DL Basics
1-3. Optimization
Introduction
1) 용어의 중요성
"Language is the source of misunderstandings"
-Antoine Saint-Exupe'ry (1900-1944)
- 최적화에서는 여러가지 용어들이 나올 것
- 이 용어들에 대해서 명확히 정의를 짚고 넘어가지 않으면 뒤에 가서 많은 오해가 생길 수 있다.
- 특히 다른 연구자들과 얘기를 할 때, 이 용어들이 통일되지 않으면 큰 문제가 생길 수도 있다.
- 여러 용어들이 나올텐데, 그 용어들에 대해서 명확히 개념을 잡고 넘어가는 게 중요 하다.
2) Gradient Descent
First Order iterative optimization algorithm
for finding a local minimum of a differentiable function
- 우리가 찾고자 하는 파라미터에 대해서, 우리가 가지고 있는 Loss function(=값이 줄어들었을 때 어떤 optimal에 이를 것이라고 기대하는 함수)을 미분한 편미분 값을 이용해서 학습을 하는 방법
Important Concepts in Optimization
1) Generalization
How well the learned model will behave on unseen data.
- 많은 경우에 우리가 높이고자 하는 것은 '일반화 성능'이다.
- 그렇다면 '일반화 성능'은 무엇일까?
- '일반화 성능'을 높이는 게 무조건 좋은 것일까?
- 질문에 답하기 위해서는 '일반화'라는 것이 어떤 의미인지를 알아야 한다.
- 일반적으로 학습을 시키면, 학습 데이터에 대한 Training Error는 계속 줄어들게 된다.
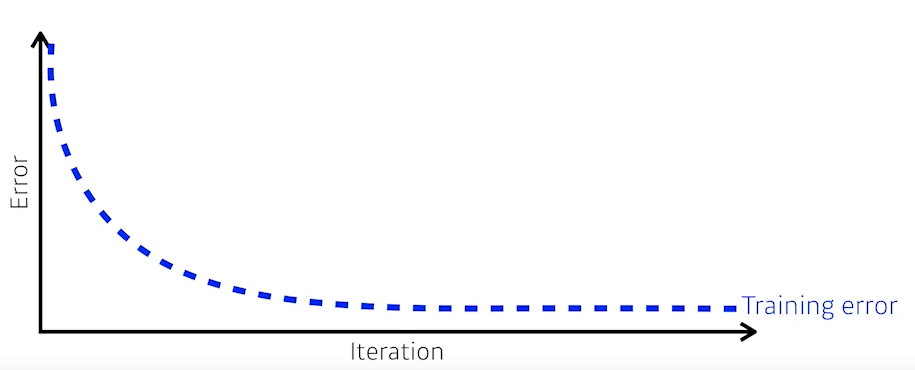
- 하지만 Training Error가 0이 되었다고 해서 항상 우리가 원하는 최적값에 도달했다고 보장할 수는 없다.
- 왜냐하면 일반적으로 Training Error가 줄어들지만, 어느 정도 단계가 지나고 나면 Test Error 즉 우리가 학습에 포함하지 않은 데이터에 대해서는 성능이 오히려 떨어지게 된다.(=Error가 커지게 된다)

- 따라서 generalization performance 라는 것은 일반적으로 Training Error와 Test Error 사이의 차이를 의미한다.
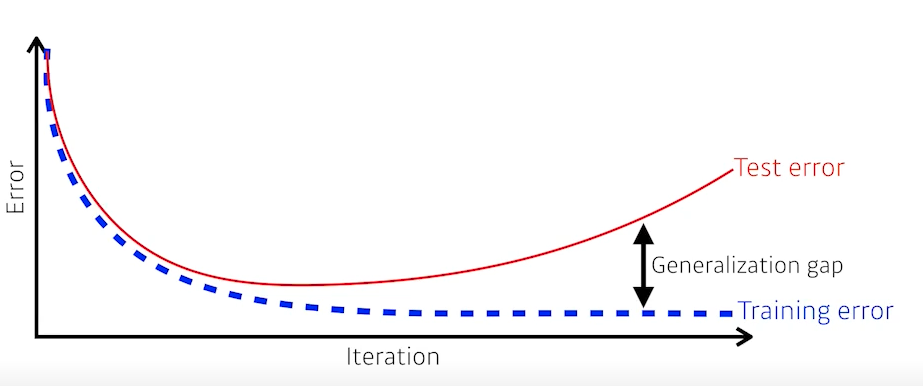
- 즉 'generalization performance가 좋다'는 것은 '이 네트워크의 성능이 학습데이터와 비슷하게 나올 것이라는 보장을 해준다'는 것과 같은 의미이다.
2) Underfitting vs Overfitting
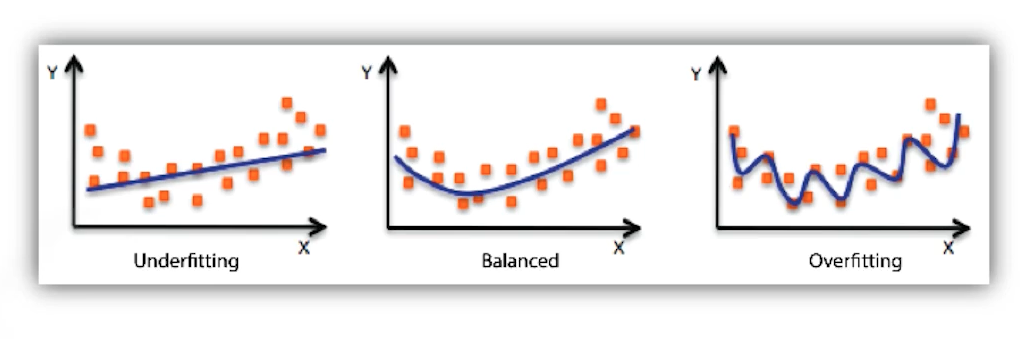
- 앞서 말한 경우와 같이, 학습데이터에 대해서는 잘 동작하지만, 테스트 데이터에 대해서는 잘 동작하지 않는 현상을 Overfitting이라고 한다.
- 반대로 네트워크가 너무 간단하거나 Trainig을 너무 조금해서 학습데이터에 대한 성능도 잘 안나오는 경우를 Underfitting이라고 한다.
- 그리고 그 중간 어딘가에 sweet spot인 Balanced 단계가 있다.
3) Cross-Validation
- 그래서 일반적으로는 Train data와 Validation data를 나눠서 학습 데이터를 주는 경우가 많다.
- 즉 학습데이터로 학습된 모델이 학습에 사용되지 않은 Validation data 기준으로 얼마나 잘 되는 지를 보는 것이다.
- 그러면 Train data와 Validation data는 얼만큼으로 나누는 것이 좋을까?
- 절반씩 나눠서 학습을 시키고 절반은 Validation할 때 사용하게 되면, Validation은 잘 될 수 있지만 학습 데이터 자체가 너무 적기 때문에 모델 자체가 학습이 덜 될 수도 있다.
- 이런 문제를 해결하기 위해 나온 아이디어가 cross validation(혹은 k-fold validation)이다.
- cross validation에서는 학습데이터를 k개로 나누고, 그 중 k-1개로 학습을 시키고 1개를 validation data로 사용한다.
- 예를 들어 10만개의 데이터가 있으면, 5-fold validation의 경우 2만개씩 5개로 데이터를 나눈다. 그 뒤 처음 학습할 때에는 1번부터 4번 세트까지 8만개 데이터로 학습을 시키고 5번 세트를 validation data로 사용했다면, 두 번째 학습할 때에는 1, 2, 3, 5번 세트를 학습 데이터로 사용하고 4번 세트를 validation data로 사용할 수 있다.
- 이렇게 하면 validation도 적절히 할 수 있을 뿐만 아니라, 더 많은 데이터로 모델을 학습할 수 있다.
- test data는 학습에 어떤 방법으로든 사용되어서는 안된다. test data를 사용하는 것은 그 자체로 치팅 행위이다.
4) Bias and Variance
- 우리가 총을 쏘거나 활을 쐈을 때, 항상 같은 곳(그게 원점이 아니라도)에만 찍히면 전체적으로 원점으로만 옮기면 되기 때문에 좋은 결과를 얻어낼 가능성이 높다.
- Variance는 이렇게 비슷한 입력을 넣었을 때, 출력이 얼마나 일관적으로 나오는지를 의미한다. Variance가 낮을수록 일관성이 높다.
- 반대로 Variance가 낮은 경우에는 입력에 따른 출력이 일관되지 않기 때문에 overfitting될 가능성이 높음을 의미한다.
- Bias는 평균적으로 봤을 때 true target에 가깝다면 Bias가 낮다고 하고, 평균이 원하는 target 값과 멀다면 Bias가 높다고 한다.
- Bias and Variance Tradeoff
- costs를 최소화 한다는 것은 bias를 minimize하는 것과, variance를 minimize하는 것, 그리고 noise term이 세가지로 이루어져 있다.
- 그래서 bias를 줄이면 variance가 높아질 가능성이 있고, variance를 줄이면 bias가 높아질 수 있다.
We can derive that what we are minimizing (cost) can be decomposed into three different parts
: bias2, variance, and noise.
5) Bootstrapping
Bootstrapping is any test or metric that uses random sampling with replacement.
- 학습 데이터가 고정되어 있을 때,
그 안에서 sub-sampling을 통해서 학습 데이터를 여러개를 만들고,
그걸 가지고 여러 모델 또는 여러 metric을 만들어서 학습을 하는 방법을 bootstrapping이라 한다.
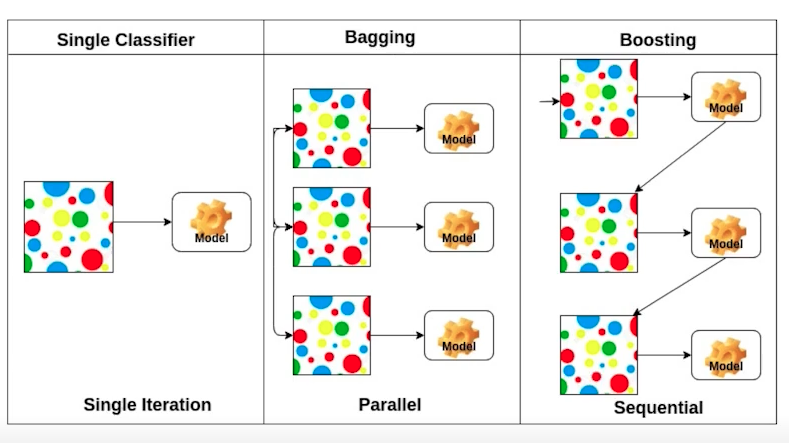
6) Bagging vs Boosting
-
Bagging(Bootstrapping appregating)
Multiple models are being trained with bootstrapping.
- ex. Base classifiers are fitted on random subset where individual predictions are aggregated.(voting or averageing)
- 즉 random sub-sampling을 통해서 학습 데이터를 여러 개 만들고, 여러 모델이나 metric을 가지고 output을 내서 그 output을 평균을 내는 방법이다.
- 학습 데이터를 다 사용해서 하나의 모델로 결과를 내는 게 더 좋을 것 같지만 사실 그렇진 않다.
- 오히려 n개의 모델을 만든 다음에 어떤 test 입력이 들어왔을 때 이 n개의 모델을 모두 돌려보고, 이 돌려본 값들의 평균이나 voting을 통해서 나온 출력값을 쓰는 게 한 개의 모델을 쓰는 것보다 더 좋은 성능을 내는 경우가 더 많다.
- 그래서 kaggle같은 대회를 풀 때 가장 기본적으로 활용하는 테크닉이 앙상블인데 이 앙상블이 bagging인 경우가 많다.
-
Boosting
It focuses on those specific training samples that are hard to classify.
A strong model is built by combining weak learners in sequence where each learner learns from the mistakes of the previous weak learner.
- 즉 우리가 학습 데이터가 100개가 있으면, 이 중에서 sequential하게 바라봐서 모델 하나를 간단한 걸 만들고, 이 모델을 학습 데이터에 대해서 다 돌려본다.
- 그러면 모델이 간단하기 때문에, 예를 들어 80개에 대해서는 잘 예측을 하지만 20개에 대해서는 잘 예측을 하지 못할 수도 있다.
- 그 때 두 번째 모델을 하나 더 만드는데, 이 모델은 20개 잘 안되는 데이터에 대해서만 잘 동작하게 만든다.
- 이런 식으로 여러개의 모델을 만들어서 모델을 합치는 것을 boosting이라고 한다.
- 또한 합칠 때, 여러 개의 모델을 독립적인 모델로 n개의 결과를 뽑는 게 아니라, 하나 하나의 모델들(weak learner)을 sequential하게 합쳐서 하나의 strong learner를 만드는 방식이다.(각각의 weak learner들의 weight를 찾는 형식으로 정보를 추합하게 된다.)
-
Bagging과 Boosting을 비교하면 다음과 같다.
7) Gradient Descent Methods : Batch Size
-
Stochastic Gradient Descent
Update with the gradient computed from a single sample.
-
Mini-batch Gradient Descent
Update with the gradient computed from a subset of data.
-
Batch Gradient Descent
Update with the gradient computed from the whole data.
-
Batch-Size Matters
- Batch size가 그렇게 중요해 보이지 않을 수 있지만 사실은 batch size가 되게 중요하다.
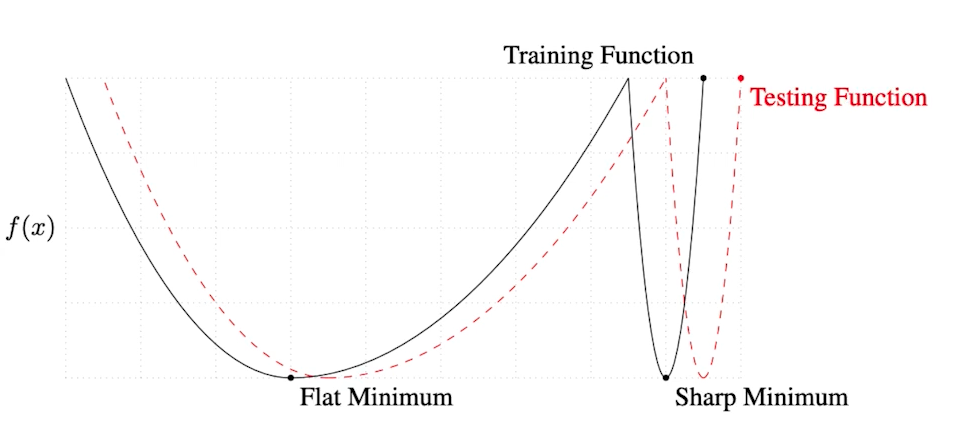
- On Large-batch Training for Deep Learning : Generalization Gap ans Sharp Minima, 2017
- Batch size는 학습에 있어 중요한 요소이다.
- Batch size를 작게 쓰는 게 일반적으로 성능이 더 좋다는 것을 실험적으로 말하고자 함
- 즉 Sharp minimizer 보다는 flat minimizer에 도달하는 것이 더 좋다.
- 왜냐하면, flat minimizer는 training에서 test가 약간 멀어져도 성능이 어느 정도 유지된다. (=generalization performance가 좋다.)
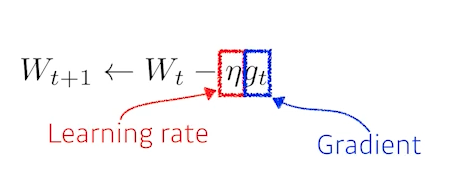
Gradient Descent Methods
1) Stochastic gradient descent
- 가장 기본적인 방식
- learning rate을 설정하기가 너무 어렵다.
(lr이 너무 크면 학습이 잘못될 수 있고, 너무 작으면 학습이 잘 안 된다.) - 따라서 똑같이 gradient information만 활용해도 더 좋은 성능, 혹은 더 빨리 학습을 시켜주기 위한 optimization 테크닉들이 제안됨.
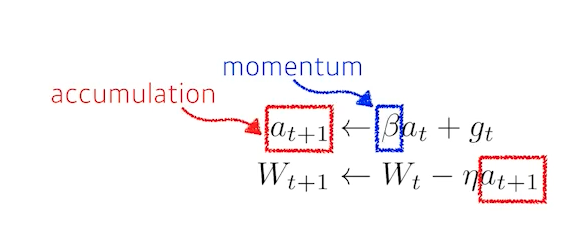
2) Momentum
- 흘러 가던 방향에 대한 가중치(momentum)를 gradient에 더해서 업데이트
- 한 번 흘러가기 시작한 방향으로 어느 정도 유지시켜주기 때문에, gradient가 굉장히 많이 왔다갔다 해도 어느 정도 잘 학습이 되는 효과가 있다.
3) Nerterov accelerated gradient
- gradient를 계산할 때 look ahead gradient를 계산
- momentum과 gradient를 사용하는 것은 이전과 동일하지만,
이 방법에서는 먼저 업데이트 하려던 결과를 미리 가보고 그곳에서 gradient를 계산 한 것을 가지고 accumulation을 한다. - 이 경우 momentum(관성)으로 인해 local minima로 수렴을 못하는 문제를 방지해서 좀 더 빨리 수렴할 수 있게 해준다.
- 이론적으로 들어가면 converging ratio가 빠르다는 것도 증명할 수 있다.
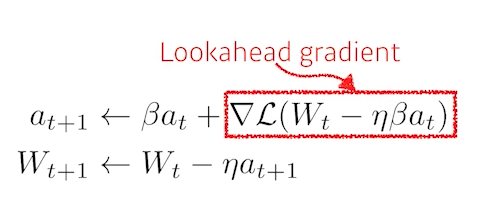
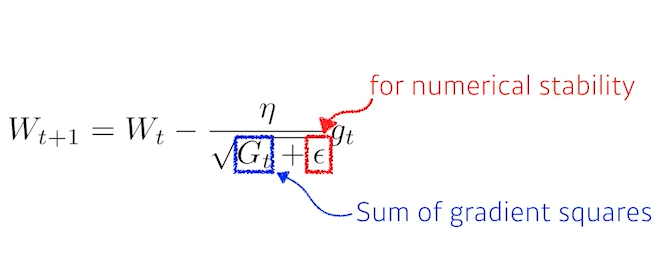
4) Adagrad
Adagrad adapts the learning rate, performing larger updates for infrequent and smaller updates for frequent parameters.
- 파라미터가 지금까지 얼만큼 변해왔는지/안 변해왔는지를 보고,
많이 변했던 파라미터는 적게 변화시키고,
적게 변했던 되었던 파라미터는 많이 변화시키도록 learning rate를 조절하는 방법 - 파라미터가 얼만큼 변해왔는지에 대한 정보를 Gt에 저장한다. Gt는 업데이트가 될수록 계속 커지기 때문에, 역수에 집어 넣어서 많이 변했을수록 적게 변화시킬 수 있다.
- 다만 학습이 오래되면 Gt가 거의 무한대로 커지기 때문에 뒤로 갈수록 학습이 멈춰지는 문제가 생긴다.이런 문제를 해결하고자 뒤의 방법론들이 나왔다.
5) Adadelta
Adadelta extends Adagrad to reduce its monotonically decreasing the learning rate by restricting the accumulation window.
- Adagrad의 문제를 막을 수 있는 가장 쉬운 방법은 현재 time step t가 주어졌을 때, 전체가 아닌 window size 만큼의 시간에 대한 파라미터 변화를 보는 것이다.
- 하지만 이 경우에도 window size를 예를 들어 100으로 잡으면
이전 100개 동안의 G라는 정보를 들고 있어야 한다. - 파라미터가 천억개라고 하면, 천억개의 파라미터마다 100개씩 정보를 갖고 있어야 하고, 그러면 GPU가 터져버린다..ㅎ
- 이런 문제를 막을 수 있는 방법으로 Exponential Moving Average(이하 EMA)를 사용한다.
- 즉 이전 값에 를 곱해주고, 만큼의 gradient(의 제곱)을 더해주게 되면 time window 만큼의 평균값을 가지고 있다고 볼 수 있다.
- Adadelta는 learning rate이 없고 바꿀 수 있는 파라미터가 많이 없기 때문에 잘 사용하지 않는다.

6) RMSprop
RMSprop is an unpublished, adaptive learning rate method proposed by Geoff Hinton in his lecture.
- 논문을 통해서 제안된 방법은 아니고, Geoff Hinton이 강의에서 제안한 방식이다.
- Adadelta처럼 Gradient squares를 EMA를 사용해서 구해주고, 업데이트 부분에서 분자에 stepsize만 추가해준 방법이다.
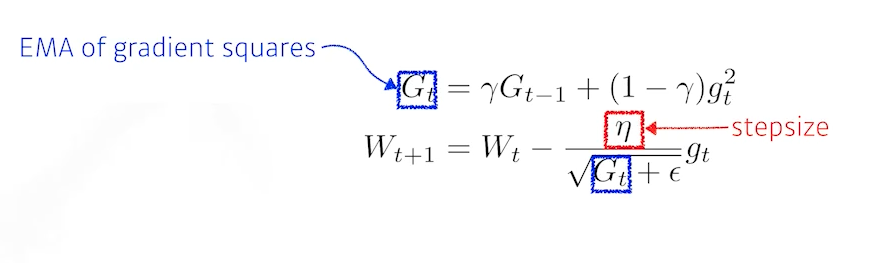
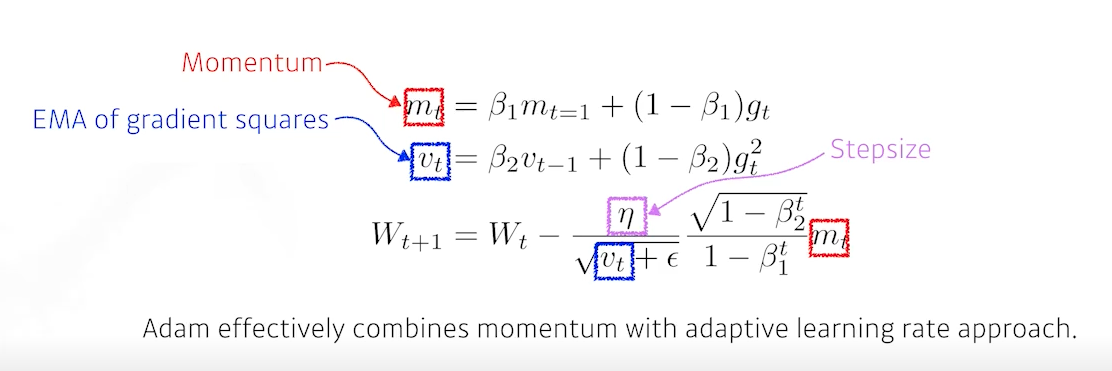
7) Adam(Adaptive Moment Estimation)
Adaptive Moment Estimation(Adam) leverages both past gradients and square gradients.
-
일반적으로 가장 잘된다고 하고, 가장 무난하게 사용하는 방식
-
gradient squares를 EMA로 가져감과 동시에 momentum을 같이 활용하는 방식
-
하이퍼 파라미터는 4개로, 다음과 같다.
- momentum을 얼마나 유지시킬지에 대한 1
- gradient squares에 대한 EMA 정보를 얼마나 유지할지에 대한 2
- learning rate인
- 분모가 0이 되는 것을 방지하는
-
이 4개의 하이퍼 파라미터를 조정하는 것도 매우 중요하다.
Regularization
- Generalization을 잘 되게 하기 위해 학습에 반대되도록 무언가 규제를 거는 방법
- 방법론이 학습 데이터 뿐만 아니라 테스트 데이터에도 잘 동작하도록 만들어 주는 방식
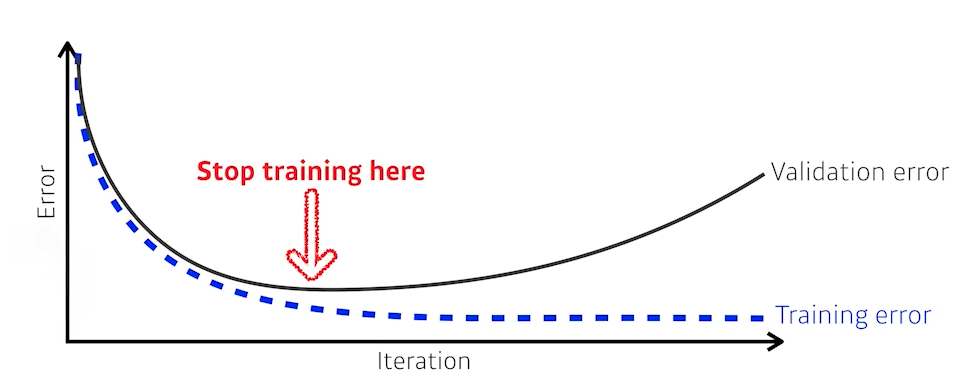
1) Early Stopping
- 학습을 중간에 멈추게 하는 방법
- 테스트 데이터는 학습에 사용할 수 없기 때문에,
학습에 활용되지 않은 validation data를 이용하여 loss를 평가해보고,
그 loss가 커지는 시점 전에 학습을 멈추게 한다. - train data 외에 추가적인 validation data 필요
2) Parameter Norm Penalty(or Weight Decay)
Adds smoothness to the function space.
- 파라미터가 너무 커지지 않게 제한하는 방법
- 네트워크 파라미터 값을 다 제곱해서 더해서 나온 숫자를 loss와 같이 줄인다.
- 이왕이면 네트워크 학습할 때 네트워크 파라미터의 절댓값이 작으면 작을수록 좋다.
- 물리적이거나 해석적인 의미 : 네트워크가 만들어내는 어떤 함수 공간(function space) 속에서 이 함수를 최대한 부드러운 함수로 보자. 부드러운 함수일수록 generalization performance가 높을 것이다.

3) Data Augmentation
- 딥러닝, 머신러닝에서 가장 중요한 것 중 하나가 바로 데이터이다.
- 데이터가 무한히 많으면 웬만하면 다 잘된다..ㅎ
- 문제는 데이터의 양이 한정적이기 때문에,
가지고 있는 데이터를 약간씩 바꿔서 데이터 양을 늘리는 방법이 바로
data augmentation이다.- 예를 들어, 강아지 사진이 있을 때, 강아지 사진을 돌리거나 좌우로 뒤집어도 강아지 사진인 것은 변하지 않기 때문에 돌리기나 뒤집기로 데이터 양을 늘릴 수 있다.
- 단, data augmentation은 변환을 했을 때에도 label이 바뀌지 않는다는 조건 하에 진행해야 한다.
- 예를 들어, mnist data에서 6을 위아래로 뒤집으면 9가되어 버리기 때문에 label이 바뀐다. 이 경우에서는 뒤집는 변환을 하면 안된다.
4) Noise Robustness
- 입력 데이터나 뉴럴 네트워크 weight에 노이즈를 집어 넣어서 성능을 올리고자 하는 방법
- 학습 시킬 떄 네크워크의 weight를 매번 흔들어주면 성능이 더 잘 나온다는 실험적인 결과가 있다.
- 사실 이게 왜 잘되는지에 대해서는 약간 의문이 있는 것 같긴하다.

5) Label Smoothing
-
Data Augmentation과 비슷한데, 굳이 차이점을 말하자면 Label smoothing은 데이터 2개를 뽑아서 섞어주는 방식이다.
-
우리가 일반적으로 분류 문제를 푼다고 하면, 가지고 있는 이미지들이 존재하는 공간 속에서 각 클래스들을 잘 구분할 수 있는 decision boundary를 찾고 싶은 것이다.
-
Label smoothing은 이 decision boundary를 약간 부드럽게 만들어주는 효과가 있다.
-
Mix-up과 CutMix가 있다.
Mix-up constructs augmented training examples by mixing both input and output of two randomly selected trainig data.
CutMix constructs augmented training examples by mixing inputs with cut and paste and outputs with soft labels of two randomly selected training data.

-
사용하면 성능이 진짜 많이 올라간다. 들이는 시간 대비 성능이 많이 올라가기 때문에 활용하기를 추천!
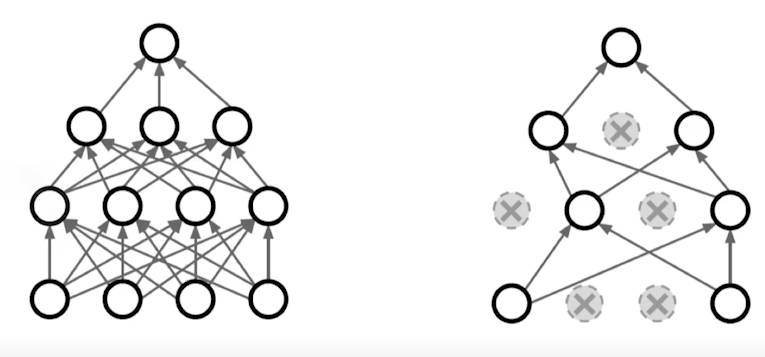
6) Dropout
In each forward pass, randomly set some neurons to zero.
- 뉴럴 네크워크의 일부 weight을 0으로 바꾸는 방법
- droupout ratio가 0.5라고 하면, 뉴럴 네트워크가 inference를 할 때에는 레이어마다 50%의 파라미터를 0으로 바꿔준다.
- dropout을 사용하면 각각의 뉴런들이 조금 더 robust한 feature까지 잡을 수 있다고 해석이 된다.
7) Batch Normalization
Batch Normalization comput the empirical mean and variance independently for each dimension(layers) and normalize.
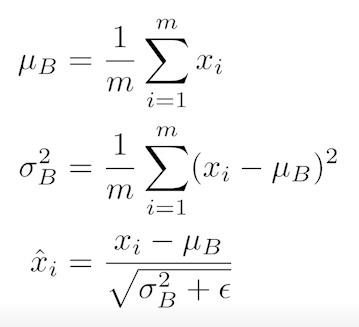
- Batch Normalization을 적용하고자 하는 레이어의 statistics를 정규화시키는 것 방법
- 뉴럴 네트워크 각각의 레이어의 statistics가 평균 0, 분산 1이 되게 만드는 것
- Batch Normalization 소개 논문에서는 이 방법이 internal covariate(feature) shift를 줄인다고 하는데, 다른 논문들에서는 동의하지는 않음
- 하지만 batch normalization을 활용하게 되면 일반적으로, 특히 레이어가 깊에 쌓아지게 되면 성능이 올라간다.
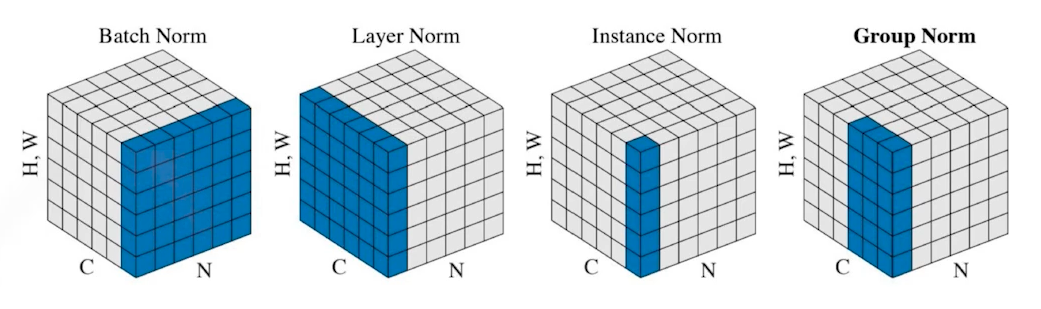
- 비슷한 맥락으로 layer norm, instance norm, group norm 방식도 있다.
질문과 회고
- SGD와 Momentum은 왜 차이가 날까?
- Momentum은 이전의 gradient를 활용
- SGD만 갖고 하면 많은 iteration이 있어야 전체 데이터를 포괄하는 gradient를 찾을 수 있는데, momentum은 이전의 gradient 정보를 활요하기 때문에 SGD보다 데이터를 많이 보는 효과가 있다.
- 거기에 Adam은 파라미터 별로 learning rate 조절까지 하기 때문에 훨씬 더 빨리 최적의 값에 수렴할 수 있다.
- Relu는 0에서 미분이 안되는데, 0값이 나오면 어떻게 처리하는지?
- 왜 batch size 작으면 flatten minimum에 가고, 크면 sharp minimum에 도달하는지?
- np.random.seed(9779) 파라미터의 역할이 무엇이고, seed를 왜 써야 하는지?
