
Observability란 무엇인가?
Observability(관측성) 는 시스템 내부 상태를 외부에서 파악(Understand)할 수 있도록 만드는 능력이다. 단순히 "시스템이 정상인가?"를 확인하는 것(Monitoring)을 넘어, "왜 이 문제가 생겼는가?"를 분석할 수 있는 능력이다.
| 구분 | Monitoring | Observability |
|---|---|---|
| 질문 | "문제가 생겼는가?" | "왜 문제가 생겼는가?" |
| 접근 | "알려진 미지수" — 예상된 장애 감지 | "알려지지 않은 미지수" — 예상 못한 장애 진단 |
| 방법 | 사전에 정의한 임계값 알람 | 데이터를 탐색해 원인 역추적 |
왜 Cloud Native 환경에서 Observability가 필수인가?
모놀리식 환경에서는 하나의 프로세스가 전부라 로그 파일 하나를 보면 됐다. 하지만 마이크로서비스 환경은 다르다.
- 수십~수백 개의 서비스가 동시에 동작
- 컨테이너는 짧은 수명을 가지며 수시로 생성, 삭제, 재시작됨
- 요청 하나가 여러 서비스를 거치는 복잡한 경로
- 비동기 이벤트 흐름으로 원인과 결과를 파악하기 어려움
이런 환경에서 "어느 서비스에서 지연이 생겼는가?", "이 에러가 어디서 시작됐는가?"를 파악하려면 체계적인 Observability 도구 없이는 불가능하다.
Observability의 3대 축 (Three Pillars)
Metrics (지표)
수치 기반의 집계 데이터다. 시계열로 저장되며, 특정 시간의 시스템 상태를 숫자로 표현한다.
- 도구: Prometheus (수집/저장), Grafana (시각화), CloudWatch, Datadog
- SRE SLO/SLI 관리의 핵심 데이터:
- Latency: 응답 시간 (P50, P90, P99 백분위수)
- Availability: 가용성 (성공 요청 비율)
- Error Rate: 에러율
메트릭 유형
| 유형 | 설명 | 예시 |
|---|---|---|
| System Metrics | 인프라 수준 | Node CPU/Memory, Pod 재시작 횟수 |
| Application Metrics | 서비스 수준 | Request Count, QPS, DB 쿼리 시간 |
| Business Metrics | 비즈니스 수준 | 분당 주문 수, 회원 가입 수, 결제 성공률 |
Metrics는 "무엇이 잘못됐는지"는 알려주지만 "왜 잘못됐는지"는 알려주지 않는다. 그래서 Logs와 Traces가 필요하다.
Logs (로그)
동작의 상태와 이벤트를 기록한 텍스트 데이터다. 특정 시점에 무슨 일이 일어났는지를 상세하게 기록한다.
- 도구: Fluentd/Fluent Bit (수집), Elasticsearch/OpenSearch + Kibana (저장/검색), Loki + Grafana (경량 스택)
구조화 로그(Structured Logging)를 권장하는 이유
비구조화 로그: "2024-01-01 12:00:00 ERROR Payment failed for user 123"
구조화 로그 (JSON):
{
"timestamp": "2024-01-01T12:00:00Z",
"level": "ERROR",
"service": "payment-service",
"message": "Payment failed",
"userId": "123",
"orderId": "456",
"correlationId": "abc-def-ghi",
"errorCode": "INSUFFICIENT_BALANCE"
}구조화 로그는 검색, 필터링, 집계가 쉽다. errorCode = "INSUFFICIENT_BALANCE" 인 로그만 추출하는 것이 자유 텍스트 로그보다 훨씬 간편하다.
Best Practice
- 모든 로그를 표준화된 스키마로 출력
- Correlation ID 필수: 하나의 요청에 고유 ID를 부여하고 모든 서비스의 로그에 포함. 이를 통해 여러 서비스에 걸친 요청 흐름을 추적할 수 있다.
- PII(개인식별정보) 마스킹 필수
Traces (분산 트레이싱)
분산 트레이싱은 마이크로서비스 환경에서 가장 중요한 Observability 요소다. 요청이 여러 서비스를 거치는 전체 경로를 end-to-end로 추적한다.
- 도구: OpenTelemetry (표준 SDK), Jaeger, Zipkin, Tempo
핵심 개념
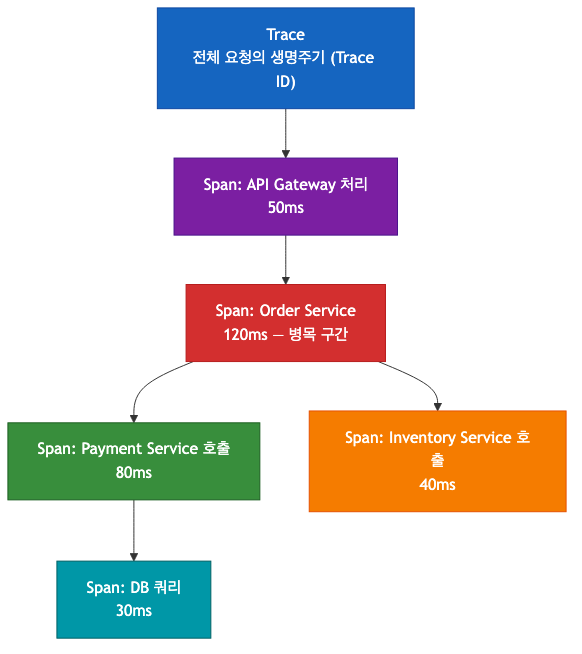
- Trace: 하나의 비즈니스 요청 전체 (Trace ID로 식별)
- Span: 각 서비스/함수에서 처리된 단위 작업 (Span ID로 식별)
- Trace ID: 여러 서비스에 걸친 요청 전체를 연결하는 식별자
- Span ID: 각 구간을 구분하는 식별자
트레이싱으로 "이 요청에서 어느 서비스 구간이 가장 느린가?"를 한눈에 파악할 수 있다. 위 예시에서 Order Service(120ms)가 병목임을 즉시 알 수 있다.
💡 Callout: OpenTelemetry 표준의 중요성
OpenTelemetry(OTel)는 CNCF에서 관리하는 Observability 프레임워크로, Metrics, Logs, Traces를 하나의 통일된 API/SDK로 수집할 수 있게 한다.
OTel 이전에는 Jaeger SDK, Zipkin SDK, Prometheus client 등 각각의 SDK를 사용했다. 나중에 다른 도구로 전환하려면 코드를 전부 수정해야 했다. OTel을 사용하면 앱 코드는 OTel API만 사용하고, 백엔드(Jaeger, Tempo 등)는 설정으로 교체할 수 있다.
Kubernetes에서 OTel 자동 계측(Auto-instrumentation): OpenTelemetry Operator를 사용하면 앱 코드를 수정하지 않고 사이드카 방식으로 트레이싱을 자동 주입할 수 있다.
오늘날 새로운 프로젝트를 시작한다면 Observability SDK는 OpenTelemetry를 기준으로 잡는 것이 사실상 표준이다.
Observability와 SRE의 연계
Observability는 SRE(Site Reliability Engineering)의 핵심 도구다. SRE는 서비스의 신뢰성을 정량적으로 관리하는데, 이를 위해 Observability 데이터가 필요하다.
SRE의 핵심 지표
- SLI (Service Level Indicator): 실제 측정값. 예: "지난 5분간 성공 요청 비율 = 99.5%"
- SLO (Service Level Objective): 목표값. 예: "월간 성공률 99.9% 이상을 목표로 한다"
- Error Budget: SLO와 실제 성능의 차이. "이번 달에 남은 허용 장애 시간 = 43분"
장애 해결의 4단계
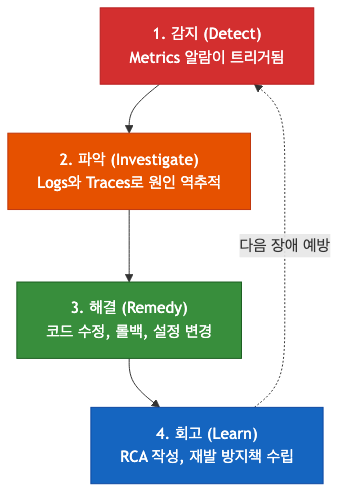
Observability가 없으면 2단계 "파악"에서 막힌다. 장애가 났는데 어디서 왜 났는지 모른다면 해결도 불가능하다.
Observability Best Practice
실전에서 Observability 체계를 구축할 때 따라야 할 원칙들이다.
-
표준화된 로그 + Correlation ID: 모든 서비스가 동일한 로그 스키마를 사용하고, 요청 ID를 반드시 포함한다.
-
모든 서비스에 OpenTelemetry 적용: 특정 벤더 SDK 대신 OTel을 표준으로 사용하면 나중에 백엔드 교체가 자유롭다.
-
Trace Sampling 전략: 모든 요청을 100% 트레이싱하면 오버헤드가 크다. 에러 요청은 100%, 일반 요청은 1~5% 샘플링하는 전략을 사용한다.
-
장애 시나리오 기반 대시보드: "가장 자주 발생하는 장애 패턴"을 중심으로 대시보드를 구성한다. 모든 지표를 다 보여주는 대시보드는 오히려 노이즈다.
-
골든 시그널(Golden Signals) 모니터링: Google SRE에서 제안한 4가지 핵심 지표.
- Latency: 요청 처리 시간 (성공/실패 구분)
- Traffic: 초당 요청 수 (QPS)
- Errors: 에러율 (4xx, 5xx)
- Saturation: 리소스 포화도 (CPU, Memory, Queue 깊이)
-
알람은 "중요한 것"만, SLO 기반으로: 너무 많은 알람은 알람 피로(Alert Fatigue)를 만든다. "이 알람이 오면 즉시 행동이 필요한가?"가 알람 기준이어야 한다.
-
Blackbox + Whitebox 모니터링 병행:
- Blackbox: 외부에서 서비스를 사용자처럼 호출해보는 방식. 실제 사용자 경험과 동일한 관점.
- Whitebox: 내부 메트릭, 로그, 트레이스를 통한 내부 상태 관찰.
-
Kubernetes 메트릭 필수 수집:
kube-state-metrics로 Pod, Deployment, Node 등 클러스터 상태 메트릭을 수집한다.
요약: Observability는 "장애가 생겼을 때 왜 생겼는지 알 수 있는 능력"이다. Metrics로 무엇이 잘못됐는지 감지하고, Logs와 Traces로 왜 잘못됐는지 파악한다. 이 세 가지가 함께 갖춰져야 진짜 Observability다. 클라우드 네이티브 환경에서는 Observability 없이 운영하는 것은 눈 감고 운전하는 것과 같다.
