 L7로 구분된다.
| 구분 | L4 로드 밸런서 | L7 로드 밸런서 |
|---|---|---|
| 계층 | Transport Layer (TCP/UDP) | Application Layer (HTTP/HTTPS) |
| 판단 기준 | IP 주소 + 포트 번호 | URL, HTTP 헤더, 쿠키, 콘텐츠 타입 |
| 성능 | 빠름 (L7보다 오버헤드 적음) | L4보다 느리지만 정밀한 라우팅 |
| 세부 제어 | 제한적 | URL 기반 라우팅, A/B 테스트, 캐시 등 가능 |
| SSL 처리 | 불가 (복호화 불가) | SSL Termination 가능 |
| 사용 예시 | TCP 기반 게임 서버, DNS 밸런싱 | API Gateway, CDN, 웹 애플리케이션 |
| 대표 제품 | AWS NLB, HAProxy (TCP mode) | AWS ALB, Nginx, HAProxy (HTTP mode) |
| 장점 | 보안성이 높고 저렴함 | 비정상적인 트래픽 필터링 및 효율적인 캐싱 가능 |
| 단점 | 패킷 내용을 알 수 없어 섬세한 제어 불가 | 패킷을 복호화해야 하므로 자원 소모가 더 큼 |
✨ 하드웨어 vs. 소프트웨어 로드 밸런서
| 구분 | 하드웨어 LB | 소프트웨어 LB |
|---|---|---|
| 형태 | 전용 물리 장비 | 소프트웨어로 구현 |
| 성능 | 초고속 (ASIC 칩 기반) | 하드웨어보다는 느리지만 충분 |
| 비용 | 수천만~수억원 | 오픈소스 무료 또는 저렴 |
| 예시 | F5 BIG-IP, Citrix ADC | Nginx, HAProxy, Envoy |
3. 로드 밸런싱 알고리즘 상세
✨ 정적 알고리즘 (Static Algorithms)
서버의 현재 상태를 고려하지 않고 미리 정해진 규칙에 따라 분배한다.
- 라운드 로빈 (Round Robin)
- 정의: 요청을 서버 목록에 순서대로 돌아가며 배분한다. CPU 스케줄링의 Round Robin과 동일한 원리이다.
- 장점: 구현이 가장 간단하고 예측 가능하다.
- 단점: 서버별 성능 차이를 반영하지 못한다. 고사양 서버와 저사양 서버가 혼재하면 비효율적이다.
- 적합한 상황: 모든 서버의 사양이 동일하고, 요청 처리 시간이 비슷한 경우
- 가중 라운드 로빈 (Weighted Round Robin)
- 정의: 각 서버에 가중치(Weight)를 부여하여 성능이 좋은 서버에 더 많은 요청을 배분한다.
- 예시: 서버 A(weight=5), B(weight=3), C(weight=2)이면 10개 요청 중 A에 5개, B에 3개, C에 2개를 배분한다.
- 장점: 서버별 성능 차이를 반영할 수 있다.
- 단점: 실시간 부하 변화를 반영하지 못한다. 가중치 설정이 수동이다.
- IP 해시 (Source/IP Hash)
- 정의: 클라이언트의 IP 주소를 해시 함수에 통과시켜 특정 서버에 매핑한다. 동일한 클라이언트는 항상 같은 서버로 연결된다.
- 장점: 세션 유지(Session Persistence/Sticky Session)가 보장된다.
- 단점: 서버 추가/제거 시 해시 분포가 크게 변동될 수 있다. (rehashing 문제)
- 해결책: Consistent Hashing을 적용하면 서버 변경 시 영향을 최소화할 수 있다.
⭐ Consistent Hashing
- 정의: 서버가 추가되거나 제거될 때, 기존 데이터나 요청의 재배치 범위를 최소화하는 해시 방식
- 핵심 아이디어: 서버와 요청(또는 데이터)을 원형 해시 공간 위에 배치해두고, 각 요청은 자기 위치에서 가장 가까운 서버로 보낸다.
✨ 동적 알고리즘 (Dynamic Algorithms)
서버의 현재 상태(connection 수, 응답 시간 등)를 실시간으로 모니터링하여 반영한다.
- Least Connections
- 정의: 현재 연결 수가 가장 적은 서버에 새 요청을 배분한다.
- 적합한 상황: 요청 처리 시간이 불균일하여 세션이 길어지는 경우 (DB 쿼리, WebSocket, 파일 업로드)
- 변형: Weighted Least Connections (서버 성능에 따른 가중치를 추가 반영)
- Least Response Time
- 정의: 현재 연결 수가 가장 적으면서 평균 응답 시간이 가장 짧은 서버에 우선 배분한다.
- 장점: Least Connections보다 더 정밀한 부하 판단이 가능하다.
- 단점: 응답 시간 측정을 위한 추가 오버헤드가 발생한다.
- Resource-Based (Adaptive)
- 정의: 서버의 CPU, 메모리, 네트워크 대역폭 등 실제 자원 사용량을 모니터링하여 분배한다. 에이전트(Agent)가 각 서버에 설치되어 상태 정보를 주기적으로 보고한다.
✨ 알고리즘 선택 가이드
| 상황 | 권장 알고리즘 | 이유 |
|---|---|---|
| 서버 사양 동일, 요청 균일 | Round Robin | 가장 간단하고 효과적 |
| 서버 사양 불균일 | Weighted Round Robin | 성능 차이 반영 |
| 세션 유지 필요 | IP Hash | 동일 클라이언트 → 동일 서버 |
| 요청 처리 시간 편차 큼 | Least Connections | 실시간 부하 반영 |
| 마이크로서비스(MSA) | L7 + Least Connections | URL 기반 라우팅 + 부하 분산 |
4. 세션 유지(Session Persistence) 전략
여러 대의 서버를 운영하는 Scale-out 환경에서는 클라이언트의 요청이 매번 다른 서버로 전달될 수 있다.
이때 사용자의 로그인 정보와 같은 '세션'을 어떻게 유지하느냐가 시스템의 안정성과 확장성을 결정짓는 핵심 요소이다.
✨ Sticky Session (부하 분산 기반 고정)
- 정의: 특정 사용자의 요청이 처음 처리되었던 서버로만 계속 전달되도록 로드 밸런서가 강제하는 방식
- 구현 방식
- Source IP Hash: 사용자의 IP 주소를 해싱하여 특정 서버에 매핑한다.
- Cookie: 로드 밸런서가 세션 쿠키를 삽입하여 서버를 식별한다.
- 장점: 서버 코드를 수정할 필요가 없으며 구현이 간단하다.
- 단점
- 부하 불균형: 특정 서버에 사용자가 몰릴 경우 트래픽이 편향될 수 있다.
- 가용성 문제: 해당 서버가 다운되면 해당 서버에 할당된 모든 사용자의 세션 데이터가 유실된다.
✨ 세션 클러스터링 (Session Clustering)
- 정의: 모든 WAS(Web Application Server)가 서로의 세션 데이터를 복제하여 공유하는 방식
- 구현 방식: 한 서버에서 세션이 생성/수정되면 다른 모든 서버로 해당 데이터를 전송(Replication)한다.
- 장점: 특정 서버가 다운되어도 다른 서버에 복제본이 있어 서비스가 중단되지 않는다. (고가용성 보장)
- 단점
- 오버헤드: 서버 수가 늘어날수록 복제해야 할 데이터 양과 네트워크 통신량이 기하급수적으로 증가한다. (O(n²))
- 메모리 낭비: 모든 서버가 동일한 세션 정보를 중복해서 들고 있어야 한다.
✨ 외부 세션 저장소 (External Session Store)
- 정의: 세션 데이터를 서버 내부 메모리가 아닌, 별도의 독립된 저장소(Redis, Memacached 등)에 보관하는 방식
- 구현 방식: 모든 서버가 공용 저장소를 바라보게 설정한다.
- 장점
- Stateless 서버: 서버는 세션 데이터를 직접 관리하지 않으므로 자유로운 Scale-out이 가능하다.
- 데이터 정합성: 어떤 서버로 접속하더라도 동일한 세션 저장소를 참조하므로 데이터 불일치가 발생하지 않는다.
- 단점: 외부 저장소 자체가 장애 포인트(SPOF)가 될 수 있으므로, 저장소 자체의 이중화(Replication/Sentinel) 구성이 필수적이다.
✨ 세션 관리 전략 비교
| 구분 | Sticky Session | Session Clustering | External Store |
|---|---|---|---|
| 데이터 위치 | 개별 서버 메모리 | 모든 서버 메모리 복제 | 외부 공유 저장소 (Redis 등) |
| 확장성 | 보통 | 낮음 (서버 증가 시 부하 급증) | 매우 높음 |
| 가용성 | 낮음 (서버 장애 시 유실) | 높음 | 매우 높음 |
| 관리 복잡도 | 낮음 | 중간 | 중간 (외부 인프라 관리 필요) |
5. Health Check 메커니즘
로드 밸런서는 백엔드 서버들이 살아있는지 주기적으로 확인하여, 건강한(Healthy) 서버에만 요청을 전달하고 문제가 있는(Unhealthy) 서버는 서비스에서 일시적으로 제외한다.
✨ Health Check 방식 (OSI 계층별 분류)
단순히 서버가 켜져 있는지 확인하는 것을 넘어, 실제 서비스가 가능한 상태인지 확인하기 위해 다양한 계층의 방식을 혼합하여 사용한다.
| 방식 | 계층 | 확인 방법 | 특징 |
|---|---|---|---|
| ICMP (Ping) | L3 | ICMP Echo Request를 보내 응답 확인 | 네트워크 연결성만 확인 가능 (실제 앱 상태는 모름) |
| TCP Check | L4 | 3-way Handshake를 통해 포트 열림 확인 | 빠르고 부하가 적지만, 프로세스 좀비 상태 등은 감지 불가 |
| HTTP Check | L7 | 특정 URL(예: /health)로 GET 요청 후 응답 코드 확인 | 가장 권장됨. DB 연결 등 실제 앱 로직의 정상 작동 확인 가능 |
| Custom Script | - | 서버 내 에이전트가 DB, 디스크, CPU 등을 체크 | 매우 정교한 상태 확인이 가능하나 설정이 복잡함 |
✨ 주요 설정 파라미터 및 판정 기준
상태 확인의 정확도를 높이고, 일시적인 네트워크 불안정으로 인해 서버가 서비스에서 빈번하게 빠졌다가 들어오는 Flapping(플래핑) 현상을 방지하기 위해 아래 파라미터들을 정교하게 설정한다.
- Interval (주기): Health Check를 수행하는 시간 간격 (보통 5~10초)
- Timeout (타임아웃): 응답을 기다리는 최대 시간. 이 시간을 넘기면 1회 실패로 간주한다.
- Unhealthy Threshold (실패 임계치): 연속으로 N회 실패하면 해당 서버를 비정상(Unhealthy)으로 판단하고 트래픽 배분에서 제외한다.
- Healthy Threshold (성공 임계치): 비정상 상태였던 서버가 다시 연속으로 M회 성공하면 정상(Healthy)으로 복구시켜 트래픽을 다시 보낸다.
✨ Health Check 워크플로우 시각화
서버가 장애에서 복구되어 다시 서비스에 투입되는 과정을 나타낸 흐름이다.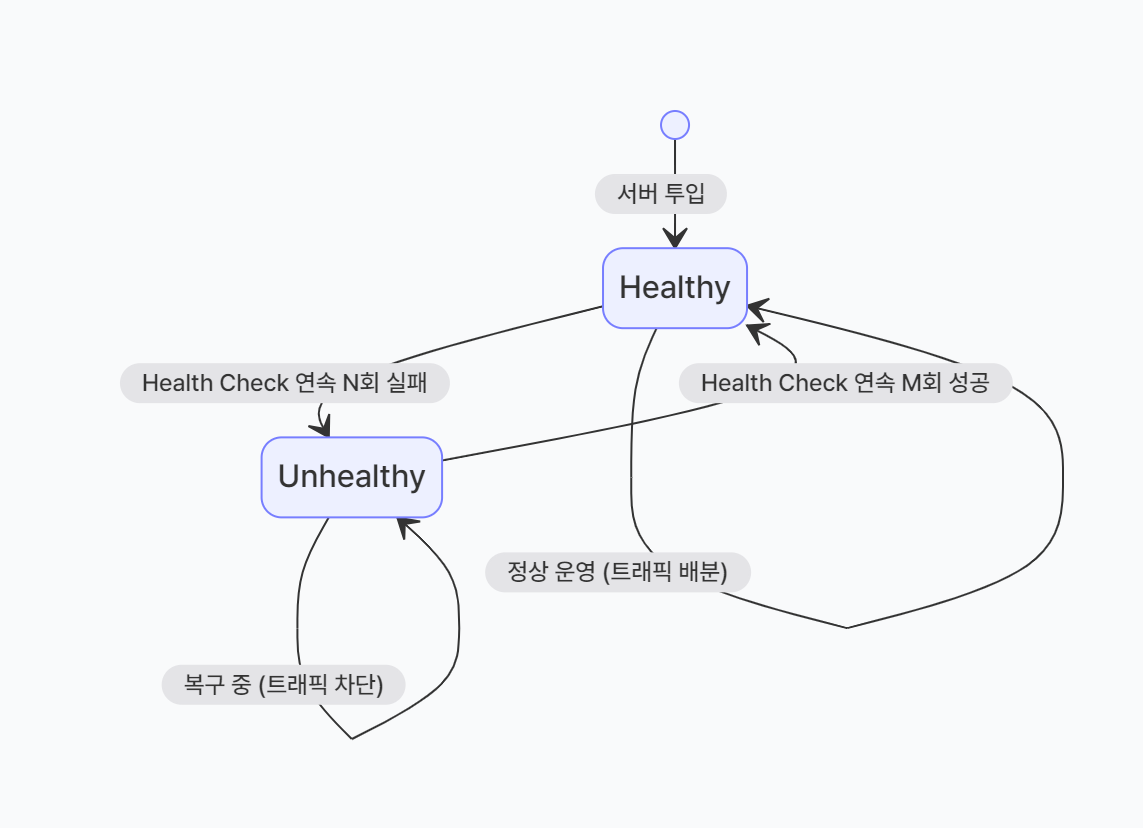
✨ 운영 시 고려해야 할 포인트
- L7 Health Check의 중요성
TC 포트만 열려 있고 실제 DB 연결이 끊어져 에러 페이지가 뜨는 경우, TCP Check는 '정상'으로 판단하지만 HTTP Check는 '비정상'으로 판단하여 사용자의 불편을 막을 수 있다. - 부하 고려
Health Check 주기가 너무 짧으면 로드 밸런서와 서버 모두에 불필요한 부하를 줄 수 있으므로 서비스 특성에 맞는 최적의 값을 찾아야 한다. - Graceful Shutdown
서버 점검 시 의도적으로 Health Check 응답을 실패하게 만들어(예: 특정 파일 삭제), 트래픽이 자연스럽게 끊기도록 유도한 뒤 안전하게 서버를 내릴 수 있다.
6. 로드 밸런서 고가용성(HA) 구성
로드 밸런서가 중단되면 뒤에 있는 수십 대의 서버가 정상이라도 서비스 전체가 마비된다.
이를 방지하기 위해 로드 밸런서를 이중화하여 무중단 서비스를 보장한다.
✨ Active-Passive (장애 대비형)
- 정의: 가장 표준적인 구성 방식으로, 한 대는 실무를 담당하고 다른 한 대는 비상 대기하는 형태
- 작동 원리
- VIP (Virtual IP): 클라이언트는 개별 서버 IP가 아닌 가상의 대표 IP(VIP)로 접속한다.
- Heartbeat: 두 로드 밸런서는 서로 '살아있음'을 알리는 신호(Heartbeat)를 주고받는다.
- Failover: Active 장비에 장애가 발생하여 신호가 끊기면, Passive 장비가 즉시 VIP를 인계받아 서비스를 계속한다.
- 장점: 구성이 비교적 단순하며, 장애 발생 시 전환히 확실하다.
- 단점: 평상시 Passive 장비의 자원이 낭비된다는 경제적 단점이 있다.
✨ Active-Active (성능 확장형)
- 정의: 두 대 이상의 로드 밸런서가 동시에 트래픽을 처리하는 방식
- 작동 원리
- GSLB/DNS: DNS 라운드 로빈 등을 통해 트래픽을 여러 로드 밸런서로 먼저 분산시킨다.
- 모든 로드 밸런서가 활성화되어 각자의 부하를 처리한다.
⭐ GSLB (Global Server Load Balancing)
전 세계에 분산된 서버 간에 인터넷 트래픽을 효율적으로 분산하여, 사용자가 가장 가까운 데이터센터로 접속하게 하고, 서버 장애 시 우회 경로를 제공하여 서비스 안정성을 높이는 DNS 기반 기술
- 장점: 전체 처리 용량이 늘어나며 자원 활용률이 극대화된다.
- 단점: 설정이 매우 복잡하며, 로드 밸런서 간의 상태 동기화 비용이 발생한다.
✨ HA 구성 방식 비교
| 구분 | Active-Passive | Active-Active |
|---|---|---|
| 자원 효율성 | 낮음 (1대는 대기만 함) | 높음 (모든 자원 활용) |
| 장애 대응 | Failover 시 약간의 지연 발생 가능 | 즉각적인 대응 가능 (남은 장비가 처리) |
| 구성 난이도 | 보통 | 높음 |
| 비용 | 동일 사양 2대 필요 (가성비 낮음) | 동일 사양 2대 필요 (가성비 높음) |
| 주요 기술 | VRRP, Heartbeat | GSLB, DNS Round Robin |
⭐ VRRP (Virtual Router Redundancy Protocol)
여러 대의 라우터를 하나의 그룹으로 묶어 가상 IP를 부여하고, 마스터(Active) 장비가 죽으면 백업(Passive) 장비가 그 역할을 자동으로 승계하도록 돕는 핵심 기술
7. DNS 및 글로벌 로드 밸런싱 (GSLB)
서비스 규모가 커져 여러 지역(Region)에 데이터 센터를 운영하게 되면, 사용자를 가장 가까운 곳으로 안내하거나 특정 지역의 장애에 대응하는 기술이 필요하다.
✨ DNS 라운드 로빈 (DNS Round Robin)
- 정의: 하나의 도메인 이름에 여러 개의 서버 IP 주소를 등록하여, DNS 서버가 요청이 올 때마다 순서대로 IP를 반환하는 방식
- 특징: 별도의 장비 없이 DNS 설정만으로 구현 가능한 가장 기본적인 분산 방식이다.
- 한계점
- 상태 확인 불가: 서버가 죽어도 DNS는 계속 해당 IP를 알려준다. (Health Check 부재)
- 캐싱 문제: 클라이언트나 ISP의 DNS 캐시(TTL) 때문에 서버를 목록에서 제외해도 한동안 트래픽이 계속 유입될 수 있어 실시간 대응이 어렵다.
✨ GSLB (Global Server Load Balancing)
- 정의: DNS의 원리를 이용하되, 서버의 상태와 사용자의 위치 등을 지능적으로 판단하여 최적의 IP를 응답하는 기술
- 핵심 기능
- Health Check: 각 데이터 센터의 상태를 주기적으로 확인하여, 장애가 발생한 곳의 IP는 응답에서 즉시 제외한다.
- 지리적 라우팅 (Geo-location): 사용자의 IP를 분석하여 물리적으로 가장 가까운 데이터 센터로 연결해 응답 속도(Latency)를 최소화한다.
- 부하 기반 라우팅: 특정 데이터센터에 트래픽이 몰리면 여유 있는 다른 지역으로 유도한다.
- 재해 복구 (Disaster Recovery): 특정 리전 전체가 마비되어도 다른 리전으로 자동 전환(Failover)하여 서비스 연속성을 보장한다.
✨ DNS 라운드 로빈 vs. GSLB 비교
| 구분 | DNS 라운드 로빈 | GSLB |
|---|---|---|
| 판단 기준 | 단순 순번 (Rotation) | 상태, 거리, 부하, 가용성 등 종합 판단 |
| Health Check | 없음 (장애 서버로도 전송) | 있음 (정상 서버만 응답) |
| 사용자 경험 | 지역에 상관없이 무작위 연결 | 최단 거리 데이터 센터 연결 (빠름) |
| 장애 대응 | TTL 만료 전까지 대응 불가 | 실시간에 가까운 자동 Failover |
| 대표 서비스 | 일반 DNS 서버 | AWS Route 53, Cloudflare, Akamai |
8. 실무 아키텍처 패턴
현대적인 대규모 웹 서비스는 단일 로드 밸런서가 아니라, 글로벌 - 리전 - 애플리케이션 - 데이터 계층으로 이어지는 다중 로드 밸런싱 구조를 가진다.
✨ 계층별 트래픽 흐름 (End-to-End)
- Global Layer (DNS/GSLB): 사용자와 가장 가까운 리전(데이터 센터)의 IP를 반환한다.
- Edge Layer (CDN/WAF): 정적 콘텐츠(이미지, JS 등)를 캐싱하고, 악성 공격(DDoS, SQL Injection)을 필터링한다.
- Regional Layer (L7 LB): SSL Termination(복호화 처리)을 수행하고, URL 경로(예:
/apivs./static)에 따라 적절한 서버 그룹으로 전달한다. - Application Layer (Auto Scaling): 트래픽 양에 따라 서버 대수를 자동으로 조절하며, Least Connections 알고리즘으로 부하를 분산한다.
- Data Layer (Read/Write Splitting): 쓰기 작업은 Master DB로, 읽기 작업은 여러 대의 Read Replica로 분산하여 DB 부하를 관리한다.
✨ AWS 기반 클라우드 네이티브 구성
AWS 환경에서는 관리형 서비스를 조합하여 높은 가용성과 확장성을 확보한다.
| 계층 | AWS 서비스 | 주요 역할 및 특징 |
|---|---|---|
| 글로벌 DNS | Route 53 | 지연 시간 기반 라우팅, 상태 확인 기반 Failover |
| 보안 & 캐시 | CloudFront + WAF | 전 세계 엣지 로케이션 캐싱 + 웹 방화벽 보안 |
| L7 밸런싱 | ALB (Application LB) | HTTP/HTTPS 경로 기반 라우팅, Lambda/컨테이너 연동 |
| 컴퓨팅 | EC2 Auto Scaling | 부하에 따른 서버 인스턴스 자동 증설/축소 |
| 세션 저장 | ElastiCache (Redis) | 분산 세션 관리 및 데이터 캐싱 (In-memory) |
| 데이터베이스 | RDS Multi-AZ | 마스터 장애 시 대기 장비로 자동 전환 (고가용성) |
✨ Nginx 로드 밸런싱 설정 예시
Nginx는 가볍고 강력한 성능 덕분에 소프트웨어 로드 밸런서로 가장 많이 사용된다.
upstream backend_servers {
# 1. 알고리즘 선택: 연결 수가 가장 적은 서버 우선
least_conn;
# 2. 서버 목록 및 가중치(Weight) 설정
server 10.0.1.1:8080 weight=5; # 고사양 서버: 더 많은 요청 처리
server 10.0.1.2:8080 weight=3; # 중간 사양
server 10.0.1.3:8080 weight=1; # 저사양 서버
# 3. 상태 확인 및 장애 대응
# 30초 동안 2번 실패하면 30초간 제외
server 10.0.1.4:8080 max_fails=2 fail_timeout=30x;
# 4. 백업 서버: 모든 서버 장애 시에만 활성화
server 10.0.1.5:8080 backup;
}
server {
listen 80;
server_name gyoogle.dev;
location / {
proxy_pass http://backend_servers; # 위에서 정의한 그룹으로 전달
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}