오늘은 데이터베이스 분리하는 과정을 공유하려고 합니다. 왜 분리하게 되었는지, 어떤 방식으로 분리하였는지에 대해 작성한 글입니다.
1-1. 문제 확인
이전 포스팅에서 데이터베이스 HikariCP에 대해서 최적화를 진행하였다. 이 과정에서 의문이 생겼다.
등록하는 과정에서 Connection을 모두 가져가면, 해당 시간대에 들어온 다른 작업은 느려지는 게 아닐까?
느려질 것이다.
기본적으로 많은 요청이 들어오기 때문에 트래픽이 몰리면 당연히 느려지는 게 된다.
하지만 전체 서비스의 규모가 커져서 평균 트래픽이 몰리는 게 아닌, 특정 기능 때문에 1-2분 가량 짧은 시간만 트래픽이 몰리는 상황이다.
따라서 등록을 시도하는 1-2분동안 다른 서비스 기능들에 지장이 가지 않도록 이 문제를 해결하고자 한다.
트래픽을 분리하거나, 방법에는 어떤 것들이 있을까?
- 샤딩
- 레플리케이션
- 샤딩
- 애플리케이션 레벨에서 Key를 기준으로 여러 개의 독립적인 데이터베이스로 분할. 각 데이터베이스는 독립적인 데이터를 가지게 된다.
- 장점: Scale out에 용이하며, 각 샤드에 부하 분산을 할 수 있다.
- 단점: 트랜잭션, 조인 처리가 복잡하며 Key를 관리가 복잡하다.
- 레플리케이션
- Master-Slave 구조로 마스터 데이터베이스의 데이터를 슬레이브 데이터베이스에 복사하는 방식으로 데이터베이스를 분리한다. 각 데이터베이스의 데이터는 동기화된다.
- 장점: 마스터 데이터베이스 장애 시 슬레이브 데이터베이스를 마스터로 승격해 장애 대응을 할 수 있다. 슬레이브 데이터베이스는 Scale out에 용이하다.
- 단점: 마스터 데이터베이스에 병목이 발생할 수 있다. 동기화 시간동안 복제 지연이 발생할 수 있다.
1-2. 해결 방법 결정
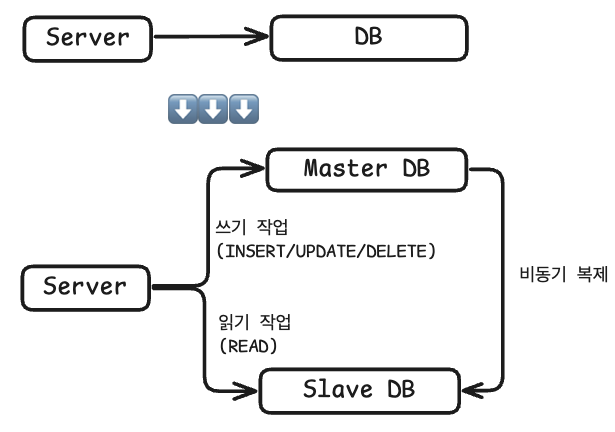
위 3가지 방법 중 2번 방법인 레플리케이션을 선택하였고,
Master-Slave구조를 사용하여 Master는 쓰기 작업(Insert/Update/Delete)을 담당하고 Slave는 읽기(Read)를 담당하도록 결정하였다.
선택의 근거는 다음과 같다.
- 샤딩을 선택하지 않은 이유
- 데이터 중 Key를 맡을만한 기준이 없다. 예를 들어 인스타그램은 특정 유명인들에 대해서 트래픽이 몰리게 되어 샤딩을 통해 트래픽을 분산한다고 알고 있다.
특정 키값에 대해 트래픽이 몰릴 것으로 예상되거나, 데이터 특성 중 논리적으로 나눌 수 있는 값이 있다면 좋았겠지만, 현재 프로젝트 구조에는 적합하게 나눌 기준이 없었다.
또한 현재 등록하는 과정에서 커넥션이 없어지는 경우를 문제 상황으로 생각하고 있어, 샤딩을 하더라도 트래픽이 하나의 데이터베이스로 몰리게 되어 같은 문제가 발생할 거라고 생각했다.- 레플리케이션을 선택한 이유
- 걱정하는 문제는 방명록 등록하는 시점에 다른 기능에 대한 요청들의 타임아웃 또는 커넥션풀 고갈이고, 이를 해결하기 위해서는 각자 다른 데이터베이스로 트래픽을 분리하면 좋다고 생각했다.
아예 방명록 등록하는 과정 자체만 다른 데이터베이스로 분리할 수도 있겠지만, 현재 프로젝트 규모와 맞지 않다고 생각했고, 전체적인 성능을 높일 수 있는 방법인 레플리케이션을 사용한 읽기 데이터베이스와 쓰기 데이터베이스를 분리하도록 결정하였다.
Postgres Replication 복제 방법 2가지
1. 동기 복제
2. 비동기 복제 (선택 ✅)
- 동기 복제
- 트랜잭션 커밋 시 슬레이브(리플리카)의 ACK 응답을 기다린다.
- 장점: 마스터와 완전 일치를 보장한다.
- 단점: ACK 응답 대기 때문에 쓰기 작업 지연이 발생한다.
- 비동기 복제 (선택 ✅)
- 마스터가 변경 사항(WAL, Write-Ahead Log)을 전송만 하고, ACK 응답을 기다리지 않는다.
- 장점: ACK 응답 대기 없어 쓰기 작업 지연이 발생하지 않는다.
- 단점: 동기화가 완벽하지 않고, 장애 시 슬레이브 승격할 땐 데이터 유실 위험이 있다.
- 비동기 복제를 선택한 이유
- 돈처럼 민감한 정보가 아니기에 약간의 시간적 오차를 허용할 수 있고, 쓰기 작업 성능이 중요한 작업이다.
- 장애 발생 시 서버 로그와 문자 알림 기록 등을 보고, 등록에 성공한 사람들을 추적할 수 있어 슬레이브에서 데이터 유실이 발생하더라도 이전 사건을 추적할 수 있는 수단들이 있다.
1-3. 코드 개선
- DatabaseConfig.java를 작성하여 master DB와 slave DB 정보를 연결합니다.
- DataSource Bean을 등록하여 LazyConnectionDataSourceProxy로 래핑된 DataSource를 반환합니다.
- 실제 쿼리 시점에 트랜잭션 타입에 따라 DataSource를 선택하여 커넥션을 획득합니다.
- LazyConnectionDataSourceProxy를 사용하지 않는다면?
아래처럼 트랜잭션을 시작하기 전에 커넥션을 얻는다면, 트랜잭션 타입을 제대로 알 수 없어 의도된 데이터베이스로 쿼리를 보낼 수 없다.
- 사용 X: 트랜잭션 시작 전에 DataSource 선택
메서드 호출 → DataSource 선택 → 커넥션 획득 → 트랜잭션 시작 → 메서드 실행- 사용 O: 트랜잭션 시작 후에 DataSource 선택
메서드 호출 → ProxyDataSource 생성 → 트랜잭션 시작 → 메서드 실행 → 실제 SQL 실행 → DataSource 선택 → 커넥션 획득
|
|---|
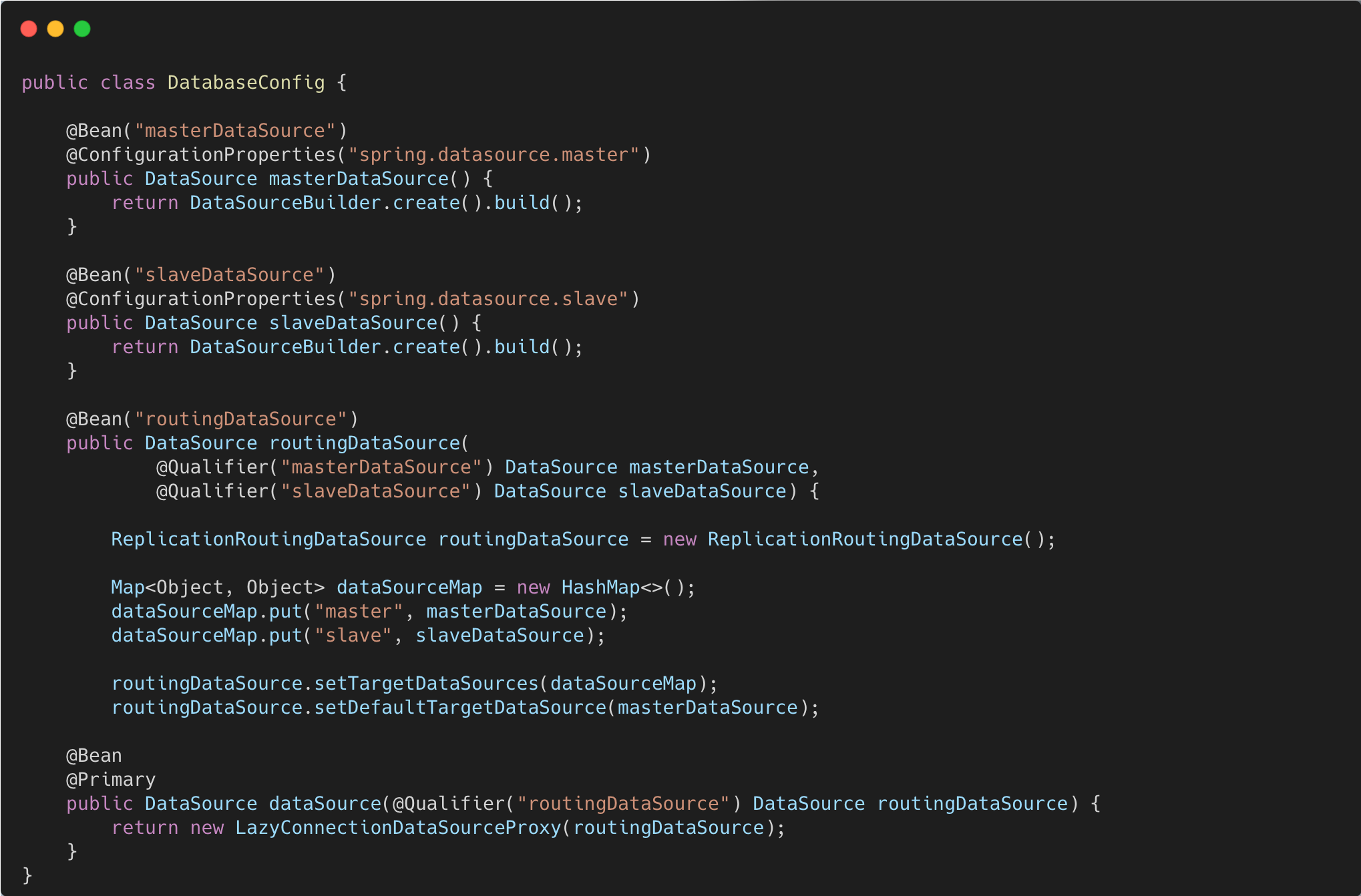 ⬆️ DatabaseConfig.java
⬆️ DatabaseConfig.java
|
|---|
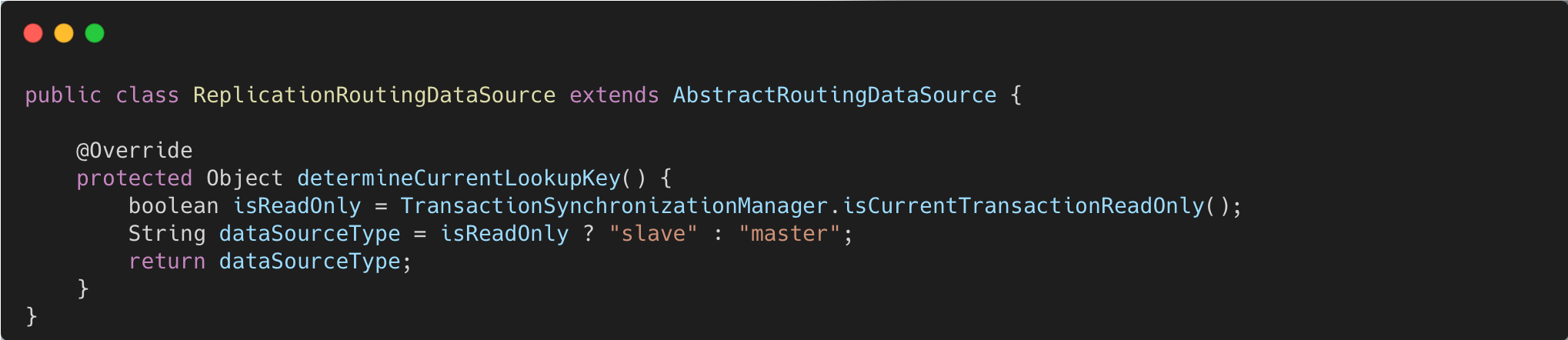 ⬆️ ReplicationRoutingDataSource.java
⬆️ ReplicationRoutingDataSource.java
|
|---|
 ⬆️ @Transactional(readonly=true) 메서드 실행 로그
⬆️ @Transactional(readonly=true) 메서드 실행 로그 2-1. 파티셔닝 추가
서비스에서는 Short_id로 Event를 검색하고 있다. Short_id는 사용자에게 보여주고, 식별 가능하도록 숫자와 영어를 섞어 최대 12글자까지로 정하였다.
하지만 32글자인 uuid(8-4-4-4-12)와는 다르게 12글자인 Short_id은 중복이 발생할 수도 있다.
물론 이를 대비해 Event 생성 시점에 Short_id를 발급받고, 이미 쓰여진 Short_id인 경우 재발급하는 retry 로직을 추가해뒀다. 하지만 대부분의 Short_id가 사용 중인 경우 retry로직도 실패할 것이다.
이 경우를 대비하여 파티셔닝을 추가하기로 했다. 성능적 이점도 파티셔닝 도입 이유 중 하나이다.
- 파티셔닝(partitioning)
- 개념
- 하나의 테이블을 논리적인 부모 테이블과 실제 데이터를 담는 자식 테이블로 나누는 구조
- 서버에서 쿼리 사용 시 부모 테이블을 사용하고, 실제 쿼리는 자식 테이블에서 동작
- 파티션 키(partition key) 기준으로 자식 테이블을 분리
- RANGE(범위 기준), LIST(목록 기준), HASH(해시값 기준), COMPOSITE(복합키 기준)
- 장점
- 쿼리 WHERE 절에 파티션 키를 사용하면, 해당 파티션만 스캔
- 특정 파티션만 통째로 DROP 가능, 대량 DELETE 불필요
- 파티션별로 VACCUM 사용 가능
- 단점
- 설계, 운영 복잡
- 인덱스 중복으로 공간 차지
