지난번 오디오 코덱 mimi에 대해 정리한 것에 이어서 moshi 의 핵심 아키텍처인 temporal transformer, depth transformer 에 대해서도 간단히 정리해보고자 한다.
Moshi
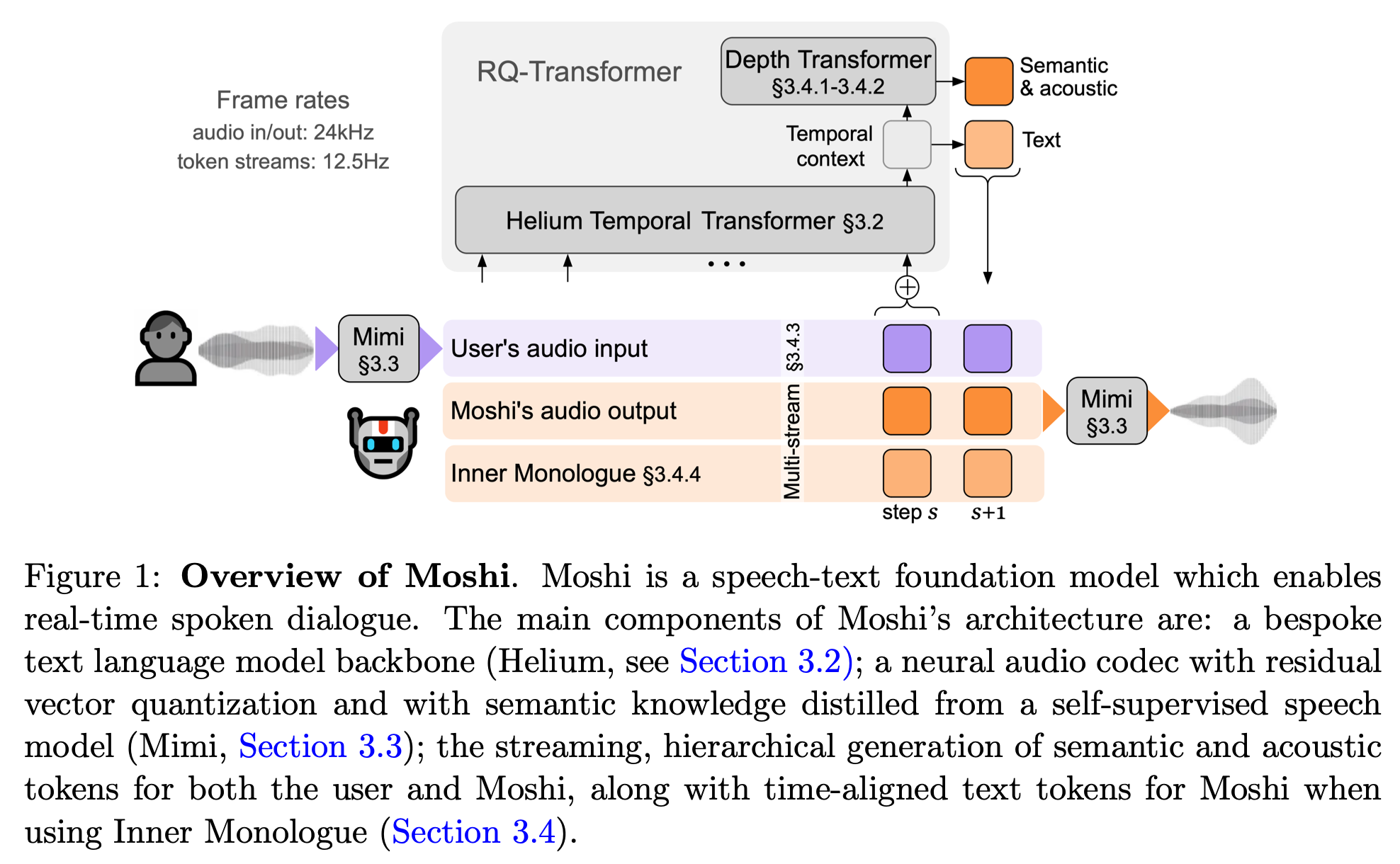
Moshi는 실시간으로 사람과 사람처럼 대화하는 것을 목표로 설계된 speech–text foundation model이다. 이 목표 때문에 Moshi의 아키텍처는 단순히 음성을 잘 표현하는 것에서 그치지 않고, 그 음성을 얼마나 빠르게 생성할 수 있는가, 즉 지연 시간(latency)을 어떻게 감당할 것인가라는 문제에서 출발한다. 이 구조를 이해하기 위해서는 먼저 Moshi가 음성을 어떤 형태의 토큰으로 다루는지부터 살펴볼 필요가 있다.
Moshi에서 오디오는 약 80ms 단위로 잘려 처리된다. 이는 1초짜리 음성을 약 12.5개의 시간 구간으로 나눈다는 뜻이다. 그런데 Moshi는 이 80ms 구간을 하나의 토큰으로 단순화하지 않는다. 대신, neural audio codec인 Mimi를 사용해 각 구간을 여러 개의 토큰으로 분해한다. 구체적으로, 한 time step마다 발화의 의미나 의도를 담은 semantic 토큰 하나와, 음색이나 발음의 미세한 차이를 표현하는 여러 개의 acoustic 토큰이 동시에 생성된다. 결과적으로 하나의 80ms 구간은 총 8개의 토큰으로 표현된다.
이러한 표현 방식은 분명 장점이 있다. 의미 정보와 음향 정보를 분리해 다룰 수 있기 때문에, 음성의 자연스러움과 제어 가능성이 크게 향상된다. 하지만 동시에 새로운 문제가 생긴다. 이 많은 토큰을 어떻게 효율적으로 생성할 것인가 하는 문제다.
가장 단순한 해결책은 이 토큰들을 모두 하나의 긴 시퀀스로 펼쳐서, 기존의 Transformer 언어 모델처럼 순차적으로 예측하는 것이다. 그러나 계산량을 조금만 따져보면 이 방식이 왜 문제가 되는지 금방 드러난다. 1초의 음성에는 약 12.5개의 time step이 있고, 각 step마다 8개의 토큰이 있으므로, 모델은 1초에 거의 100번에 가까운 예측을 수행해야 한다. 이런 방식은 오프라인 환경에서는 가능할지 몰라도, 사용자의 말에 즉각 반응해야 하는 실시간 대화에서는 지연 시간과 연산량 측면에서 현실적인 선택이 아니다.
즉, Moshi가 직면한 핵심 문제는 명확하다. 시간적으로 얼마나 긴 발화가 이어지는지와, 각 순간에 얼마나 복잡한 토큰 구조가 존재하는지를 하나의 Transformer가 동시에 처리하도록 해서는 안 된다는 것이다. 바로 이 지점에서 Moshi의 핵심적인 아키텍처 설계(시간 축과 단일 시점 내부 구조를 분리해 다루는 방식)가 등장한다.
Temporal Transformer
Moshi는 이 문제를 Temporal Transformer + Depth Transformer라는 분리된 구조로 해결한다.
이 둘은 역할이 명확히 다르다.
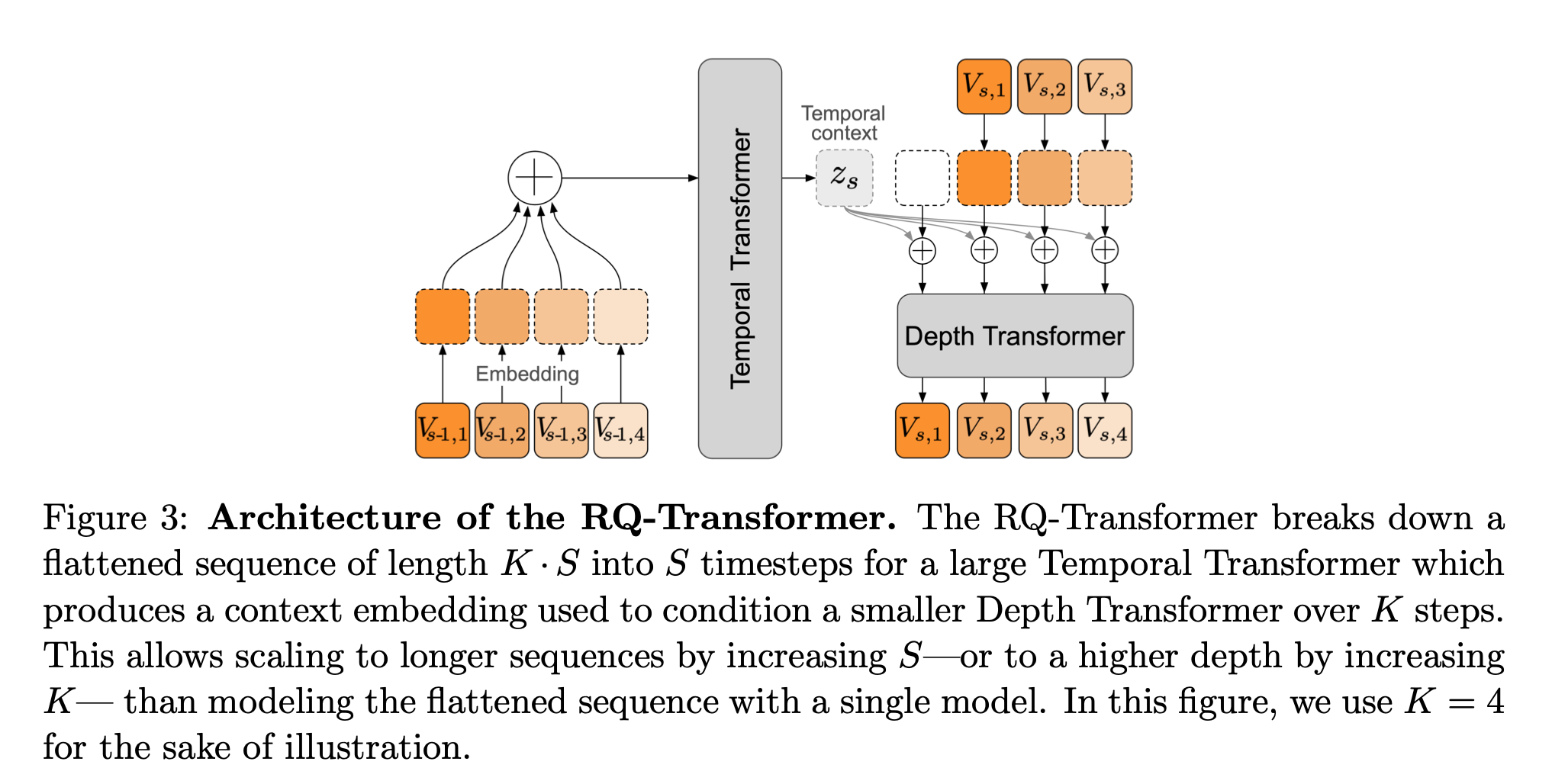
Temporal Transformer는 Moshi 아키텍처에서 시간 축(time dimension)을 따라 동작하는 핵심 모델이다. Moshi는 오디오와 텍스트를 모두 토큰 시퀀스로 다루지만, 각 80ms time step마다 여러 개의 서브 시퀀스(semantic 및 acoustic codebook 토큰)가 동시에 존재하기 때문에, 이들을 단순히 하나의 긴 시퀀스로 펼쳐 모델링하면 계산량과 지연 시간이 크게 증가한다. 이를 피하기 위해 Moshi는 RQ-Transformer 구조를 사용하며, 그 중심에 Temporal Transformer가 위치한다.
RQ-Transformer에서 Temporal Transformer는 길이 (S)의 시간 축을 따라 동작하며, 매 시점 (s)에서 과거의 멀티-시퀀스 토큰을 입력으로 받아 시간 문맥 벡터 (z_s)를 생성한다. 이때 중요한 점은 Temporal Transformer의 step 수가 항상 (S)로 유지된다는 것이다. 즉, 각 time step 안에 존재하는 코드북 개수 (K)에 비례해 시퀀스 길이가 늘어나지 않으며, 모든 코드북 토큰을 길이의 단일 시퀀스로 flatten하는 방식과 비교해 연산량을 크게 줄일 수 있다. 이는 스트리밍 음성 생성에서 필수적인 설계 선택이다.
Temporal Transformer가 생성한 latent는 해당 시점의 시간적 문맥을 표현하는 벡터로, 이후 Depth Transformer의 조건으로 사용된다. 단일 time step 내부에서 어떤 코드북 토큰이 어떤 순서로 생성되는지는 Temporal Transformer가 직접 모델링하지 않는다. 대신, 같은 시점 (s)에서 코드북 인덱스 (k)에 따른 토큰 (V_{s,k})의 예측은, 이전 코드북 토큰들과 Temporal Transformer가 제공한 (z_s)를 입력으로 하는 Depth Transformer가 담당한다. 이로써 시간 방향의 의존성과 단일 시점 내부의 코드북 간 의존성이 명확히 분리된다.
Moshi에서 Temporal Transformer는 텍스트 언어 모델 백본인 Helium과 동일한 아키텍처를 사용하며, 약 7B 파라미터 규모로 구성되어 있다. 반면 Depth Transformer는 훨씬 작은 규모의 모델로 설계된다.
Depth Transformer
Depth Transformer는 Moshi의 RQ-Transformer 구조에서 단일 time step 내부의 코드북 토큰 생성을 담당하는 작은 Transformer 모델이다. Moshi에서 각 time step은 하나의 토큰이 아니라, semantic 토큰과 여러 개의 acoustic 토큰으로 이루어진 다중 서브 시퀀스로 구성된다. 이처럼 동일한 시점에 여러 토큰이 존재하는 경우, 이들 사이의 의존성을 직접 모델링하지 않으면 생성 품질이 크게 저하된다. Depth Transformer는 바로 이 intra-step 코드북 간 의존성을 모델링하기 위해 도입된다.
RQ-Transformer에서 Temporal Transformer가 과거의 토큰 시퀀스으로부터 시간 문맥 벡터를 생성하면, Depth Transformer는 이를 조건으로 사용해 현재 시점 (s)의 코드북 토큰들을 순차적으로 예측한다. 구체적으로, 코드북 인덱스 (k>1)에 대해 Depth Transformer는 (zs)와 이전에 생성된 코드북 토큰들을 입력으로 받아 (V{s,k})의 분포를 추정한다. 첫 번째 코드북 토큰 (V_{s,1})은 Depth Transformer가 아니라, (z_s)에 대한 별도의 선형 계층을 통해 직접 예측된다.
Depth Transformer의 중요한 특징은 시퀀스 길이가 최대 (K)로 제한된다는 점이다. 이는 시간 축 길이 (S)에 비해 매우 짧으며, 전체 오디오를 하나의 긴 시퀀스로 펼쳐 autoregressive하게 생성하는 방식과 비교해 계산 비용을 크게 줄인다. 논문에서 사용된 Depth Transformer는 6개의 레이어, 1024 차원의 hidden size, 16개의 attention head로 구성된 비교적 작은 모델이며, 시간 축 전체를 담당하는 Temporal Transformer에 비해 훨씬 가볍다.
또한 Moshi는 기존 RQ-Transformer 계열 연구와 달리, Depth Transformer 내부에서 코드북 인덱스 (k)마다 서로 다른 파라미터를 사용한다. 이는 semantic 코드북과 acoustic 코드북이 서로 다른 특성을 가지며, 동일한 변환으로 처리하는 것이 비효율적일 수 있다는 점을 반영한 설계다. 논문에서는 이러한 depth-wise 파라미터 분리가 학습과 추론 시간에는 거의 영향을 주지 않으면서도, 생성 품질을 향상시키는 데 도움이 된다고 보고한다.
결과적으로 Depth Transformer는 시간 축의 장기 의존성을 직접 다루지 않고, Temporal Transformer가 제공한 시간 문맥을 바탕으로 단일 time step 내부의 다중 코드북 구조를 효율적으로 풀어내는 역할을 수행한다. 이 분리된 설계 덕분에 Moshi는 스트리밍 환경에서 요구되는 낮은 지연 시간과, 다중 코드북 오디오 토큰 간의 복잡한 상관관계를 동시에 만족시킬 수 있다.
정리하면 Moshi의 핵심은 시간 축과 단일 시점 내부 구조를 명확히 분리한 아키텍처적 선택에 있다. Temporal Transformer는 전체 대화의 시간적 흐름을 따라가며 문맥을 형성하고, Depth Transformer는 각 80ms 구간 안에서 semantic 및 acoustic 코드북 간의 의존성을 효율적으로 모델링한다. 이러한 역할 분리를 통해 Moshi는 오디오 토큰을 flatten했을 때 발생하는 비현실적인 계산 비용을 피하면서도, 스트리밍 음성 생성에 필요한 표현력을 유지할 수 있다. 다음 글에서는 이러한 multi-turn 대화를 가능하게 하기 위해 어떤 데이터셋을 사용했는지, 그리고 token delay 방식 등을 포함해 Moshi가 어떻게 학습되었는지를 정리해보고자 한다.
