
VM에서 컨테이너로: 왜 전환이 필요했는가?
가상 머신(VM)은 물리 서버를 여러 개의 독립된 서버처럼 사용할 수 있게 해주는 혁신이었다. 물리 서버 한 대에 여러 VM을 올려 자원을 효율적으로 쓸 수 있었고, 클라우드 인프라의 기반이 되었다.
하지만 VM에는 구조적인 한계가 있었다. VM은 OS 전체를 가상화한다. 즉, 앱 하나를 실행하기 위해 수 GB의 OS 이미지를 올려야 한다. 부팅에만 수십 초~수 분이 걸리고, 물리 서버 한 대에 4~6개 VM을 올리는 것이 한계였다. 무엇보다 "환경 구축에 하루 이상"이 걸리는 구조적 불편함이 있었다.
컨테이너는 이 문제를 다른 관점에서 해결했다. OS 전체를 가상화하는 대신, Linux 커널의 namespace와 cgroup 기능을 이용해 프로세스 수준에서만 격리한다. OS는 Host와 공유하고, 앱과 그 실행에 필요한 bin/lib만 패키징한다. 결과적으로 컨테이너 이미지는 수십 MB~수백 MB로 가볍고, 시작은 수 초 안에 가능하며, 물리 서버 한 대에 20~30개까지 올릴 수 있다.
VM vs Container: 핵심 차이 비교
| 항목 | VM | 컨테이너 |
|---|---|---|
| 가상화 방식 | Hypervisor가 서버 전체 가상화 | namespace로 프로세스 수준 격리 |
| 이미지 크기 | OS 포함, 수 GB | 앱 + bin/lib만, 수십~수백 MB |
| 부팅 시간 | 수십 초 ~ 수 분 | 수 초 ~ 수십 초 |
| 집적도 | 물리 서버당 4~6 VM | 물리 서버당 20~30 컨테이너 |
| 베어메탈 대비 성능 | 50~80% | 98% |
| 앱 확장성 | Low (수작업 많음) | High (완전 자동화 가능) |
| 플랫폼 이식성 | 동일 Hypervisor 간 | 이기종 물리/가상/클라우드 모두 |
| OS Cost | VM 당 | Host 당 |
컨테이너의 4가지 핵심 특성을 한 단어로 요약하면: 이식성(Portability), 경량성(Size), 속도(Speed), 호환성(Compatibility)이다.
Dockerfile: 컨테이너 이미지 설계도
컨테이너 이미지는 Dockerfile이라는 선언적 명세로 만든다. Dockerfile은 "이 이미지가 무엇으로 구성되어야 하는지"를 레이어(Layer) 단위로 기술한다.
FROM python:3.10-alpine # 베이스 이미지: Python 3.10이 설치된 Alpine Linux
RUN apk add --no-cache bash curl gcc musl-dev linux-headers jq # 시스템 패키지 설치
RUN pip install fastapi uvicorn psutil python-multipart prometheus-client # Python 패키지 설치
COPY fastserver.py fastserver.py # 앱 코드 복사
CMD ["python3", "fastserver.py"] # 컨테이너 시작 시 실행할 명령각 명령(FROM, RUN, COPY)은 하나의 이미지 레이어가 된다. 레이어는 불변(Immutable)이며, 상위 레이어에서 변경이 생기면 해당 레이어부터 다시 빌드한다. 이 덕분에 변경이 없는 레이어는 캐시를 재사용해 빌드 속도가 빠르다.
컨테이너의 핵심 기반 기술
컨테이너가 "그냥 격리된 프로세스"라고 말할 수 있는 이유는, Linux 커널이 제공하는 두 가지 핵심 기술 덕분이다.
Namespace: 프로세스 격리
Namespace는 각 컨테이너가 자신만의 독립된 세계를 가질 수 있게 한다. 각 컨테이너는 자신이 시스템 전체를 독차지하고 있는 것처럼 동작한다.
| Namespace | 격리 대상 |
|---|---|
| PID | 프로세스 테이블. 컨테이너 내부의 PID 1은 호스트의 실제 PID와 다름 |
| Network | 네트워크 인터페이스, IP, 포트, 라우팅 테이블 |
| UID/GID | 사용자/그룹 ID. 컨테이너 안의 root가 호스트의 root와 다를 수 있음 |
| Mount | 파일 시스템 트리. 컨테이너마다 독립된 rootfs |
| UTS | 호스트명과 도메인명 |
| IPC | 공유 메모리, 세마포어 등 프로세스 간 통신 자원 |
cgroup: 자원 제한
Namespace가 "무엇을 볼 수 있느냐"를 결정한다면, cgroup은 "얼마나 쓸 수 있느냐"를 제한한다.
| 항목 | 기능 |
|---|---|
| cpu | CPU 사용량 제한 |
| memory | 메모리와 swap 사용량 제한 |
| cpuset | 특정 CPU 코어와 메모리 노드 배치 제어 |
| blkio | 블록 디바이스 입출력량 제어 |
| devices | 디바이스 접근 허가 및 제한 |
| pids | 프로세스 개수 제한 |
💡 Callout: OOM Killer 동작 과정
컨테이너에서 메모리 Limit을 초과하면 다음 순서로 처리된다:
- cgroup에서
memory.limit_in_bytes = 512MiB설정- 컨테이너 내 프로세스가 700MiB 사용 → limit 초과 감지
- Linux 커널의 OOM(Out-of-Memory) Killer 동작 → 가장 많은 메모리를 사용하는 프로세스를 강제 종료
- containerd-shim이 PID 1(init process) 종료 감지 → containerd에 컨테이너 종료 상태 알림
- containerd가 컨테이너 상태를 갱신, Kubernetes는 이를 감지해 Pod 재시작
Kubernetes의
resources.limits.memory설정이 바로 이 cgroup 값으로 적용된다. 컨테이너가 갑자기 재시작된다면 OOMKilled 상태 여부를 먼저 확인해야 한다.
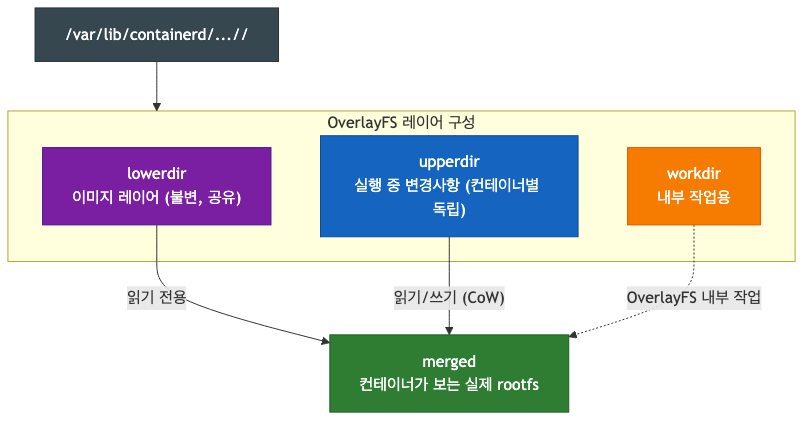
OverlayFS: 컨테이너 이미지 관리의 비밀
Docker 이미지가 레이어 구조를 가질 수 있는 이유는 OverlayFS 덕분이다. OverlayFS는 두 개 이상의 디렉토리를 겹쳐서 하나의 파일 시스템처럼 보이게 하는 Linux의 union mount 파일 시스템이다.
컨테이너 파일 시스템은 다음 4개의 디렉토리로 구성된다:
- lowerdir (읽기 전용): 컨테이너 이미지의 레이어들. 여러 컨테이너가 공유할 수 있어 디스크 효율이 높다.
- upperdir (읽기-쓰기): 컨테이너 실행 중 변경된 파일이 저장되는 레이어. 컨테이너가 종료되면 사라진다.
- workdir (임시 공간): OverlayFS 내부 작업용 디렉토리.
- merged (병합 결과): 위 세 레이어를 합쳐서 컨테이너가 실제로 보는
/(rootfs)가 된다.
Copy-on-Write(CoW) 방식: 파일을 수정할 때 원본(lowerdir)은 그대로 두고, 수정본만 upperdir에 복사하여 저장한다. 이 덕분에 여러 컨테이너가 같은 이미지 레이어를 공유하면서도 서로 영향을 주지 않는다.
Docker 내부 실행 구조
Docker가 컨테이너를 실행하는 과정은 여러 컴포넌트가 계층적으로 협력한다.
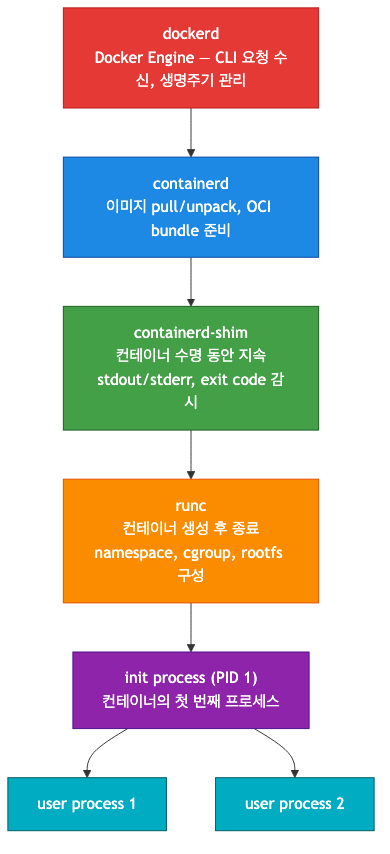
- dockerd: Docker CLI 요청을 받는 진입점. 이미지 관리, 컨테이너 생명주기 관리를 containerd에 위임한다.
- containerd: 이미지 pull/unpack, OverlayFS 마운트, OCI bundle(config.json + rootfs) 준비. runc에 전달하기 위한 환경을 구성한다.
- containerd-shim: runc 실행 후 init process를 계속 감시한다. stdout/stderr 연결, exit code 감시,
docker exec/docker logs처리를 담당한다. runc가 종료된 후 init process의 부모 프로세스가 된다. - runc: OCI 표준 컨테이너 런타임. config.json을 읽어 namespace, cgroup, rootfs 환경을 구성하고, CMD(PID 1)를 실행한 뒤 자신은 종료한다.
💡 Callout: 컨테이너는 결국 프로세스다
컨테이너의 본질을 한 문장으로 요약하면: "Linux 커널의 namespace(격리)와 cgroup(자원 제한)으로 통제되는 프로세스 집합."
Host에서
ps aux를 실행하면 컨테이너 내부의 프로세스들이 일반 프로세스처럼 보인다. 단지 namespace 덕분에 컨테이너 내부에서는 서로 다른 PID로, 독립된 네트워크로, 독립된 파일시스템으로 보이는 것이다. dockerd, containerd는 이 프로세스들을 "컨테이너"라는 논리적 단위로 추상화해서 관리한다.이 점을 이해하면 컨테이너 디버깅이 훨씬 쉬워진다. 컨테이너가 이상하게 동작한다면 결국 Linux 프로세스 문제이므로,
ps,top,strace,/proc같은 일반 Linux 도구들을 사용할 수 있다.
Docker 네트워킹
Docker 컨테이너는 물리 NIC와 별도로, 각 컨테이너에 가상 NIC를 할당한다.
| 네트워크 타입 | 설명 | 통신 범위 |
|---|---|---|
| bridge | 기본 모드. Linux bridge(docker0)를 통해 컨테이너 간 통신. 외부 통신 시 NAT | 단일 호스트 내 컨테이너끼리 |
| host | 컨테이너가 호스트 IP를 그대로 사용. 네트워크 격리 없음 | 호스트와 공유 |
| overlay | 여러 호스트의 컨테이너를 연결하는 가상 네트워크 | 다중 호스트 가능 |
외부에서 컨테이너로 포트를 열 때(-p 8080:80), iptables가 hostIP:8080 → containerIP:80으로 NAPT를 수행한다.
Docker 보안
- Capability: 프로세스 권한을 세분화. root에게 모든 권한을 주지 않고 필요한 최소 권한만 부여.
- SELinux: 프로세스와 파일의 상호 작용을 제한하는 강력한 보안 모듈 (NSA 개발). 컨테이너와 호스트 간 보안 경계 강화.
- AppArmor: Ubuntu/Debian 계열에서 주로 사용하는 프로파일 기반 보안. SELinux보다 설정이 단순.
- seccomp: 컨테이너가 사용할 수 있는 시스템 콜을 제한.
컨테이너 오케스트레이션: 수백 개의 컨테이너를 어떻게 관리하나?
컨테이너 하나, 두 개를 직접 실행하는 것은 어렵지 않다. 하지만 수십 개의 마이크로서비스가 각각 여러 인스턴스로 실행되고, 이것들이 서로 통신하면서 장애 시 자동 복구해야 한다면? 사람이 직접 관리하는 것은 불가능하다.
컨테이너 오케스트레이션은 이 문제를 해결한다. 다수의 컨테이너를 자동으로 배치, 관리, 확장, 네트워킹, 모니터링하는 시스템이다.
오케스트레이션이 없다면 생기는 문제
- 배포/설정이 모두 수동 작업
- 자동 스케일링 불가 (트래픽이 폭증해도 직접 인스턴스 추가해야 함)
- 장애 대응 및 Self-healing 없음 (서버가 죽으면 직접 재시작해야 함)
- 서비스 디스커버리와 로드밸런싱을 직접 구현해야 함
- 롤링 업데이트, 블루/그린 배포 등 안전한 배포 전략 사용 어려움
- 자원 사용 최적화 어려움
오케스트레이션 도구 비교
| 도구 | 설명 |
|---|---|
| Kubernetes (K8s) | 사실상 업계 표준. Pod 관리, 자동 스케일링, 서비스 디스커버리, 롤링 업데이트, 자가 복구 제공 |
| Docker Swarm | Docker 내장 오케스트레이션. 단순하고 빠르게 설정 가능하지만 Kubernetes에 비해 기능 제한 |
| Apache Mesos | 대규모 클러스터 자원 관리. 복잡하지만 다양한 워크로드 지원 |
| EKS (AWS) | AWS 완전 관리형 Kubernetes. AWS 서비스(IAM, ALB, EBS 등)와 깊은 통합 |
| AKS (Azure) | Azure 완전 관리형 Kubernetes |
| GKE (Google) | Google Cloud 완전 관리형 Kubernetes. 자동 업그레이드, 자동 복구 기능 강점 |
Kubernetes의 핵심 기능
- Pod 관리: 하나 이상의 컨테이너를 묶는 최소 배포 단위인 Pod를 관리
- 자동 스케일링: CPU/메모리 사용률 또는 커스텀 메트릭 기반으로 Pod 수 자동 조정
- 서비스 디스커버리: 동적으로 생성되는 Pod들을 이름 기반으로 찾을 수 있게 함
- 롤링 업데이트: 배포 중에도 서비스 중단 없이 새 버전으로 순차 교체
- 자가 복구(Self-healing): 비정상 Pod를 자동 재시작하고, 노드 장애 시 다른 노드에 Pod 재배치
요약: 컨테이너는 "애플리케이션을 어디서나 동일하게 실행"하는 문제를 해결하고, 오케스트레이션은 "수많은 컨테이너를 자동으로 관리"하는 문제를 해결한다. 두 기술의 조합이 클라우드 네이티브 인프라의 근간이다.
