Java로 알고리즘을 풀면 Collection을 활용하는 모습을 보게 된다.
주로 보게되는 자료형을 조금 정리해보고자 한다.
Collection란
JDK 1.2 부터 'Collection Framework'라는 개념으로 정의가 되었다.
다수의 데이터를 쉽고 효과적으로 처리할 수 있는 표준화된 방법을 제공하는 클래스의 집합을 의미한다.
즉, 데이터를 저장하는 자료구조와 데이터를 처리하는 알고리즘을 구조화하여 클래스로 구현해놓은 것.
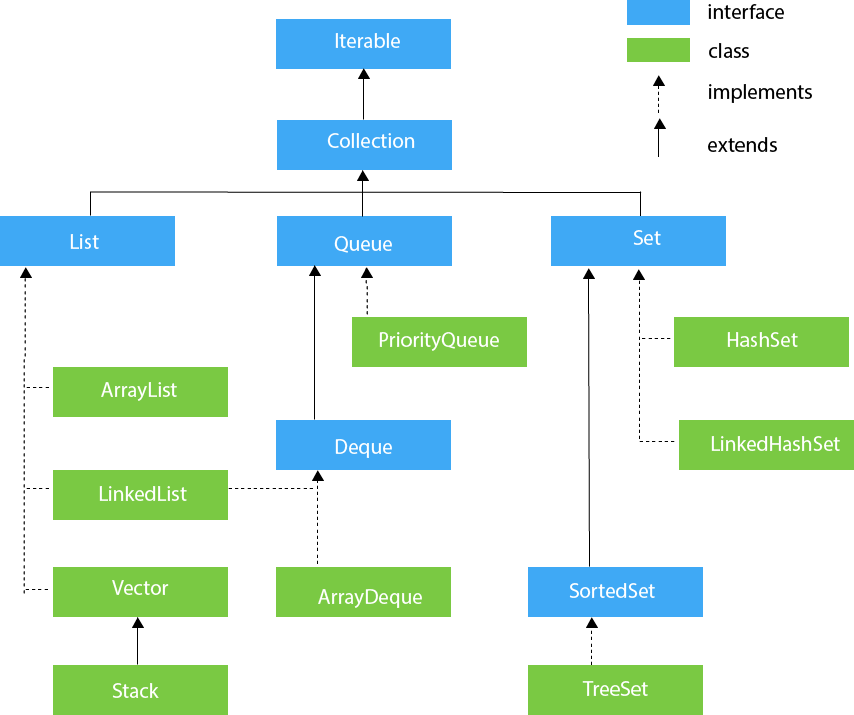
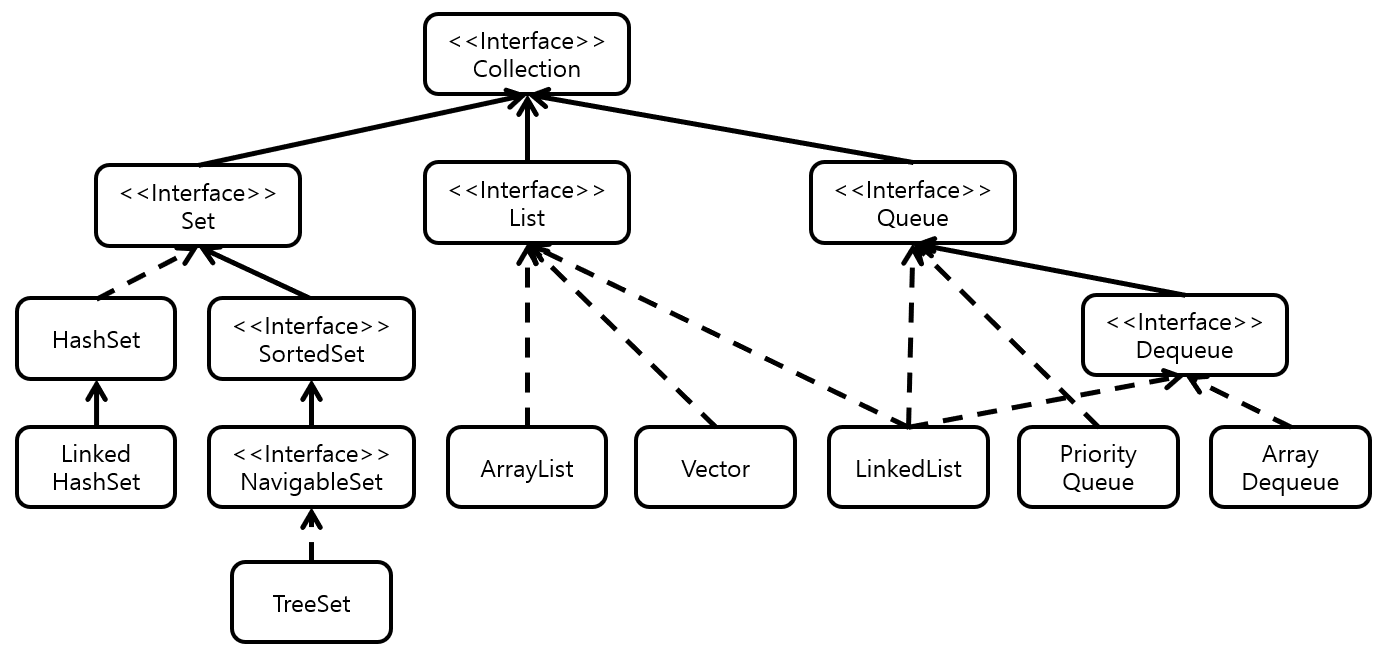
클래스의 집합이기 때문에 하위에 컬렉션을 인터페이스해 구현된 다양한 자료구조를 포함하고 있다.
- 순서가 있는 목록인 List형
- 순서가 중요하지 않은 목록인 Set형
- 먼저 들어온 것이 먼저 나가는 Queue형
- Key-Value의 형태로 저장되는 Map형
Map은 Key-Value 구조가 기존 Collection 구조와 많이 상이하기에 별도로 분리되어있지만, 분류상 Collection으로 분류된다.
List형
List에는 배열과 같이 순서가 존재한다.
List 컬렉션은 객체를 일렬로 늘어놓은 구조를 가지고 있으며, 객체를 인덱스로 관리한다.
저장되는 객체에는 인덱스가 부여되고, 해당 인덱스로 객체를 관리한다.
저장에는 객체 자체 대신 객체의 주소를 참조한다.
즉, 인덱스 마다 객체의 주소가 들어있다.
List 하위 클래스에는 ArrayList, LinkedList, Vector이 존재한다.
ArrayList
ArrayList는 동적 배열이다.
일반 배열과 가장 큰 차이점으로 데이터를 순차적으로 저장 시, 더이상 저장할 공간이 없으면 보다 큰 배열을 새롭게 생성해 기존 배열의 저장된 내용을 새로운 배열로 복사해 저장한다.
즉, 크기가 고정 된 일반 배열에 비해, 저장 용량이 초과된 경우 자동적으로 용량이 늘어난다.
또한 인덱스를 가지고 있기 때문에 조회시 한번에 접근이 가능해 대용량 데이터를 여러번 참조해도 성능 문제가 발생하지 않는다.
단점으로는 동적 구조를 가지고 있기 때문에 중간에 데이터 삽입 시 기존 데이터가 뒤로 밀려나면서 계산이 발생해 성능 저하가 발생한다.
LinkedList
LinkedList는 인접 참조를 링크해서 체인처럼 관리한다.
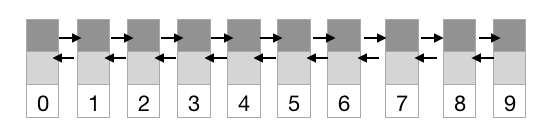
연결된 자료의 정보만 담고 있기 때문에 중간 노드에 접근해 데이터를 추가시켜도 전체 요소에 대한 연산이 필요없다.
즉, 추가/삭제가 빈번하게 일어나는 대용량 데이터 처리에 용의하다.
단점으로는 각 노드는 다음 노드에 대한 정보만을 보유하고 있기에 검색시 첫 노드부터 정보를 타고가면서 찾아야 하기 때문에 검색 성능이 좋지 않다.
Vector
ArrayList와 유사하게 동적 배열을 제공한다.
ArrayList와 차이가 있다면 Vector는 동기화가 되고, ArrayList는 동기화가 되지 않는다.
다른 말로는, Vector는 Thread-Safe하며 ArrayList는 Thread safe하지 않다.
Thread-Safe
Multi Thread 프로그래밍에서 여러 Thread로부터 어떤 method나, variable, object에
동시에 접근이 이뤄져도 프로그램의 실행에 문제가 없다는 의미다.
하나의 function이 한 Thread로 부터 호출되어 실행 중일 때, 다른 Thread가 동일한 함수를 호출하여 동시에 실행되더라도 각 Thread에서 함수의 수행 결과가 바르게 나오는 것!
Set
순서가 없는 데이터의 집합이며, 데이터 중복을 허용하지 않는다.
인덱스가 존재하지 않기 때문에 iterator(반복자)를 통해 접근해야한다.
중복을 방지하고 고유한 데이터만 저장해야하는 경우 사용된다.
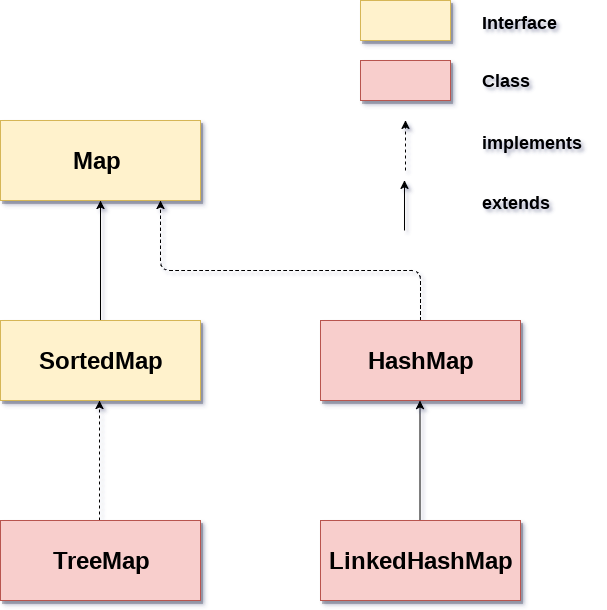
Map
키(key)와 값(value)로 구성된 객체를 저장해 관리한다.
키는 중복될 수 없으며, 만약 기존에 저장 된 키와 동일한 키로 값을 저장하면 기존 값은 대체된다.
Map의 주요 특징은 다음과 같다.
- 모든 데이터는 키와 값이 존재
- 키가 없이 값만 저장 불가능(반대의 경우도 불가능)
- Key는 Map에서 고유해야함
- 값은 중복되도 상관없음
- 순서를 신경쓰지 않음
Queue
선입선출(먼저 들어온게 먼저 나감)을 기본적으로 사용하며, 순서가 중요한 경우 사용한다.
Deque는 큐 데이터 구조의 변형으로 양방향 큐라고도 불리며, 양쪽 끝에서 요소를 추가하고 제거할 수 있는 구조다.
