[Paper Review] FSPEN: An Ultra-Lightweight Network for Real Time Speech Enhancement
Speech & Audio
출처: https://research.samsung.com/blog/FSPEN-AN-ULTRA-LIGHTWEIGHT-NETWORK-FOR-REAL-TIME-SPEECH-ENAHNCMENT
최근에 speech enhancement 분야를 보고 있는 중인데, 경량화된 모델의 크기나 퍼포먼스가 궁금해서 찾아보던 중 ICASSP 2024에서 발표된 해당 논문을 읽게 되었다. IEEE 접근이 불가능하여(ㅠㅠ) 삼리에서 작성된 글을 대신하여 읽었다.
1. Speech Enhancement
speech enhancement 는 보통 음성에서 배경 잡음과 같은 원하지 않는 노이즈를 제거하여 깨끗한 소리를 만드는 task를 의미합니다. 노이즈가 섞여있으면 음성 인식률이 저하되는 등의 문제가 있기 때문에 보통 음성 자체의 품질을 미리 올려놓는 전처리 작업에 많이 활용 됩니다.
이 논문 같은 경우에는 실시간으로 음성 향상 작업을 하기 위해서 경량화된 모델을 만드는 것을 목표로 하였습니다.
2. FSPEN
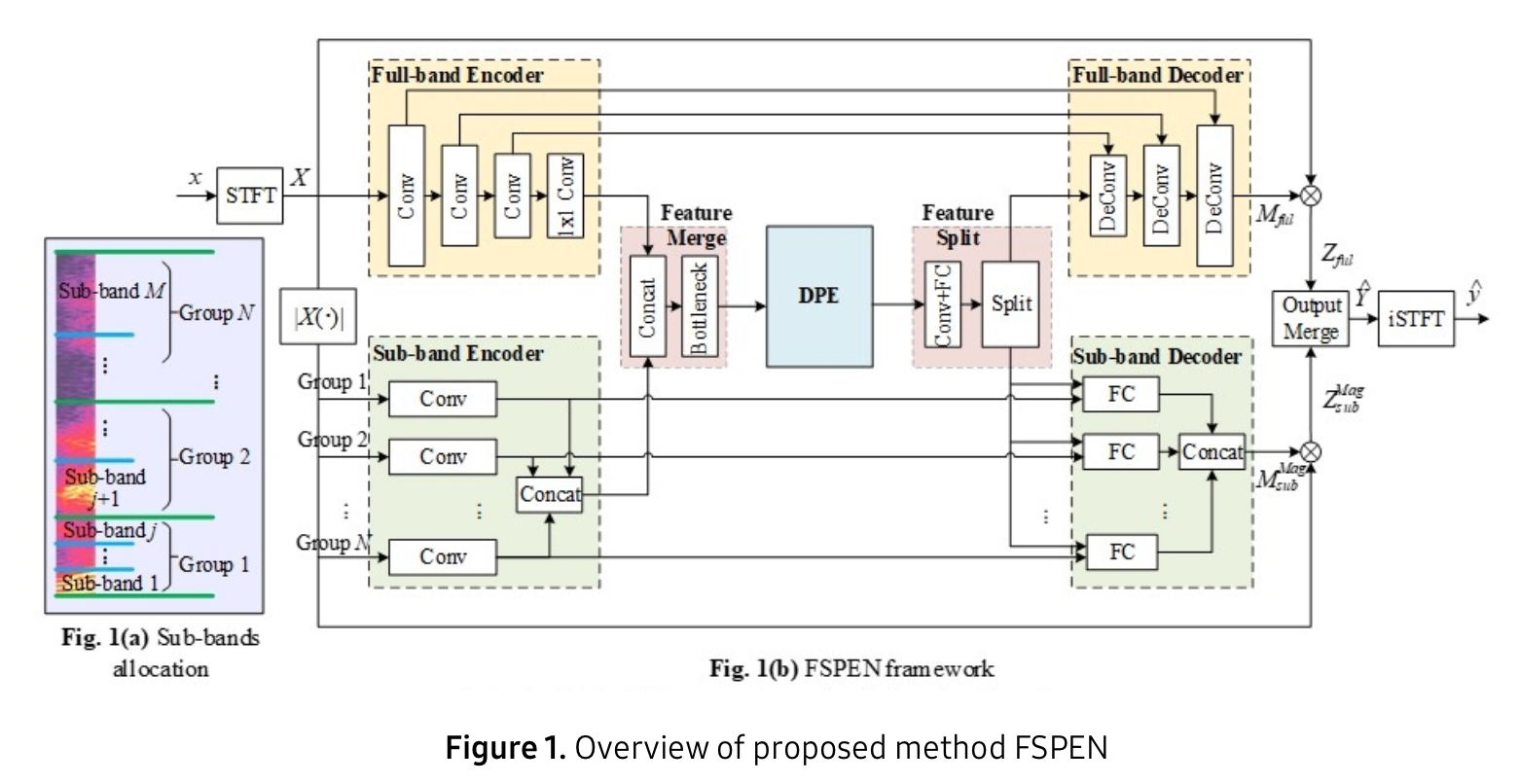
논문의 주된 방법론은, full band 와 sub band 로 모델 구조를 나눠서 global, local features 를 추출하였고, inter-frame path extension 으로 성능을 높였다고 하네요.
좀 더 자세하게 살펴보자면, 그림에서 보시다시피 모델은 크게 다음의 세 파트로 나뉘어 있습니다.
- full-band and sub-band encoder
- Dual Path enhancer with path Extension (DPE)
- full-band and sub-band decoder
우선, encoder 에서는 3-layer CNN으로 이루어져 spectrum 의 feature 를 뽑아냅니다. 1x1 convolution 으로 global feature 를 얻을 수 있지만 local 정보들이 흐리게 나타나는 문제가 발생할 수 있습니다. 이를 해결하기 위해서 1-layer CNN을 sub band encoder 로 활용하여 spectrum 을 처리하는데, k개의 frequency bin이 m개의 sub band 로 나눠지고 m개의 sub band 가 다시 또 N 그룹으로 나누어지는 구조입니다.
어렵게 생각할 필요 없이, global feature 는 말 그대로 spectrum 전체를 가지고 처리하여 정보를 뽑고, local feature 는 spectrum 을 주파수 영역을 나눠 (frequency bin 구역들을 나눠) 각각 CNN으로 처리하고 concat 하여 더 세부적인 local feature 를 처리했다고 보시면 됩니다.
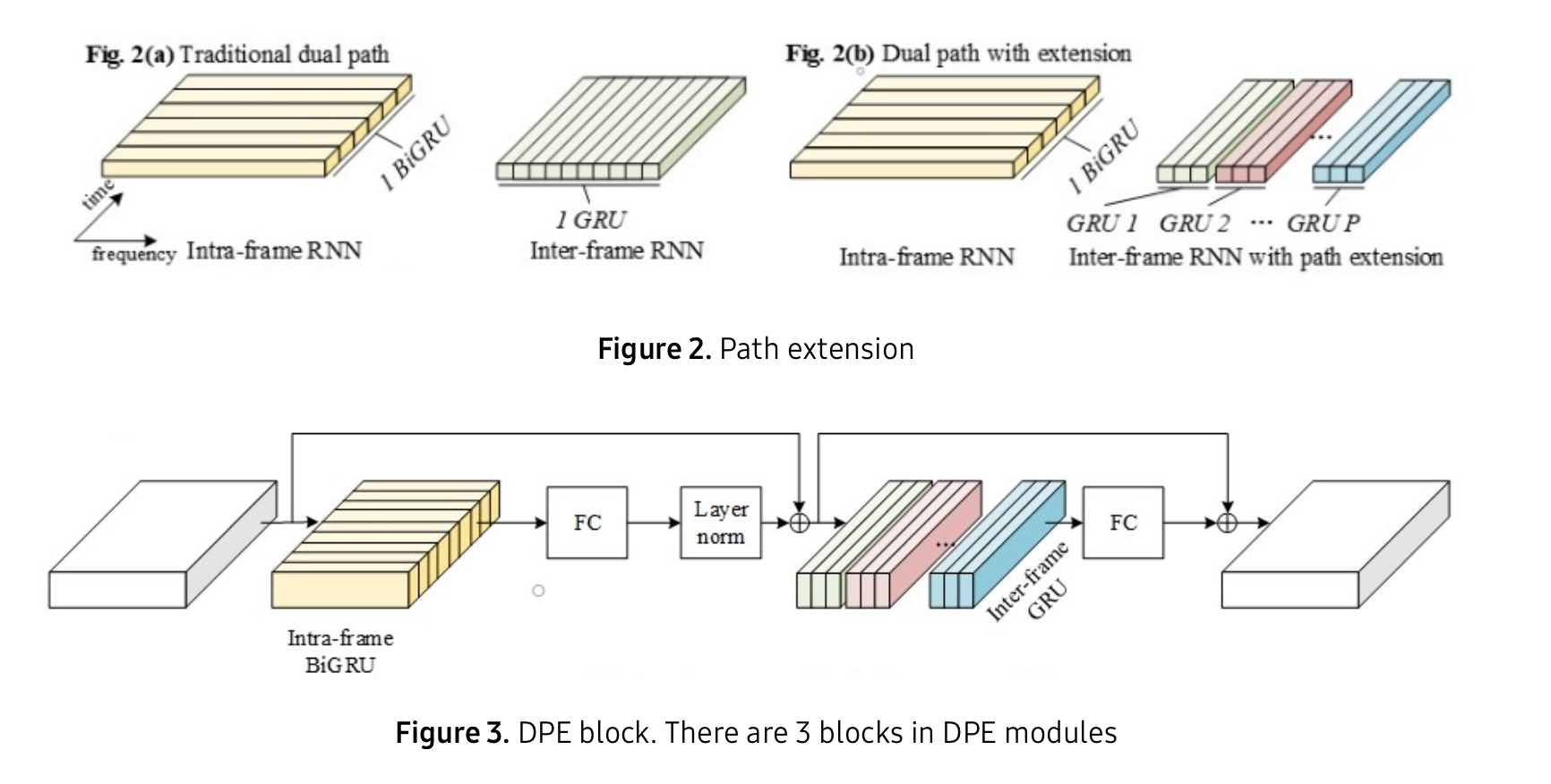
중간에 DPE 같은 경우에는, 일반적인 dual path network는 1개의 GRU 가 causal inter-frame 모델링에 자용되고 1개의 BiGRU가 intra-frame 모델링에 사용됩니다. 이 때, 이러한 dual-path network 에 대해서 부가적으로 설명드리자면, Speech enhancement 모델에서 입력은 보통 time × frequency feature map 형태입니다. 그래서 이런 음성 특성을 반영하여 같은 frame 안에서 frequency 관계 학습하고자 intra-frame modeling을 하고, 시간 방향으로 frame 간 관계 학습하고자 inter-frame modeling을 하는 구조가 Dual-Path Network입니다.
하지만 저자들은 이러한 구조를 개선한 방법론을 제시합니다. 이는 모든 feature를 하나의 GRU로 처리하는 것이 아니라 그룹으로 나누어 각 그룹에 GRU를 적용하는 것입니다.
이렇게 하게 되면 당연히 필요한 GRU의 수가 많아지지만 feature dimension 이 줄어들기 때문에 capacity는 높이면서(더 복잡한 speech pattern이 학습 가능해져 성능이 높아지면서) complexity는 유지(모델의 계산 비용은 유지; MACs 유지)할 수 있습니다. 모델 사이즈가 path extension 적용 후 39k에서 79k로 커졌지만 complexity는 89M MACs(모델이 한 번 추론(inference)할 때 필요한 연산량) 라고 합니다.
마지막으로 디코더의 경우에는 full band 디코더는 skip connection으로 full-band encoder랑 연결되어 있고, 3-layer deconvolution이 적용되어 spectrum을 얻고, 추가적인 complexity를 줄이고자 feature의 채널수는 반으로 줄인다고 합니다. sub-band 디코더도 비슷한 구조이지만 FC 레이어를 사용했습니다.
실험 및 결과
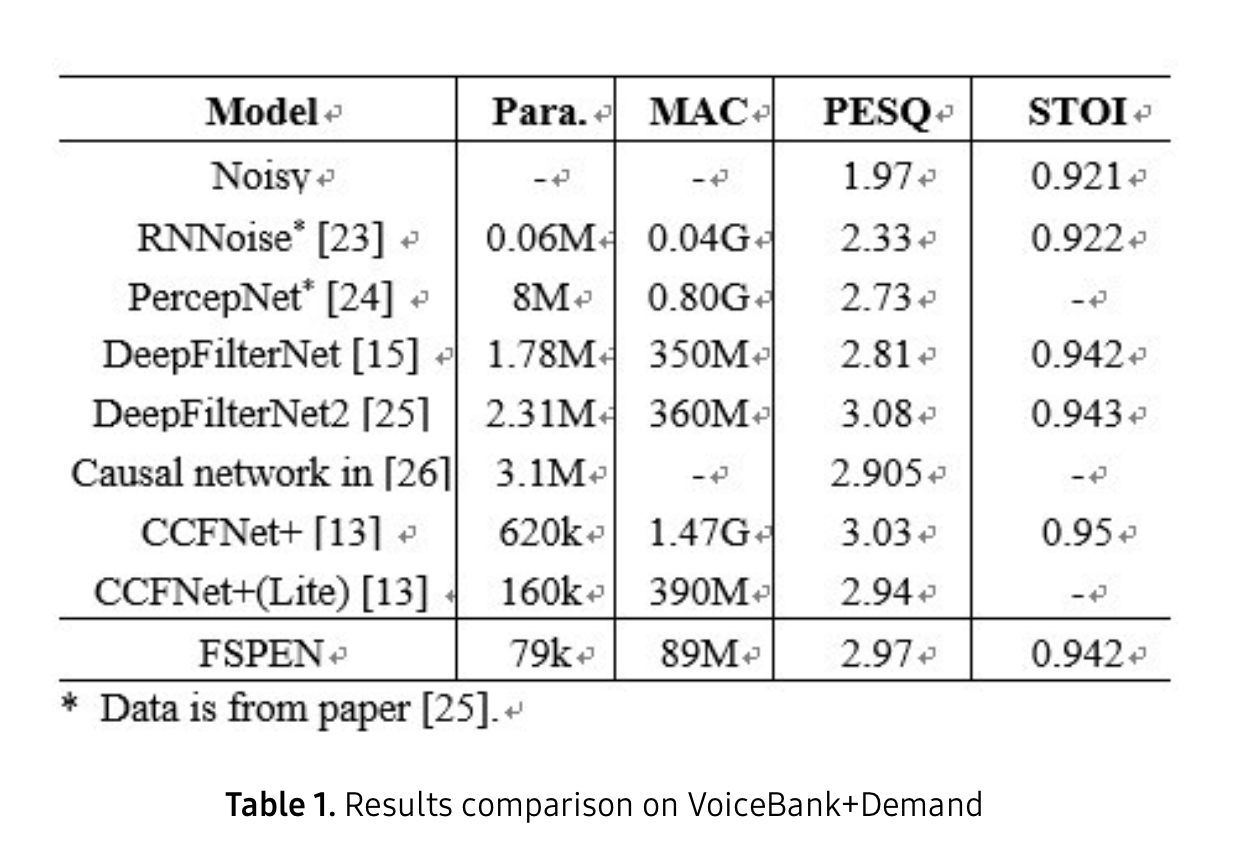
디바이스에 적합하게 작은 파라미터와 연산량 가지고 우수한 PESQ, STOI 성능을 보여줍니다.
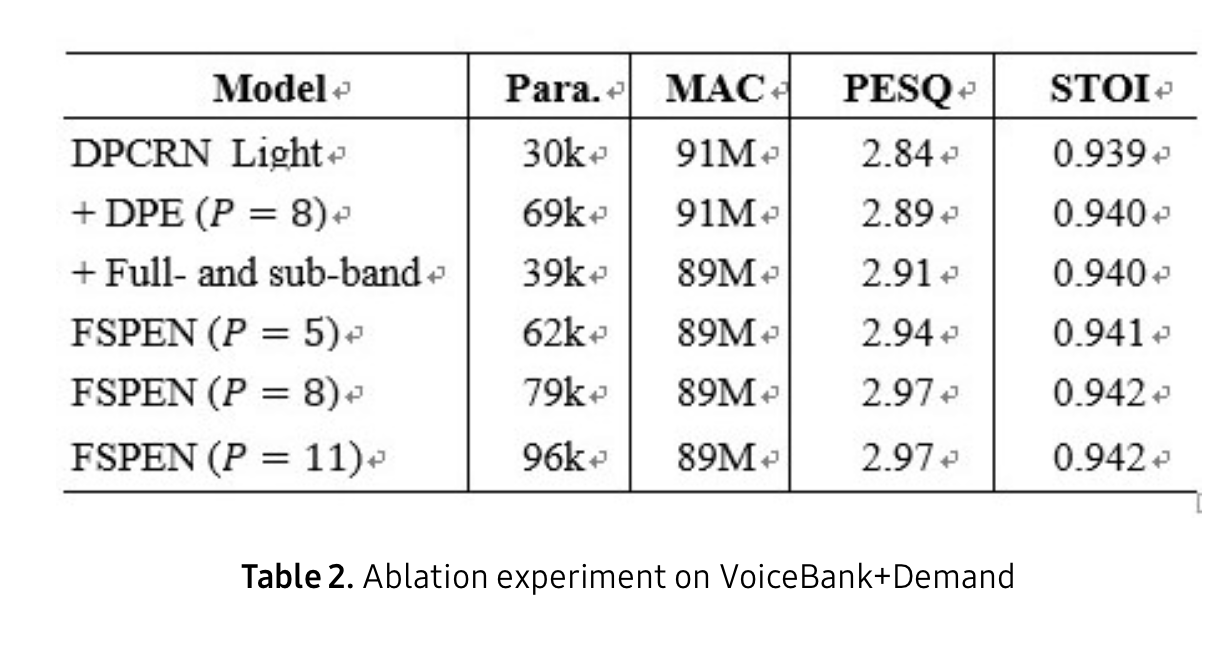
ablation 에서는 DRCRN으로 베이스라인으로 시작하여
DPE와 sub band 모두 각각 성능이 올라가는 것을 볼 수 있으며
GRU 그룹수는 8에서 가장 성능이 좋고 그 이후로는 큰 차이가 없음을 알 수 있습니다.
FSPEN 같은 경우에는 워낙 모델의 사이즈와 연산량이 작다보니 실시간 처리와 온디바이스에 적합한 모델입니다. 음성 연구를 하다보면 전체 정보를 그룹으로 나누어 처리하는 아이디어를 많이 적용하곤 하는데, 이 연구에서는 음성의 feature를 여러 그룹으로 나누어 성능을 높인 연구였습니다.
