
데이터도 함께 분리되어야 한다
MSA로의 전환에서 가장 놓치기 쉬운 부분이 데이터다. 코드는 서비스 단위로 분리했지만, DB는 여전히 하나를 공유한다면? 이는 가짜 MSA다. 서비스가 독립되려면 데이터도 독립되어야 한다.
모놀리식에서 마이크로서비스로 가는 과정은 사실 데이터 분리의 과정이기도 하다. 이 과정에서 기존에는 당연했던 "테이블 간 JOIN", "하나의 트랜잭션으로 여러 테이블 업데이트" 같은 것들이 불가능해진다. 그 대신 새로운 패턴들이 필요해진다.
데이터 관리의 핵심 목표
- 각 도메인 서비스가 자신의 데이터에 대한 소유권(Ownership) 을 가짐
- 확장성(Scalability), 가용성(Availability), 일관성(Consistency)의 균형
- 운영 자동화(Backup, DR, 스키마 변경, 보안)를 플랫폼/코드로 관리
도메인 중심 데이터 소유권
"서비스 = 코드 + 데이터 + 운영 책임"의 한 묶음
각 마이크로서비스는 자신의 데이터베이스를 소유하고, 다른 서비스의 DB에 직접 접근해서는 안 된다.
flowchart LR
OS["Order Service\n주문 서비스"]
PS["Payment Service\n결제 서비스"]
InvS["Inventory Service\n재고 서비스"]
ODB[("Order DB\n주문 서비스만 접근")]
PDB[("Payment DB\n결제 서비스만 접근")]
IDB[("Inventory DB\n재고 서비스만 접근")]
OS --> ODB
PS --> PDB
InvS --> IDB
OS -."API 또는 이벤트로만 통신".-> PS
PS -."API 또는 이벤트로만 통신".-> InvS
style OS fill:#1565C0,stroke:#0D47A1,color:#fff
style PS fill:#7B1FA2,stroke:#4A148C,color:#fff
style InvS fill:#388E3C,stroke:#1B5E20,color:#fff
style ODB fill:#F57C00,stroke:#E65100,color:#fff
style PDB fill:#F57C00,stroke:#E65100,color:#fff
style IDB fill:#F57C00,stroke:#E65100,color:#fff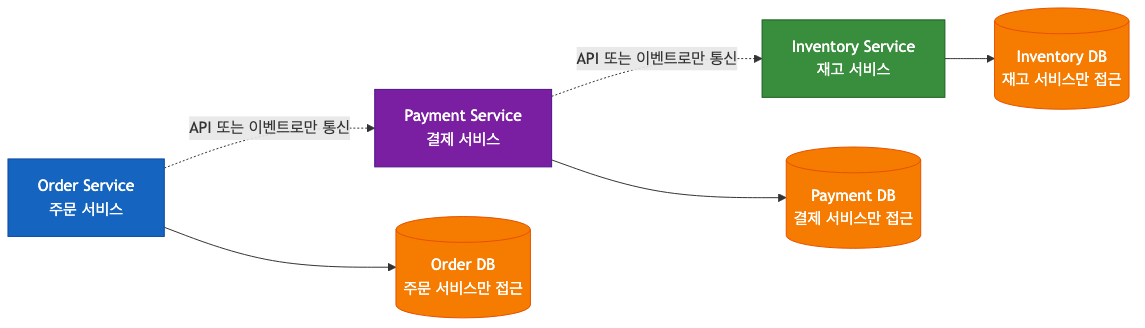
다른 서비스의 데이터가 필요하다면, 해당 서비스의 API를 통해 요청하거나 이벤트를 통해 수신한다. "다른 팀 DB에 직접 쿼리하는 것"은 MSA에서 금지된 행위다.
왜 이 원칙이 중요한가?
공유 DB를 사용한다면, A 서비스 팀이 스키마를 변경할 때 B, C, D 서비스 팀과 모두 상의하고 동시에 배포해야 한다. 독립 배포가 불가능해진다. DB 소유권 분리는 팀 간 의존성을 제거하는 구조적 방법이다.
Polyglot Persistence: 저장소도 목적에 맞게 선택하라
모놀리식 시대에는 하나의 RDBMS가 모든 것을 담당했다. MSA에서는 서비스마다 가장 적합한 저장소를 선택할 수 있다.
| 데이터 특성 | 적합한 저장소 | 이유 |
|---|---|---|
| 주문/결제 트랜잭션 | PostgreSQL, MySQL | ACID 보장, 강한 일관성 |
| 세션/캐시 | Redis | 인메모리 고속 처리, TTL 관리 |
| 이벤트/로그 스트림 | Kafka, Kinesis, Pulsar | 대용량 순차 쓰기, 영구 보존 |
| 파일/이미지/미디어 | AWS S3, GCS, Azure Blob | 대용량 오브젝트, 저비용 |
| 전문 검색 | Elasticsearch, OpenSearch | 역색인 기반 빠른 검색 |
| 그래프 관계 | Neo4j, Amazon Neptune | 관계 탐색 최적화 |
이것이 Polyglot Persistence(다중 언어 영속성) 다. 각 워크로드에 최적화된 저장소를 선택하면 성능과 비용 효율이 높아진다.
단, 다양한 저장소를 운영한다는 것은 운영 복잡도 증가를 의미한다. 모니터링, 백업, 보안 정책을 각 스토리지에 일관되게 적용해야 한다. 플랫폼 팀의 표준화 작업이 뒷받침되어야 한다.
분산 트랜잭션 문제: Saga 패턴으로 해결
모놀리식에서는 단일 DB에 ACID 트랜잭션으로 모든 것을 처리했다. 주문 생성, 결제 처리, 재고 차감을 하나의 트랜잭션으로 묶으면 됐다. 하지만 MSA에서는 이 세 작업이 각각 다른 서비스, 다른 DB에 있다.
2PC(Two-Phase Commit)는 왜 쓰지 않는가?
2PC는 분산 트랜잭션의 전통적인 해결책이지만, 클라우드 네이티브 환경에 적합하지 않다. 모든 참여 서비스가 동시에 lock을 잡고 Coordinator의 결정을 기다려야 하므로 성능이 나빠지고, Coordinator 장애 시 교착 상태가 발생한다.
Saga 패턴
각 서비스가 로컬 트랜잭션을 처리하고, 실패 시 이미 완료된 단계를 되돌리는 보상(Compensation) 트랜잭션을 실행하는 방식이다.
강한 일관성(Strong Consistency) 대신 최종 일관성(Eventual Consistency) 을 목표로 한다. 결과적으로는 일관된 상태가 되지만, 그 과정에서 잠깐 일관되지 않은 상태가 존재할 수 있다.
Choreography vs Orchestration 비교
| 구분 | Choreography | Orchestration |
|---|---|---|
| 흐름 제어 | 각 서비스가 이벤트를 받아 자율적으로 다음 단계 결정 | Saga Orchestrator가 명시적으로 각 서비스 호출 |
| 장점 | 서비스 간 직접 의존성 없음, 느슨한 결합 | 전체 흐름이 한 곳에 정의되어 추적 용이 |
| 단점 | 전체 흐름 파악이 어려움, 분산된 로직 | Orchestrator가 복잡해지고 단일 장애점 가능성 |
CQRS와 Event Sourcing: 읽기와 쓰기를 분리하다
CQRS (Command Query Responsibility Segregation)
Command(쓰기) 와 Query(읽기) 를 담당하는 모델을 분리하는 패턴이다.
왜 필요한가? 쓰기 작업과 읽기 작업의 요구사항이 근본적으로 다르기 때문이다.
- 쓰기: 일관성, 트랜잭션, 검증이 중요. 정규화된 RDBMS에 최적화.
- 읽기: 성능, 유연성이 중요. 다양한 형태의 집계 데이터가 필요. 비정규화된 뷰, 캐시, 검색 인덱스에 최적화.
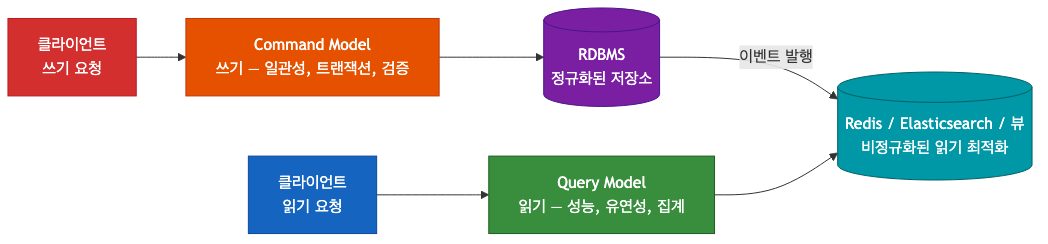
Command Model은 데이터를 쓰고 이벤트를 발행한다. Query Model은 이 이벤트를 소비해서 읽기에 최적화된 형태로 자신의 저장소를 업데이트한다. 읽기 모델은 여러 개일 수도 있다. 하나는 Redis에 캐시, 다른 하나는 Elasticsearch에 검색 인덱스로.
Event Sourcing (이벤트 소싱)
현재 상태를 저장하는 대신, 상태를 만들어낸 이벤트의 히스토리를 저장한다.
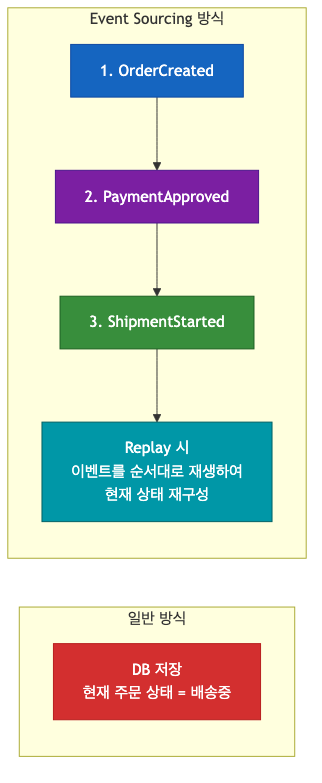
현재 상태가 필요하면 이벤트들을 처음부터 재생(Replay)하여 계산한다. 어느 시점의 상태든 재현 가능하고, 완전한 감사 로그(Audit Trail)가 자동으로 만들어진다.
장점: 히스토리 완전 보존, 버그 수정 후 재처리 가능, 감사 용이, 다양한 읽기 모델 생성 가능
단점: 설계 복잡도가 높음, 이벤트 스키마 변경 관리가 어려움, 현재 상태 조회가 느릴 수 있음(스냅샷으로 완화)
💡 Callout: CQRS + Event Sourcing 조합
두 패턴을 함께 쓰면 강력하다. Kafka에 이벤트를 저장(쓰기 모델)하고, Consumer들이 이 이벤트를 읽어 각자의 읽기 모델을 만든다.
- Consumer A: Elasticsearch에 검색 인덱스 구성
- Consumer B: Redis에 캐시 구성
- Consumer C: BI 툴을 위한 데이터 마트 구성
하나의 이벤트 스트림에서 여러 용도의 뷰가 파생된다. 단, 이 패턴은 복잡성이 상당하므로 금융 거래, 주문 히스토리처럼 감사와 재현이 정말 중요한 도메인에 선택적으로 적용해야 한다.
데이터 접근 패턴
API Composition
여러 서비스의 데이터를 조합해서 하나의 응답을 만들어야 할 때, BFF나 API Gateway에서 여러 서비스를 순차 또는 병렬 호출하여 결과를 조합한다.
예: 주문 상세 화면을 위해 Order Service, User Service, Product Service를 동시에 호출하고 결과를 합쳐서 반환.
GraphQL 기반 접근
GraphQL은 클라이언트가 필요한 필드만 선택해서 요청할 수 있는 쿼리 언어다. 서버는 여러 서비스/DB에서 데이터를 조합해 반환한다. 클라이언트마다 다른 데이터 구조가 필요한 환경에서 Over-fetching(필요 없는 데이터 수신)과 Under-fetching(여러 번 요청 필요)을 동시에 해결한다.
읽기 전용 뷰 (Query Model)
복잡한 집계 리포트나 대시보드를 위해, 여러 서비스의 데이터를 조합한 읽기 전용 데이터 마트를 별도로 운영한다. 각 서비스가 변경 이벤트를 발행하면, 데이터 마트가 이를 구독해서 자신의 뷰를 업데이트한다.
요약: MSA에서 데이터 관리는 단순히 "DB를 나누는 것"이 아니다. 도메인별 소유권 설정, 목적에 맞는 저장소 선택(Polyglot), 분산 트랜잭션 처리(Saga), 읽기/쓰기 분리(CQRS), 감사와 히스토리(Event Sourcing)까지 아우르는 체계적인 전략이 필요하다.
