Seq2Seq with Attention
1. Seq2Seq Model
1.1. 소개
- Seq2Seq는 Sequence-to-Sequence의 약자이다.
- Input으로 단어의 sequence를 받고, Output으로 단어의 sequence를 내뱉는 모델
- Encoder와 Decoder로 구성된다.
- Encoder와 Decoder 간에 서로 파라미터 공유는 하지 않는다.
- 아래 사진은 LSTM으로 구성된 Seq2Seq 모델의 예시이다.
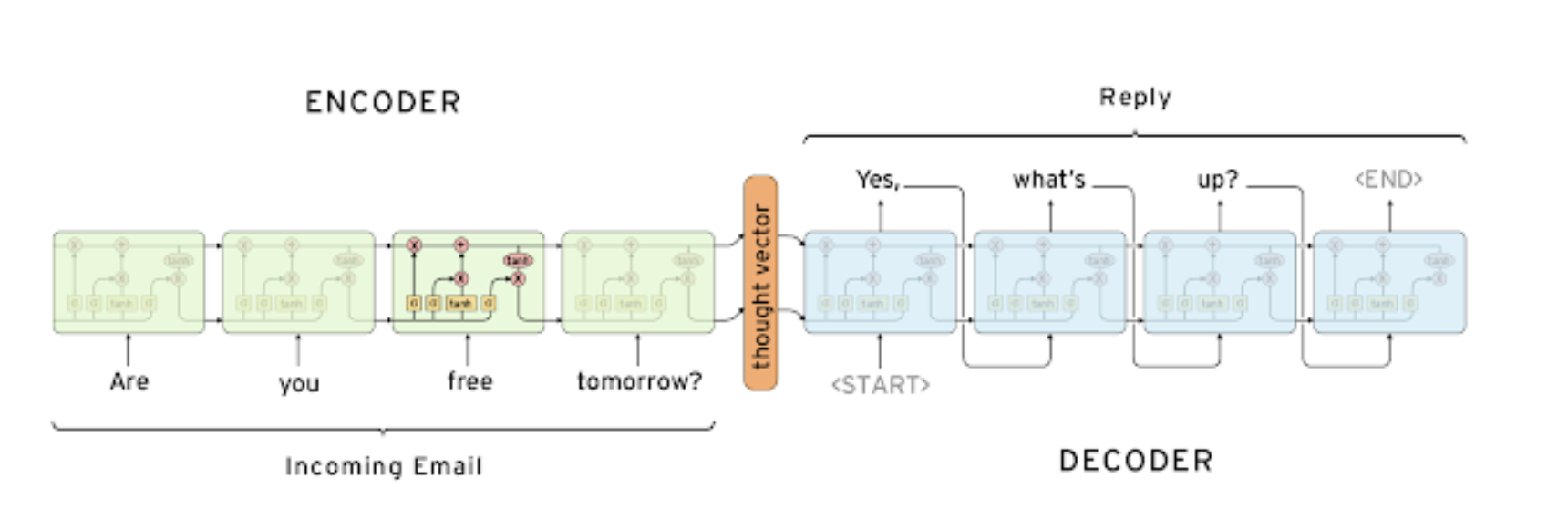
1.2. Recall : Types of RNNs
- RNN task는 입력과 출력에 대해 다음과 같이 5가지로 분류할 수 있다.
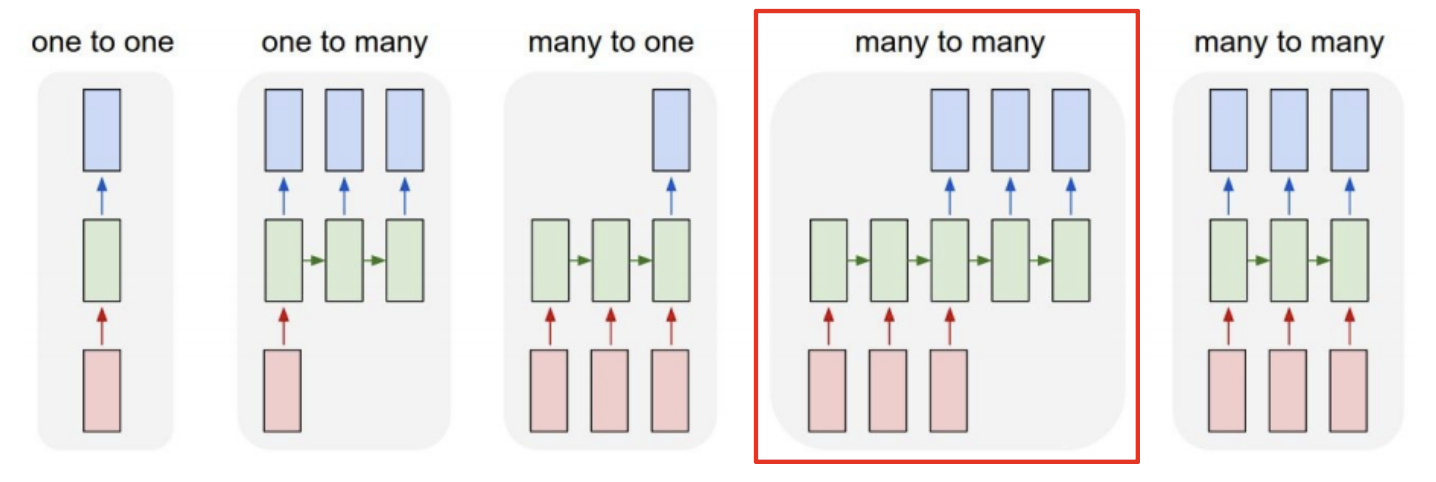
- 이 중 Sequence-to-Sequence, 그 중에서도 특히 Machine translation(기계 번역)은 many to many에 해당된다.
1.3. RNN Seq2Seq Model의 한계
-
기계번역 모델을 RNN Seq2Seq Model을 사용해 만든다고 가정해보자.
(예시 번역 : '나는 학교에 간다' -> 'I go to school') -
RNN 구조의 경우, Encoder에서 Decoder로 넘어갈 때 하나의 hidden vector만 넘길 수가 있다.
( 1.1번의 그림에서 thought vector에 해당된다) -
따라서 Encoder의 마지막 hidden state에 input 문장에 대한 모든 정보를 담아서 Decoder에 전달해야 하는데, 문장이 길어지면 이 모든 정보를 Encoder의 마지막 hidden state에 제대로 담지 못하는 문제가 발생한다.
-
이는 정보 변질, 손실의 위험으로 이어지고, 특히 Encoder의 마지막 hidden state에만 정보 전달을 의존하므로 앞쪽 정보를 거의 저장하지 못하게 된다.
-
Encoder에서 앞쪽 정보를 저장하지 못하면 Decoder에서 첫단어부터 제대로 번역하지 못하는 문제가 발생할 수 있고, 첫 단어가 잘못되면 이후 단어들도 엉망이 될 가능성이 높기 때문에 첫 단추부터 잘못 끼운 문장은 산으로 가게 된다...
-
이러한 문제를 해결하기 위해 '첫 단어부터 잘 맞추게 하자'라는 목적으로 Encoder에 집어 넣는 문장의 어순을 거꾸로 배열해서 ('나는 학교에 간다' -> '간다 학교에 나는') 집어넣는 시도도 있었다. 하지만 이 경우에도 Encoder 문장의 모든 정보를 잘 담아내지 못하기 때문에 근본적인 해결책이 되지 못한다.
-
이렇게 Encoder 문장의 많은 정보를 하나의 벡터에만 담아야 해서 나타나는 문제를 Bottleneck problem이라고 하며, Attention 방식을 통해 이러한 RNN Seq2Seq 모델의 한계를 해결하게 되었다.
2. Seq2Seq Model with Attention
2.1 Seq2Seq Model with Attention 과정 설명
- Core Idea : Decoder의 각 time step마다, Source Sentence(=Encoder에 들어온 문장)의 특정 부분을 보자.(정확히 말하면 전체를 보되 특정 부분에 집중해보자)
-
뭔 말인지 모를 수도 있겠지만, 한 단계씩 해보자!
-
예시로, 프랑스어를 영어로 번역하는 과정을 설명해보려 한다.
( les pauvres sont de'munis -> The poor do not have any money ) -
Encoder
- 먼저 Encoder 부분은 기존에 알던 RNN과 크게 다르지 않다.
- Sequence 단어 임베딩 벡터가 차례로 입력으로 들어가고, 각 time step 마다 다음으로 hidden state를 전달한다.
- 마지막 단어가 들어가는 time step에서 나온 hidden state는 decoder의 시작 hidden state로 전달된다.
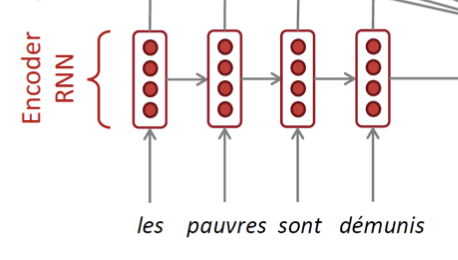
- 먼저 Encoder 부분은 기존에 알던 RNN과 크게 다르지 않다.
-
Decoder
- 문제는 Decoder이다. Decoder에서 많은 일이 벌어진다.
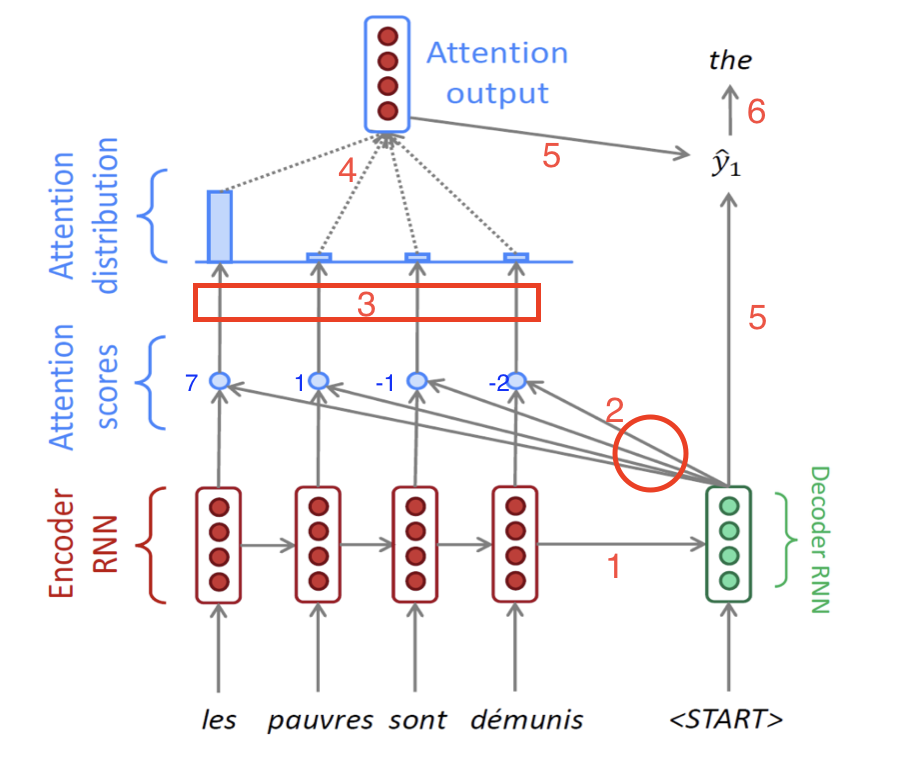
- 너무 많은 화살표들이 있지만, 놀라지 말고 빨간색 숫자를 따라가보자.
- 1 : Encoder부분에서 말한대로, Encoder 마지막 hidden state가 Decoder의 처음 hidden state로서 전달되는 과정이다.
- 그 다음 Decoder에서는 이 처음 hidden state 벡터()와 문장의 시작을 알리는 <START>(=<SOS>) 토큰의 임베딩 벡터를 입력으로 받아서 hidden state 벡터()를 만들어낸다.
- 원래는 여기에서 를 그냥 다음 time step으로 넘겼는데, Attention은 그 전에 작업이 좀 더 들어간다. 이게 중요하다.(2번)
- 2 : 만들어진 hidden state 벡터()를 가지고, Encoder의 단어들을 다시 본다. 정확히 말하면, 가 Encoder Sequence의 각 단어들의 hidden state 벡터와 각각 내적 연산(dot product)를 수행한다.
- 예를 들어 Encoder의 hidden 벡터들을 왼쪽부터 라고 명칭을 붙이면, 그림속 4개의 파란 점들은 각각 왼쪽부터 (와 내적 값), (와 내적 값),(와 내적 값),(와 내적 값)을 의미한다.
- 참고로 여기서 내적값은 두 벡터를 내적한 값이고, 내적값은 두 벡터의 코사인 유사도와 비례한다. 즉 내적값이 클수록 두 벡터는 더욱 연관성이 크다는 것을 의미한다.
- 예를 들어 Encoder의 hidden 벡터들을 왼쪽부터 라고 명칭을 붙이면, 그림속 4개의 파란 점들은 각각 왼쪽부터 (와 내적 값), (와 내적 값),(와 내적 값),(와 내적 값)을 의미한다.
- 3 : 예시로 위에서 구한 내적값이 각각 7, 1, -1, -2가 나왔다고 하자.이 값들을 softmax 함수를 통과시켜서 전체 합이 1이고 모든 값이 0과 1 사이인 확률값으로 바꾼다.
예시로, 구해진 확률값은 왼쪽부터 각각 0.85, 0.08, 0.04, 0.03이라고 하자.(아래 그림 참고)
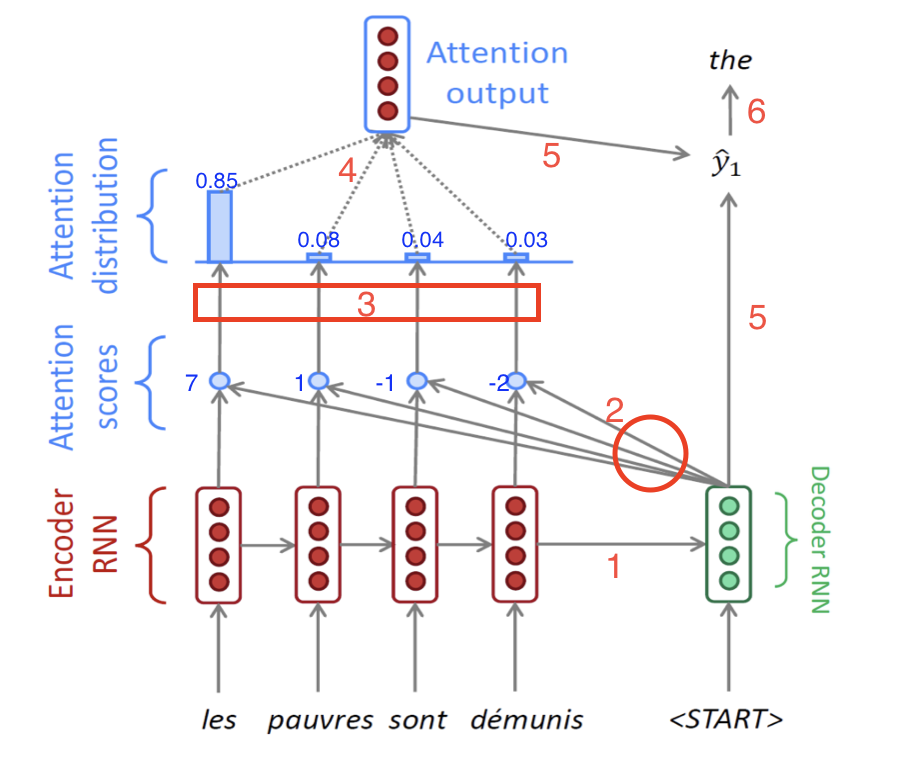
- 4 : 위에서 구해진 확률값 0.85, 0.08, 0.04, 0.03은 각각 Encoder의 hidden state벡터의 가중치로서 사용이 된다. 즉 Decoder의 현재 time step에서, Encoder의 어느 단어의 정보를 좀 더 참고하고 좀 덜 참고할 것인지를 정하는 값이다. 따라서 마지막에 있는 Attention output은 각 encoder hidden 벡터와 가중치의 곱의 합으로 구해진다.
즉,
이렇게 구해진 Attention output vector를 context vector라고도 부른다.
- 5 : 앞에서 구한 context vector와 Decoder의 첫번째 hidden state에서 나온 output vector를 concatenate해서 최종 output vector를 구한다.
- 6 : 마지막으로 최종 출력값인 현재 time step의 다음 단어를 내뱉는다. RNN Seq2Seq에서는 최종 출력값을 내보낼 때 현재 time step의 output vector만을 사용했지만, Attention에서는 그 output vector와 context vector를 모두 고려해서 다음 단어를 예측하는 것이 차이점이다.
- 문제는 Decoder이다. Decoder에서 많은 일이 벌어진다.
-
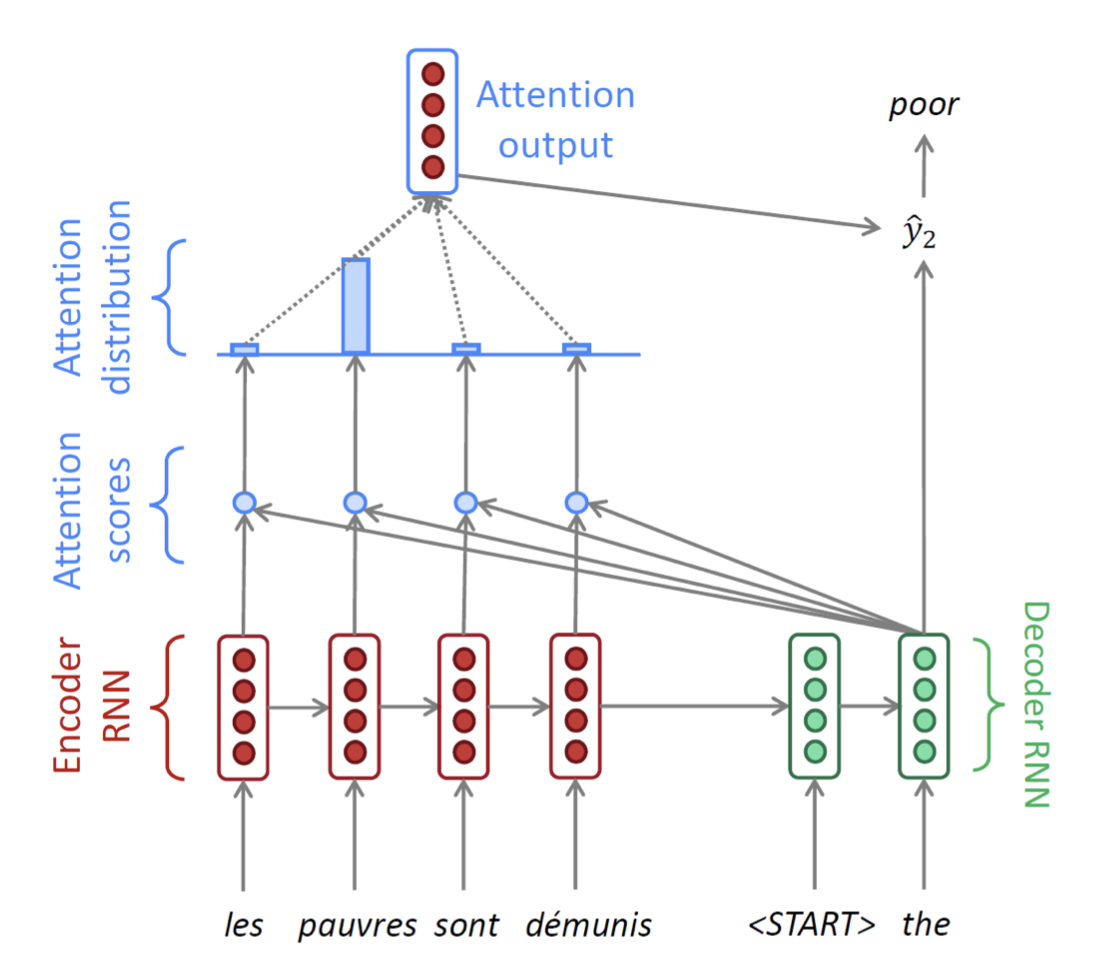
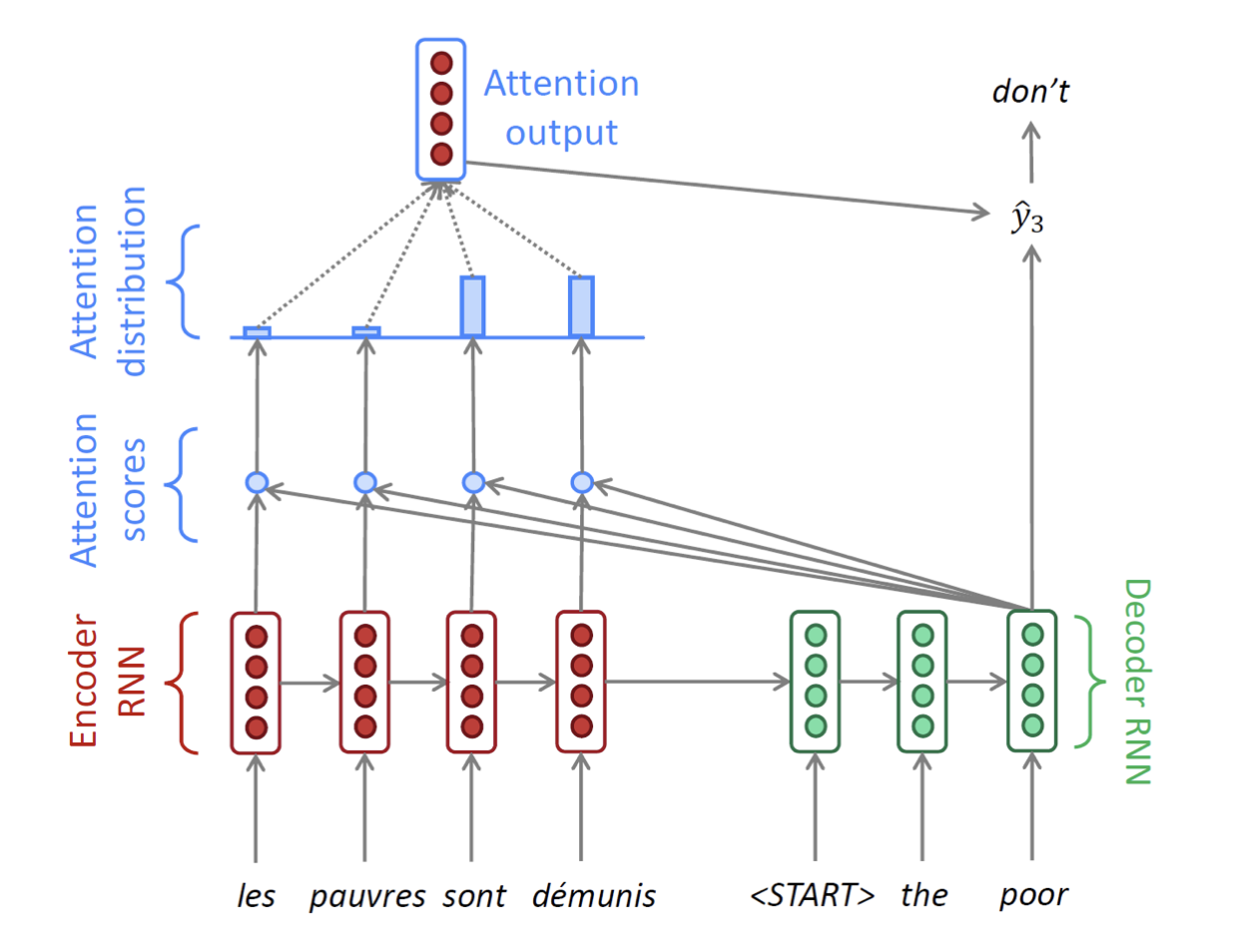
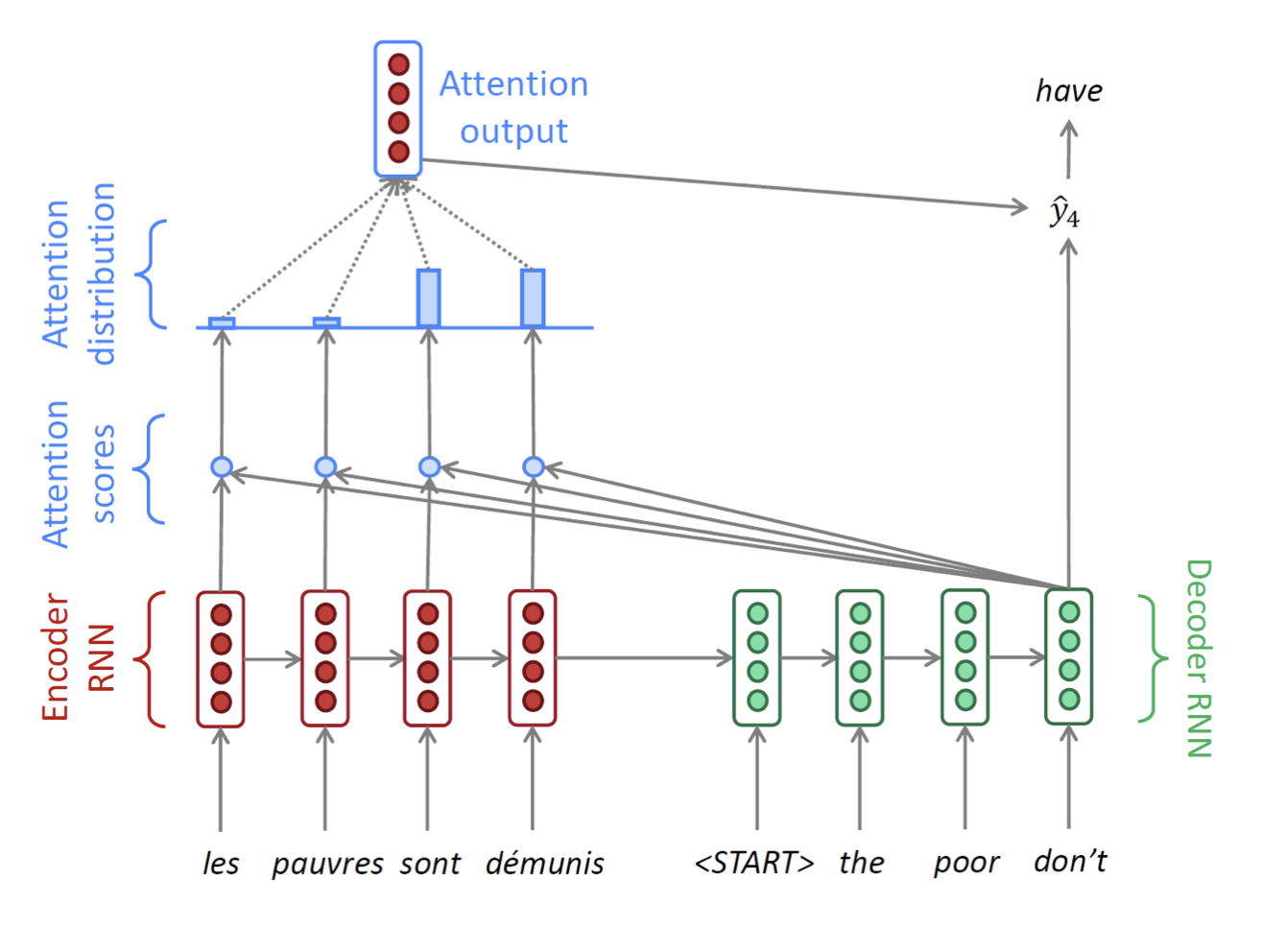
설명이 너무 길었지만 Decoder부분의 한 time step 설명이 끝났다!다음 time step들도 같은 방식으로 진행된다. (문장이 끝날때까지 = 보통 또는 토큰이 나올 때까지 진행)
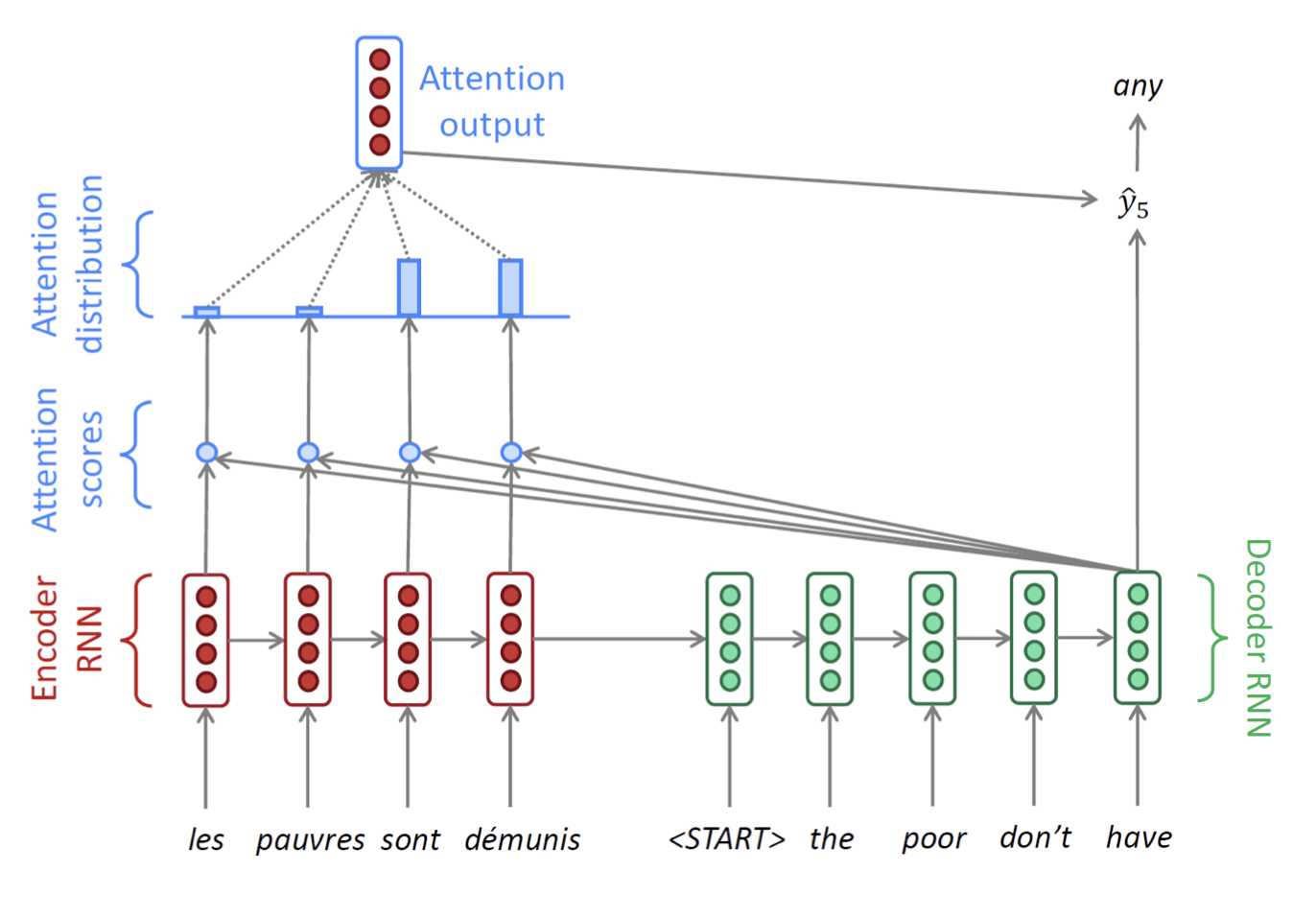
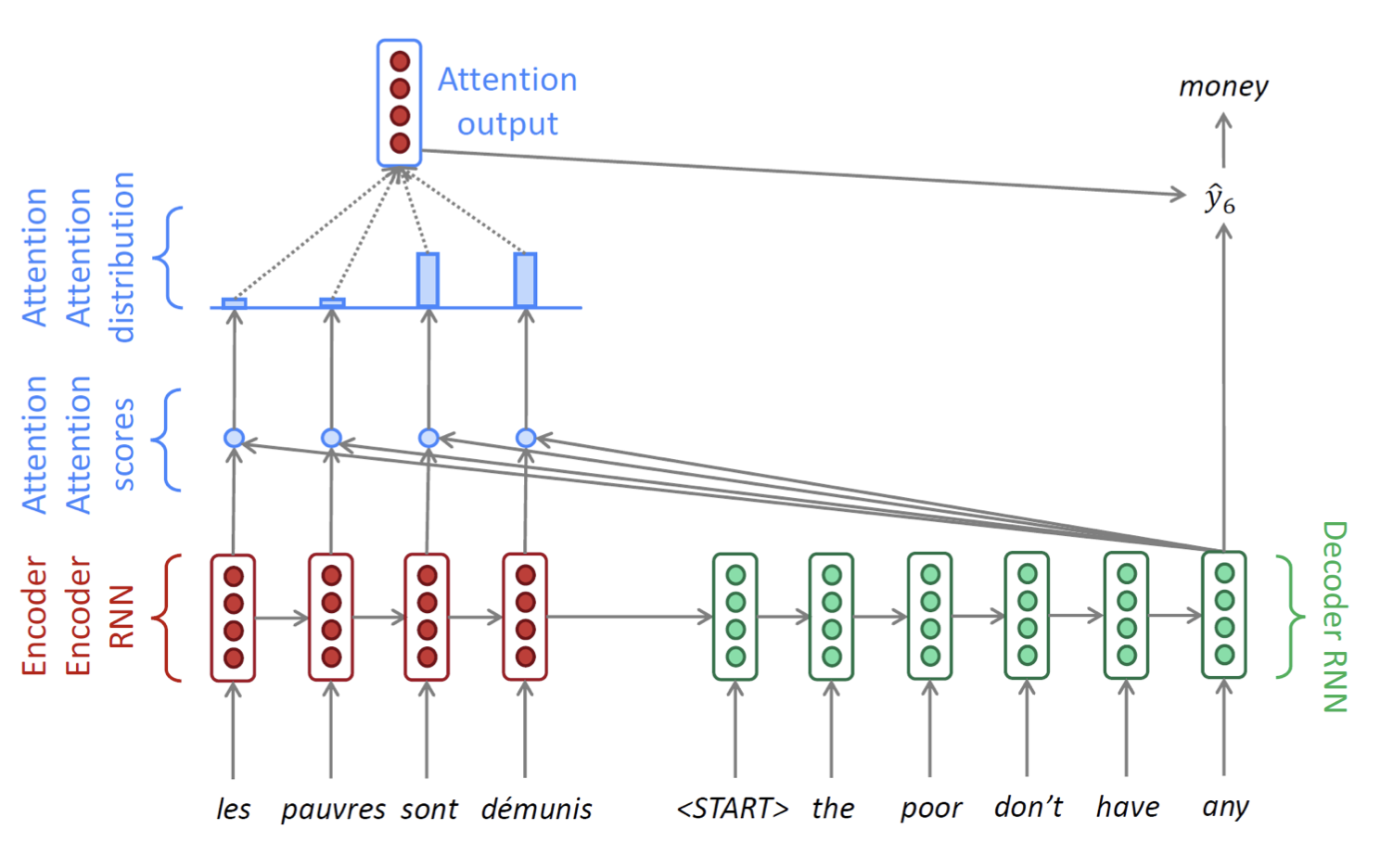
-
여기서 헷갈릴 수 있는 부분은, Decoder의 매 time step마다 Encoder의 모든 단어에 대해 내적과 softmax를 취해 context 벡터를 본다는 것이다. 즉 Decoder에서 단어 하나 뱉을 때마다 Encoder에 있는 모든 단어를 본다고 이해하면 될 것 같다.
2.2.Attention Mechanism 조금 더 들여다보기
-
위에서 Attention을 사용한 Encoder와 Decoder를 거쳐 번역 문장을 만들어내는 과정을 살펴보았다.
-
이번에는 Attention 방식에서 Decoder hidden state의 역할, Back propagation 경로, Teacher Forcing 방식에 대해 살펴보려고 한다.
-
Decoder hidden state의 역할
- RNN Seq2Seq에서 Decoder hidden state는 해당 time step의 output을 도출하는 역할과 다음 time step으로 현재 정보를 전달하는 역할, 이렇게 두 가지 역할을 수행한다.
- 반면 Attention에서 Decoder hidden state는 기존의 두 가지 역할에 더해서, 현재 time step에서는 Encoder의 단어들 중 어떤 것을 더 중점적으로 봐야 하는지에 대한 가중치를 구하는 역할도 수행한다.
- RNN Seq2Seq에서 Decoder hidden state는 해당 time step의 output을 도출하는 역할과 다음 time step으로 현재 정보를 전달하는 역할, 이렇게 두 가지 역할을 수행한다.
-
Back propagation 방식
- Attention에서 Forward propagation 경로를 먼저 보면,아래 파란색 화살표와 같이 Decoder hidden state에서 바로 output으로 가는 경로(다음 단어 예측-1번)과 Decoder hidden state에서 Encoder hidden state와의 계산을 거쳐 output으로 오는 경로(가중치 계산 - 2번)이 있다.
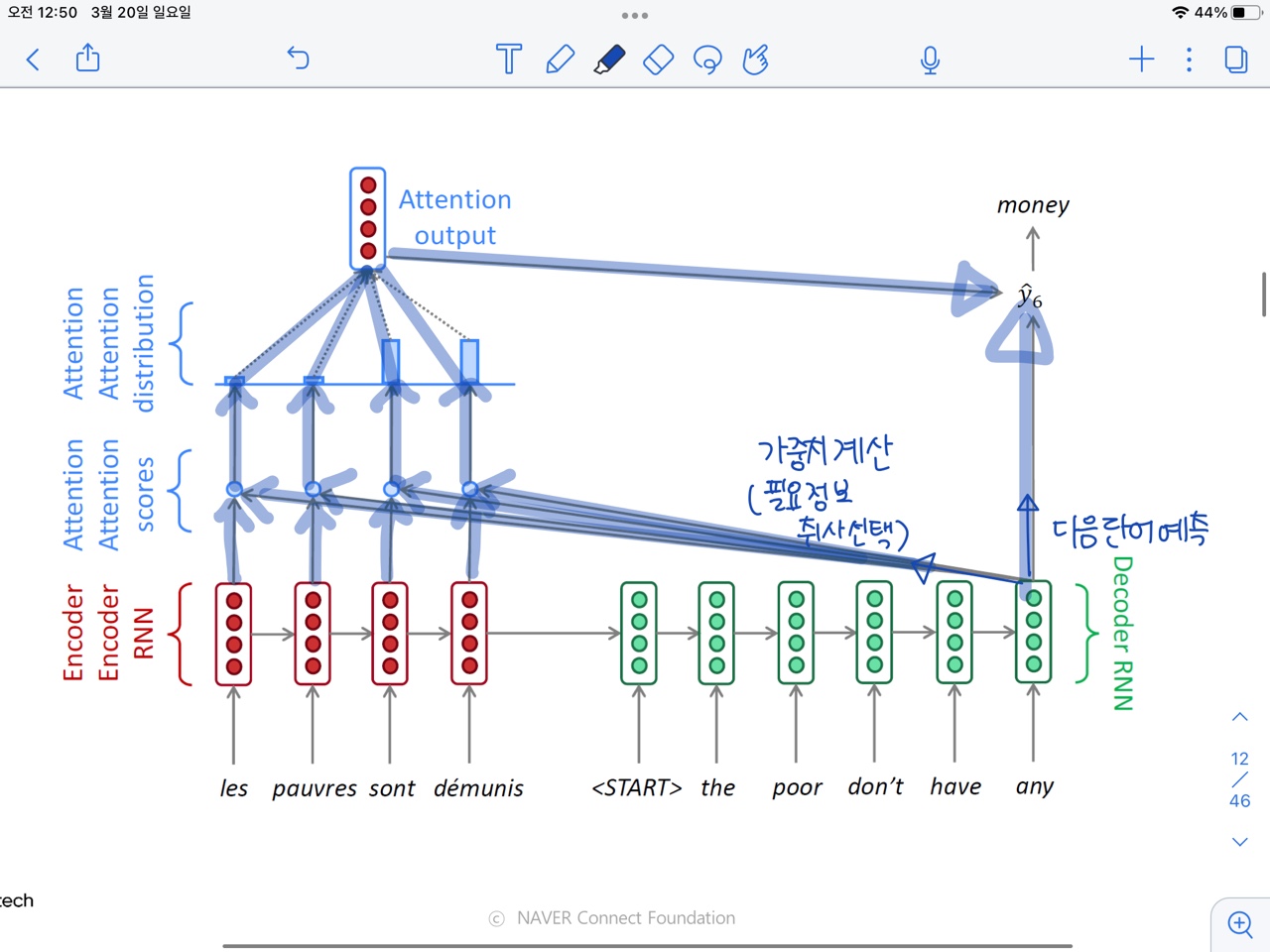
- Back propagation은 Forward propagation의 경로를 역방향으로 흐르기 때문에 Back propagation 또한 두 가지 경로로 흐르게 된다.
- Decoder hidden state vector로 흐르는 경로(1번)
- Encoder의 각 hidden state vector로 흐르는 경로(2번)
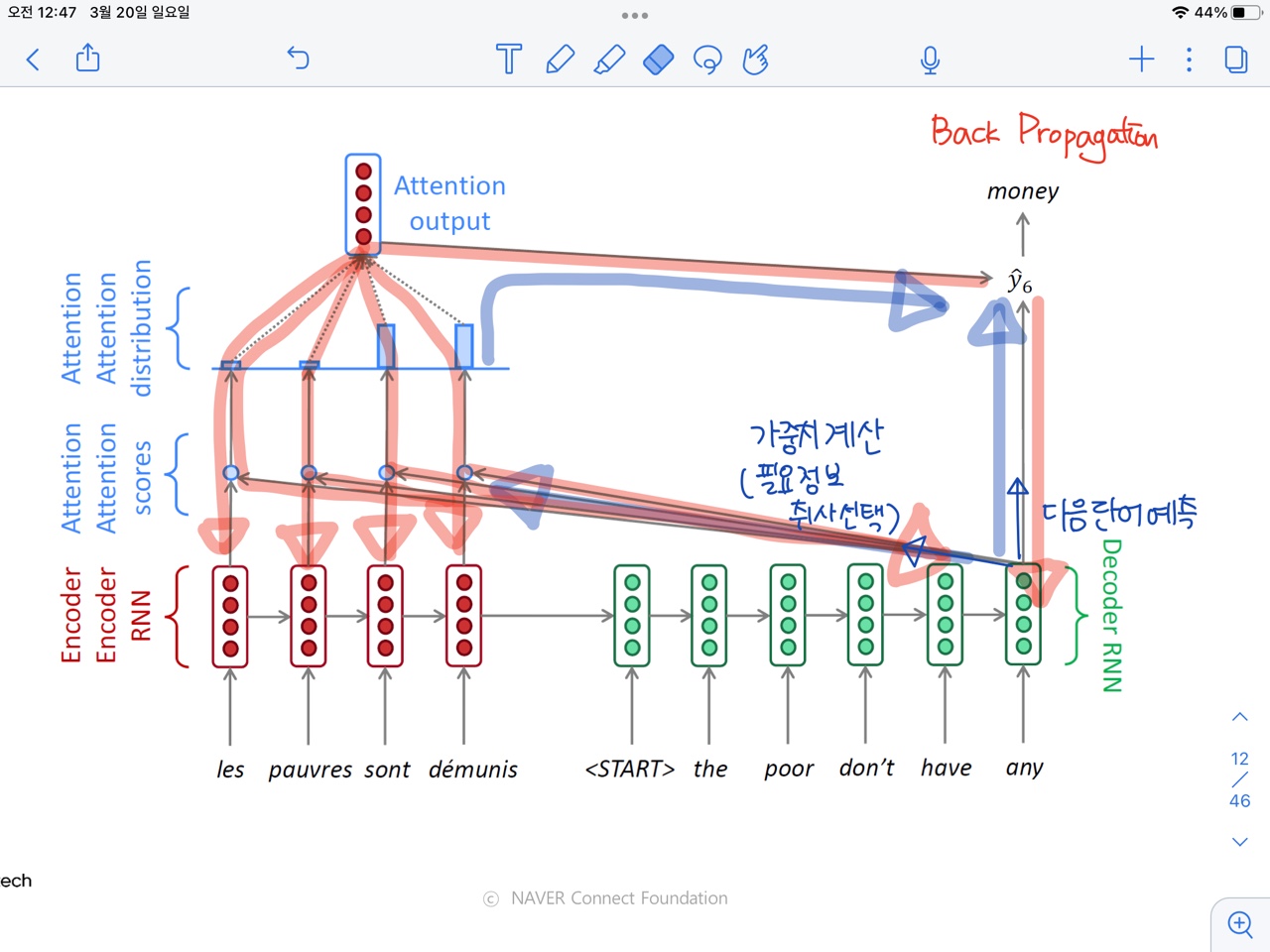
- Attention에서 Forward propagation 경로를 먼저 보면,아래 파란색 화살표와 같이 Decoder hidden state에서 바로 output으로 가는 경로(다음 단어 예측-1번)과 Decoder hidden state에서 Encoder hidden state와의 계산을 거쳐 output으로 오는 경로(가중치 계산 - 2번)이 있다.
-
Teacher Forcing
- Teacher Forcing은 앞에서는 설명하지 않은 개념이다.
- Teacher Forcing은 간단히 말하면 Decoder에서 Input으로 이전에 출력으로 내보낸 단어를 넣는 게 아니라 실제 정답 단어를 넣는 것을 말한다.
- 원래 Decoder를 생각하면, 현재 time step에서 다음 단어를 예측하고 그 예측된 단어가 다음 time step의 input으로 들어가야 한다.
- 하지만 원래 Decoder 방식을 사용하면, 만약에 현재 time step에서 다음 단어를 잘못 예측했을 경우, 그 다음에 나오는 단어들이 연쇄적으로 잘못 예측될 가능성이 높다.
- 따라서 Attention에서는 Training 단계에서는 현재 time step에서 출력으로 내보낸 예측한 단어를 그대로 다음 time step의 input으로 넣지 않고, 실제로 다음에 오는 단어를 input으로 넣어서 학습하고, Inference 과정에서는 원래 Decoder대로 예측 단어를 다음 input으로 사용하는 방식을 제안했는데, 이게 바로 Teacher Forcing 방식이다.
- 이러한 Teacher Forcing으로 학습 과정이 더 빨라지고, 안정화 될 수 있다. 다만 Teacher Forcing으로 인해 나타나는 Training과 Inference 단계의 괴리감도 문제가 되고 있어서, 이를 해결하기 위한 여러 방식들도 제안되고 있다.( Professor Forcing 등...)
- Teacher Forcing은 앞에서는 설명하지 않은 개념이다.
2.3.Different Attention
-
위에서 본 것과 같이, 기본 Attention 방식에서는 Decoder의 hidden vector와 Encoder의 hidden vector의 유사도를 구할 때 두 벡터의 내적을 계산하였다.
-
하지만 Decoder의 hidden vector와 Encoder의 hidden vector의 유사도를 구할 때 반드시 두 벡터의 내적으로만 유사도를 구해야 하는 것은 아니다. 내적 값 계산 이외에 다른 두 가지 방식을 소개해보려 한다.
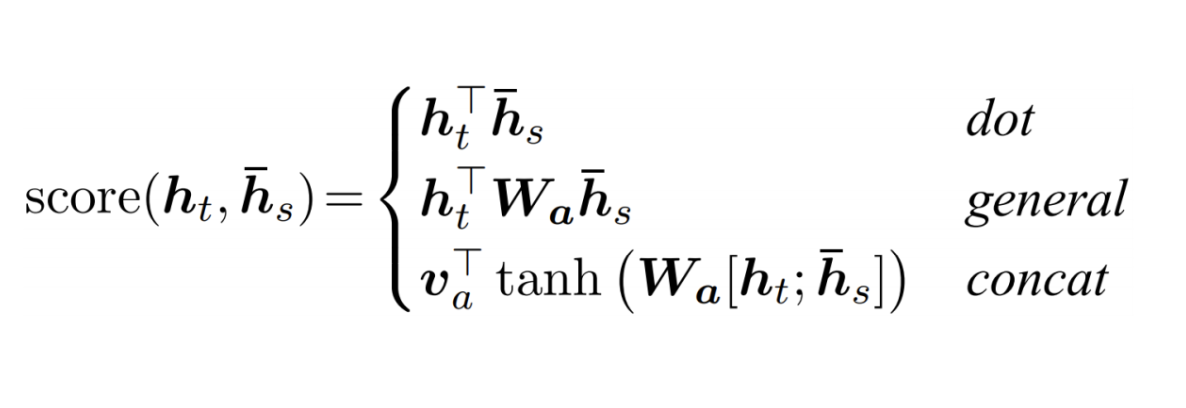
-
Generalized dot product
- 수식 :
- 내적의 좀 더 일반화된 방식
- 이라고하면, 원래 내적 계산은 다음과 같이 계산되었다.
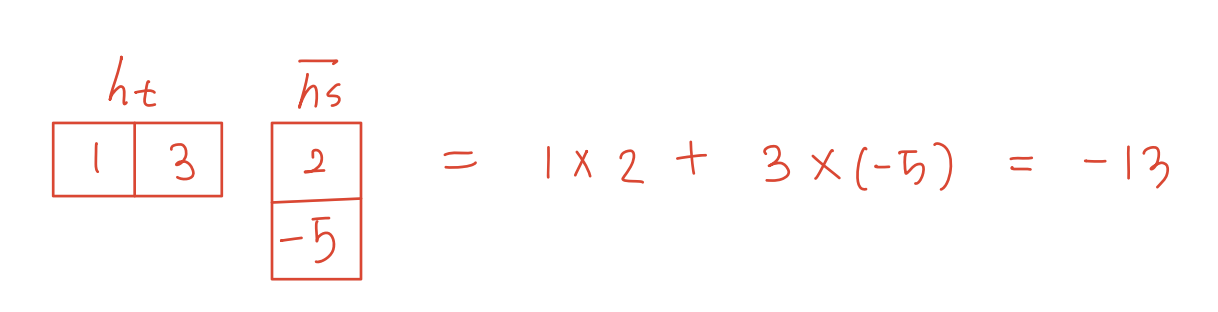
- 하지만 Generalized dot product에서는 두 벡터 사이에 행렬이 하나 더 추가된다.
- 행렬이 Identity 행렬일 때에는 내점 값이 유지 된다.
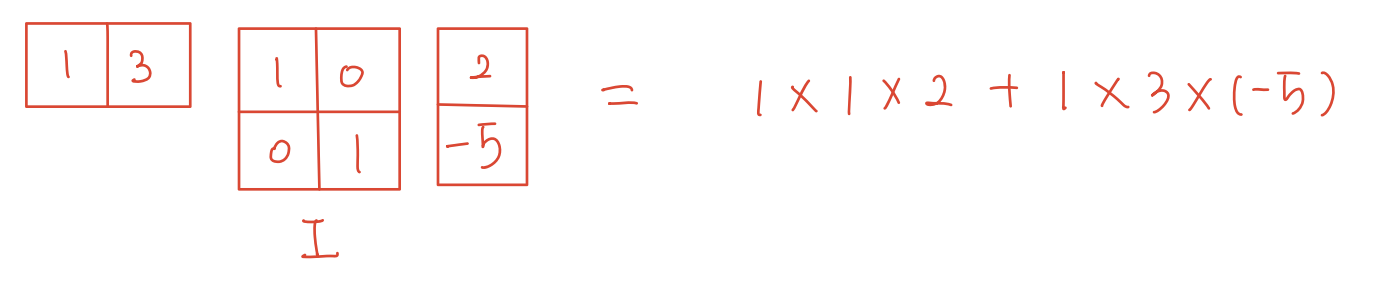
- 하지만 이 행렬 값을 바꿔보면, 내적값도 달라진다.

- 행렬의 다른 원소 값도 바꿔보면, 행렬의 원소값이 두 벡터의 원소의 곱에 각각 곱해지는 것을 볼 수 있다.
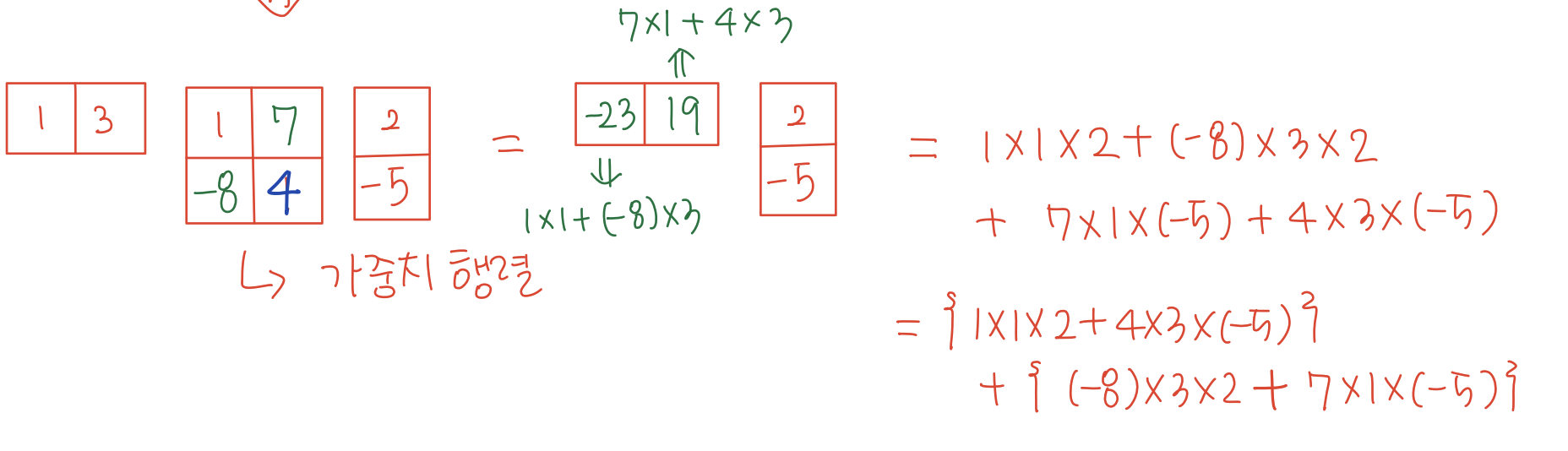
- 여기에서 중간에 낀 행렬 를 가중치 행렬로 보고, 의 각 원소들은 두 벡터의 원소의 곱에 해당하는 가중치가 된다. 또한 가중치 행렬 는 학습 가능한 요소이다.
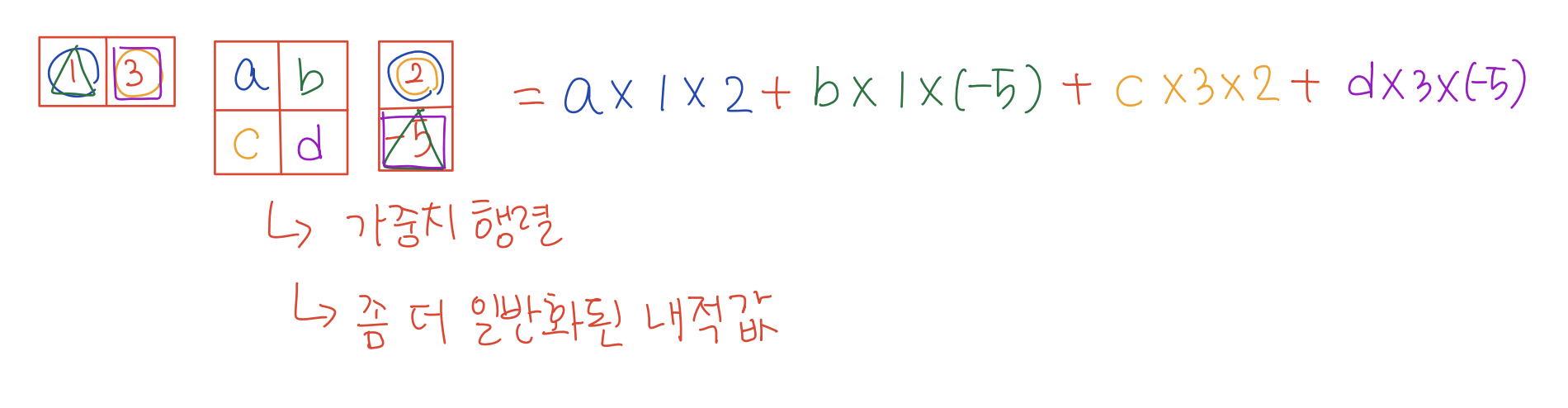
-
Concatenation 기반의 Attention
- 수식
- 두 벡터를 concat한 후 행렬 변환하여 score를 구해주는 방법이다.
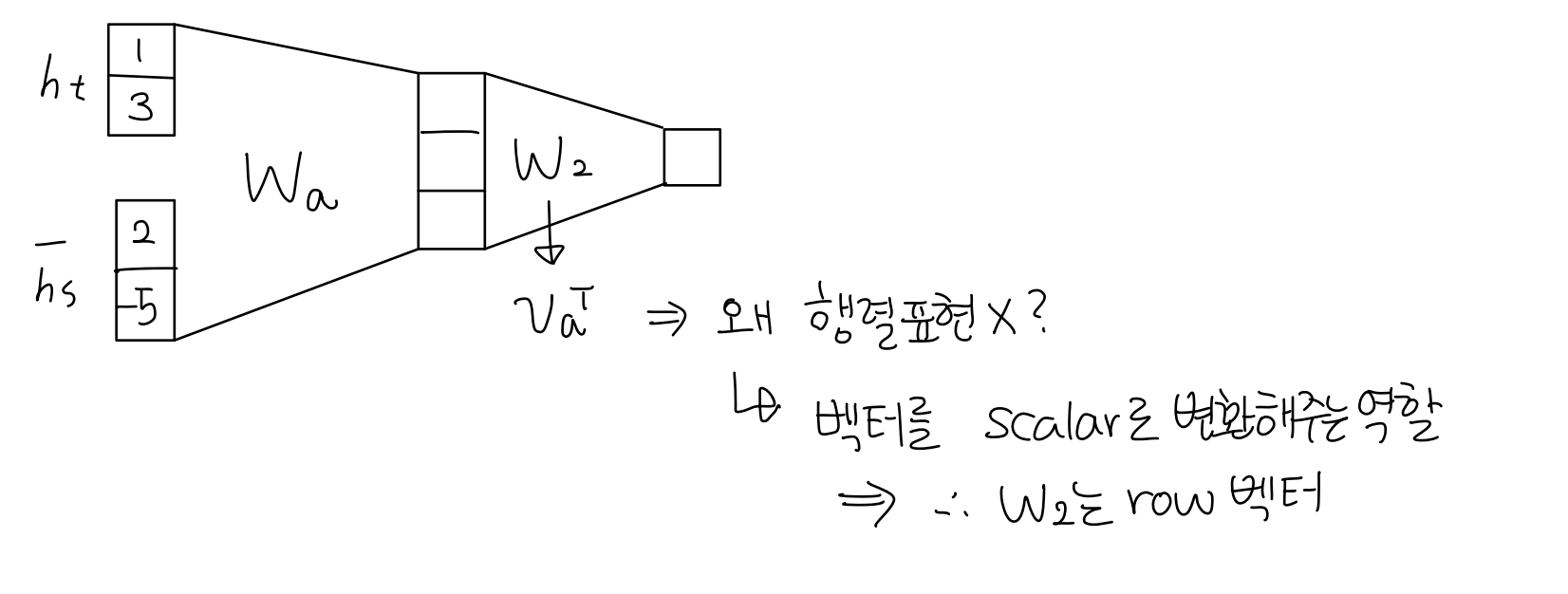
- 그림으로 보면, 두 벡터 를 concat한 후, 행렬 로 선형변환한다. 그 후 (=)로 한 번 더 행렬 변환하여 벡터를 scalar 값으로 바꿔준다.
- 도 행렬 변환이지만 행렬로 표현하지 않고 벡터로 표현한 이유는, 의 역할이 벡터를 scalar값으로 변환해주는 것이기 때문에 는 항상 벡터일 수밖에 없기 때문이다.
-
원래 내적 계산에서는 학습 가능한 파라미터가 존재하지 않았다. 하지만 'Generalized dot product'과 'Concatenation 기반의 Attention'에서는 학습가능한 파라미터가 존재한다. 이 파라미터들은 어떻게 학습될까?
- 'Generalized dot product'과 'Concatenation 기반의 Attention'을 사용하면 아래 그림의 파란 점 4개가 모두 학습가능한 파라미터를 포함하게 된다.
- 빨간색 화살표 방향으로 Back propagation이 일어나기 때문에 'Generalized dot product'과 'Concatenation 기반의 Attention'의 가중치 행렬, 벡터 또한 이 과정에서 업데이트 된다.
-
관련 개념
- Luong attention
- Bahdanau attention
2.4. Attention의 성능
-
마지막으로 Attention이 RNN의 한계를 어떻게 극복했고, 어떻게 성능이 좋아졌는지에 대해 정리해보자.
-
Attention significantly improves NMT performance
- Decoder의 매 time step 마다, 입력 sequence에서의 어떤 부분에 정보를 집중해서 볼 것인지를 정하고, 실제로 그 정보를 사용해서 다음 단어를 예측하는 것을 가능하게 했다.
-
Attention solves the bottleneck problem
- Attention은 Decoder가 직접적으로 Encoder Sequence를 들여다 볼 수 있게 되어있다.
- 이러한 구조는 RNN Seq2Seq에서 발생했던 bottleneck 문제(Encoder의 마지막 time step에서의 hidden state 벡터만을 사용하여 번역을 수행해야 해서 긴 문장에 대해 모든 정보를 전달하지 못하는 문제) 를 해결하였다.
-
Attention helps with vanishing gradient problem
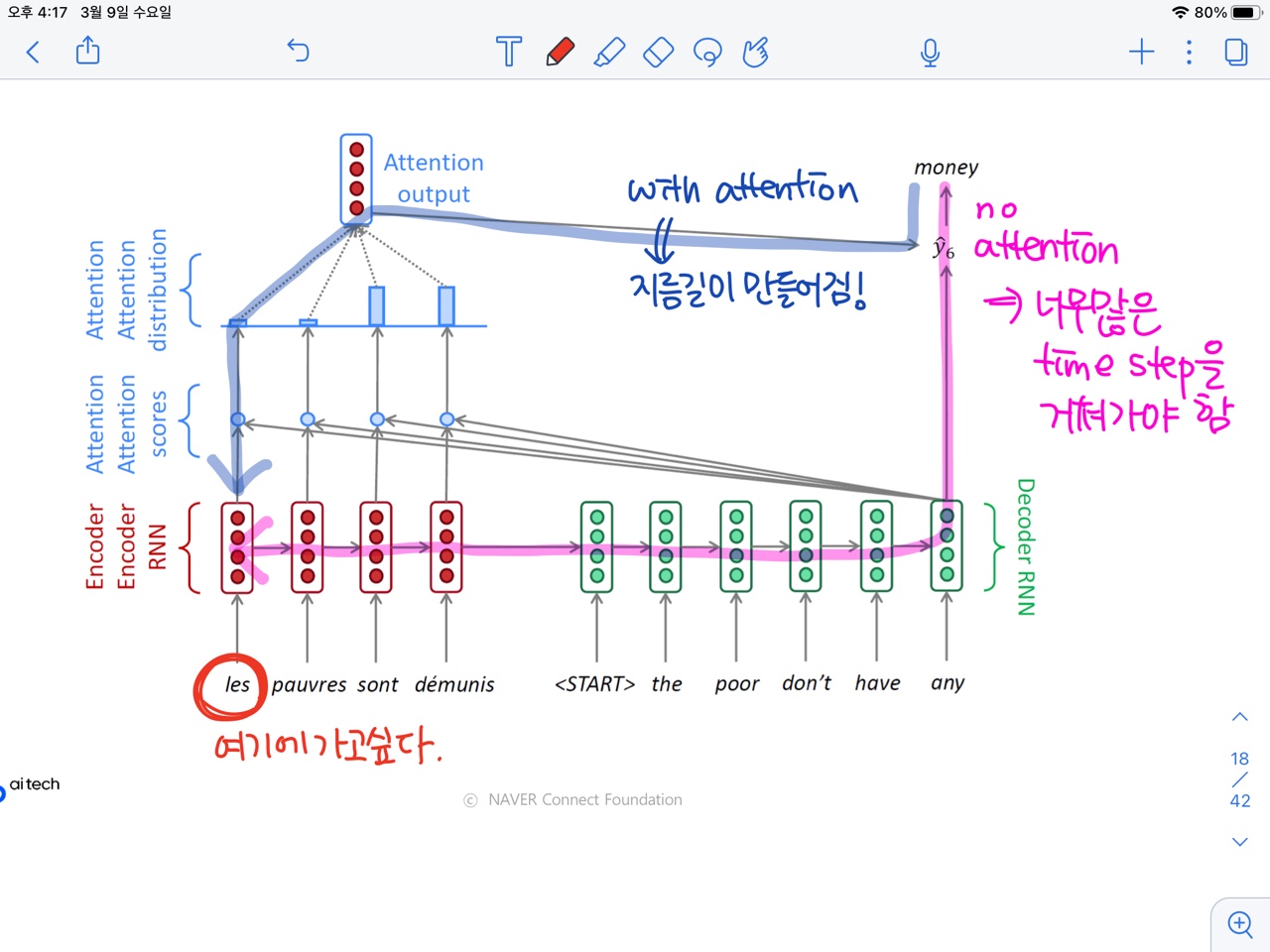
- 만약 Attention이 없다면, Encoder 문장의 앞쪽 단어까지 gradient를 전달하려면 그 전에 많은 단어들의 time step을 지나가야 한다. 이 과정에서 gradient가 많이 손실되거나 변형된다.=long term dependency 문제(위 그림 핑크색)
- 하지만 Attention 방식의 경우, 위 그림에서 파랑색 화살표처럼 바로 그 단어로 gradient를 전달할 수 있는 경로가 존재하기 때문에 멀리 있는 단어라도 gradient를 손실과 변형이 거의 없이 전달할 수 있다.
-
Attention provides some interpretability
- Attention의 패턴이 어떤식으로 나왔는가를 조사하면, Decoder가 각 단어를 예측할 때 Encoder의 어떤 단어에 더 집중했는지를 볼 수 있다.
- Attention Examples in Machine Translation
- 왼쪽 언어를 위쪽 언어(영어)로 번역하는 task
- 왼쪽이 encoder에, 위쪽이 decoder에 해당됨
- 대부분의 경우에는 단어를 번역할 때 순차적으로 집중한 것을 볼 수 있다(빨간색)
- 하지만 특정 부분에서는 어순에 맞게 역전해서 attention을 하기도 한다.(두 언어가 어순이 다를 수 있기 때문)
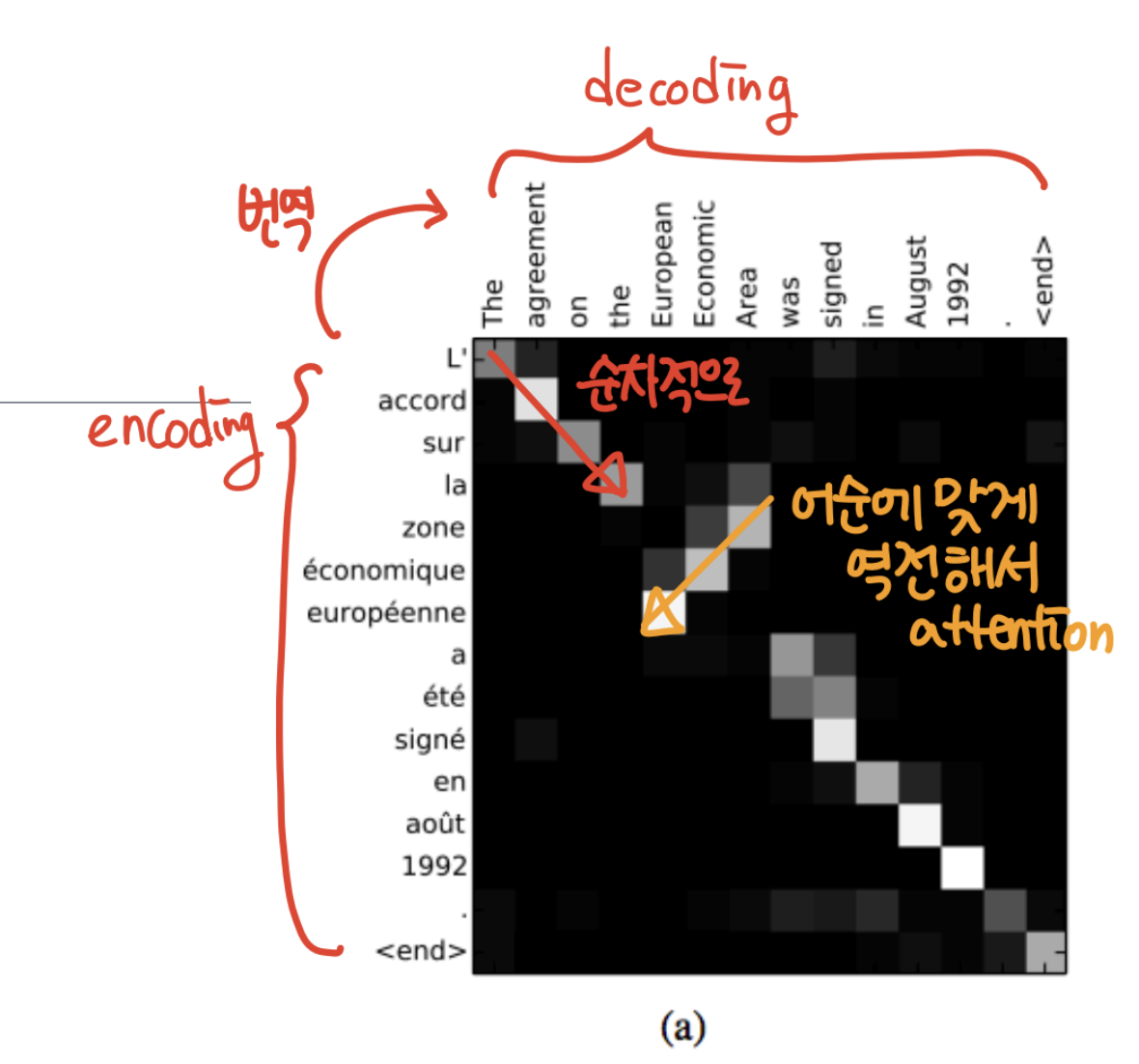
- 또한 한 단어를 decoding할 때 여러 개의 encoding 단어를 바라볼 때도 있고, 하나의 encoding 단어가 여러 개의 decoding 단어에 해당되는 경우도 있음
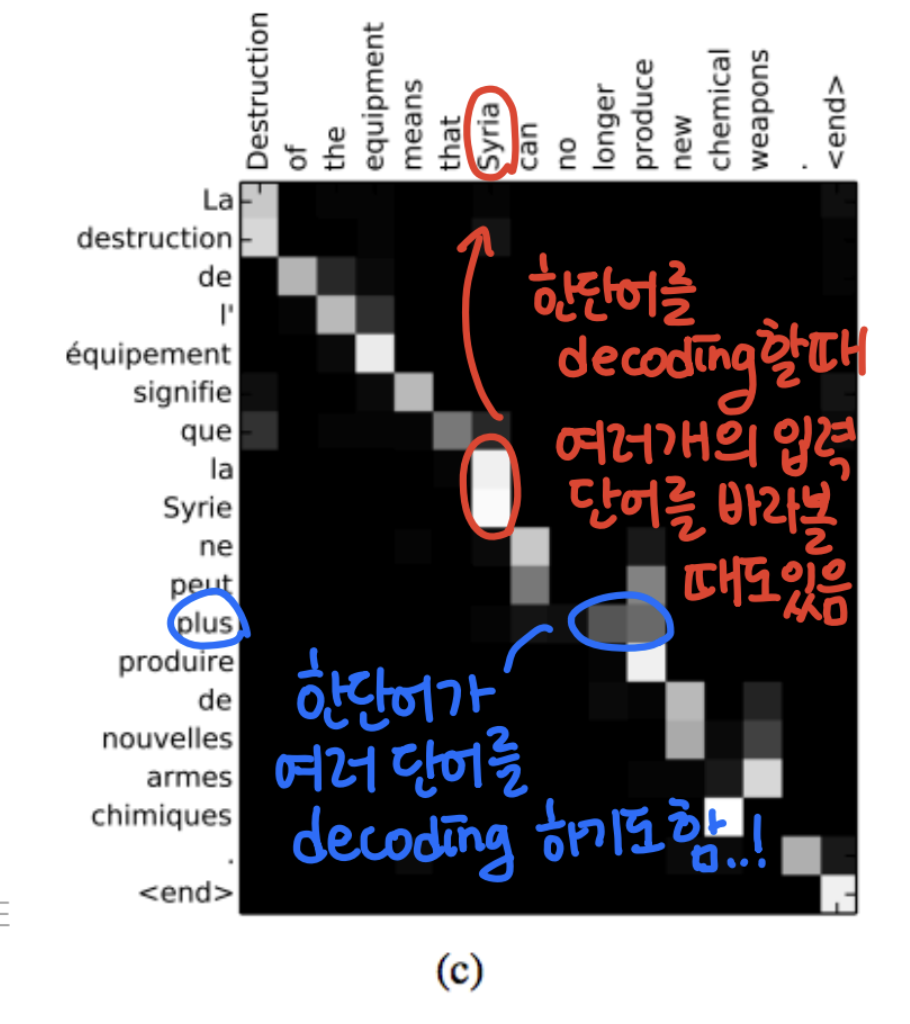
- End-to-end learning : 모델이 번역 task도 학습하면서,동시에 언제 어떤 단어를 봐야할지를 스스로 학습하게 된다.
궁금증 & 회고
-
attention에서 encoder hidden vector와 decoder hidden vector를 내적해서 내적값을 구하는데, 문득 내적값이 음수인 걸 어떻게 해석해야 하는지에 대해 의문이 들었다. 두 단어가 각각 -1, -2가 나왔다면 -1의 경우보다 -2의 경우가 연관성이 더 떨어진다고 보는 게 맞나?? 두 벡터가 완전히 반대 방향을 보고 있으면 이는 그냥 두 단어와 완전 관계가 없다고 봐야 하는건지, 아니면 반대 의미를 가진다고 해석해도 되는건지 궁금하다.
-
Seq2Seq2 with Attention의 과정이 복잡하다고만 생각해서 항상 자신이 없었는데, 이번 기회에 내 언어로 설명을 적다 보니 많은 부분이 이해가 되어 자신감이 좀 생겼다. 다음에 배우는 내용들도 내 언어로 최대한 정리를 해 보아야겠다.
참고
-
Effective Approaches to Attention-based Neural Machine Translation, EMNLP 2015
