NLP Intro & Word Embedding
1. Academic disciplines related to NLP
1) Natural Language Processing (Major Conferences : ACL, EMNLP, NAACL)
- Includes state-of-art deep learning-based models and tasks
- Low-level parsing
- Tokenization : 문장을 일정 단위로 분리(단어 단위로 할 수도 있고, 형태소 단위로 할 수도 있음)
- stemming : 어근 추출
- Word and phrase level
- Named entity recognition(NER) : 고유 명사 인식
- part-of-speech(POS) tagging : 형태소 분석
- noun-phrase chunking : 명사구 단위로 분리하기
- dependency parsing : 의존성 분석, 문장에 존재하는 개별 단어 간 의존 또는 수식 방향으로 관계를 파악하여 문장 구조를 분석(한국어처럼 어순이 비교적 자유로운 언어에서 사용하기 좋음)
- coreference resolution: 임의의 개체(entity)를 표현하는 다양한 단어(표현 방법)들을 찾아 연결해주는 task(같은 대상을 별명, 약어, 대명사 등으로 표현한 것들에 대한 참조 관계를 찾기)
- Sentence Level
- Sentiment analysis : 감정 분석
- machine translation : 기계 번역
- Multi-sentence and paragraph level
- Entailment prediction : 논리적인 내포, 모순 관계 예측
- Question answering : 독해 기반 질의응답
- Dialog systems : 챗봇
- Summarization : 요약
2) Text mining (Major Conferences : KDD, The WebConf(formely, WWW), WSDM, CIKM, ICWSM)
- Extract useful information and insights from text and document data
- Document clustering(e.g.topic modeling)
- Highly related to computational social science
3) Information retrieval(Major Conferences: SIGIR, WSDM, CIKM, RecSys)
- Highly related to computational social science
- 구글, 네이버 등의 검색 기술을 의미
- 이미 많이 성숙해진 분야이기 때문에 연구가 활발히 일어나는 분야는 아님
- 하지만 추천시스템과 결합된 검색 기술 분야는 아직도 활발히 연구되고 있음
2. Bag of Words
1) Bag of words representation
-
Step 1: 문장으로부터 Vocabulary를 만든다. 이 때 Vocabulary 안의 단어들은 중복되지 않고 문장에 한 번 이상 나타난다. (Constructing the Vocabulary contating unique words)

-
Step 2: Vocabulary의 단어들을 각각의 one-hot 벡터로 encoding 한다.

- 각 단어들 간의 유클리디안 거리는
- 각 단어들 간의 cosine similarity는 0 (단어가 무엇이든지 상관없이)
-
이 때 문장은 단어들의 one-hot 벡터들의 합으로 표현된다.
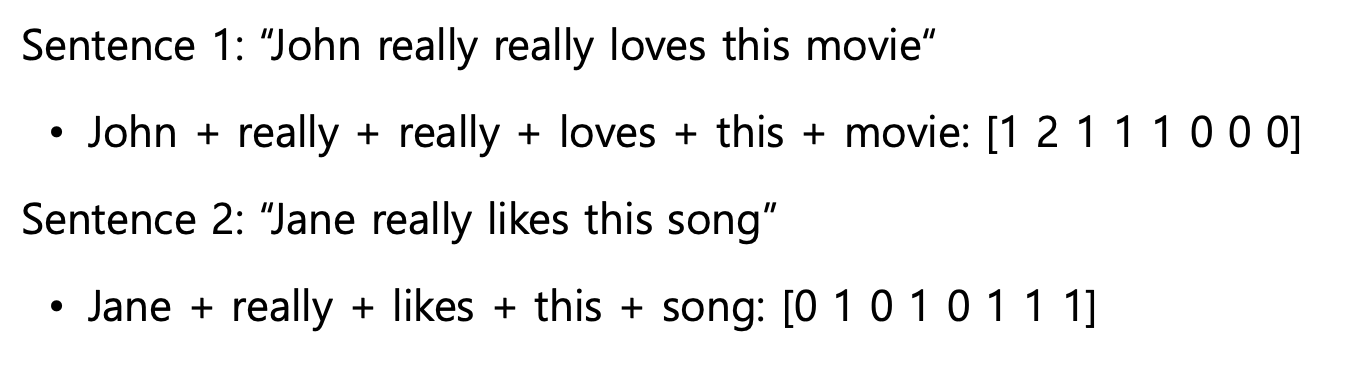
2) NaiveBayes Classifier for Document Classification
- 문서를 보고 이 문서가 NLP에 대한 내용인지 CV에 대한 내용인지를 판단하는 classification task를 한다고 생각해보자.
- Bag of Words에서는 NaiveBayes Classifier를 이용해 이를 수행할 수 있다.
- 문서를 d, 문서의 종류(class)를 c라 하자.
- 이 때 문서가 주어졌을 때 가장 가능성이 높은 class에 대해 수식을 표현하면 다음과 같다.
(MAP(Maximum a Posteriori) : 사후확률을 최대화하는 class)

- 위 수식은 Bayes Rule에 의해 다음과 같이 정리될 수 있다.
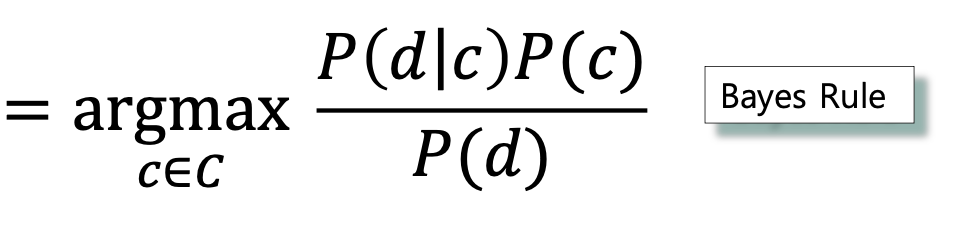
- 이 때 주어진 문서는 고정되어 있으므로 P(d)는 상수이다. 따라서 는 P(d)에 상관없이 결정된다.
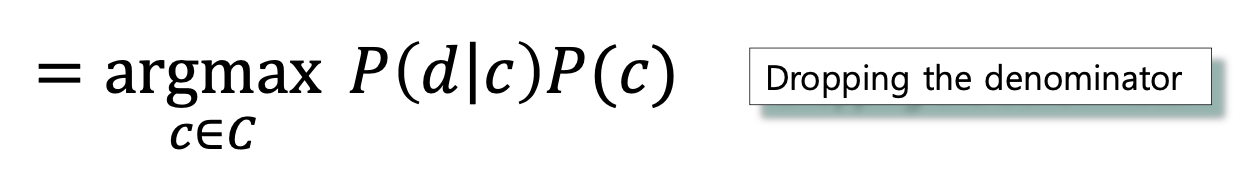
- 여기에서 문서(d)의 모든 단어들이 서로 독립이라고 가정하면, 위의 식은 클래스가 주어졌을 때 각 단어들의 출현 확률의 곱과 P(c)의 곱으로 표현될 수 있다.(Bag of words는 모든 단어가 서로 독립)
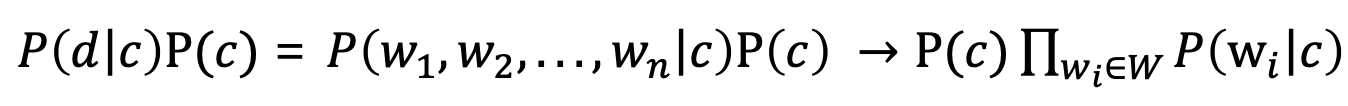
- 예시

- ( training 문장 4개 중 2개가 cv 문장)
- ( training 문장 4개 중 2개가 nlp 문장)
- 이므로,
(는 topic이 인 문서에서 가 등장한 횟수, n은 topic이 인 문서의 전체 단어 수)
각 단어에 대해 를 구하면 다음 표와 같이 구할 수 있다.
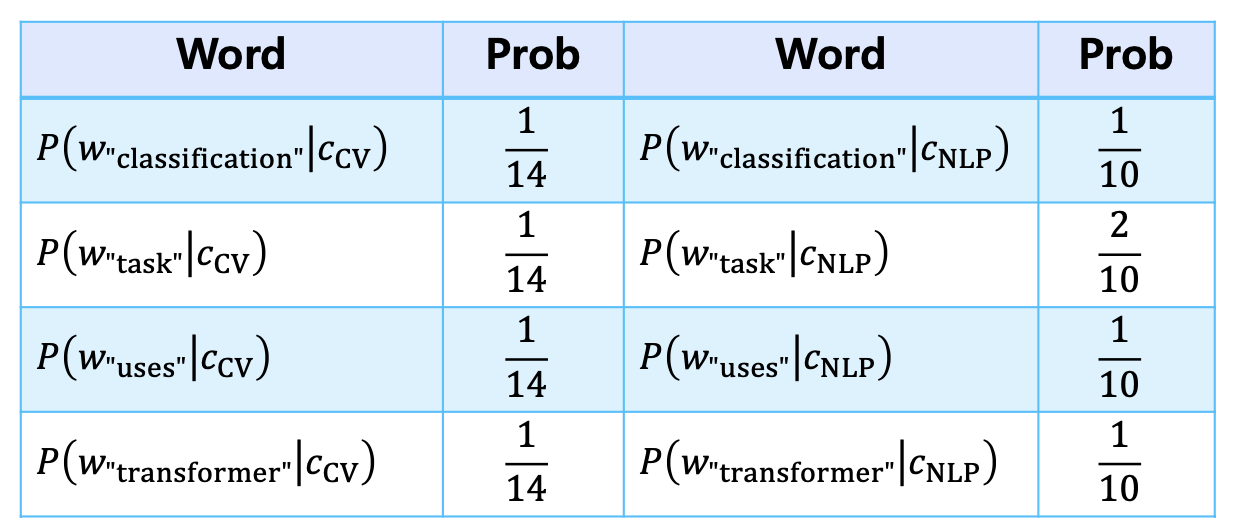
- 따라서 test 문서가 cv에 대한 문서일 확률과 nlp에 관한 문서일 확률을 각각 구하면 다음과 같다.
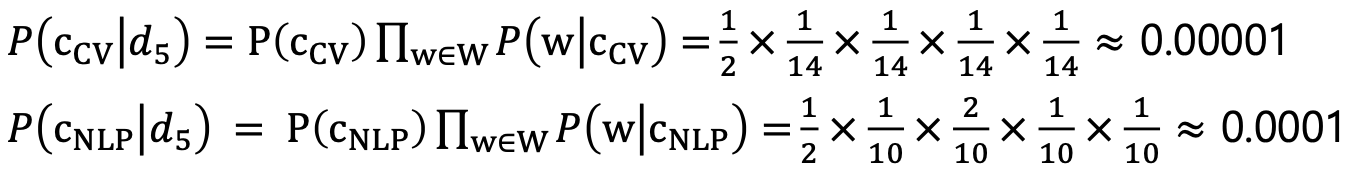
- 여기에서는 문서가 nlp에 관한 것일 확률이 더 높다.
- 계산 과정에서 눈치 챌수 있겠지만, 이러한 방식은 test 문서에 train 문서에는 없는 단어가 나오면 확률이 0이 되어버리는 문제가 있고, 문장이 길어서 단어 수가 많을수록 확률이 낮아지는 문제가 있다.
3) one-hot encoding의 한계
- 모든 단어를 독립적으로 보고 단어의 개수 만큼 벡터 차원을 정해서 one-hot vector를 만드는 것은 가장 쉬운 방법이지만 한계가 존재한다.
- 단어의 개수가 늘어날 수록, 벡터를 저장하기 위해 필요한 공간이 계속 늘어난다
- 단어의 유사도를 표현하지 못한다. 모든 단어가 서로 완전히 다른 의미를 가지고 있다고 가정하기 때문에, 유의어 등을 표현하지 못한다.
- 따라서 이러한 한계를 보완하기 위한 encoding 방식들이 후에 등장한다.
3. Word Embedding : Word2Vec, Glove
1) What is Word Embedding?
- 단어를 벡터로 표현하는 것
- 'cat'과 'kitty'는 비슷한 단어이기 때문에, 이렇게 유사한 단어들은 벡터 공간에서 가까운 위치에 있게 하고 싶다.
- 'hamburger'와 'cat'은 거의 연관성이 없기 때문에, 이러한 경우 벡터 공간에서 멀리 떨어뜨려 놓고 싶다.
2) Word2Vec
- 인접한 단어들은 벡터 공간에서 가까이 표현되도록 vector representation을 학습하는 방법
- 가정 : 유사한 문맥에 있는 단어들은 유사한 의미를 가질 것이다.
- Idea of Word2Vec
- 예) 'cat'과 인접한 단어들에 대해 'cat'과의 유사도를 높이고자 한다면,
'cat'을 입력으로 넣어서 주변 단어들을 예측하게 하고, 예측값과 실제 주변 단어와의 차이를 loss로 두어 학습한다.
- 예) 'cat'과 인접한 단어들에 대해 'cat'과의 유사도를 높이고자 한다면,
- How Word2Vec Algorithm Works
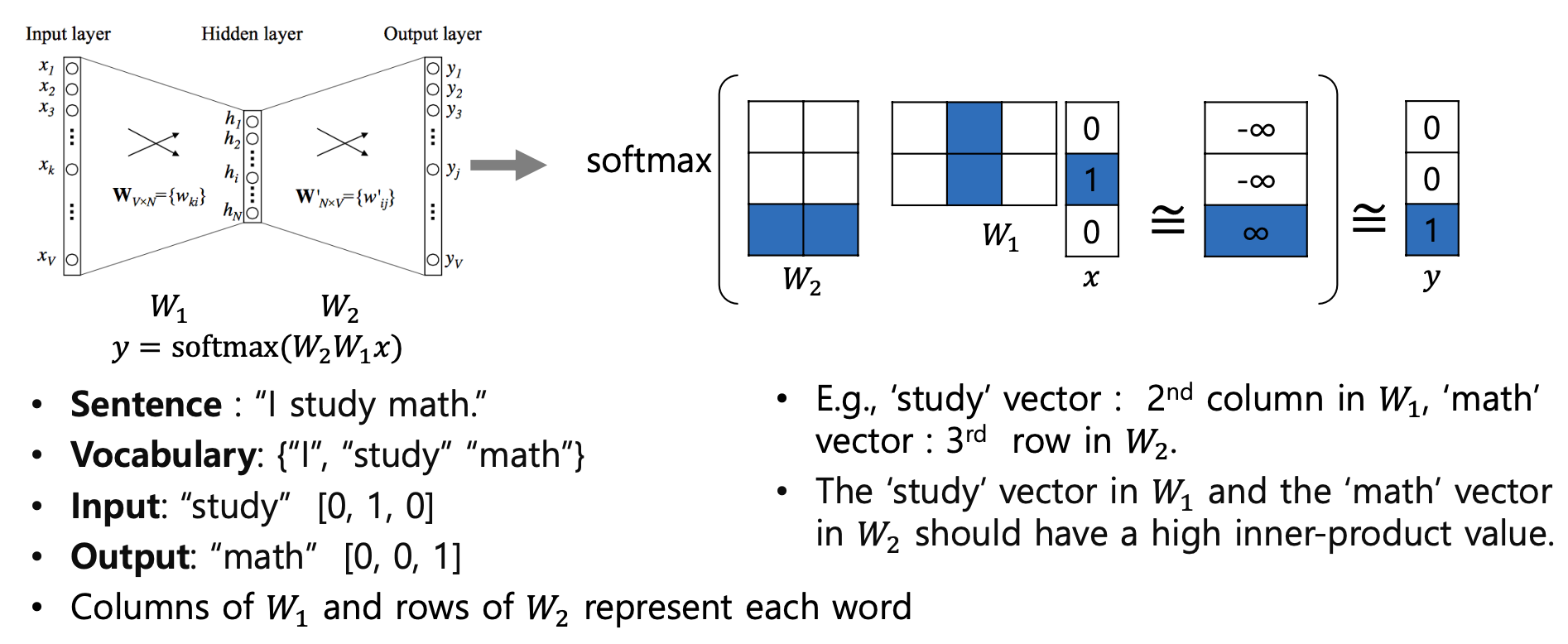
-
'I study math'라는 문장 사이에서 인접한 단어는 높은 유사도를 가지도록 vector representation을 학습해보자
-
먼저 인접한 단어쌍을 만든다.
- window = 3이라하면 자기 자신 포함 3개의 단어를 보는 것을 의미한다.
- 예시에서 인접한 단어쌍(window=3일 때) : (I, study) / (study, I), (study, math) / (math, study)
-
단어쌍 중에서 (study, math) 쌍을 예시로 보자. study와 math는 인접해 있으므로, study을 입력으로 넣으면 주변 단어로 math를 예측할 수 있도록 학습하면 된다.
-
이 때 를 보면, 는 one-hot vector이므로 는 사실상 one-hot vector 의 1의 위치에 해당되는 의 column만 가져온 결과와 같다.
-
즉 그림에서도 최종적으로는 와 의 두번째 column을 곱한 벡터가 나오고, 여기에 softmax를 취해주면 logit vector가 나온다.
-
마지막으로 결과로 나온 logit vector와 정답인 'math'의 one-hot vector를 비교하여 업데이트한다.
-
- Word2Vec은 대부분의 NLP task에서 성능을 높이는 데 도움을 준다.
- Word similarity
- Machine translation
- Part-of-speech (PoS) tagging
- Named entity recognition (NER)
- Sentiment analysis
- Clustering
- Semantic lexicon building
3) GloVe: Global Vectors for Word Representation
- 인접한 단어 쌍을 만들어서 단어를 집어 넣어 주변 단어를 예측하는 Word2Vec과 달리,
GloVe에서는 먼저 각 단어들 사이의 co-occurence matrix(동시 등장 행렬)를 먼저 만들고, 여기에 log 씌운 값을 ground truth로 사용한다.- 예를 들어 다음과 같은 문장이 있을 때,
- I like deep learning
- I like NLP
- I enjoy flying
co-occurance matrix는 다음과 같다.(window는 3으로 가정, window size 정의가 다 다른가..?)
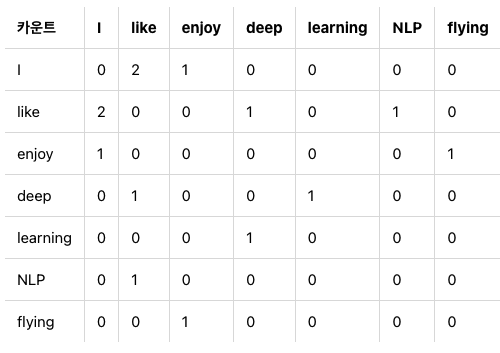
- 예를 들어 다음과 같은 문장이 있을 때,
- 이러한 방식을 통해 중복 계산을 줄여주기 때문에 Word2Vec보다 학습 속도가 빠르고 작은 데이터셋에서도 잘 동작한다.
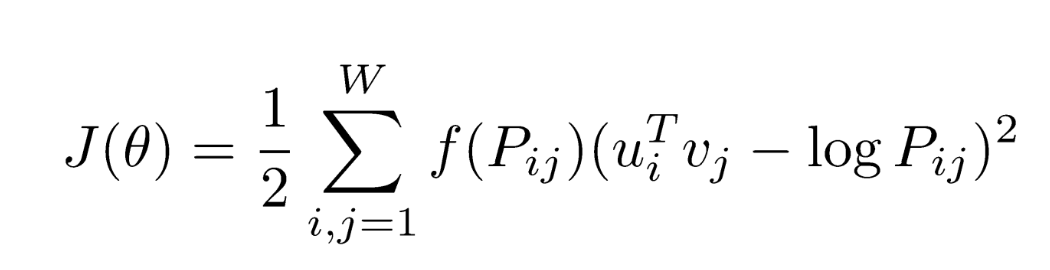
- 여기에서 f는 weighting function을 의미하며, 여기서 는 위 식에서 와 같다.
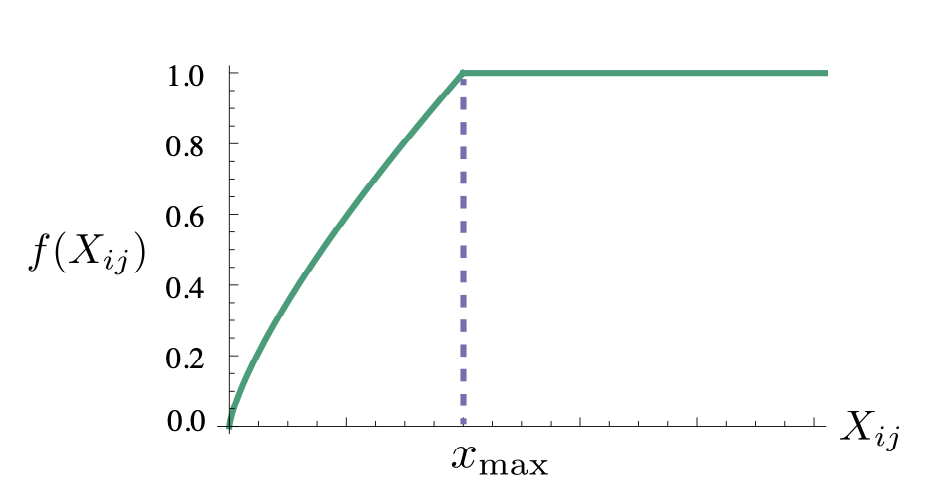
- co-occurence matrix는 많은 값이 0이거나, 동시 등장 빈도가 적어서 많은 값이 작은 수치를 가지는 경우가 많다. 즉 희소 행렬(Sparse Matrix)일 가능성이 다분하다.
- GloVe의 연구진은 동시 등장 행렬에서 co-occurence matrix의 값이 굉장히 낮은 경우에는 정보에 거의 도움이 되지 않는다고 판단하였고, 그래서 이에 대한 가중치를 주기 위해 값에 영향을 받는 가중치 함수(Weighting function)를 손실 함수에 도입하였다.
- 가중치 함수(Weighting function)는 의 값이 작으면 상대적으로 함수의 값은 작도록 하고, 값이 크면 함수의 값은 상대적으로 크도록 한다. 하지만 가 지나치게 높다고해서 지나친 가중치를 주지 않기위해서 또한 함수의 최대값이 정해져 있다. (최대값은 1) 예를 들어 'It is'와 같은 불용어의 동시 등장 빈도수가 높다고해서 지나친 가중을 받아서는 안 된다.
- 이 함수의 값을 손실 함수에 곱해주면 가중치의 역할을 할 수 있다.
4. 참고 자료, 추가 자료
- Word2Vec
- 논문 : Distributed Representations of Words and Phrases and their Compositionality, NeurIPS’13
- Wevi: word embedding visual inspector : https://ronxin.github.io/wevi/
- Word intrusion detection : https://github.com/dhammack/Word2VecExample
- Analogy Reasoning : http://wonjaekim.com/archives/50
- Korean Word2Vec : http://w.elnn.kr/search
- Wikidocs, Word2Vec : https://wikidocs.net/22660
- 관련 블로그 : https://dreamgonfly.github.io/blog/word2vec-explained/
- GloVe
- 논문 : GloVe: Global Vectors for Word Representation, EMNLP’14
- Glove code and Pretrained Model : https://nlp.stanford.edu/projects/glove/
- Wikidocs, Glove : https://wikidocs.net/22885

유쾌하게, 열정적으로, 진심을 다해