이번 글은 검색 기능 개선을 다룬 글입니다. 다른 사람이 만든 이벤트는 무엇이 있는지 볼 수 있도록 서비스에 검색 기능을 도입하였고, 이에 대해 테스트하던 중 발견한 문제입니다.
1-1. 문제 발생 확인
다음주부터 실사용을 위해 시나리오별 테스트를 진행하던 중 "검색(Search)"부분에서 쿼리 속도가 현저히 느리다는 것을 발견하였다. 현재 검색 기능은 전체 QrcodeEvent 중 LIKE문을 활용해 검색어와 제목이 일치하는 모든 것을 받아온다. 제목으로 매칭되는 것이 한 가지인 경우 아래 사진과 같이 3.3초가 걸렸다.
매칭되는 것이 많아질수록 더욱 오랜 시간이 걸릴 것이다.
(오고 가는 데이터가 많아지니까 당연히 네트워크 비용이 더 커지기에) 따라서 최소 3초 이상 걸리는 해당 쿼리를 변경해야만 한다.
|
|---|
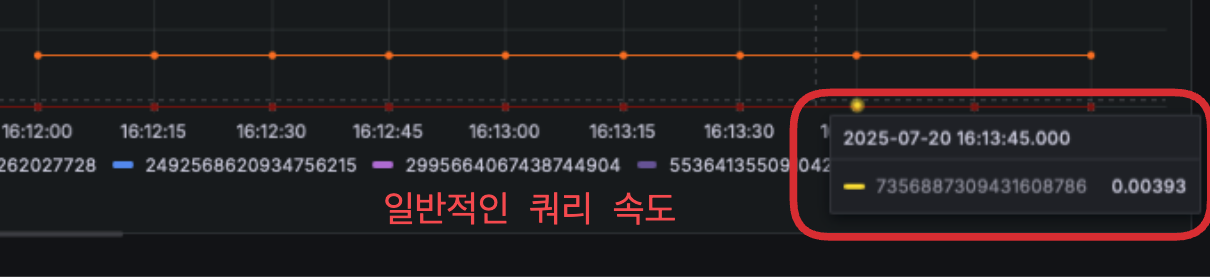 ⬆️ 일반적인 쿼리 속도: 1초 미만
⬆️ 일반적인 쿼리 속도: 1초 미만
|
|---|
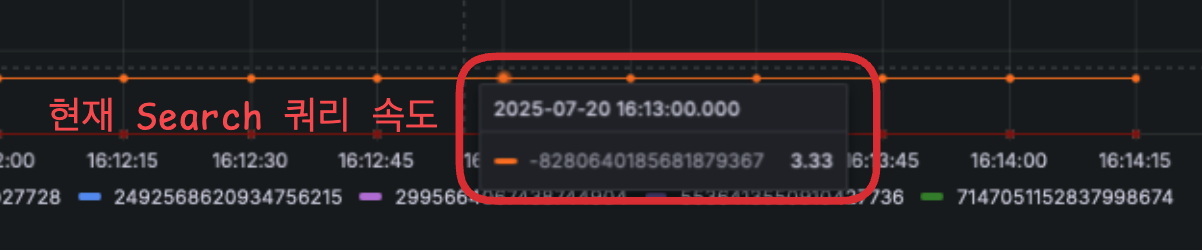 ⬆️ 현재 Search 쿼리 속도: 3.3초
⬆️ 현재 Search 쿼리 속도: 3.3초 1-2. 문제 원인 분석
현재 쿼리는 아래와 같다.
- 문제
- EXPLAIN ANALYZE 사용하여 쿼리 실행 계획을 살펴본 결과 LIKE문을 실행하는 과정에서 Parallel Seq Scan 발생을 확인 ➡️ "%title%" 이런 식으로 쓰기에 title_index를 사용할 수 없음
- 인덱스를 탈 수 없는 이유는 접두사에 "%"를 사용하였기 때문이다.
B+Tree 인덱스는 문자열을 정렬된 상태로 유지할텐데 "%(= 와일드카드)" 를 사용하게 된다면, 어느 위치에 키워드가 있을지를 전혀 에측할 수 없어 정렬 순서를 타고 건너뛰는 게 불가능.- "title은 모두 인덱스에 있으니까 거기서 훑고 데이터 테이블에 접근해서 정보를 가져오면 안될까?"라는 생각은 해봤지만, [인덱스 전체 스캔 + 테이블 접근] vs [테이블 전체 검색]을 비교해보면 굳이 인덱스를 모두 스캔하고 테이블을 접근할 이유가 없기 때문인 것 같다.
- 여러 워커를 사용해 모든 데이터를 훑기 때문에 오래 걸릴 수 밖에 없는 구조 (현재 데이터 200만건)
- postgreSQL 데이터 접근 방식
- Sequential Scan
- 테이블 전체를 순차 읽기
- Parallel Sequential Scan
- 여러 워커로 테이블을 분할하여 Seq Scan
- 여러 워커를 사용해 병렬로 진행하여 Seq Scan보다는 빠르나, 모든 데이터를 읽는 것은 동일
- Bitmap Index Scan
- 여러 인덱스를 사용하여 검색
- Index Scan
- 인덱스를 사용하여 필요한 행에 대해 테이블에서 데이터 검색
- Index Only Scan
- 인덱스만을 사용하여 테이블에 접근하지 않고, 데이터 검색
- Sequential Scan
|
|---|
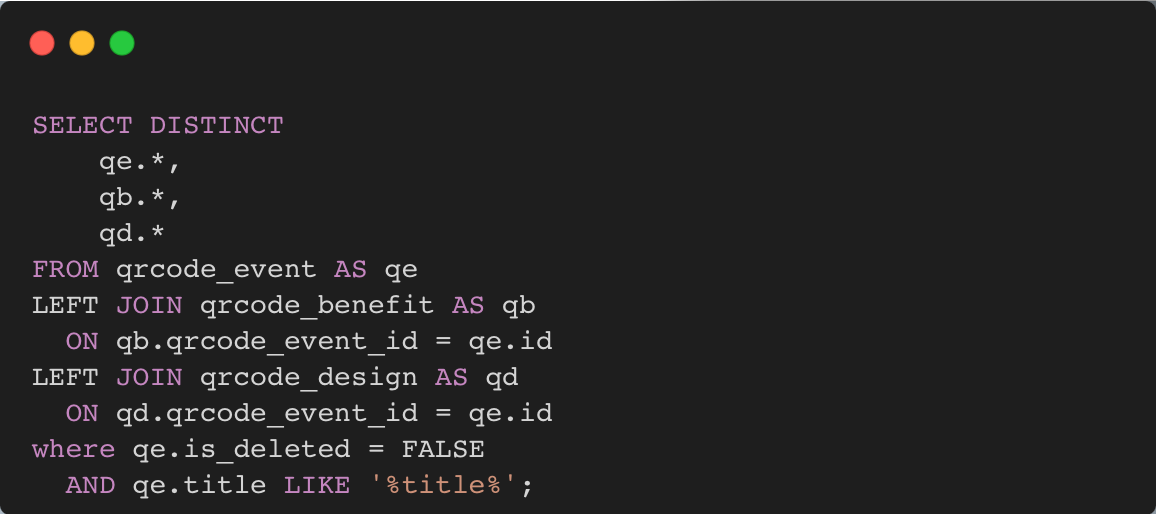 ⬆️ 현재 Search 쿼리
⬆️ 현재 Search 쿼리
|
|---|
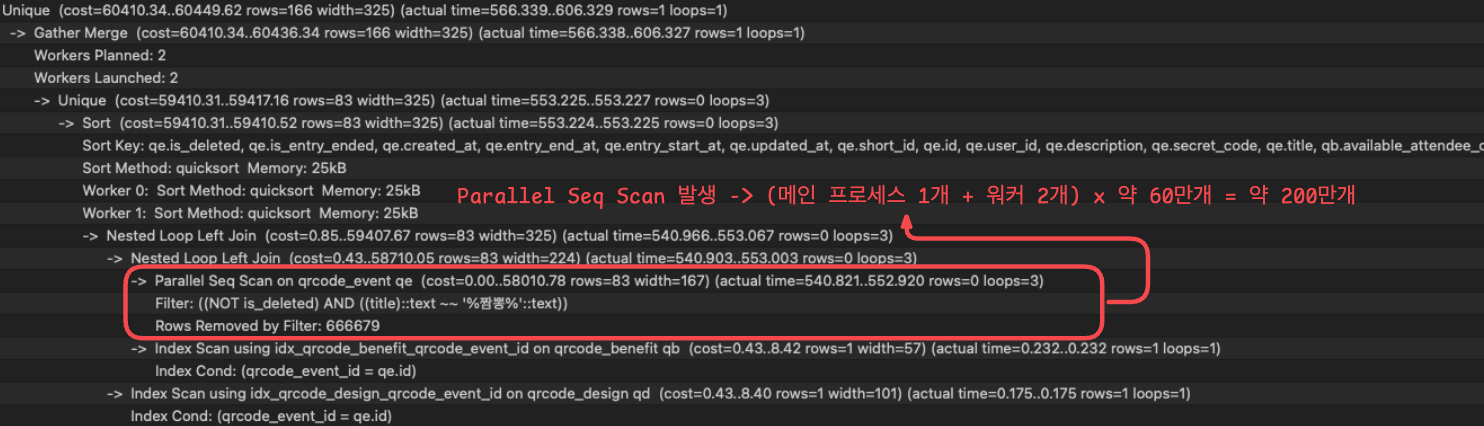 ⬆️ 현재 Search 쿼리 실행 계획 - Parallel Seq Scan 발생
⬆️ 현재 Search 쿼리 실행 계획 - Parallel Seq Scan 발생 1-3. 해결 방법 탐색
현재 LIKE문을 사용해 검색하는 것은 성능상 한계가 있다는 것을 알게 되었다. 이걸 어떻게 바꿔야할까
- 외부 검색엔진 도입 (Elasticsearch/ OpenSearch)
- 장점: 오타, 어간, 유사도 등등 여러 측면에서 검색 결과에 대해 더욱 정확하고 적합한 결과를 낼 수 있다.
- 단점: 리소스(돈, 서버)가 많이 필요하고, 학습적인 측면과 추후 관리 측면에서 현재 프로젝트와 적합하지 않다고 생각한다.
- 현재 프로젝트는 네이버, 구글과 달리 검색 엔진이 주요한 기능이 아니기에 선택하지 않았다.
- 접두사에 와일드카드 삭제(%title% ➡️ title%)
- 장점: 검색 키워드의 맨 앞이 고정이기에 정렬된 상태로 유지되는 인덱스를 탈 수 있다.
- 단점: 검색하고자 하는 이벤트 제목의 맨 앞부터 입력해야 올바른 결과가 나오게 된다.
예를 들어, "매운 짬뽕 맛있다"라는 이벤트를 찾기 위해서는 "매운 짬뽕"을 검색해야 올바른 검색 결과가 나올 것이다. 반면 "짬뽕"을 검색하게 된다면 이는 검색되지 않을 것이다.- 이는 사용자 경험에 악영향을 끼칠 수 있기에 선택하지 않았다.
- Full-Text Search(FTS) 기반 검색
- 문자열을 띄어쓰기 단위로 토큰화하여 GIN과 함께 사용하여 검색을 진행한다.
- 장점: rank(순위)를 계산할 수 있다. 단, 유사도가 아닌 문서 내 빈도 수, 총 문서 중 차지하는 비율 등으로 계산되는 순위이다.
- 단점: 오타, 부분 일치 등을 잡을 수 없다.
- pg_trgm(Trigram) 기반 검색
- 문자열을 3글자(3-gram) 단위로 분해하여 검색을 진행한다.
- 장점: 유사도 검색이 가능하고, 오타가 있더라도 검색이 가능하다.
- 단점: 문자열을 3글자씩 나누다보니 인덱스 크기가 커진다. 또한 3글자씩 나눠 인덱스에 저장하기 때문에 쓰기 비용이 증가한다.
- 3-gram 단위로 문자열을 나누다보니 일부 오타가 있더라도, 나머지 글자가 매칭이 되어 검색 결과에 포함되도록 할 수 있다. 지원하는 기능이 다양하지만, PGroonga보다 성능이 확연하게 좋지 못해 선택하지 않았다.
- ✅ PGroonga (Groonga엔진 사용 검색)
- PostgreSQL 위에 Groonga 검색 엔진을 통합한 확장 모듈로, 성능이 매우 좋다는 특징이 있다.
또한 편집 거리를 통한 fuzzy search(퍼지 검색)을 지원하며 오픈소스라는 특징이 있다.- 장점: 고성능, 다양한 언어 지원, fuzzy search 가능, ("&@*") 이용한
- 단점: 매우 큰 크기, 일부 기능은 pgroonga_command와 같은 별도 API 사용
- pg_trgm과 비슷하게 PGroonga도 n-gram 기반 유사도 검색을 지원하기에 선택하였다. 비슷한 기능을 지원하기 때문에 성능이 더 높은 쪽을 선택하였다. 하지만 PGroonga는 성능이 좋은 대신 공간을 많이 잡아먹는 Trade-off 관계에 있다.
1-4. 해결 과정
1️⃣ title과 description을 검색 대상으로 하기 묶기 위해 Generated Column 사용
- OR 조건으로 검색한다면 인덱스를 두 번 스캔해야 되기 때문에 둘을 합쳐 하나의 컬럼으로 생성
- Trigger를 사용하지 않는 이유는 업데이트 일관성 때문이다. 의도하지 않은 작동이 발생할 수 있고, 여러 설정이 추가된다면 트리거 자체가 복잡해지기에 사용하지 않았다.
- 함수팩 설치, 테이블 스키마 동기화 등을 위해 Flyway를 사용하여 버전 관리, 스키마 동기화하였다.
- Flyway를 사용해 PGroonga 모듈 설치, Generated Column 설정, search_text 인덱스 생성을 적용
|
|---|
 ⬆️ Generated Column 쿼리
⬆️ Generated Column 쿼리
|
|---|
 ⬆️ PGroonga 인덱스 생성 쿼리
⬆️ PGroonga 인덱스 생성 쿼리 2️⃣ WAL Resource Manager 사용하여 SlaveDB에 변경사항 전파
- PostgreSQL 기본 WAL(Write-Ahead Log)은 DDL을 기록해 slave에게 전파
- PGroonga 인덱스는 Groonga 엔진 내부에서 생성되어 기본 WAL 로그는 전파 불가능
- PGroonga에서 제공하는 WAL Resource Manager 모듈을 추가하여 slaveDB에게 전파
- 이를 스크립트로 작성하여 데이터베이스 시작 시 활성화하도록 설정
|
|---|
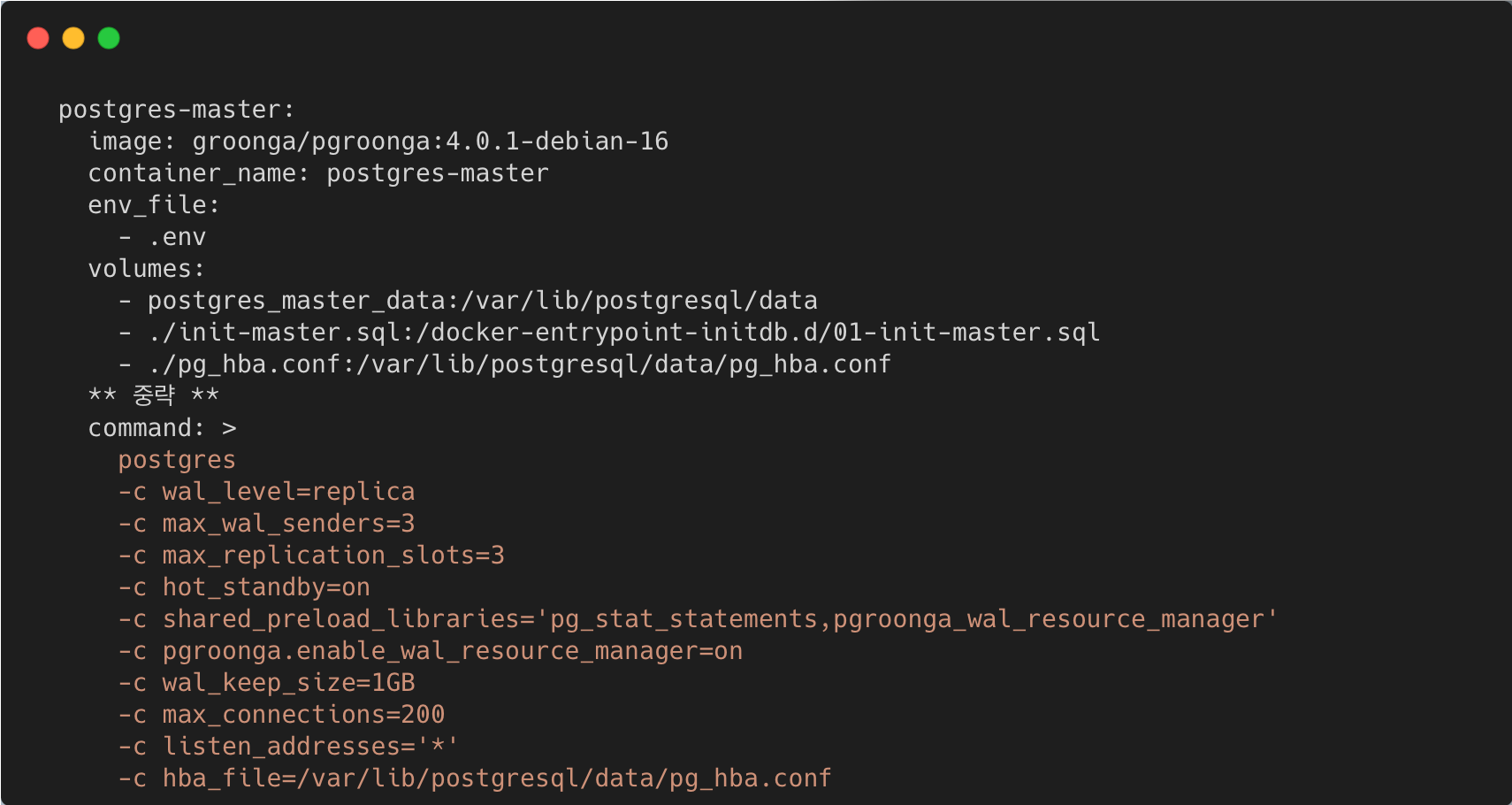 ⬆️ MasterDB 설정
⬆️ MasterDB 설정 3️⃣ PGroonga의 fuzzy_search()를 사용
- 역색인 기반 인덱스 사용
- fuzzy_search()는 편집 거리를 설정 가능하여 오타가 있더라도 수용 가능
- 짧은 단체명, 이벤트명으로 검색할 가능성이 높다고 판단
- 오타가 있을 때 n-gram을 쓰는 ("&@*")보다 원하는 검색 결과를 얻을 수 있을 것이라 판단
- 아래처럼 "정수환"이 원본 데이터인 경우 "정주환"으로 검색한다면 fuzzy_search()만 올바르게 검색 가능
|
|---|
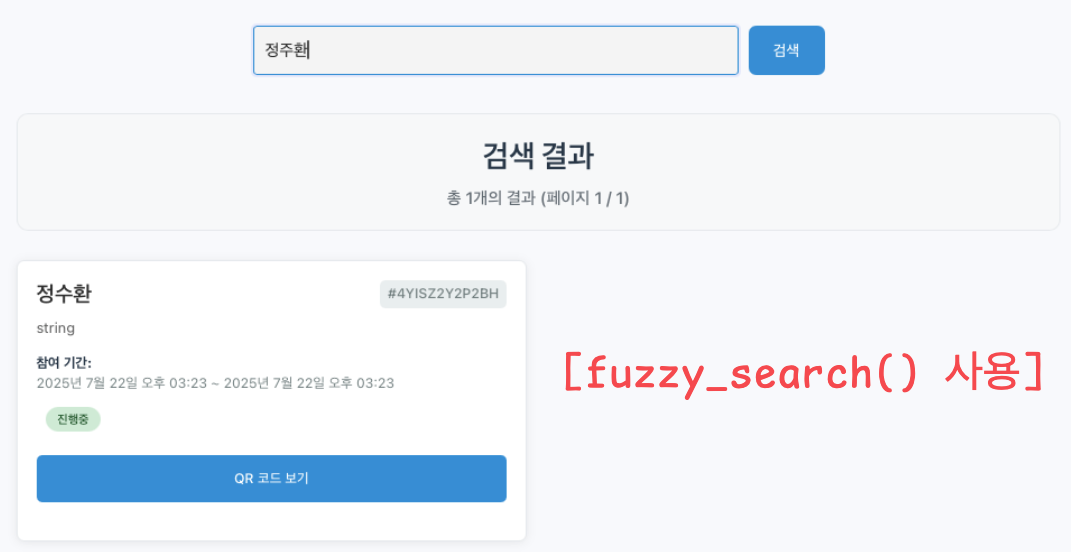 ⬆️ fuzzy_search() - "정주환" 검색 결과 ✅
⬆️ fuzzy_search() - "정주환" 검색 결과 ✅
|
|---|
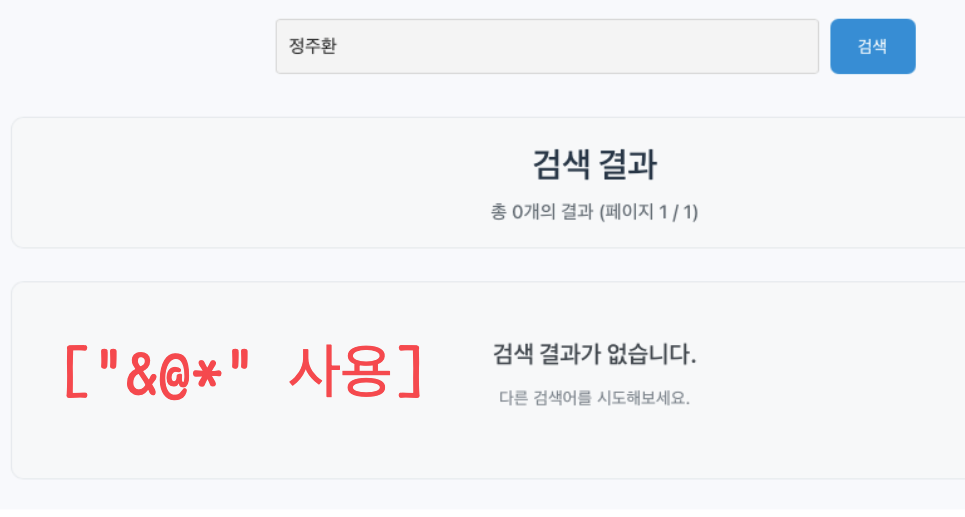 ⬆️ "&@*" - "정주환" 검색 결과 ❌
⬆️ "&@*" - "정주환" 검색 결과 ❌ 1-5. 지표 확인
- 테스트 시나리오: 기존 LIKE문 때와 동일
- 테스트 횟수: 10번
- 테스트 단위: 10번 쿼리의 평균 ms 단위
- 결과: LIKE문: 3,300ms(3.3초) ➡️ PGroonga fuzzy_search(): 632ms
- 쿼리 변화: Parallel Sequential Scan ➡️ Bitmap Index Scan + Bitmap Heap Scan
- Bitmap Index Scan
- Index를 이용하여 1차 필터링을 진행
- 필터링 후 후보가 된 데이터 위치(TID)를 Bitmap(페이지 단위)으로 표시
- Bitmap Heap Scan
- 만들어진 Bitmap에서 필요한 페이지를 순차적으로 조회
|
|---|
 ⬆️ PGroonga fuzzy_search(): 632ms
⬆️ PGroonga fuzzy_search(): 632ms
|
|---|
 ⬆️ 쿼리 실행 계획 변화: Bitmap Index Scan + Bitmap Heap Scan
⬆️ 쿼리 실행 계획 변화: Bitmap Index Scan + Bitmap Heap Scan 