
오퍼레이터 패턴이란 무엇인가?
Kubernetes는 강력하다. Deployment를 선언하면 Pod를 원하는 수만큼 유지하고, 장애가 생기면 자동으로 재시작한다. StatefulSet으로 순서 있는 배포와 안정적인 스토리지를 관리한다. 하지만 Kubernetes의 기본 리소스들은 "일반적인 패턴"까지만 지원한다.
PostgreSQL 클러스터를 구성한다고 생각해보자. 단순히 Pod를 띄우는 것은 Kubernetes가 해주지만, "장애 발생 시 자동 Failover", "읽기 복제본 자동 생성", "롤링 업그레이드 중 데이터 마이그레이션", "주기적 백업 스케줄 관리" 같은 PostgreSQL 전문 지식이 필요한 작업들은 여전히 숙련된 DBA가 수동으로 처리해야 한다.
오퍼레이터 패턴은 이 문제를 해결한다. 사람이 하던 운영 지식(도메인 지식)을 소프트웨어로 캡슐화하여, 애플리케이션 전용 컨트롤러를 만드는 방식이다.
오퍼레이터 = CustomResourceDefinition(CRD) + Controller + 도메인 전문 운영 로직
왜 오퍼레이터가 필요한가?
Kubernetes의 기본 리소스인 Deployment, StatefulSet, Service 등은 상태 없는(Stateless) 앱 또는 단순한 Stateful 앱 관리에 최적화되어 있다. 하지만 다음과 같은 복잡한 시스템들은 훨씬 더 정교한 운영 로직을 요구한다.
- 데이터베이스 클러스터 (PostgreSQL, MySQL, Cassandra): 노드 추가 시 데이터 재분배, 장애 노드 교체, 마이너 버전 업그레이드 절차
- 메시지 큐 (Kafka): 브로커 확장 시 파티션 재분배, Topic 설정 관리
- 모니터링 스택 (Prometheus): 스크랩 타겟 자동 등록, Alert 룰 관리
오퍼레이터를 사용하면 이런 전문 지식이 코드로 구현되어 자동 실행된다. 숙련된 운영자 없이도 복잡한 시스템의 라이프사이클 전체를 Kubernetes가 관리하게 된다.
오퍼레이터의 3대 구성 요소
1. CustomResourceDefinition (CRD)
CRD는 Kubernetes에 새로운 리소스 타입을 등록하는 메커니즘이다. Kubernetes가 기본으로 제공하는 Deployment, Service, ConfigMap 외에 사용자가 직접 새로운 리소스 타입을 만들 수 있다.
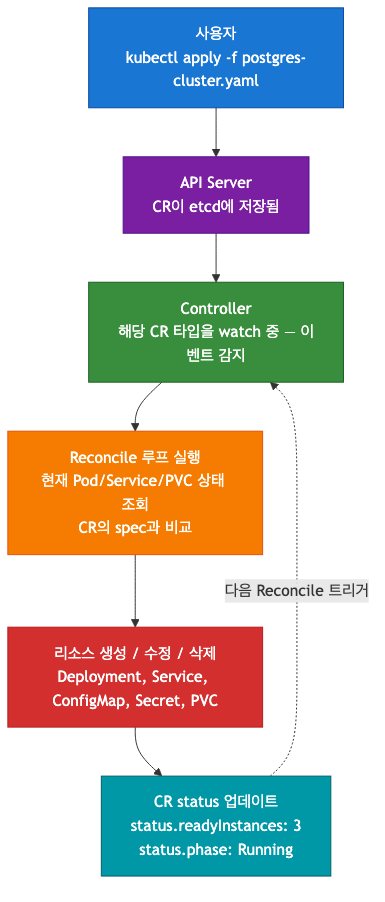
예를 들어 PostgreSQL 오퍼레이터는 PostgresCluster라는 CRD를 등록한다. 이렇게 하면 kubectl get postgrescluster처럼 표준 Kubernetes 도구로 조회하고 관리할 수 있다.
2. Custom Resource (CR)
CR은 CRD로 정의된 타입의 실제 인스턴스다. 사용자는 "원하는 상태(Desired State)"를 YAML로 선언한다.
apiVersion: postgres.example.com/v1
kind: PostgresCluster
metadata:
name: my-postgres
spec:
instances: 3 # 원하는 인스턴스 수
postgresVersion: 14 # PostgreSQL 버전
backupSchedule: "0 2 * * *" # 백업 스케줄이 YAML은 "이런 PostgreSQL 클러스터가 있었으면 좋겠다"는 의도를 표현한다. 어떻게 만들지는 오퍼레이터의 Controller가 결정한다.
3. Controller (오퍼레이터의 "뇌")
Controller는 CR을 감시(watch)하고, 현재 상태(Current State)를 원하는 상태(Desired State)에 맞추는 Reconciliation Loop를 실행한다.
Reconciliation Loop: 쿠버네티스 자동화의 심장
오퍼레이터 패턴의 핵심 메커니즘은 "끊임없이 현재 상태를 원하는 상태로 맞추려는" 제어 루프다. 이를 Reconciliation Loop라 한다.
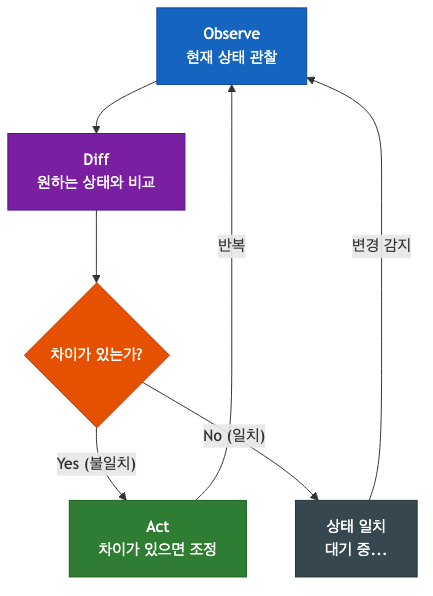
Reconcile 함수는 CR이 생성, 변경, 삭제될 때마다 호출되며, 반드시 Idempotent해야 한다. 즉, 같은 상황에서 여러 번 호출해도 항상 동일한 결과를 만들어야 한다. 네트워크 오류나 프로세스 재시작으로 Reconcile이 중복 실행되어도 문제가 생기면 안 된다.
이 루프가 강력한 이유는 "선언"만으로 시스템이 스스로 수렴하기 때문이다. 사용자가 "3개의 PostgreSQL 인스턴스"를 선언하면, 오퍼레이터는 현재 2개라면 1개를 추가하고, 4개라면 1개를 삭제한다. 그리고 이 상태를 지속적으로 감시하며 유지한다.
오퍼레이터 동작 흐름
대표적인 오퍼레이터 사례
Prometheus Operator
가장 널리 쓰이는 오퍼레이터 중 하나. Prometheus, Alertmanager, ServiceMonitor, PrometheusRule 등의 CRD를 제공한다. 덕분에 Prometheus 설정을 YAML로 선언하면 오퍼레이터가 자동으로 설정 파일을 생성하고 Prometheus를 재로드한다. ServiceMonitor 리소스를 생성하는 것만으로 새로운 서비스의 메트릭이 자동으로 수집된다.
DB Operators
PostgreSQL Operator(Crunchy Data, CloudNativePG), MongoDB Operator 등. 고가용성 구성, 자동 백업/복구, 마이너 버전 업그레이드 절차, 읽기 복제본 관리 등을 자동화한다.
그 외
Kafka, Redis, Elasticsearch, Cert-Manager(TLS 인증서 자동 갱신), Istio, ArgoCD 등 오늘날 대부분의 복잡한 오픈소스 시스템들이 오퍼레이터 패턴으로 제공된다.
Helm을 이용한 오퍼레이터 설치와 관리
오퍼레이터는 보통 Helm Chart로 배포된다. 일반적인 오퍼레이터 Chart의 구조는 다음과 같다.
my-operator/
Chart.yaml
values.yaml
templates/
crds.yaml # 오퍼레이터가 사용할 CRD 정의
operator-deployment.yaml # 실제 오퍼레이터 Deployment
rbac.yaml # CRD/리소스에 대한 RBAC 권한
serviceaccount.yaml
operator-config.yaml설치 명령어
# 1. Helm Repository 등록
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
# 2. 설치 가능한 옵션 확인
helm show values prometheus-community/kube-prometheus-stack
# 3. 기본 설치
helm install my-operator my-operator/my-operator \
--namespace operators --create-namespace
# 4. 커스텀 값 파일 적용
helm install my-operator my-operator/my-operator \
-f values-production.yaml
# 5. 특정 설정만 인라인 변경
helm install my-operator my-operator/my-operator \
--set image.tag=v1.3.0 \
--set operator.replicas=2
# 6. 업그레이드
helm upgrade my-operator my-operator/my-operator \
--namespace operators --reuse-values
# 7. 롤백
helm rollback my-operator 1
# 8. 히스토리 확인
helm history my-operatorGitOps(ArgoCD)와의 결합
오퍼레이터를 GitOps 방식으로 관리할 때 주의할 점이 있다.
CRD 관리 방식
CRD는 Helm으로 관리하지 않고 Git에서 직접 관리하는 것이 권장된다. CRD는 업데이트 시 diff가 크게 발생해서 Helm의 helm diff나 ArgoCD의 diff 기능이 제대로 동작하지 않는 경우가 많기 때문이다.
# values.yaml
crds:
install: false # CRD는 Helm이 아닌 GitOps로 별도 관리ArgoCD Application 예시
source:
repoURL: https://charts.example.com
chart: my-operator
targetRevision: 1.2.0
helm:
valueFiles:
- values-argocd.yaml
releaseName: my-operator💡 Callout: Helm Chart 내 CRD를 GitOps에서 관리해야 하는 이유
CRD는 Kubernetes 클러스터 전체에 영향을 미치는 API 확장이다. Helm이 CRD를 관리하면
helm upgrade나helm rollback시 CRD가 의도치 않게 변경되거나 삭제될 수 있다. 또한 CRD 업데이트 시 발생하는 대규모 diff는 ArgoCD의 sync 과정을 복잡하게 만든다.따라서 CRD는 Git 레포지토리에서 직접 YAML로 관리하고,
kubectl apply나 ArgoCD를 통해 별도 Application으로 배포하는 것이 안전하다. 오퍼레이터 Deployment 자체는 Helm으로 관리해도 문제없다.
자주 발생하는 문제와 해결
| 문제 | 원인 | 해결 방법 |
|---|---|---|
| CRD 적용 실패 | CRD 적용 순서 문제 | crds.install=true 또는 Helm 설치 전 수동 kubectl apply |
| 오퍼레이터 CrashLoop | RBAC 권한 미설정 | rbac.yaml 검토, ClusterRole/ClusterRoleBinding 확인 |
| CR 생성 후 리소스 미생성 | Reconcile 실패 | 오퍼레이터 Pod 로그 확인 (kubectl logs) |
| Helm rollback 실패 | CRD가 여전히 클러스터에 존재 | CRD 수동 삭제 후 재시도 |
Helm Chart 생성 및 배포 (자체 오퍼레이터 개발 시)
자체 오퍼레이터를 개발한다면 다음 흐름으로 Helm Chart를 생성하고 배포한다.
# 1. Chart 스캐폴딩 생성
helm create my-operator
# 2. 필요한 파일 수정
# - templates/deployment.yaml → 오퍼레이터 Deployment
# - templates/crds.yaml → CRD 정의 추가
# - values.yaml → 이미지, 리소스, 설정값
# - Chart.yaml → 버전 관리
# 3. 패키징
helm package my-operator
# 4. OCI 레지스트리에 Push
helm push my-operator-0.1.0.tgz oci://ghcr.io/myrepo/charts요약: 오퍼레이터 패턴은 Kubernetes의 선언적 API와 제어 루프 개념을 확장하여, 복잡한 애플리케이션의 운영 지식을 코드로 캡슐화한다. "사람이 하던 일을 소프트웨어가 한다"는 것이 핵심이며, 이를 통해 복잡한 Stateful 시스템도 클라우드 네이티브 방식으로 완전 자동화할 수 있다.
