RNN, LSTM, GRU
* 모든 사진 자료의 저작권은 네이버 부스트코스에 있습니다.
1. RNN
1) Sequential Model
- Sequential Model은 Sequential한, 즉 순서가 존재하는 데이터에서 다음 데이터를 예측하는 모델이다.
- Sequential 데이터는 순서가 존재한다. 즉 뒤에 오는 데이터가 이전 데이터에 의존적이다.
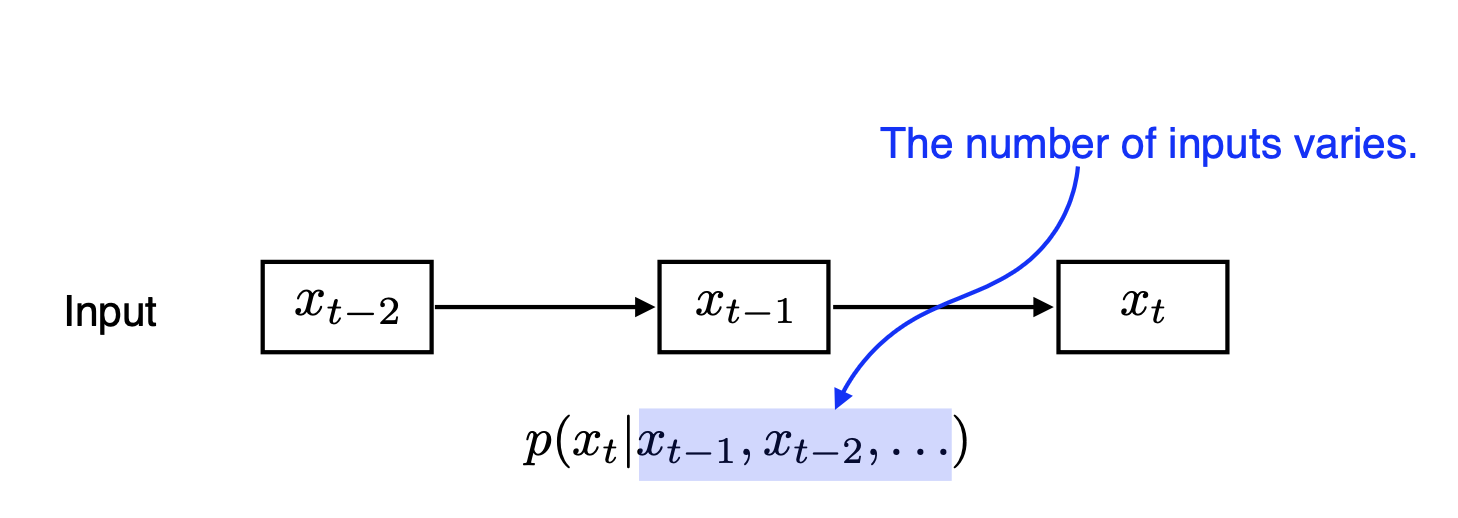
(독립적이지 않다.) - 따라서 Naive sequential model의 경우 생기는 가장 큰 문제점은 input 데이터의 길이가 계속 달라진다는 것이다.
정확히 말하면, 현재 시점의 데이터는 시작 시점부터 이전 시점까지의 데이터들을 기반으로 예측되고,
다음 시점의 데이터는 시작 시점부터 현재 시점까지의 데이터를 기반으로 예측한다. 즉 미래로 갈수록 데이터가 계속 쌓이고, 길이가 길어진다. - 그렇기 때문에 Sequential Model은 다른 모델처럼 input의 크기를 고정할 수 없다는 문제가 있었다.
2) Auto Regressive Model
- 그러면 과거 데이터를 다 보지말고 지금으로부터 개 전까지의 데이터만 보면 어떨까?
그러면 input으로 넣는 길이를 고정할 수 있을 것이다.
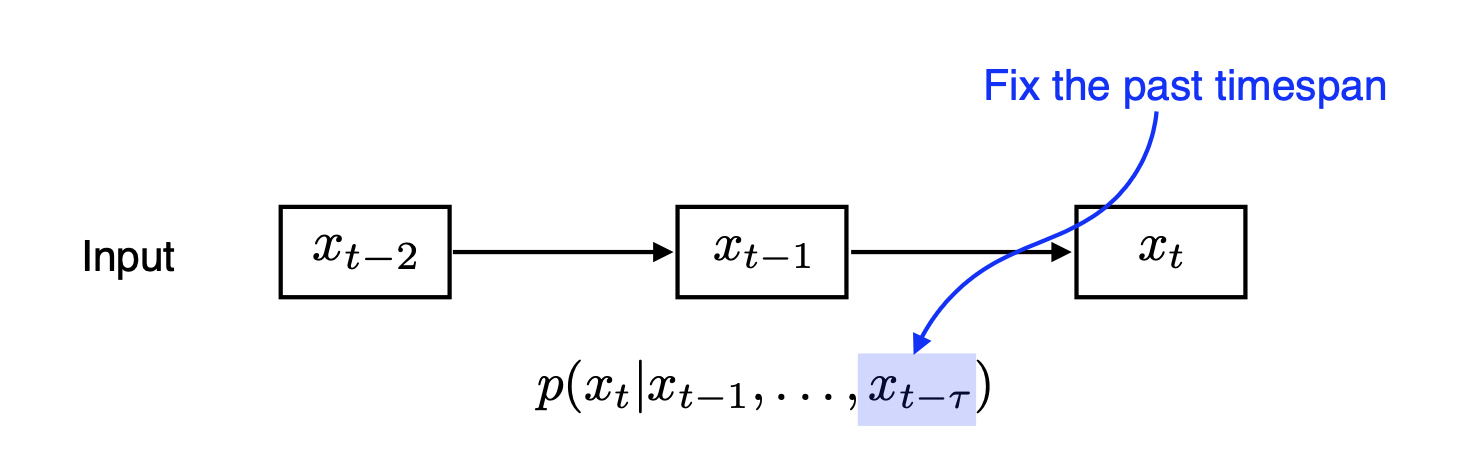
- 참고로 이러한 아이디어에서 가 1인, 즉 바로 전 데이터 한 개만 보는 모델이 Markov Model이다. Markov 가정을 바탕으로 joint distribution을 표현하면 수식 표현이 훨씬 쉬워지는 것을 알 수 있다.(Markov Model은 Generative Model에서 많이 활용한다.)
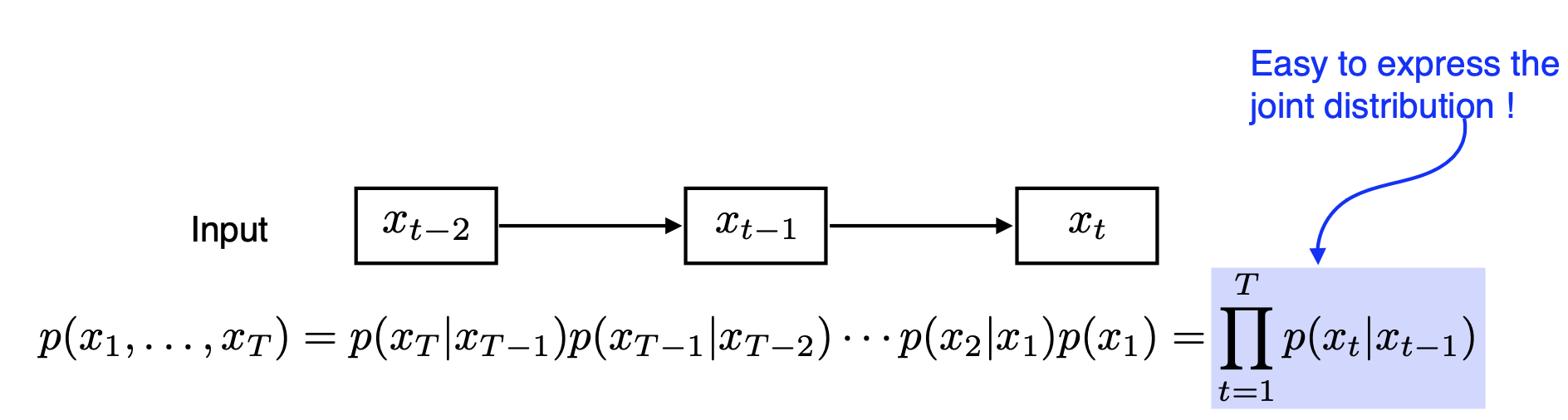
- 이렇게 과거의 일부만 보는 방식은 input의 크기를 고정할 수 있고, joint distribution을 쉽게 표현할 수 있다는 장점이 있다. 하지만 우리가 선택한 과거보다 더 과거의 정보가 중요함에도 그 정보가 버려질 수 있고, 바로 가까운 과거 정보에만 의존하는 문제가 발생할 수 있다.
3) Latent Auto Regressive Model
- 그래서 나온 아이디어가 바로 과거의 정보를 압축해서 하나의 데이터로 받는 것이고, 이를 latent autoregressive model이라고 한다.
(우리가 여러 파일을 압축해서 하나의 파일로 받듯이!)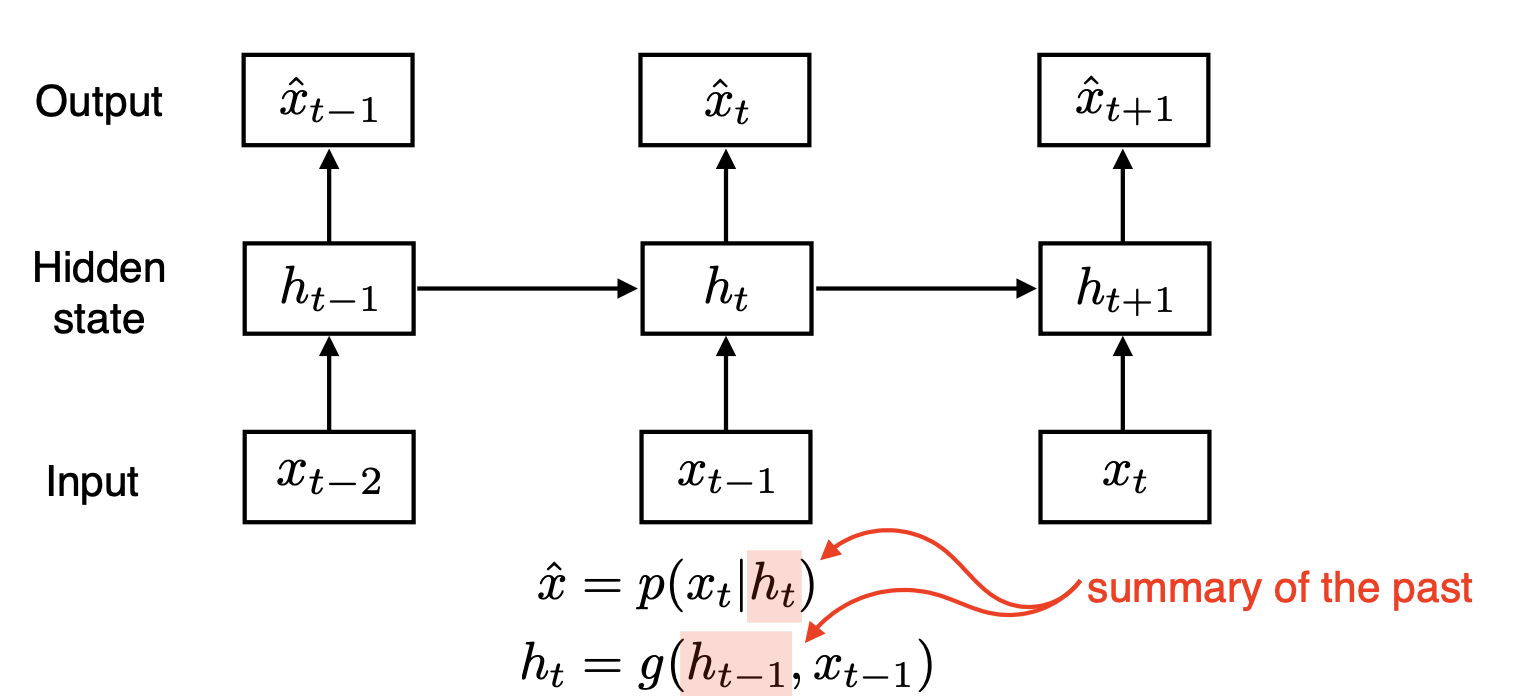
4) RNN 소개
- RNN은 Latent Auto Regressive Model로, 현재의 input 값(x)과 과거 데이터 압축 정보(h)를 받아서 다음 output값을 예측하는 모델이다. 그리고 예측된 output값은 현재 데이터와 과거 데이터 압축정보를 모두 가지고 있으며, 다음 단계로 다시 전달된다.(위의 그림 참고)
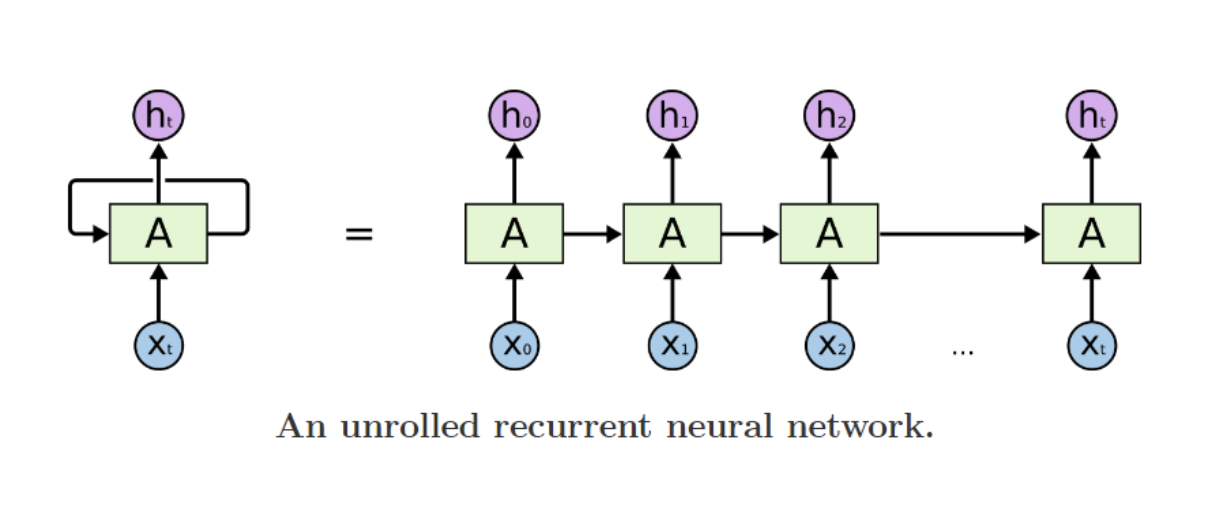
- NLP에서 자연어 또한 어순과 문맥 등이 중요한 Sequential 데이터이기 때문에, RNN 기반 모델을 많이 이용했다(Transformer 전까지)
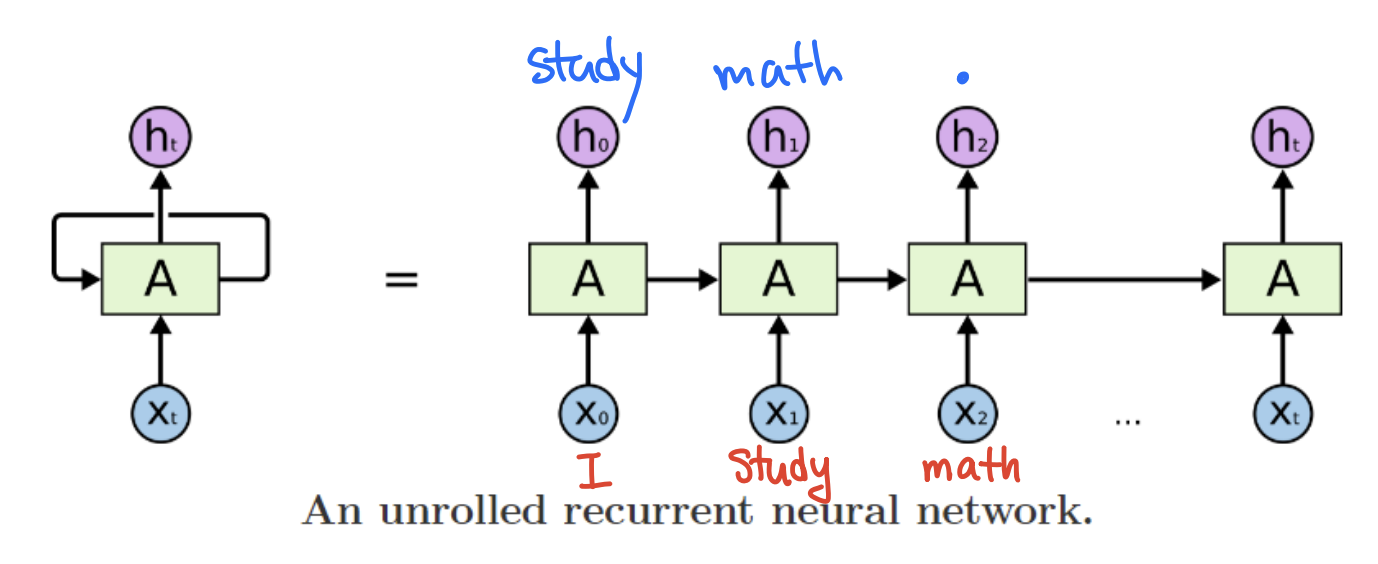
- 예를 들어 "I"를 집어 넣고 계속 다음 단어를 예측해 "I study math."라는 문장을 만들고 싶다면,
차례대로 "I"를 input으로 넣으면 다음 단어로 "study"를 내뱉고, "study"를 넣으면 다음 단어인 "math"를 내뱉고, "math"를 넣으면 다음 문자인 "."를 내뱉도록 모델을 구현할 수 있다.
5) RNN Hidden states 계산하기
-
RNN을 구성하는 요소(벡터)들은 다음과 같다.

- 현재 time step을 t라고 하면, 은 이전 hidden-state vector로 과거 정보들을 가지고 있다.
- 는 현재 time step에 들어오는 input vector이다.
- 는 현재 time step에서 내뱉는 사실상 output vector이다. 는 과거 정보와 현재 input의 정보를 합쳐서 input으로 받는 친구이다. 즉 와 를 합쳐서(concat) 선형변환()을 한 결과이다.
- 마지막으로 는 우리가 보고자 하는 결과값으로, 를 원하는 형태로 지지고 볶아서(?) 나오는 결과이다.
task에 따라 매 time step 마다 나오기도 하고 마지막 time step에만 나오기도 한다.
(예시. 품사예측 - 단어마다 예측해야 하므로 매 time step마다 결과가 나옴 /
문장 긍정, 부정 판단 - 문장이 끝나는 time step에서만 결과가 나오면 됨)
-
RNN에서 중요한 점은, 매 time step 마다 같은 함수와 같은 파라미터를 사용한다는 것이다. 즉 하나의 linear transform matrix만 사용되며 매 time step은 파라미터를 공유한다.
-
hidden states 계산과 파라미터 수를 더 자세히 생각해보자.
- embedding vector 의 차원을 3, 의 차원을 2라고 생각하자.
(를 input vector로 이해해도 되지만,
엄밀히 말하면 input vector에서 embedding과정을 한 번 거친 벡터를 말한다) - 먼저 와 를 concat한다(아래 그림에서 가장 오른쪽 부분) -> 그렇게 concat한 벡터는 차원이 5
- 이 concat한 벡터에 linear tranformation을 적용해서 차원을 만들어준다.
-> 차원도 2이므로 linear transform matrix(W)의 차원은 (2 x 5) - 여기에서 W를 각각 와 에 대해 쪼개서 생각하면,
에는 가 적용되고(초록색 글씨) 에는 가 적용되는 것이고, 위에처럼 한 번에 계산하는 것은 이 둘을 더한 것과 같다. - 그 뒤 계산된 +에 non-linear activation인 tanh를 씌우면 이 된다.
- 마지막으로 는 를 linear transform() 해서 만들 수 있다.
- 여기에서 bias가 없다고 하면 모델의 파라미터 수(제외)는 transform matrix(W)의 차원 수(10)와 동일하다.
(는 원하는 output 형태에 따라 다르므로 고려하지 않았다. output 형태도 알면 총 파라미터 수를 구할 수 있다.)

- embedding vector 의 차원을 3, 의 차원을 2라고 생각하자.
6) Type of RNNs
-
RNN은 input과 output의 개수와 출력 시점에 따라 크게 5종류가 있다.
-
one to one
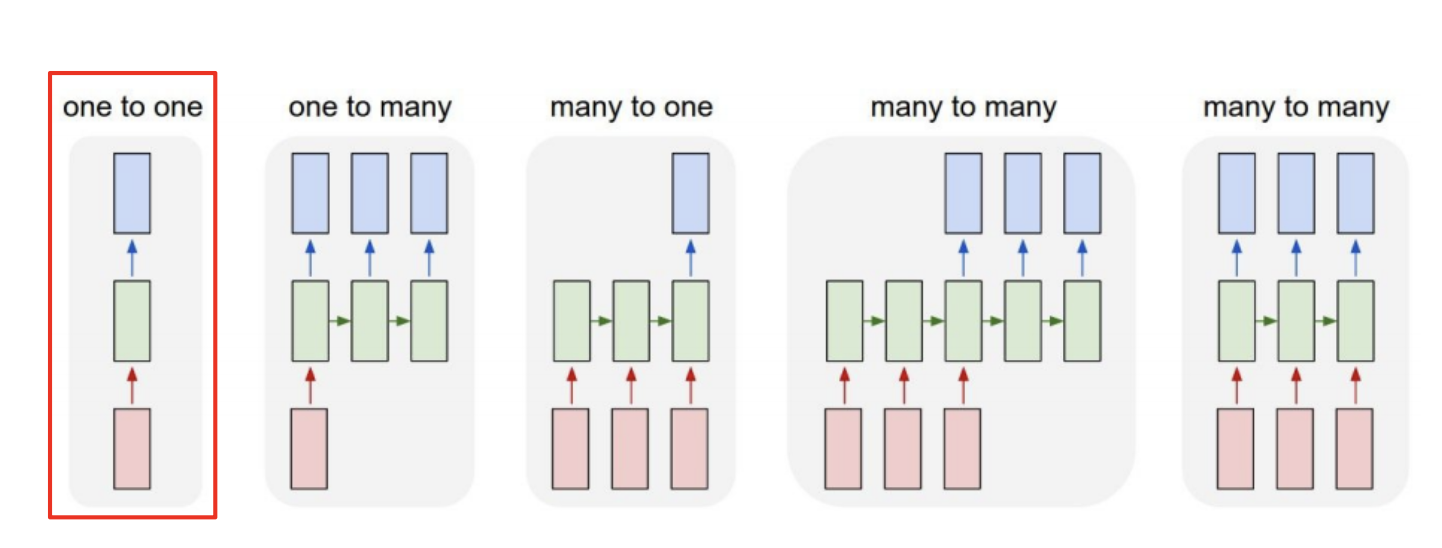
- input 하나, output 하나
- 사실상 sequence가 아닌 형태
- 그냥 기본 input, output 형식. time step도 아님
-
one to many
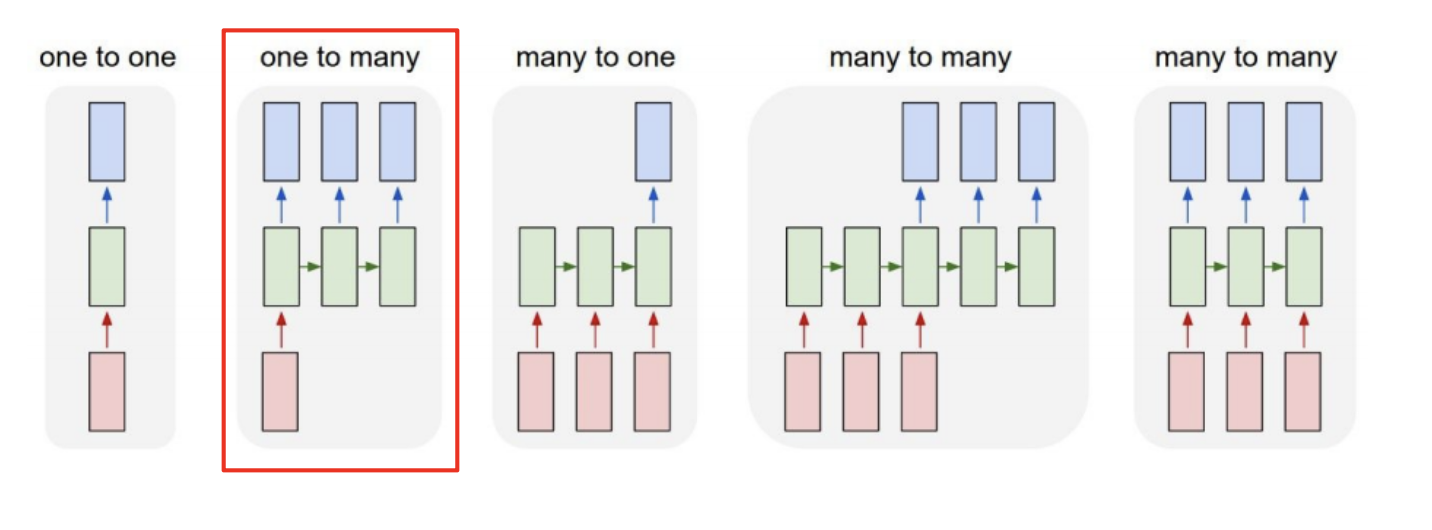
- input 하나 output 여러 개
- 예시 ) 이미지를 input으로 넣으면 이미지에 대한 설명글이 나오는 모델
- 처음에 이미지를 넣고 나서 다음 sequence에는 0으로 채워진 텐서를 input으로 넣는다.
-> (그래도 괜찮나..?)
-
many to one

- input 여러개 output 하나
- 예시) 문장을 넣고 그 문장의 긍정/부정 판단
-
many to many(input 먼저 output 나중)
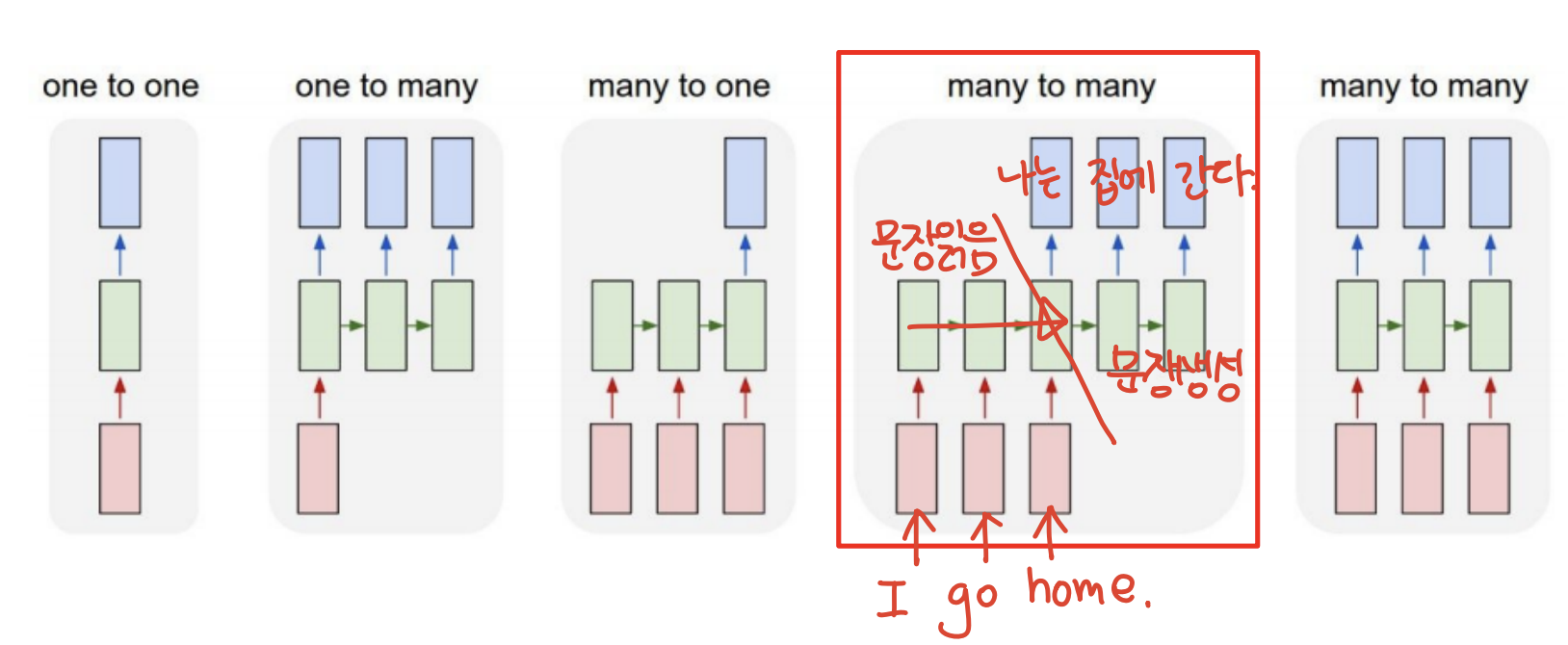
- input 여러개 output 여러개
- input을 차례로 받고 나서 output 차례로 내보냄
- 예시) 기계 번역
- 질문 ) 기계 번역은 동시에 하면 안되나..? -> 문맥을 고려해서 번역해야 하므로 먼저 input 받고 하는 것 같다..(나는 차를 마시고 그녀에게 차였다.) transformer를 보면 입력 출력이 두 개로 분리가 되는 것 자체가 장점인 것 같기도 하다
-
many to many(input과 output 동시에)
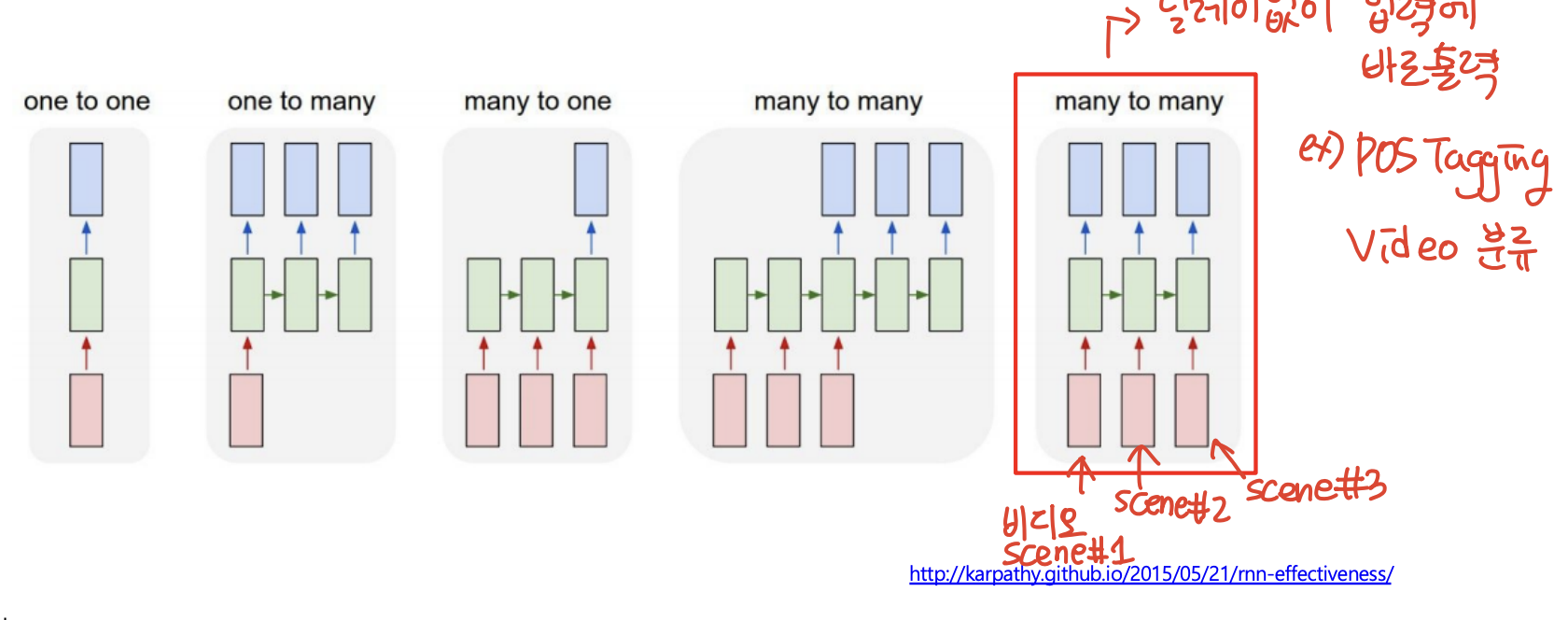
- input 여러개 output 여러개
- 딜레이 없이 넣으면 바로 출력
- 예시) 품사 분석, POS Tagging, Video scene 분류하기
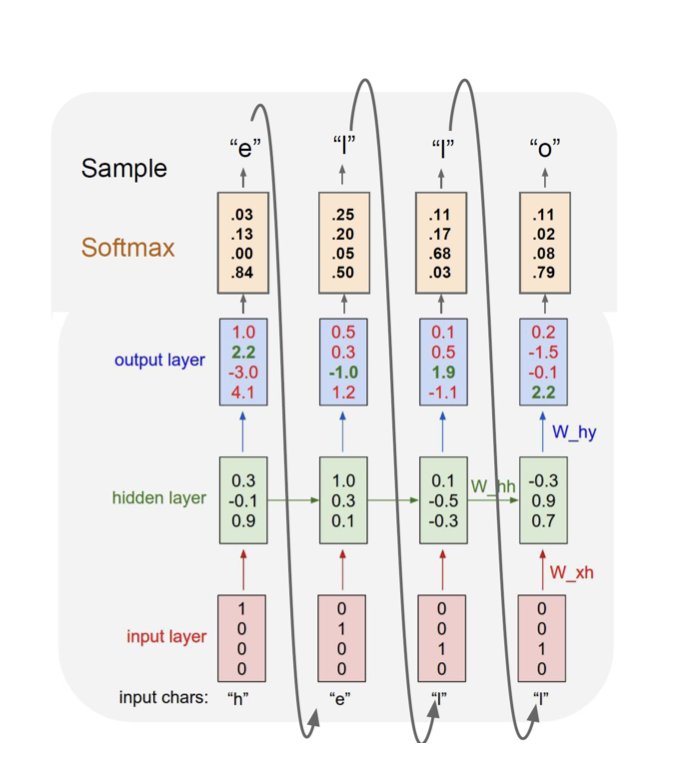
7) Character-level language Model
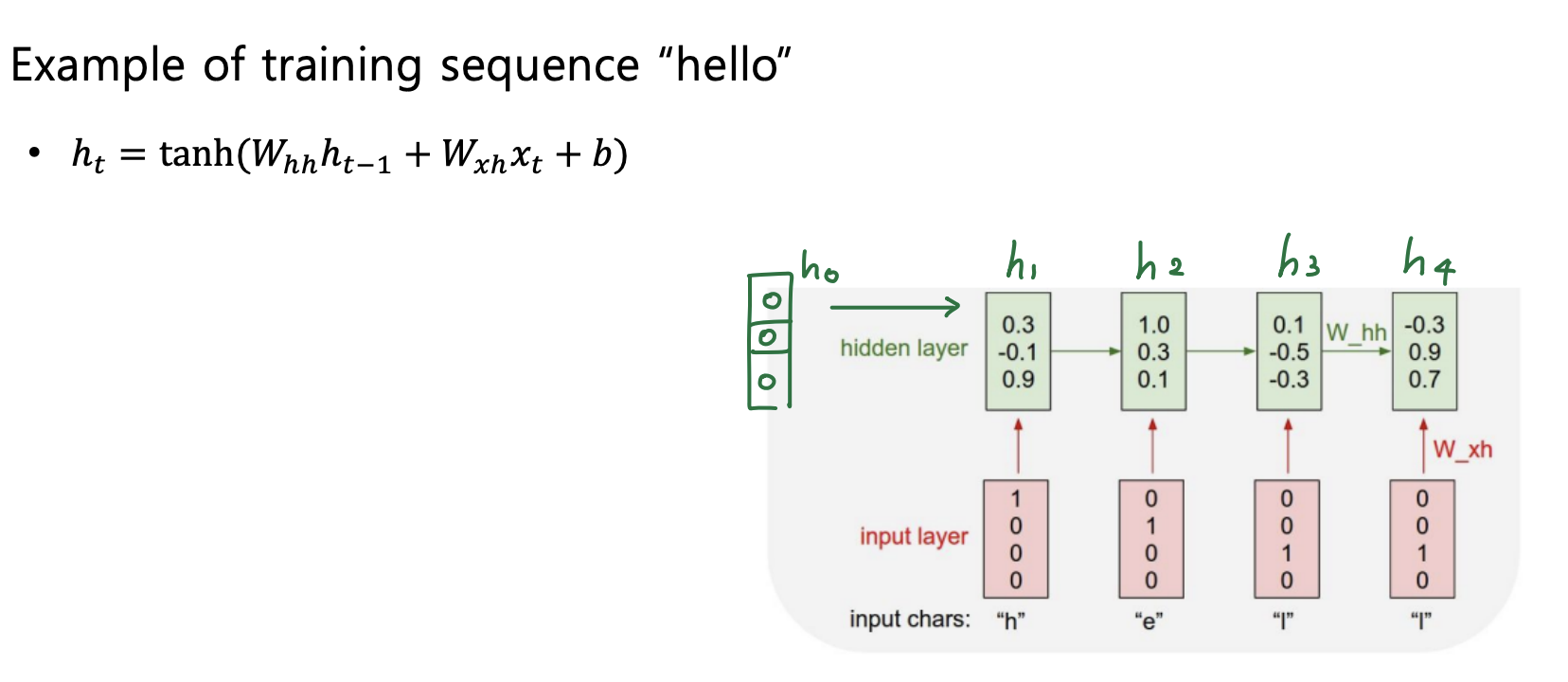
- 단어가 아닌 문자 단위로 Language Model을 구축한다고 생각해보자.
- "hello"가 있으면 -> Vocabulary : [h, e, l, o]
- "hello"를 가지고 학습한다고 생각하면,
- "h"가 들어가면 "e"가 나오고, "e"가 들어가면 "ㅣ"가 나오고...이런식으로 다음 문자를 예측한다.
- 참고로 처음에는 이전 hidden state이 없기 때문에 0으로 채워진 hidden vector를 hidden state로 사용한다.
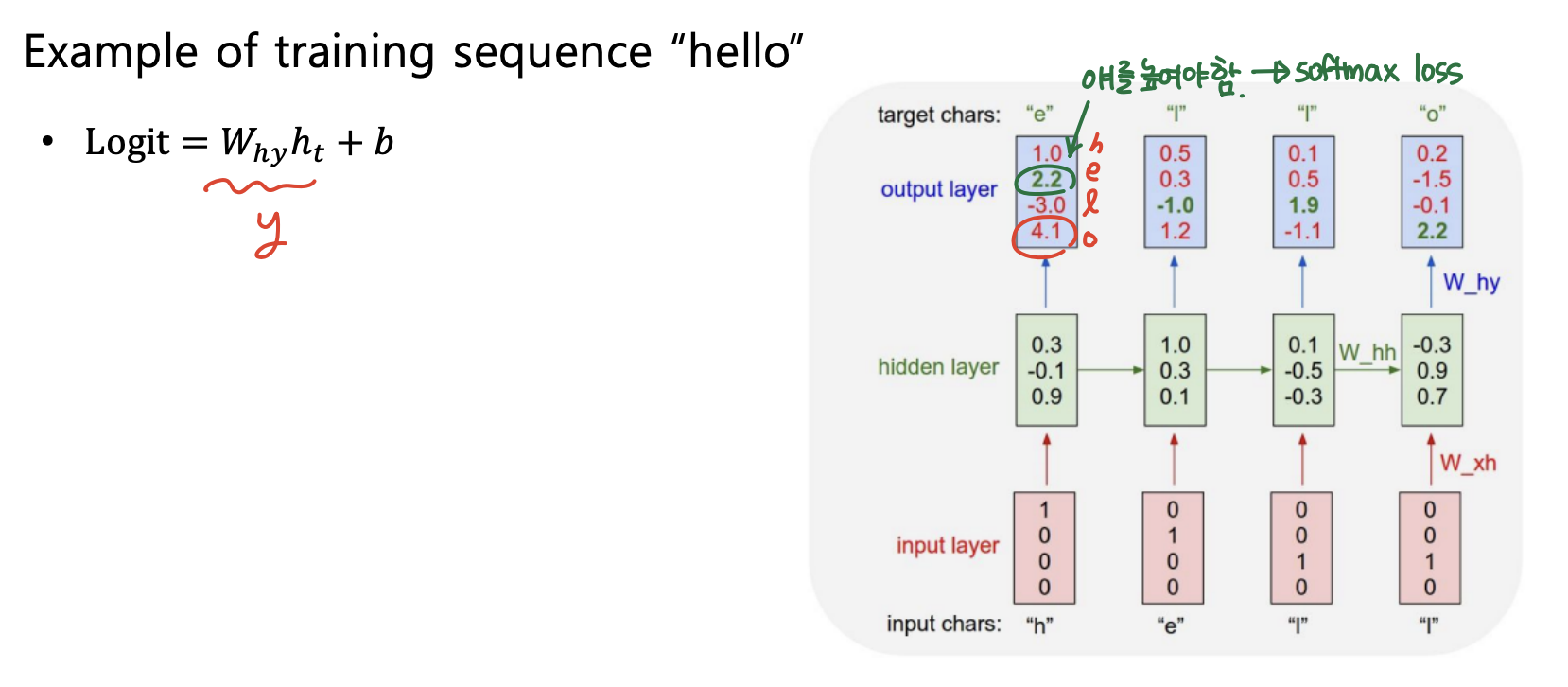
- output은 hidden vector에 linear transform을 취해 구하게 되고, 단어 [h, e, l, o] 중에 ground truth의 확률을 높이기 위해 softmax loss를 사용해 학습한다.
- 학습이 끝나고 inference단계에서는 아래 그림과 같이 output 값이 다음 input으로 들어가서 예측을 하는 형식으로 진행된다.
8)trained RNN이 할 수 있는 것
- 셰익스피어 희곡을 학습하고 희곡을 쓸 수 있음
- 대화문을 읽고, 대화문을 생성해낼 수 있음(왼쪽이 원래 대화문, 오른쪽이 RNN model로 생성한 대화문)

- 논문을 쓸 수 있음
- C code를 짤 수 있음
(출처 : http://karpathy.github.io/2015/05/21/rnn-effectiveness/)
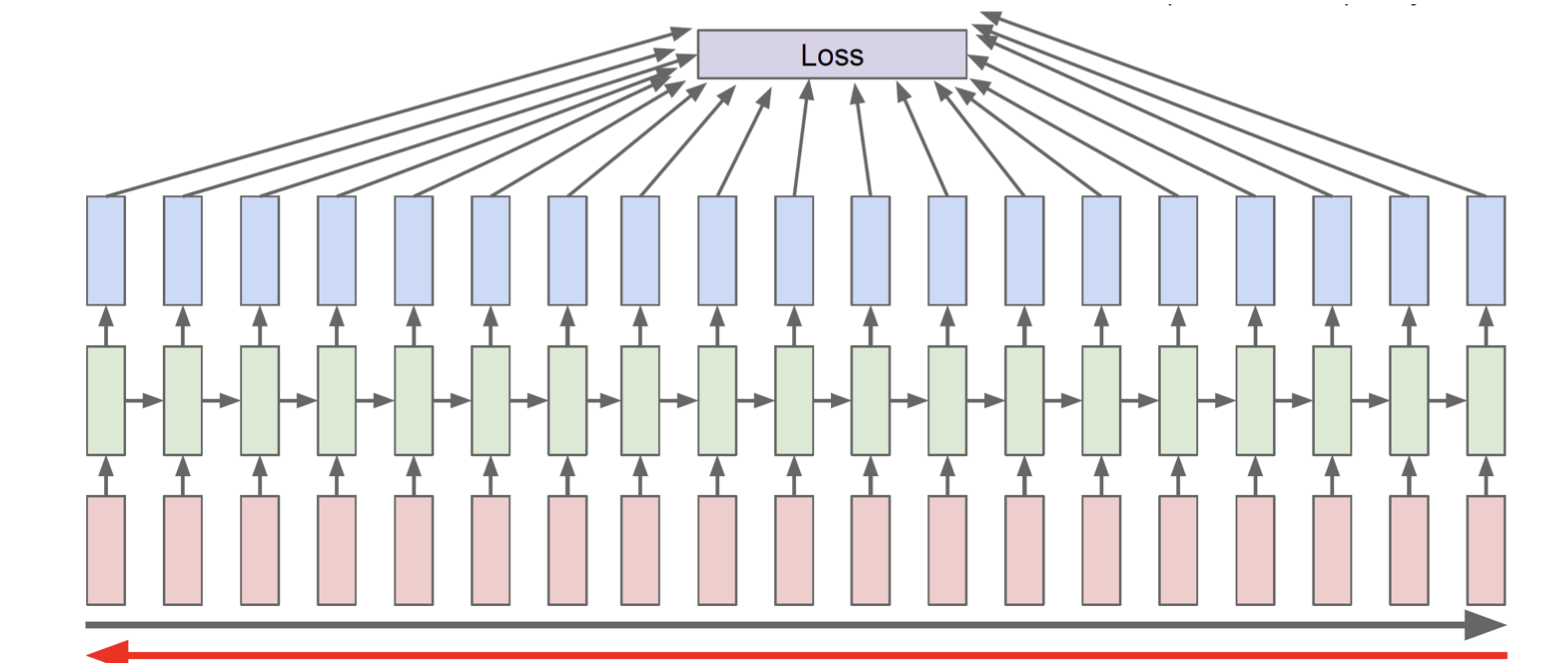
9) BPTT(Backpropagation Through Time)
- RNN의 backward 방식
- forward할 때 전체 sequence에 대해 loss를 저장했다면, backward에서도 gradient 구하기 위해 전체 시퀀스를 고려해야 함
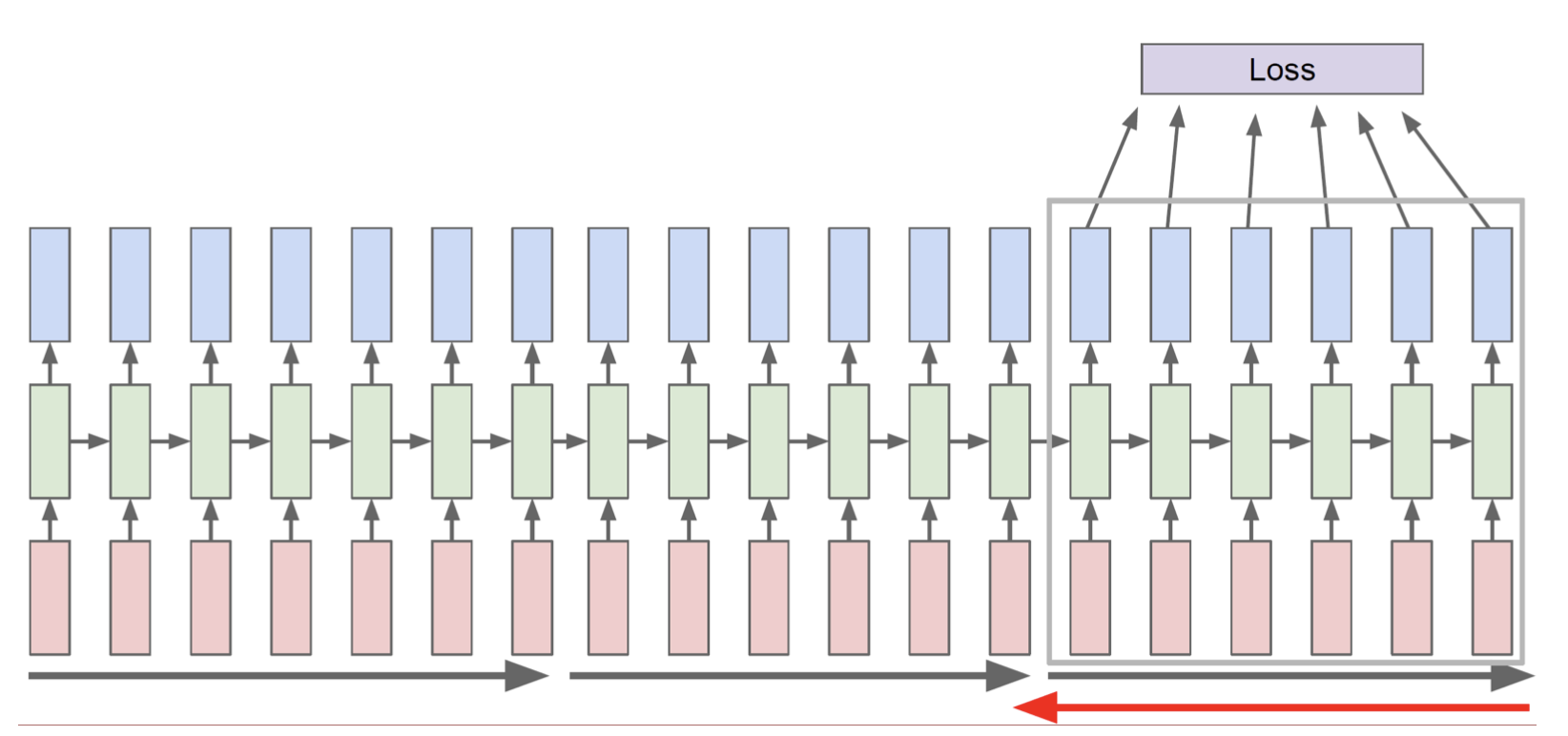
- 그런데 시퀀스가 너무 긴 경우에는 시퀀스를 작은 단위로 나눠서(chunk) forward와 backward를 할 수도 있다.
10) How RNN works
- RNN이 학습할 때 hidden state가 정보를 어떻게 저장하고 있는지 확인
- hidden state 벡터에서 찾고자 하는 정보가 어디에 있는지를 역추적하는 방식으로 분석을 수행(예를 들어hidden state가 3차원이라고 하면 띄어쓰기에 대한 정보는 3개 중 어디에 있는지를 역추적)
- 즉, hidden state 의 차원하나를 고정하고 그 값이 학습 진행에 따라 어떻게 변하는지를 분석함으로써 RNN 특성을 분석할 수 있다.
- 파랑은 특정 위치의 hidden state 값이 음수, 빨강은 값이 양수
- Quote Detection cell
- 문장에서 큰 따옴표부터 그 사이에서는 값이 음수이고 다른 구간에서는 양수인 것을 볼 수 있다.

- 문장에서 큰 따옴표부터 그 사이에서는 값이 음수이고 다른 구간에서는 양수인 것을 볼 수 있다.
- If statement cell
- If 구문에서만 값이 양수이다.

- If 구문에서만 값이 양수이다.
- 즉 hidden state에서 시퀀스의 특징 및 패턴을 저장하고 있는 것을 알 수 있다.
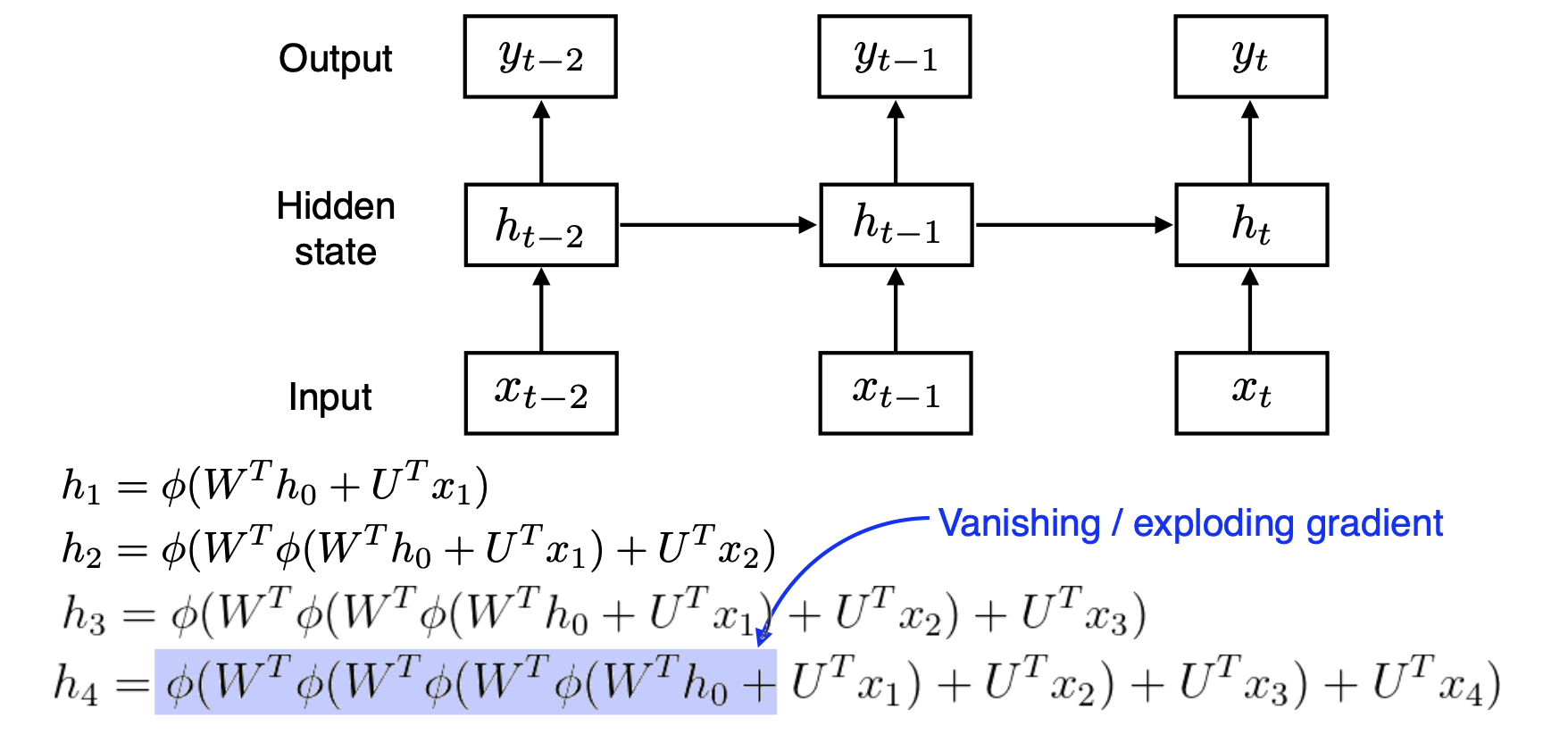
9) Vanilla RNN의 한계
- Vanilla RNN에서는 계속 이전 정보에 linear transformation을 하고 activation 함수를 씌우는 방식으로 hidden state를 업데이트한다. 그렇기 때문에 linear transformation과 activation 함수가 계속 곱해진다.
- 그렇기 때문에 back propagation을 할 때에도 계속 gradient 값을 곱하게 된다.
- 이 경우, 계속 곱해지는 값이 1보다 작으면 전체 값은 0으로 수렴하고 / 1보다 크면 무한히 발산하는 문제가 발생하는데 이러한 문제를 gradient vanishing / gradient exploding이라 한다.
- gradient exploding이 일어나면 loss 값이 수렴되지 않으므로 학습이 진행되지 않고, gradient vanishing 문제가 일어나면 업데이트를 하는 항이 0에 수렴하므로 파라미터 업데이트가 되지 않는다. 즉 얘도 학습이 진행되지 않는다.
- tanh, sigmoid의 gradient 값은 0에서 1사이 이므로 gradient vanishing 문제가 일어날 확률이 높고, ReLU를 사용하면 gradient exploding이 일어날 수 있다.
- 값을 계속 곱해나가기 때문에 발생하는 문제이므로, 이를 해결해야 한다.
2. LSTM(Long Short Term Memory)
1) LSTM Intro
- Core Idea : transformation 없이 바로 cell state 정보를 보내자
- Long-Term Dependency(장기 의존성) 문제를 해결하는 것이 목표
- 장기 의존성
시퀀스 데이터는 문맥(context) 의존성을 가진다.
아래와 같은 예문을 살펴보자.
"나는 그제 가족과 함께 광화문 광장에서 즐겁게 놀았다"
이 문장의 핵심인 '나는'과 '놀았다'는 7이라는 시간 차이를 두고 서로 의존성을 갖는다.
이와 같이 대부분의 시퀀스 데이터에서 요소들은 각기다른 시간 차이를 두고 서로 관련성을 갖고있다.
관련된 요소가 멀리 떨어져 있는 경우 시퀀스에 장기 의존성이 존재한다고 한다.
(출처)
- 장기 의존성
- 즉, 계속 1보다 작은 값을 곱해감으로써 과거 데이터를 많이 잊어버리는 RNN의 문제를 해결하는 것에 집중
2) RNN vs LSTM
- RNN
- LSTM
- -> (cell state)가 추가됨!
- : 과거 정보를 가지고 있는 온전한 정보
- : 를 한 번 더 가공한 정보, 에서 다음으로 보낼 정보만 빼내서 가져온 정보
3) LSTM Gate
-
LSTM에는 4개의 gate라는 것이 존재한다.
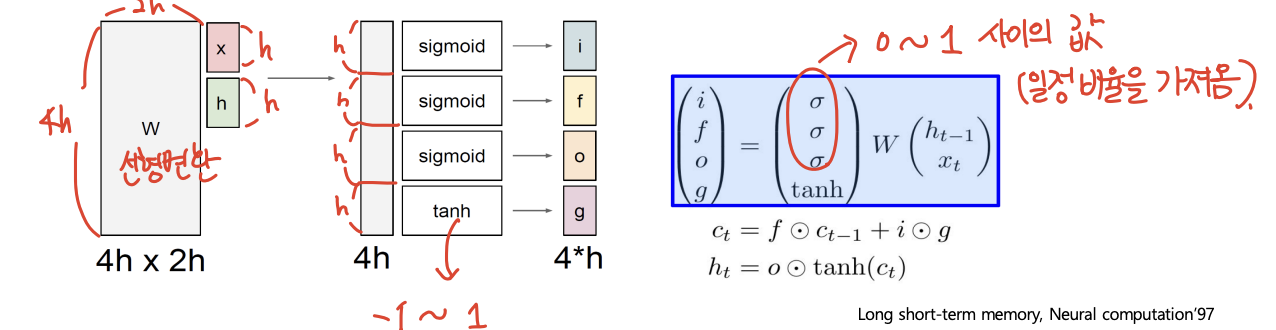
-
먼저 input과 이전 hidden state를 concat하고 선형변환해서, 그것을 gate에 따라 4등분하고 각각 sigmoid 또는 tanh를 씌운다.
-
4개의 gate는 각각 input gate, forget gate, output gate, gate gate이다.
-
이 때 sigmoid함수는 0~1사이의 함숫값을 가지므로 과 곱해지면 값의 일부를 가져오는 것과 같은 효과를 낸다. 따라서 sigmoid가 붙은 gate들은 정보에서 일정 비율의 정보만 가져오는 역할을 한다.
-
tanh는 -1~1 사이의 함숫값을 가지고, hidden을 유의미한 정보로 만들기 위해 쓰인다. Gate gate에 사용된다.
-
그럼 이제 하나씩 살펴 보자.
-
f : Forget gate, Whether to erase cell
- forget gate는 이전 hidden state()와 input()을 concat하고 선형변환한 후(bias가 있으면 더하기), sigmoid를 씌워 0~1사이 값으로 만든 벡터이다.
- 이후 forget gate는 이전의 cell state()에 곱해져서 이전 정보에서 몇 퍼센트를 기억할 것인지(=몇퍼센트를 잊어버릴 것인지)를 정하게 된다.
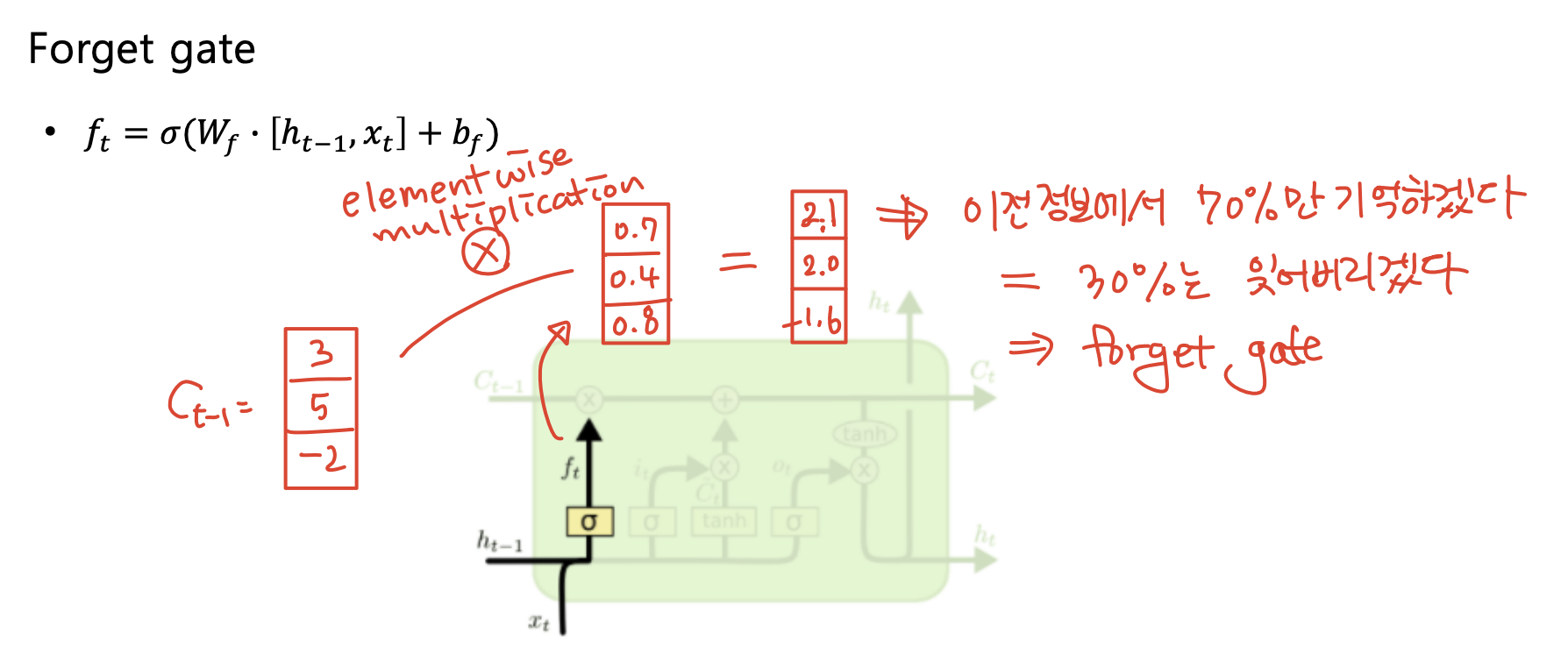
-
i : input gate, Whether to write to cell & g : Gate gate, How much to write to cell
- input gate와 gate gate는 서로 곱해지는 친구들이다.
- gate gate를 먼저 보면, hidden state()와 input()을 concat하고 선형변환한 후(bias가 있으면 더하기) tanh를 씌운 결과이다. (아래 그림의 ) gate gate는 앞에서 forget gate와 곱해진 의 현재 정보 버전이라고 생각하면된다.
- input gate는 forget gate와 유사한 역할을 한다. 즉 forget gate가 과거의 정보 중 뭘 기억하고 뭘 잊어버릴지 그 비율을 정해주는 것이라면, input gate는 현재의 정보를 얼마나 가져갈지를 정한다.
- 따라서 (현재 time step의 cell state) = (과거 정보의 일부) + (현재 정보의 일부)로 표현되며, 이를 수식으로 표현하면 이다.
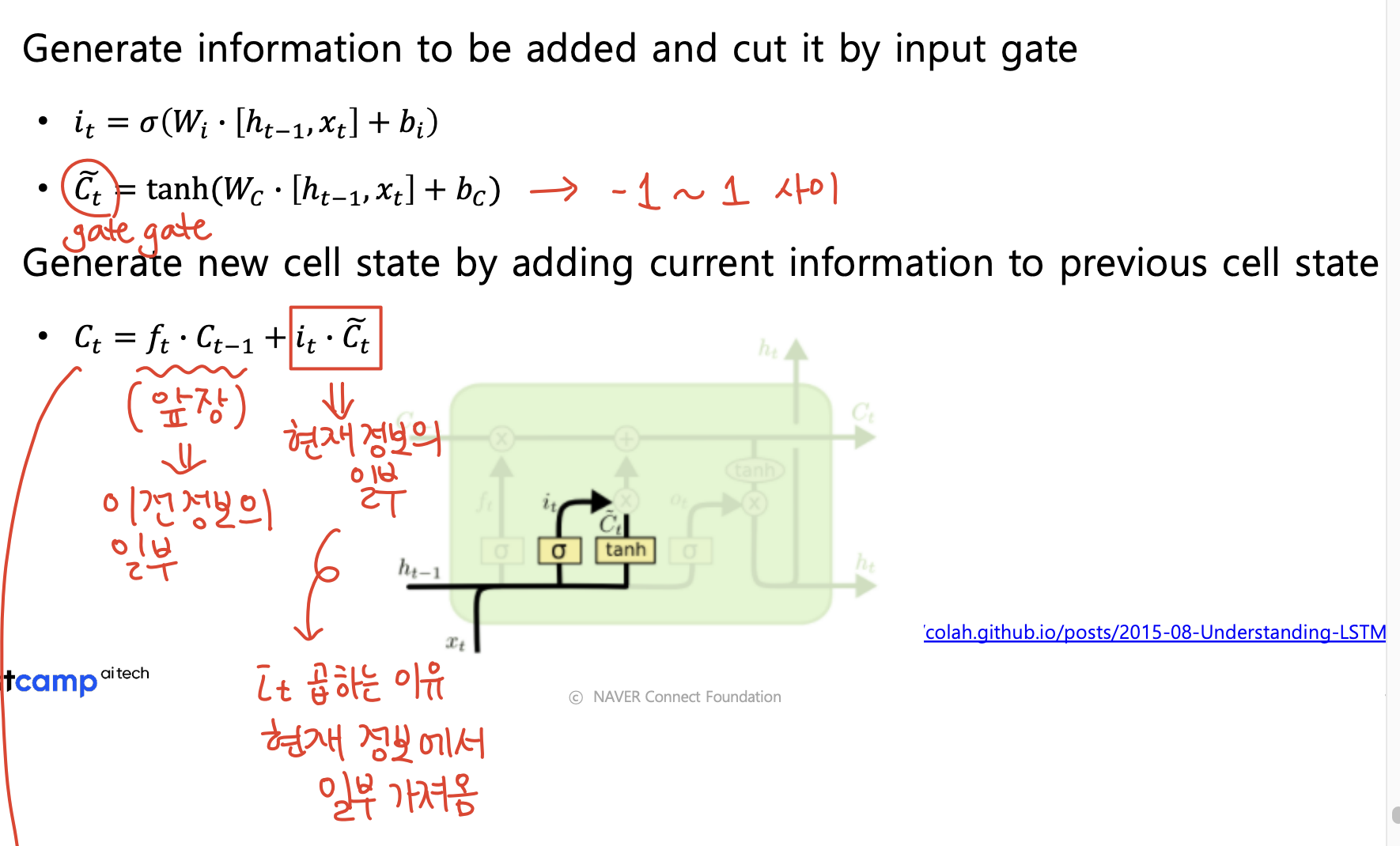
-
o : Output gate, How much to reveal cell
- 위에서 구한 현재 time step의 cell state()는 현재 time step에서 기억할 모든 정보를 가지고 있다.
- output gate는 에서 또 한 번 필요한 정보만 필터링하기 위한 gate로,
forget gate와 input gate와 유사한 역할을 한다. - 따라서 우리가 출력형태로 내보낼 값인 는 에 tanh를 씌운 결과에 output gate를 곱하여 구해진다. 즉, 의 정보중 output gate에서 주어진 일정 비율만을 가져온 값이 이다.

-
3. GRU(Gated Recurrent Unit)
1) GRU
- LSTM에서 은닉 상태를 업데이트하는 계산을 줄여서 네트워크 구조를 단순화한 모델
- LSTM보다 적은 메모리의 요구량과 빠른 수행시간을 특징으로 한다.
2) LSTM vs GRU
- LSTM
- , 존재
- input gate, forget gate
- GRU
- 로 합쳐버림(GRU의 는 LSTM의 와 유사)
- input gate()만 사용, forget gate는 ()로 대체
-> input gate와 forget gate가 독립적이지 않고, 하나가 커지면 하나가 작아짐
-> 현재 정보를 많이 챙길수록 과거 정보를 많이 못 가져감
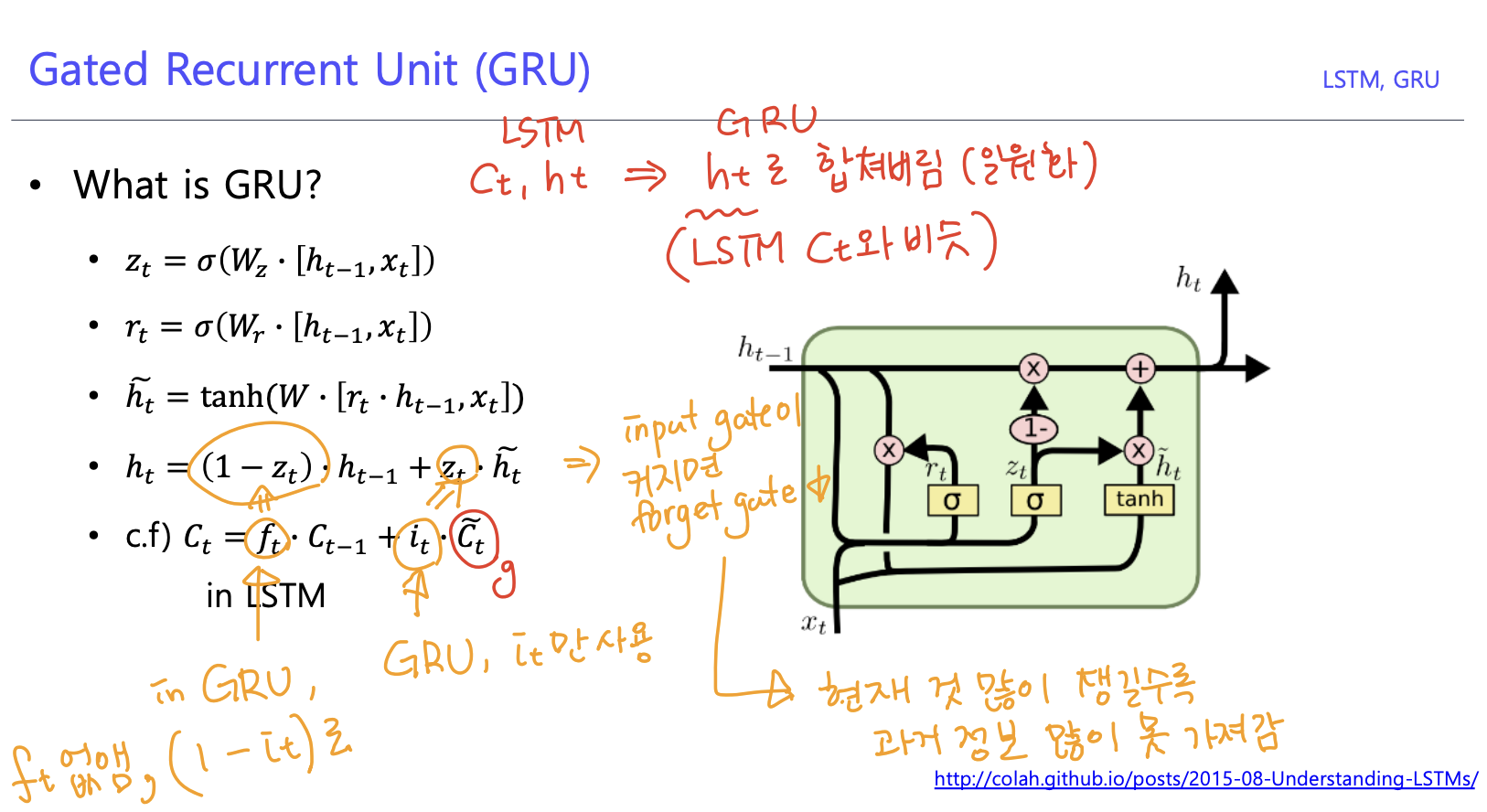
4. Backpropagation in LSTM & GRU
- Vanilla RNN에서는 를 계속 곱하는 식으로 과거의 정보를 저장했다.
- 하지만 LSTM, GRU에서는 정보를 담는 vector가 update되는 과정이 이전 time step의 cell state vector에서 일정 비율을 가져오고(forget gate, input gate, output gate등 곱하기), 필요로 하는 정보는 곱셈이 아닌 덧셈을 통해 연산해준다는 점에서 gradient 문제를 해결할 수 있다.
- 덧셈 연산은 역전파를 수행할 때 gradient를 복사해주는 효과가 있기 때문에 멀리 있는 time step까지 gradient를 큰 변형 없이 전달 가능하다.

5. 참고자료
1) RNN의 gradient vanishing 문제
2) http://karpathy.github.io/2015/05/21/rnn-effectiveness/
3) http://colah.github.io/posts/2015-08-Understanding-LSTMs/
4) http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture10.pdf
