이번 글에서는 HikariCP 연결을 설정하는 내용에 대해 작성하려고 합니다. 지난 글에서 이어진 내용으로 이전 글들을 보고 오시면 도움되실 것 같습니다.
1-1. 문제 확인
지난 글에서 알림 기능을 Spring Event, 비동기처리를 이용해 성능을 개선한 내용에 대해 얘기하였다.
그 결과 에러율이 0.1% 미만으로 내려갔고 TPS 또한 4배 이상 늘어났다.
하지만 아래 사진처럼 Connection Timeout Count가 여전히 발생하고 있었고 이는 그대로 에러로 직결된다.
특히 Timeout이 되기까지 시간동안 사용자는 응답을 받지 못한 채 기다리게 되고 이는 서비스에 악영향을 끼친다.
이를 개선하기 위해 아래 의문에 대해 답을 찾아가고자 한다.
- 여기서 생기는 의문
- Connection Size를 늘린다면 여러 쿼리를 한 번에 동작시킬 수 있지 않을까?
- Connection이 많다면 그만큼 메모리도 많이 먹게 되는 거 아닐까?
- 그렇다면 적절한 Connection Size는 무엇일까?
|
|---|
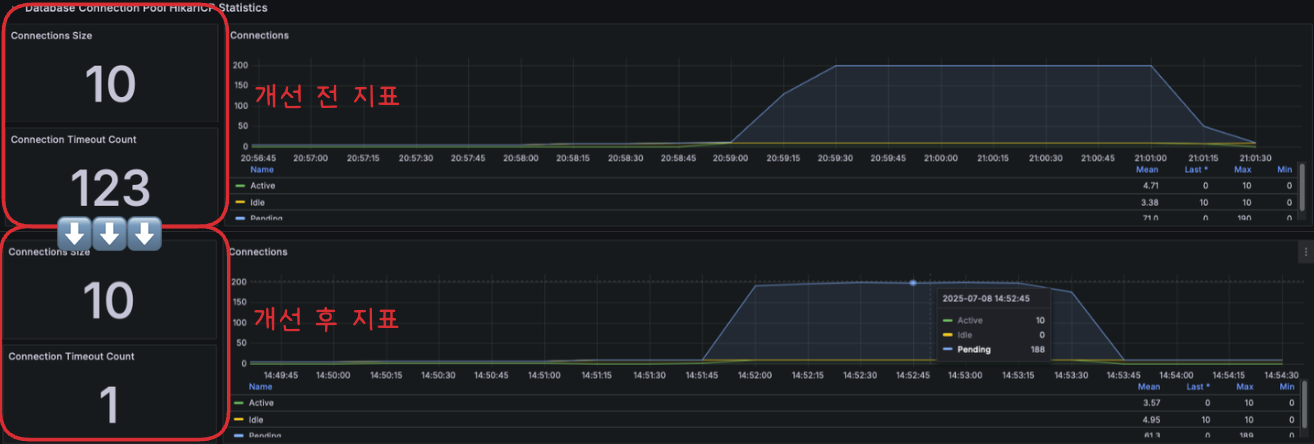 ⬆️ Connection Timeout Count 개선 전후 지표 (상단: 개선 전, 하단: 개선 후)
⬆️ Connection Timeout Count 개선 전후 지표 (상단: 개선 전, 하단: 개선 후) 1-2. 현재 설정 확인
현재 설정은 아래와 같다. 최소 5개 ~ 최대 10개 Connection을 가질 수 있고, 테스트 지표에서 볼 수 있듯 사용 가능한 10개의 커넥션을 소비하여 요청을 처리한다. 하지만 Connection Timeout이 발생하고 있고, 이를 위해 maximum-pool-size와 minimum-idle을 수정하고자 한다.
|
|---|
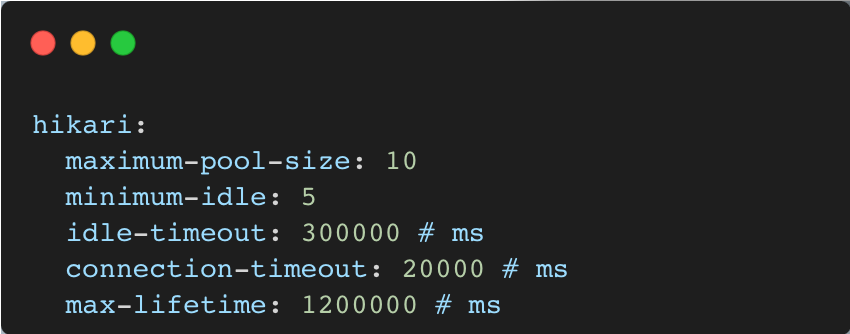 ⬆️ 현재 HikariCP 설정
⬆️ 현재 HikariCP 설정
- maximum-pool-size
- 최대 풀 크기를 설정하는 파라미터로 HikariCP가 동시에 유지할 수 있는 최대 데이터베이스 연결 수를 지정
- ⬆️ 값이 크다면, 동시 처리 가능한 요청 수가 증가하지만, 데이터베이스 서버 과부하 우려
- minimum-idle
- 최소 idle 연결 수를 설정하는 파라미터, 새로운 요청이 들어올 때 빠르게 연결을 제공하도록 함
- ⬆️ 값이 크다면, 트래픽이 적더라도 많은 idle 연결 수가 유지되어 자원 낭비 발생
- connection-timeout
- 연결 타임아웃을 설정하는 파라미터. 데이터베이스 연결을 위해 API 서버가 기다릴 최대 시간을 밀리초 단위로 설명
- 풀 고갈 상황에서 요청들이 빠르게 실패하고 예외 처리를 적절하게 대응 가능
- ⬇️ 값이 작다면, 일시적인 트래픽 급증 시 불필요한 타임아웃 발생
- ⬆️ 값이 크다면, 기다리는 시간동안 응답을 줄 수 없어 사용자 만족도 감소
- idle-timeout
- idle 상태의 타임아웃을 설정하는 상태
- connection timeout 설정과 유사
- max-lifetime
- 연결의 풀에서 유지될 수 있는 최대 수명을 설정
- 기본적으로 30분으로 설정. 오래된 연결을 폐기하고 새로운 연결 생성
- ⬇️ 값이 낮다면, 연결을 빈번하게 재성성하여 성능에 영향
1-3. 해결 방법 탐색
Connection을 많이 설정하면 커넥션 유지 비용, 동시 쿼리 실행 시 메모리 소비, 락 경합 등 문제가 발생할 것이다. 반대로 적게 설정한다면 많은 요청이 커넥션을 얻기를 기다리며 트래픽 급증하는 상황에서 timeout이 발생할 것이다.
그렇다면 적합한 Connection pool size는 어떻게 정해야할까?
아래는 참고한 문서입니다.
HikariCP GitHub페이지
HikariCP 문서 중 pool size에 관하여
|
|---|
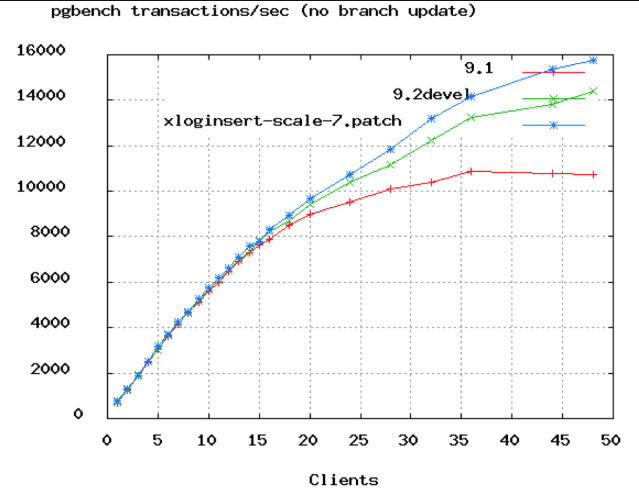
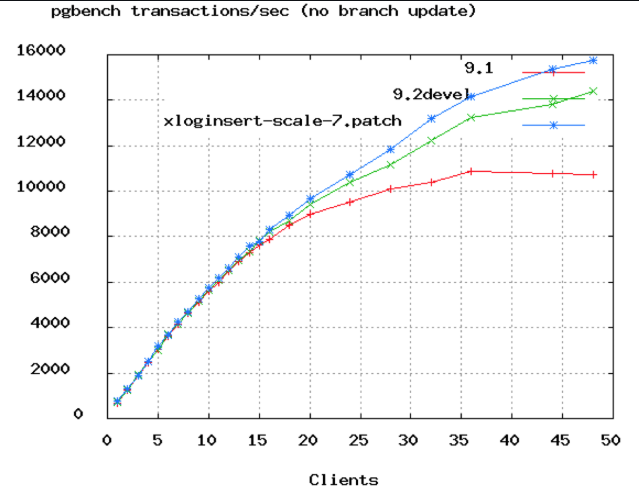 ⬆️ PostgreSQL 벤치마크
⬆️ PostgreSQL 벤치마크 위 사진은 PostgreSQL 벤치마크 그래프이다. x축은 연결의 갯수로, 약 50개 정도에서 TPS가 정체되는 것을 볼 수 있다. 또한 Oracle에서 DB 커넥션을 2048 ➡️ 96개로 줄여 100 ms ➡️ 2 ms로 개선한 사례가 있다.
- Connection Size를 무작정 늘리는 게 도움이 되지 않는 이유
CPU 코어가 1개인 컴퓨터는 여러 쓰레드를 동시에 실행하는 것처럼 보이더라도 실제로는 하나의 코어에서 한 번에 하나의 스레드만 실행할 수 있고 OS에서 context switching을 통해 다른 스레드의 코드를 실행하는 방식으로 동작한다. 이는 동시성과 병렬성의 차이이다.
따라서 스레드 수가 CPU 코어 수를 초과하면 context switching 때문에 스레드를 추가할수록 성능이 저하되는 것이다.- DB 관점에서 보면?
데이터는 일반적으로 디스크에 저장된다. HDD의 경우 헤드를 통해 데이터에 접근하며 헤드가 이동하고 조회하는 탐색 시간이 필요하다. 탐색 시간동안 해당 쓰레드는 block되고, block된 스레드를 제외하고 다른 스레드의 코드를 실행함으로 처리량을 늘릴 수 있다.
따라서 DB는 데이터를 찾는 I/O 대기 시간이 존재하고, 이 시간동안 스레드는 block되어 실제 코어 수보다 많은 연결 또는 스레드를 확보하면 더 많은 작업을 처리할 수 있다.
|
|---|
 ⬆️ 최적의 Connection Pool 공식
⬆️ 최적의 Connection Pool 공식 검증된 공식은 다음과 같다.
활성 커넥션 수 = ((CPU 코어 수 * 2) + 유효 스핀들 수)
이 때, 스핀들 수는 하드 디스크에서 데이터를 읽고 쓸 수 있는 경로의 수를 의미한다.
HDD의 경우 1, SDD의 경우 0으로 계산하면 된다.
- 예시
- 4 코어 i7 CPU와 HDD
- CPU 코어 수(4개) x 2 + 1 = 9
- 따라서 9개가 최적
- 4 코어 i7 CPU와 SDD
- CPU 코어 수(4개) x 2 + 0 = 8
- 따라서 8개가 최적
1-4. 지표 확인
Connection Pool size를 다르게 하여 기존 설정 10개, 증가한 경우 20개, 감소한 경우 8개, 최적의 경우 4개를 비교할 예정이다.
- 테스트 환경
- 테스트 connection Pool size: 4개(최적), 8개(감소), 20개(증가)
- 시나리오: 지난 포스팅 시나리오와 동일
- 가상 유저: 최소 120명 ~ 최대 200명
- 0 ~ 1 min: 초당 50번 요청
- 1 ~ 2 min: 초당 100번 요청
- 2 ~ 3 min: 초당 0번 요청 (기존 들어온 요청 처리)
- 확인할 지표: TPS, Connection Timeout Count
⬇️ Connection Pool Size 4개 지표
|
|---|
 ⬆️ Connection Pool Size 4개 [Connection Timeout Count]
⬆️ Connection Pool Size 4개 [Connection Timeout Count]
|
|---|
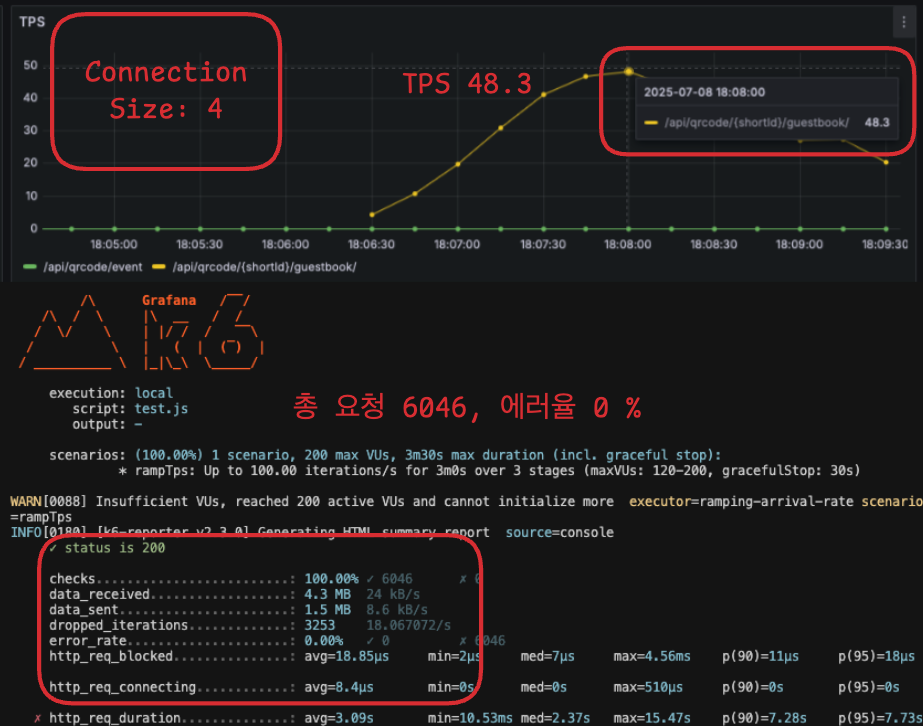 ⬆️ Connection Pool Size 4개 [TPS, 총 요청 횟수 및 에러율]
⬆️ Connection Pool Size 4개 [TPS, 총 요청 횟수 및 에러율] ⬇️ Connection Pool Size 8개 지표
|
|---|
 ⬆️ Connection Pool Size 8개 [Connection Timeout Count]
⬆️ Connection Pool Size 8개 [Connection Timeout Count]
|
|---|
 ⬆️ Connection Pool Size 8개 [TPS, 총 요청 횟수 및 에러율]
⬆️ Connection Pool Size 8개 [TPS, 총 요청 횟수 및 에러율] ⬇️ Connection Pool Size 20개 지표
|
|---|
 ⬆️ Connection Pool Size 20개 [Connection Timeout Count]
⬆️ Connection Pool Size 20개 [Connection Timeout Count]
|
|---|
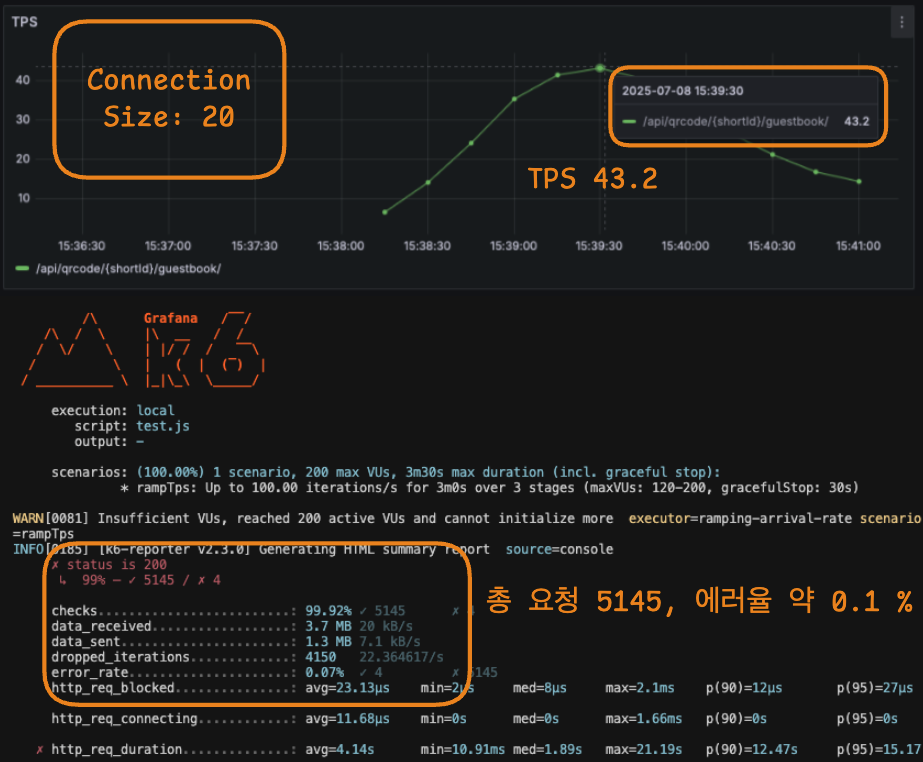 ⬆️ Connection Pool Size 20개 [TPS, 총 요청 횟수 및 에러율]
⬆️ Connection Pool Size 20개 [TPS, 총 요청 횟수 및 에러율] 1-5. 성능 지표 비교
Hikari maximum-pool-size를 10 ➡️ 4 로 변경하여
기존 TPS 42, 에러율 0.1 % ➡️ TPS 48, 에러율 0 %로 개선하였다.
| 연결 갯수/지표 | TPS | 연결 시간 초과 횟수 | 총 요청 횟수 | 에러율 |
|---|---|---|---|---|
| 4개 (최적) | 48.3 | 0 번 | 6 046 번 | 0 % |
| 8개 (감소) | 46.3 | 0 번 | 5 775 번 | 0 % |
| 10개 (기존) | 42.6 | 1 번 | 5 521 번 | ≈ 0.1 % |
| 20개 (증가) | 43.2 | 4 번 | 5 145 번 | ≈ 0.1 % |
