
EDA란 무엇인가?
Event-Driven Architecture(EDA) 는 시스템 간 통신을 이벤트(Event)를 기반으로 동작시켜 서비스 간 결합도를 낮추고, 확장성과 반응성을 높이는 아키텍처다.
여기서 이벤트(Event)란 "무언가가 일어났다는 사실" 이다. 명령(Command, "이것을 해라")이나 조회(Query, "이것을 알려달라")와 다르게, 이벤트는 과거에 발생한 사실을 기록한다. OrderCreated, PaymentCompleted, StockDepleted 처럼 과거형으로 표현한다.
EDA의 흐름
- Producer(생산자): 이벤트를 발행하는 서비스 (예: 주문 서비스가
OrderCreated발행) - Event Broker: 이벤트를 저장하고 전달하는 중간 시스템 (예: Kafka)
- Consumer(소비자): 이벤트를 구독하고 처리하는 서비스 (예: 결제 서비스, 알림 서비스)
왜 EDA인가? 동기 방식의 한계
EDA의 가치를 이해하려면, 기존 동기식 REST 호출 방식의 문제를 먼저 봐야 한다.
동기 방식의 문제
주문 서비스가 주문을 받으면 결제, 재고, 배송, 알림 서비스를 순서대로 동기 호출한다고 가정하자.

이 구조의 문제는 명확하다.
- 알림 서비스가 느려지면 주문 서비스의 응답도 느려진다
- 재고 서비스가 일시적으로 다운되면 주문 전체가 실패한다
- 트래픽이 폭증하면 모든 서비스가 동시에 스케일 아웃해야 한다
EDA 도입 후
주문 서비스는 OrderCreated 이벤트를 Kafka에 발행하고 즉시 응답을 반환한다. 결제, 재고, 배송, 알림 서비스는 각자의 속도에 맞춰 이벤트를 처리한다.
- 알림 서비스가 느려도 주문 응답에 영향 없음
- 재고 서비스가 일시 다운되어도 이벤트가 Kafka에 보존되어 복구 후 처리
- 각 서비스를 독립적으로 스케일 아웃 가능
EDA의 핵심 특징
- 느슨한 결합(Decoupling): Producer는 Consumer가 누구인지, 몇 개인지 알 필요가 없다. 이벤트를 발행하면 끝이다.
- 비동기 처리(Async): Producer는 Consumer의 처리 완료를 기다리지 않는다.
- 고성능/확장성: Broker가 버퍼 역할을 하므로 순간 트래픽 폭증을 흡수하고, Consumer를 독립적으로 스케일 가능하다.
- 장애 격리: 하나의 Consumer 장애가 Producer나 다른 Consumer에 영향을 주지 않는다.
- 실시간 반응성: 이벤트 발생 즉시 구독 중인 모든 Consumer가 반응한다.
EDA 구성 요소
Event Producer: 이벤트를 생성하는 주체. 비즈니스 로직에서 의미 있는 일이 발생했을 때 이벤트를 발행한다.
Event Broker: Kafka, RabbitMQ, AWS SNS/SQS, NATS 등. 이벤트 저장, 전달, 재시도, 파티션, 순서 보장을 담당한다. 브로커의 특성에 따라 "at-least-once", "at-most-once", "exactly-once" 전달 보장 수준이 다르다.
Event Consumer: 이벤트를 구독하고 비즈니스 로직을 처리하는 서비스.
Event Router / Stream Processor: 이벤트를 변환, 필터링, 집계하는 컴포넌트. Kafka Streams, Apache Flink, Spark Streaming, KSQL 등.
EDA 패턴 3가지
① Event Notification (이벤트 알림)
가장 단순한 패턴. 이벤트에는 "무슨 일이 생겼다"는 최소한의 정보만 담는다. Consumer는 이벤트를 받으면 Producer에게 API를 호출해 필요한 상세 정보를 조회한다.
// 이벤트 페이로드 (최소 정보)
{ "event": "OrderCreated", "orderId": "12345", "timestamp": "..." }장점: 이벤트가 가볍고 단순하다. 단점: Consumer가 매번 API를 다시 조회해야 해서 트래픽이 증가한다.
② Event-Carried State Transfer (이벤트 상태 전달)
이벤트 자체에 처리에 필요한 모든 데이터를 포함한다. Consumer가 추가 조회 없이 이벤트만으로 처리를 완료할 수 있다.
// 이벤트 페이로드 (필요한 모든 데이터 포함)
{
"event": "OrderCreated",
"orderId": "12345",
"userId": "u789",
"items": [...],
"totalAmount": 50000,
"shippingAddress": {...}
}장점: Consumer 자율성이 높아지고 API 호출이 줄어든다. 단점: 이벤트 페이로드가 커지고, 데이터 중복이 발생한다.
③ Event Sourcing (이벤트 소싱)
상태를 저장하는 대신, 상태를 만들어낸 이벤트의 히스토리를 저장한다. 현재 상태가 필요하면 이벤트들을 처음부터 재생(Replay)하여 재구성한다.
OrderCreated → PaymentApproved → ShipmentStarted → Delivered이 이벤트 스트림이 곧 주문의 전체 역사다. 어느 시점의 상태든 이벤트를 그 시점까지 재생하면 알 수 있다.
장점: 완전한 감사 로그, 상태 재현 가능, 버그 수정 후 재처리 가능. 단점: 설계 복잡도가 높고, 이벤트 스키마 변경 관리가 어렵다. 보통 CQRS와 함께 사용된다.
💡 Callout: Kafka 핵심 개념 이해
Kafka는 EDA에서 가장 널리 쓰이는 분산 이벤트 스트리밍 플랫폼이다. 주요 개념:
- Topic: 이벤트의 논리적 채널.
order-events,payment-events처럼 도메인 단위로 구성.- Partition: Topic을 물리적으로 분할한 단위. 파티션 수가 병렬 처리량의 상한을 결정한다. 같은 키(예: orderId)를 가진 이벤트는 항상 같은 파티션에 저장되어 순서가 보장된다.
- Consumer Group: 같은 그룹 내 Consumer들이 파티션을 나눠 처리한다. 그룹 단위로 오프셋(어디까지 읽었는지)을 관리하므로, 서비스별로 독립적으로 이벤트를 처리할 수 있다.
- Offset: Consumer가 어디까지 읽었는지를 기록하는 포인터. 장애 후 재시작 시 마지막 오프셋부터 이어서 처리한다.
- 보존 기간: 이벤트를 일정 기간 또는 영구적으로 보관 가능. 새로운 Consumer를 추가하면 과거 이벤트부터 처음 읽을 수 있다.
Event Flow 동작 예시: 주문 → 결제 → 배송
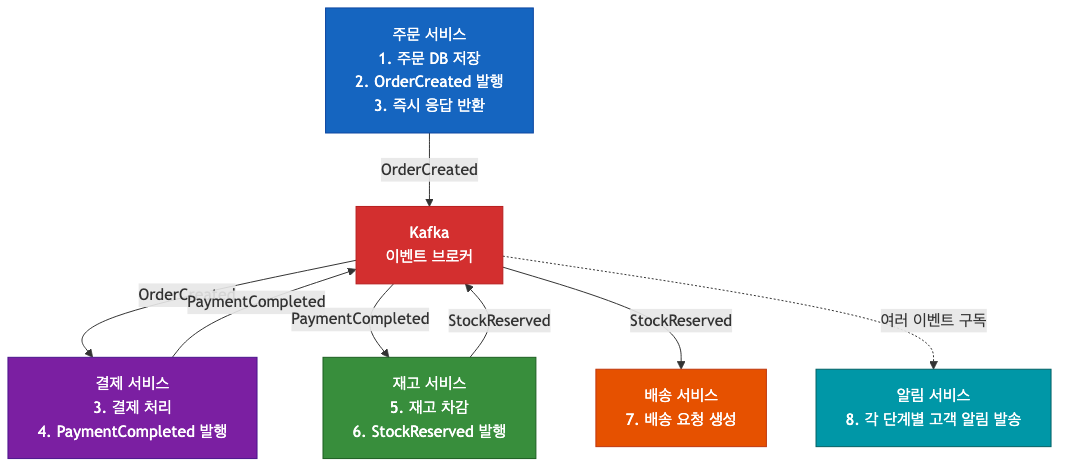
각 단계는 독립적으로 처리되고, 어느 단계에서 실패해도 Saga 패턴의 보상 트랜잭션으로 처리한다.
요약: EDA는 서비스 간 동기 의존성을 끊고 이벤트라는 간접 매개체를 통해 통신하는 방식이다. 결합도를 낮추고 확장성과 복원력을 높이는 강력한 패턴이지만, 이벤트 순서 보장, 중복 처리, 최종 일관성 등 분산 시스템의 복잡성을 함께 고려해야 한다.
