
클라우드 네이티브 보안: 패러다임의 전환
전통적인 보안은 경계 기반(Perimeter-based) 이었다. 방화벽으로 외부와의 경계를 만들고, 그 안에 있으면 신뢰하는 방식이다. 외부 침입을 막으면 내부는 안전하다고 가정했다.
클라우드 네이티브 환경에서 이 가정은 위험하다. 마이크로서비스가 수십 개이고, 각 서비스가 독립적으로 배포되며, 내부 서비스들도 서로 API로 통신한다. 내부 서비스 하나가 침해되면, 경계 안에 있다는 이유로 다른 모든 서비스로 자유롭게 이동(Lateral Movement)할 수 있다.
패러다임 전환: 경계 기반 → ID 중심 + Zero Trust
보안 적용 범위도 달라진다. 과거에는 네트워크 경계가 보안 경계였다. 이제는 코드, 컨테이너 이미지, 런타임, 네트워크, CI/CD 파이프라인, 데이터, 서비스 간 통신까지 전체 라이프사이클이 보안 적용 범위다.
클라우드 네이티브 6대 보안 영역
1. Identity & Access (IAM/RBAC)
누가 무엇에 접근할 수 있는지를 세밀하게 제어한다. 사람(개발자, 운영자)뿐 아니라 서비스(Pod, Service Account)도 ID와 권한이 있다. Kubernetes의 RBAC으로 "이 ServiceAccount는 이 네임스페이스의 Pod를 읽을 수 있다" 수준까지 세밀하게 정의한다.
2. Supply Chain Security (CI/CD 및 Image Security)
컨테이너 이미지가 신뢰할 수 있는 소스에서 왔는지, 알려진 취약점이 없는지 검증한다. CI/CD 파이프라인에서 다음을 자동화한다.
- SAST (Static Application Security Testing): 소스 코드 취약점 분석
- DAST (Dynamic Application Security Testing): 실행 중인 앱에 대한 취약점 테스트
- Container Scan: Trivy, Snyk 등으로 이미지의 CVE(취약점) 스캔
3. Runtime Security (K8s Runtime + Workload Protection)
실행 중인 컨테이너의 이상 행동을 감지한다. 컨테이너가 갑자기 새로운 프로세스를 실행하거나, 예상치 못한 네트워크 연결을 시도하거나, 민감한 파일에 접근하는 것을 탐지한다. Falco, eBPF 기반 도구들이 이 역할을 한다.
4. Network Security (Zero Trust, Service Mesh)
서비스 간 통신을 mTLS로 암호화하고, NetworkPolicy로 필요한 통신만 허용한다. "기본 차단, 필요한 것만 허용(Default Deny, Explicit Allow)" 원칙.
5. Data Security (Encryption, Tokenization)
저장 데이터(Data at Rest)와 전송 데이터(Data in Transit) 모두 암호화한다. 민감 데이터는 토큰화(Tokenization)하여 실제 값 대신 토큰을 저장한다. Secret은 절대 컨테이너 이미지나 Git에 포함하지 않고, Vault나 Kubernetes Secret(암호화 필수)으로 관리한다.
6. Governance & Compliance (감사 및 정책 관리)
모든 접근과 변경을 감사 로그로 기록한다. OPA(Open Policy Agent), Kyverno 같은 정책 엔진으로 "이 네임스페이스에는 특권 컨테이너를 배포할 수 없다" 같은 규칙을 코드로 정의하고 자동 적용한다.
Zero Trust: 아무도 믿지 않는다
"Never Trust, Always Verify"
Zero Trust는 네트워크의 위치(내부/외부)를 신뢰의 근거로 삼지 않는다. 모든 접근은 신원을 검증받아야 한다.
Zero Trust를 구현하는 핵심 요소:
- Identity 기반 인증/인가: 서비스 A가 서비스 B를 호출할 때도 신원 검증 필요
- mTLS: 클라이언트와 서버 양쪽이 서로의 인증서를 검증 (상호 인증)
- 최소 권한 원칙(Least Privilege): 필요한 최소 권한만 부여. "이 서비스는 Order DB를 읽기만 할 수 있다"
- 지속적인 정책 평가(Continuous Authorization): 요청 시마다 권한을 재검증. 한 번 인증됐다고 계속 신뢰하지 않는다.
Zero Trust = 네트워크 보안 + 워크로드 보안 + ID 보안의 결합
Workload Identity: Pod에도 ID 카드가 있다
기존에는 서비스가 외부 시스템(AWS S3, DB 등)에 접근할 때 API Key나 비밀번호를 환경 변수나 설정 파일에 저장했다. 이는 보안상 위험하다. 유출 시 즉시 악용될 수 있고, 권한 범위를 세밀하게 제어하기 어렵다.
Workload Identity는 API Key 대신 Pod 자체가 ID(신원)를 가지는 방식이다. Kubernetes에서는 ServiceAccount가 이 역할을 한다.
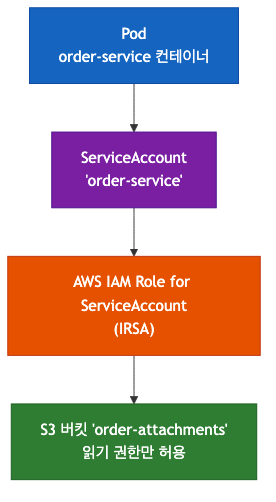
AWS EKS의 IRSA를 사용하면, Pod에 명시적으로 API Key를 주입하지 않아도 Pod의 ServiceAccount를 통해 IAM 권한이 자동으로 부여된다. 키가 유출될 일이 없고, 어느 Pod가 어떤 권한으로 무엇을 했는지 감사 로그로 추적할 수 있다.
장점: API Key/Secret 공유 문제 해결, Pod 단위 보안 격리, 감사 추적 가능
보안 Best Practice
| 영역 | 실천 사항 |
|---|---|
| 설계 | Zero Trust 기반 설계, Least Privilege 원칙 |
| Pod 보안 | Pod Security Standards (Baseline/Restricted) 준수 |
| 통신 암호화 | 모든 통신 구간 TLS/mTLS 적용 |
| Identity | Workload Identity 필수, Secret 이미지/코드 포함 금지 |
| CI/CD | SAST/DAST/Container Scan 자동화 |
| 권한 관리 | RBAC 최소 권한 설계, 정기 권한 검토 |
| 감사 | 로그, 이벤트, Audit 기록 표준화 |
| Runtime | eBPF/Falco로 이상 행동 탐지 |
| 모니터링 | CSPM으로 클라우드 설정 보안 지속 점검 |
| 훈련 | 정기적인 Security Game Day 실행 |
탄력성(Resilience): 장애를 전제로 설계하라
탄력성은 시스템이 장애, 오류, 과부하, 네트워크 문제를 겪더라도 자체적으로 복구하고 정상 상태를 유지하는 능력이다.
전통적인 사고방식: "장애가 없도록 만들자"
클라우드 네이티브 사고방식: "장애는 반드시 온다. 장애가 와도 서비스는 살아있게 만들자"
왜 이 사고방식의 전환이 필요한가? 마이크로서비스 환경에서는 장애를 완전히 막는 것이 불가능하다.
- 수십~수백 개의 서비스 → 어느 하나는 항상 문제가 생긴다
- 컨테이너/Pod는 짧은 수명 → 재시작이 기본 전제
- 네트워크는 불안정하다 → 타임아웃, 패킷 손실은 언제든 발생
- 의존하는 외부 서비스(DB, API)는 때때로 느려진다
"장애는 전제조건, 복구는 자동화해야 한다."
Cloud Native SRE 핵심 원칙: Fail Fast, Recover Fast, Self-Heal
탄력성의 핵심 구성 요소 6가지
① Self-Healing (자가 복구)
Kubernetes의 Liveness Probe와 Readiness Probe를 통해 구현한다.
- Liveness Probe: "이 Pod는 살아있는가?" 죽어있다면 재시작.
- Readiness Probe: "이 Pod는 트래픽을 받을 준비가 됐는가?" 준비가 안 됐다면 로드밸런서에서 제외.
두 Probe의 차이가 중요하다. 앱이 부팅 중이거나 DB 연결 중일 때는 Readiness가 실패해 트래픽을 받지 않고, Liveness는 성공해서 재시작되지 않도록 설정해야 한다.
② Isolation & Bulkhead (격리 및 구획화)
한 서비스의 과부하나 장애가 다른 서비스로 전파되지 않도록 서비스 간 자원을 분리한다.
구체적으로는 CPU/메모리 Limit을 강제하여 한 서비스가 리소스를 독점하지 못하게 하고, 서비스별로 스레드 풀이나 연결 풀을 분리한다.
③ Retry / Timeout / Circuit Breaker
네트워크 오류와 일시적 서비스 장애에 대응하는 3대 패턴이다. 서비스 메시(Istio 등)나 라이브러리(Resilience4j)로 구현한다.
- Retry: 일시적 오류 시 재시도. 반드시 지수 백오프(Exponential Backoff) 와 최대 횟수 제한을 함께 적용해야 한다. 그냥 재시도하면 이미 과부하 상태인 서비스에 더 많은 요청을 보내 상황을 악화시킨다.
- Timeout: 응답 대기 시간에 한계를 둔다. 응답이 안 오는 서비스를 무한정 기다리면 스레드가 고갈된다.
- Circuit Breaker: 오류율이 일정 임계값을 초과하면 해당 서비스 호출을 일시 차단(Circuit Open). 장애가 난 서비스를 계속 호출하는 낭비를 막고, 빠르게 실패(Fail-fast)하여 자원을 보존한다.
💡 Callout: Circuit Breaker의 3가지 상태 (3가지 상태 상세 설명은 강의자료 외 내용)
Circuit Breaker는 전기 회로 차단기의 동작 원리에서 이름을 따온 패턴이다.
- Closed (정상): 요청이 정상적으로 서비스에 전달됨. 오류율을 모니터링.
- Open (차단): 오류율이 임계값(예: 50%) 초과. 회로를 열어 서비스 호출 없이 즉시 실패 반환. 서비스가 복구될 시간을 준다.
- Half-Open (시험): 일정 시간(예: 10초) 후 소수의 요청을 서비스로 보내 복구 여부 테스트. 성공 시 Closed로, 실패 시 다시 Open으로 전환.
Circuit Breaker가 없으면 하나의 서비스 장애가 그것을 호출하는 모든 서비스를 연쇄적으로 느리게 만드는 Cascading Failure가 발생한다.
④ Autoscaling (오토스케일링)
트래픽 변화에 즉각 대응한다.
- HPA (Horizontal Pod Autoscaler): CPU/메모리 사용률 기반으로 Pod 수를 자동 조정
- KEDA: Kafka 메시지 수, 큐 깊이 등 커스텀 메트릭 기반 스케일링. 이벤트 기반 워크로드에 특히 유용
⑤ Load Balancing
여러 Pod에 트래픽을 분산하여 단일 인스턴스에 부하가 집중되지 않게 한다. kube-proxy 또는 eBPF 기반으로 Pod들 간에 라운드로빈 등 방식으로 분산한다.
⑥ Chaos Engineering (혼돈 실험)
강의자료에서는 탄력성의 핵심 구성 요소 6가지 중 하나로, 그리고 Best Practice 목록의 마지막 항목("정기적인 장애 훈련 실행")으로 이름만 언급된다. 상세 개념은 아래 Callout을 참고한다.
💡 Callout: Chaos Engineering 상세 (강의자료 외 추가 내용)
Chaos Engineering은 프로덕션에 가까운 환경에서 의도적으로 장애를 주입하여 시스템의 취약점을 사전에 발견하고 복원력을 검증하는 방법론이다. Netflix에서 2011년 "Chaos Monkey"라는 도구를 공개하면서 알려졌고, 이후 Principles of Chaos Engineering(principlesofchaos.org)으로 체계화됐다.
대표 실험 유형
- Pod 또는 Node 랜덤 종료
- 특정 서비스의 응답을 의도적으로 지연(Latency Injection)
- 네트워크 패킷 손실 또는 차단
- CPU/메모리 리소스 강제 소모
대표 도구
- Chaos Monkey (Netflix): 프로덕션 인스턴스를 랜덤 종료
- Chaos Mesh: Kubernetes 네이티브 Chaos 프레임워크. CRD로 실험 정의
- Litmus Chaos: CNCF 샌드박스 프로젝트. 다양한 실험 시나리오 제공
Chaos Engineering의 핵심 전제는 "장애는 언젠가 반드시 온다"는 것이다. 예상치 못한 장애 상황에서 당황하는 대신, 통제된 환경에서 미리 경험해 대응 절차와 자동 복구 로직을 검증해두는 것이다.
참고: Principles of Chaos Engineering, Chaos Mesh 공식 문서, Netflix Tech Blog — Chaos Engineering
탄력성 Best Practice
| 항목 | 실천 사항 |
|---|---|
| Pod 헬스체크 | 모든 Pod에 Liveness/Readiness Probe 적용 |
| 타임아웃 | 모든 외부 호출에 Timeout 설정 |
| 재시도 | 지수 백오프 + 최대 횟수 제한 |
| Circuit Breaker | 모든 서비스 간 호출에 적용 |
| 트래픽 탄력성 | Service Mesh로 Retry/Circuit Breaker 정책 관리 |
| 격리 | CPU/Memory Limit 강제, Bulkhead 패턴 |
| 스케일링 | HPA/KEDA 기반 자동 스케일링 |
| DB 가용성 | Multi-AZ DB 구성 |
| 장애 훈련 | 정기적인 Chaos Engineering 실행 |
요약: 보안은 네트워크 경계 너머 전체 라이프사이클에 걸쳐 적용되어야 하며, Zero Trust가 그 핵심 원칙이다. 탄력성은 "장애가 없는 시스템"이 아니라 "장애가 와도 스스로 복구하는 시스템"을 목표로 하며, Self-Healing, Circuit Breaker, Chaos Engineering이 그 핵심 수단이다.
