작성중...

#Streaming_TTS
✔️ 배경
텍스트를 자연스러운 음성으로 변환하는 기술, 즉 TTS(Text-to-Speech)는 AGI(범용 인공지능)로 가는 길에서 핵심 역량 중 하나로 꼽힙니다. 최근 몇 년간 대규모 데이터셋으로 학습된 신경망 기반 TTS 모델들은 불과 몇 초의 참조 음성만으로도 고품질 음성을 합성해내는 놀라운 능력을 보여주고 있습니다.
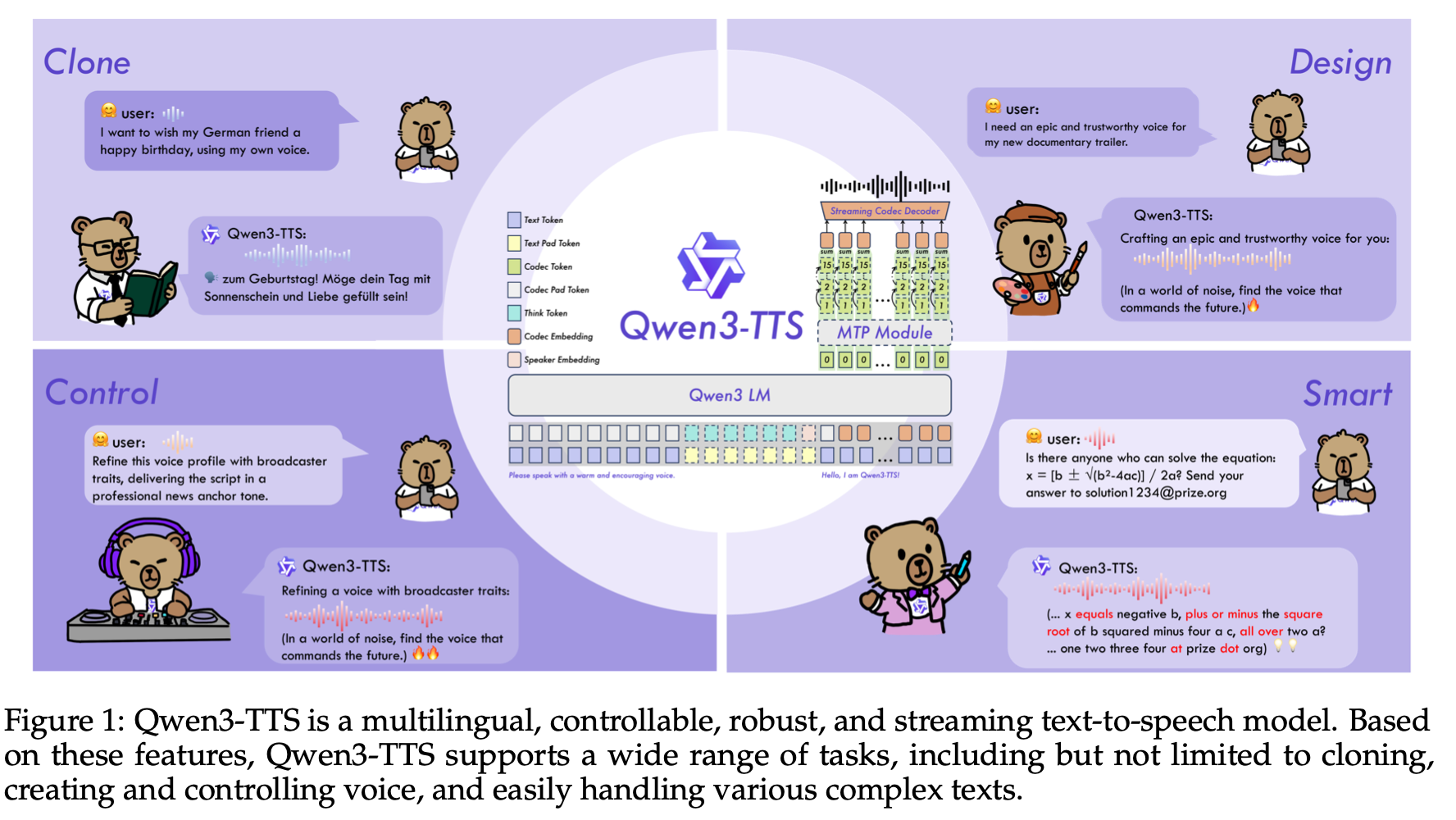
Qwen3-TTS는 Qwen 시리즈에서 최초로 선보이는 TTS 모델입니다. 이 논문은 단순히 목소리를 합성하는 수준을 넘어, 다국어 지원(10개 언어), 3초 음성 클로닝, 자연어 명령을 통한 세밀한 음성 제어, 초저지연 스트리밍이라는 네 가지 핵심 역량을 하나의 프레임워크에 통합한 모델 패밀리를 제안합니다. 그리고 500만 시간이 넘는 음성 데이터로 학습되었다는 점에서, 지금까지 공개된 TTS 모델 중 가장 대규모 학습 기반 중 하나입니다.
최근 TTS 분야에서는 이산적 음성 토큰화(discrete speech tokenization)와 자기회귀 언어 모델링(autoregressive language modeling)의 결합이 큰 주목을 받고 있습니다. 이 방식은 음성 신호를 숫자 코드 시퀀스로 변환한 뒤, 마치 텍스트를 생성하듯 다음 코드를 예측하는 방식으로 음성을 합성합니다. 기존 연속적(continuous) 표현 방식 대비 안정성이 크게 개선되면서도 자연스러움과 인간 유사성을 유지하는 장점이 있습니다. Qwen3-TTS는 이 흐름 위에서, 음성 특징이나 텍스트 지시에 따른 세밀한 운율·스타일 제어까지 가능하게 하여 가상 비서, 자동 콘텐츠 생성 등 다양한 응용 분야의 길을 열어줍니다.
✔️ Paper Info
- Title: Qwen3-TTS Technical Report
- Authors: Hangrui Hu, Xinfa Zhu, Ting He, Dake Guo, Bin Zhang, Xiong Wang, Zhifang Guo, Ziyue Jiang, Hongkun Hao, Zishan Guo, Xinyu Zhang, Pei Zhang, Baosong Yang, Jin Xu, Jingren Zhou, Junyang Lin
- Affiliation: Qwen Team (Alibaba Group)
- Conference:
- Keywords: Text-to-Speech, Speech Tokenizer, Voice Cloning, Streaming Synthesis, Multilingual TTS, Controllable Generation, Multi-Token Prediction, Dual-Track LM Architecture
✔️ Main Problem and Key Approach
기존 TTS의 한계
현재 TTS 기술은 크게 세 가지 도전 과제를 안고 있습니다.
첫째, 의미와 음향 사이의 트레이드오프 문제입니다. 음성을 이산 토큰으로 변환하는 토크나이저 설계에서, 순수한 의미 토크나이저(semantic tokenizer)는 "무슨 말인지"는 잘 포착하지만 음색이나 감정 같은 표현력이 부족합니다. 반대로 순수한 음향 토크나이저(acoustic tokenizer)는 너무 많은 저수준 디테일을 담아서 언어 모델이 다루기 어렵고, 긴 시퀀스에서 오류가 누적됩니다.
토크나이저란? 연속적인 음성 신호를 이산적인(discrete) 토큰(숫자 코드 시퀀스)으로 변환해주는 모듈입니다. 텍스트를 단어나 서브워드 단위로 쪼개는 것처럼, 음성도 일정한 단위로 쪼개서 언어 모델이 처리할 수 있는 형태로 만드는 것이죠.
둘째, 실시간 스트리밍의 어려움입니다. 기존 모델들은 텍스트를 전부 처리한 후에 음성을 생성하거나, 스트리밍을 지원하더라도 첫 패킷 지연(first-packet latency)이 높아 실시간 대화형 응용에 부적합합니다. 특히 DiT(Diffusion Transformer) 같은 복잡한 디코더를 쓰면 품질은 좋지만 지연이 커지는 딜레마가 있습니다.
셋째, 제어 가능성과 다국어 지원의 통합입니다. 음성 클로닝, 음성 설계(자연어로 새 목소리 생성), 스타일 편집, 다국어 합성을 하나의 프레임워크에서 동시에 지원하는 모델은 거의 없었습니다.
Qwen3-TTS의 핵심 접근 방식
이 문제들에 대한 Qwen3-TTS의 해법은 이중 토크나이저 + 이중 트랙 LM 아키텍처라는 설계 철학으로 요약됩니다.
1) 두 종류의 토크나이저를 동시 개발합니다. 의미와 음향 정보를 통합한 25Hz 단일 코드북 토크나이저와, 초저지연 스트리밍에 최적화된 12Hz 다중 코드북 토크나이저를 각각 개발하여 응용 시나리오에 따라 선택할 수 있게 합니다.
2) 이중 트랙(Dual-Track) LM 아키텍처를 채택합니다. 텍스트 토큰과 음향 토큰을 채널 축으로 연결하여, 텍스트가 들어올 때마다 즉시 음향 토큰을 예측하는 스트리밍 구조를 구현합니다. 다중 코드북의 경우 MTP(Multi-Token Prediction) 모듈로 모든 잔여 코드북을 동시 예측하여 지연을 최소화합니다.
3) ChatML 형식 기반의 통합된 제어 체계를 구축합니다. 음성 클로닝, 음성 설계, 스타일 편집을 모두 자연어 지시로 통합하며, 확률적으로 활성화되는 사고 패턴(thinking pattern)을 도입하여 복잡한 지시에 대한 추종 능력을 강화합니다.
4) 대규모 데이터와 체계적 학습 전략을 결합합니다. 500만 시간 이상의 다국어 음성 데이터로 3단계 사전학습을 수행한 뒤, DPO와 GSPO를 포함한 3단계 후학습으로 인간 선호도에 맞추어 품질과 안정성을 끌어올립니다.
✔️ Architecture & Method
1. 모델 패밀리 구성
Qwen3-TTS는 단일 모델이 아니라 10개의 모델 변형으로 구성된 패밀리입니다. 이 모델들은 토크나이저(12Hz / 25Hz), 모델 크기(0.6B / 1.7B), 그리고 기능 특화(Base / VoiceDesign / VoiceEditing / CustomVoice) 세 축으로 분류됩니다.

- Base: 기본 모델. 스트리밍, 다국어, 음성 클로닝을 지원합니다.
- VoiceDesign / VoiceEditing: 자연어 설명 기반으로 새 목소리를 "설계"하거나, 기존 목소리 속성을 "편집"하는 기능 특화 모델입니다.
- CustomVoice: 특정 화자에 대해 파인 튜닝(fine-tuning)된 모델로, 해당 화자의 목소리로 다국어 음성을 생성할 수 있습니다.
2. 음성 토크나이저 (Qwen-TTS-Tokenizer)
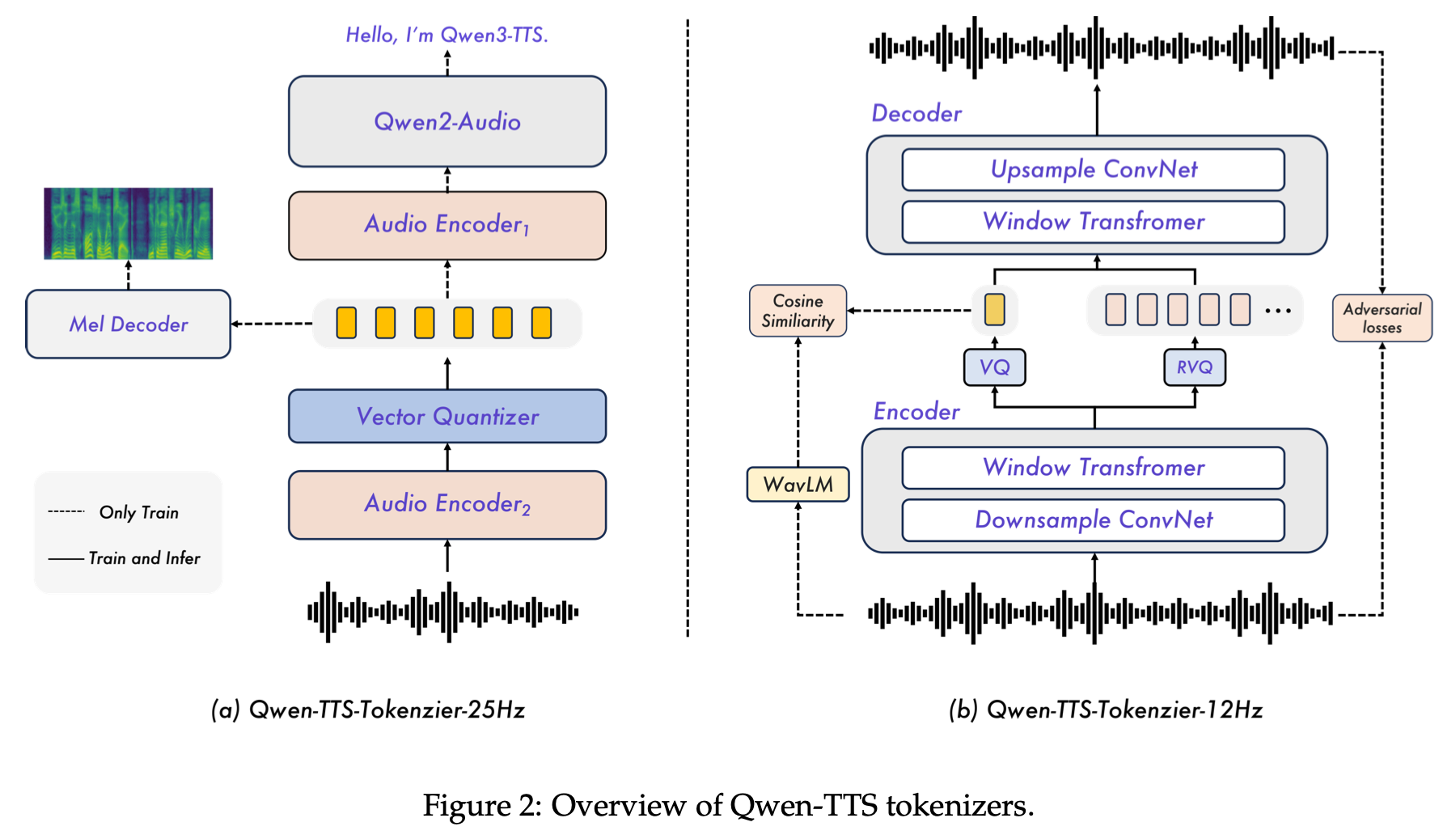
TTS 시스템의 핵심은 음성을 어떻게 표현하느냐에 있습니다. Qwen3-TTS는 이를 위해 서로 다른 설계 철학을 가진 두 가지 토크나이저를 개발했습니다.
2-1. Qwen-TTS-Tokenizer-25Hz: 의미 중심의 단일 코드북
이 토크나이저는 기존의 Qwen2-Audio 모델을 기반으로 만들어졌으며, 초당 25개의 토큰을 생성하는 단일 코드북(single-codebook) 방식입니다. 코드북 크기는 32,768입니다. 학습은 두 단계로 진행됩니다.
Stage 1 (ASR 지도학습): Qwen2-Audio를 자동 음성 인식(ASR) 과제에 대해 추가 사전학습합니다. 이때 오디오 인코더 중간에 리샘플링(resampling) 레이어와 벡터 양자화(VQ) 레이어를 삽입합니다. 이 과정을 통해 음성에서 "무슨 말을 하는지"라는 의미 정보가 토큰에 잘 담기게 됩니다.
Stage 2 (음향 정보 주입): 전체 모델을 파인 튜닝하면서 컨볼루션 기반 멜-스펙트로그램(mel-spectrogram) 디코더를 추가합니다. 이 디코더는 오디오 토큰으로부터 멜-스펙트로그램을 복원하도록 학습되며, 이를 통해 토큰에 음향적(acoustic) 정보도 함께 주입됩니다. 의미적 충실도(semantic fidelity)와 음향적 풍부함(acoustic richness) 사이의 의도적인 트레이드오프를 반영한 설계입니다.
코드북(Codebook)과 벡터 양자화(VQ)란? 코드북은 일종의 "음성 사전"입니다. 연속적인 음성 신호의 한 프레임(짧은 시간 조각)을 가장 가까운 "대표 벡터"로 매핑하는 과정을 벡터 양자화(VQ)라고 하며, 이 대표 벡터들의 모음이 코드북입니다. 단일 코드북은 하나의 사전만 쓰고, 다중 코드북(RVQ)은 첫 번째 사전에서 대략적으로 표현한 뒤 남은 오차를 두 번째, 세 번째 사전으로 점진 보정하는 방식입니다.
멜-스펙트로그램이란? 음성 신호를 시간-주파수 영역에서 표현한 2D 이미지 같은 것입니다. 가로축은 시간, 세로축은 주파수(인간 청각 특성을 반영한 멜 스케일), 각 점의 밝기는 해당 시간-주파수의 에너지 크기를 나타냅니다.
스트리밍 디토크나이저: 블록 단위 DiT + BigVGAN
생성된 코드 시퀀스를 실제 음성 파형으로 바꾸기 위해, DiT(Diffusion Transformer)와 Flow Matching을 결합한 방식을 사용합니다.
스트리밍을 지원하기 위해, 인접한 코드들을 고정 길이의 블록으로 묶고 슬라이딩 윈도우 블록 어텐션(sliding-window block attention)을 적용합니다. DiT의 수용 범위(receptive field)는 총 4블록으로 제한됩니다: 현재 블록 + 3블록 과거(lookback) + 1블록 미래(lookahead). 이렇게 해야 무한히 긴 시퀀스에서도 메모리가 폭발하지 않으면서 충분한 맥락을 유지할 수 있습니다. DiT가 생성한 멜-스펙트로그램은 수정된 BigVGAN 보코더를 통해 최종 음성 파형으로 변환되며, BigVGAN에도 동일한 청크 방식 처리를 적용하여 스트리밍 파형 합성을 지원합니다.
Flow Matching이란? 확산 모델(Diffusion Model)의 변형으로, 노이즈에서 데이터로의 변환 경로를 직선에 가깝게 학습시켜 더 효율적인 생성을 가능하게 하는 기법입니다.
구체적인 스트리밍 동작 방식: 청크 크기 8 설정 기준으로, LM이 16개 토큰을 생성해야 DiT가 첫 8-토큰 멜 청크를 만들 수 있습니다(1블록 lookahead 때문). 25Hz 토큰 속도에서 토큰 1개 = 40ms이므로, 한 패킷 = 320ms의 멜 콘텐츠입니다. BigVGAN 보코더는 추가로 130ms의 우측 컨텍스트를 필요로 합니다. 따라서 첫 패킷에는 약 190ms 분량의 오디오가 포함되며, 정상 상태 스트리밍에서는 LM이 8개 토큰을 생성할 때마다 320ms 분량의 오디오 패킷이 합성됩니다.
2-2. Qwen-TTS-Tokenizer-12Hz: 초저지연을 위한 다중 코드북
이 토크나이저는 Mimi 아키텍처의 의미-음향 분리 양자화(semantic-acoustic disentangled quantization) 전략에서 영감을 받았습니다. 초당 12.5개의 토큰을 생성하며, 코드북 크기 2,048, 총 16개 레이어로 구성됩니다. 음성을 두 개의 이산 코드 시퀀스로 분해합니다:
- 의미 코드북(Semantic Codebook): 고수준 의미 내용을 포착. WavLM이 교사(teacher) 역할을 하여 첫 번째 의미 코드북 레이어가 의미적으로 정렬된 특징을 학습하도록 안내합니다.
- 음향 코드북(Acoustic Codebook): 음향 세부 사항, 운율(prosody) 등을 모델링. 15개 레이어의 잔여 벡터 양자화(RVQ) 모듈로 구성되어, 의미 코드북이 포착하지 못한 디테일을 점진적으로 보정합니다.
학습은 GAN(Generative Adversarial Network) 기반 프레임워크를 사용합니다. 생성기(generator)는 원시 파형에서 직접 특징을 추출하고 양자화하며, 판별기(discriminator)는 복원된 음성의 자연스러움과 충실도를 개선합니다. 추가로 다중 스케일 멜-스펙트로그램 재구성 손실(multi-scale mel-spectrogram reconstruction loss)을 사용하여 시간-주파수 일관성을 확보합니다.
스트리밍 지원의 핵심 — 완전 인과적(Causal) 설계: 인코더와 디코더 모두 미래 프레임을 전혀 참조하지 않고 현재까지의 입력만으로 토큰을 생성하고 음성을 복원합니다. 이것이 25Hz 토크나이저(1블록 lookahead 필요)와의 결정적 차이점입니다.
인과적(Causal)이란? 시간 순서상 미래 정보를 사용하지 않는 설계입니다. 현재 시점 t에서의 출력은 시점 1, 2, ..., t까지의 입력에만 의존합니다. 미래 정보 없이 즉시 처리할 수 있어 스트리밍에 필수적입니다.
12Hz의 스트리밍 동작: 순수 좌측 컨텍스트(left-context only) 코덱 디코더를 사용하므로, 필요한 토큰이 생성되자마자 즉시 파형을 방출할 수 있습니다. 12.5Hz에서 토큰 1개 = 80ms 분량의 오디오. 스케줄링 오버헤드를 줄이기 위해 4개 토큰 = 1 음성 패킷(320ms)으로 정의합니다. 이 경량 설계 덕분에 높은 동시 접속(concurrency) 환경에서도 낮은 RTF를 유지합니다.
3. Qwen3-TTS 전체 아키텍처
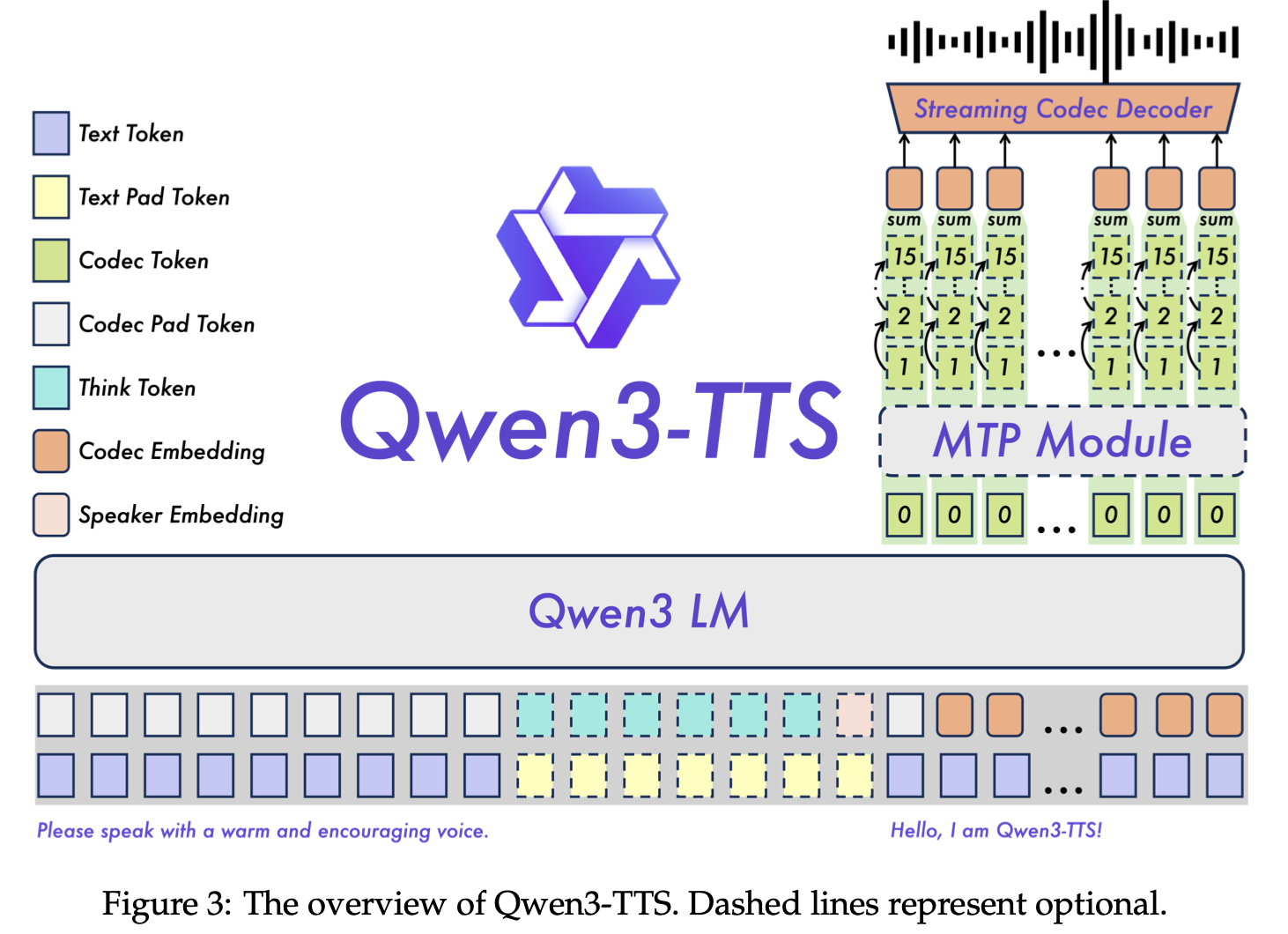
3-1. 이중 트랙(Dual-Track) 설계
Qwen3-TTS는 Qwen3 LM 패밀리를 백본으로 활용합니다. 전체 구조는 다음과 같습니다:
- 입력 처리: 텍스트는 표준 Qwen 토크나이저로, 음성은 Qwen-TTS-Tokenizer로 인코딩됩니다.
- 화자 정체성 제어: 학습 가능한 화자 인코더(speaker encoder)를 백본과 함께 공동 학습(jointly train)하여 정밀한 화자 정체성 제어를 가능하게 합니다.
- 이중 트랙 표현: 실시간 합성을 위해, 텍스트 토큰과 음향 토큰을 채널 축(channel axis)을 따라 연결(concatenate)합니다. 텍스트 토큰을 받으면 모델은 즉시 대응하는 음향 토큰을 예측하고, 이를 Code2Wav 모듈이 파형으로 변환합니다.
이것은 "텍스트를 먼저 다 읽고, 그 다음 음성을 생성한다"는 순차적 방식이 아니라, 텍스트가 들어올 때마다 즉시 음성이 나가는 진정한 스트리밍 구조입니다.
3-2. 25Hz 변형의 예측 방식
25Hz 변형은 단일 수준(single-level) 음성 토큰을 사용합니다. 백본이 텍스트 특징과 이전 음성 토큰을 통합한 후, 선형 헤드(linear head)를 통해 현재 음성 토큰을 예측합니다. 생성된 시퀀스는 청크 단위 DiT 모듈에 의해 고충실도 파형으로 복원됩니다.
3-3. 12Hz 변형의 예측 방식 — MTP 모듈
12Hz 변형은 RVQ 토큰(16개 코드북 레이어)을 다루기 때문에 더 복잡한 예측 구조가 필요합니다. 계층적 예측 체계(hierarchical prediction scheme)를 채택합니다:
- 백본: 집계된 코드북 특징을 입력받아 0번째 코드북(의미 코드북)을 예측합니다.
- MTP(Multi-Token Prediction) 모듈: 나머지 모든 잔여 코드북(1~15번)을 한 번에 생성합니다.
이 전략은 복잡한 음향 세부 사항을 포착하면서도, 단일 프레임 즉시 생성(single-frame instant generation)을 가능하게 하여 지연을 최소화합니다. MTP는 원래 LLM에서 다음 토큰 여러 개를 동시에 예측하는 기법으로 제안되었는데, 여기서는 다중 코드북의 여러 레이어를 동시에 예측하는 데 활용됩니다. 이를 통해 음성 일관성(vocal consistency)과 표현력(expressivity)을 크게 향상시킵니다.
4. 학습 전략: 3단계 사전학습 + 3단계 후학습
모든 데이터는 ChatML 형식으로 포맷팅되어 입력 표준화와 제어 가능한 음성 생성을 지원합니다.
4-1. 사전학습 (Pre-training)
S1 — 일반 단계(General Stage): 500만 시간 이상의 다국어 음성 데이터로 학습합니다. 이 단계에서 다국어 텍스트 표현에서 음성으로의 단조 매핑(monotonic mapping)을 확립하고, 모델의 일반적인 능력을 구축합니다.
단조 매핑이란? 텍스트의 순서와 음성의 순서가 일관되게 대응되도록 하는 것입니다. "안녕하세요"의 "안" → "녕" → "하" → "세" → "요" 순서가 음성에서도 그대로 유지되도록 학습한다는 의미입니다.
S2 — 고품질 단계(High-Quality Stage): 전용 파이프라인으로 데이터 품질을 계층화하고, 고품질 데이터만으로 연속 사전학습(CPT)을 수행합니다. 이 단계는 S1에서 노이즈 데이터로 인해 발생한 환각(hallucination) — 원래 텍스트에 없는 내용을 말하거나, 있는 내용을 빼먹는 현상 — 을 완화하고 생성 음성의 품질을 크게 향상시킵니다.
S3 — 장문맥 단계(Long-Context Stage): 최대 토큰 길이를 8,192 → 32,768로 확장하고, 학습 데이터에서 긴 음성 샘플의 비율을 높입니다. 이를 통해 모델이 긴 입력이나 복잡한 입력을 처리하고, 맥락에 적절한 음성을 생성하는 능력이 향상됩니다.
4-2. 후학습 (Post-training)
사전학습이 끝난 모델을 더 인간적이고 안정적으로 만들기 위한 3단계 후학습이 진행됩니다.
1단계 — DPO(Direct Preference Optimization): 인간 피드백을 기반으로 다국어 음성 샘플의 선호도 쌍(preference pair)을 구성합니다. "이 두 음성 중 어느 것이 더 자연스러운가?"라는 인간의 판단을 모델에 반영하는 것입니다. DPO는 기존 RLHF와 달리 별도의 보상 모델 없이 직접 정책을 최적화할 수 있어 더 안정적입니다.
2단계 — 규칙 기반 보상 + GSPO: 규칙 기반 보상(rule-based rewards)을 사용하고 GSPO 알고리즘을 통해 모델의 능력과 안정성을 과제 전반에 걸쳐 종합적으로 향상시킵니다.
3단계 — 경량 화자 파인 튜닝: 베이스 모델 위에 경량(lightweight) 화자 파인 튜닝을 수행하여, 특정 목소리를 채택하면서도 자연스러움, 표현력, 제어 가능성을 더욱 개선합니다.
5. 주요 기능 (Features)
5-1. 음성 클로닝 (Voice Cloning)
Qwen3-TTS는 두 가지 방식으로 목표 음성을 클로닝합니다:
- 화자 임베딩 기반: 참조 음성에서 화자 임베딩(speaker embedding)을 추출하여 실시간 클로닝을 수행합니다. 빠르지만 운율(prosody) 보존에는 한계가 있을 수 있습니다.
- 인컨텍스트 러닝(In-Context Learning) 기반: 텍스트-음성 쌍을 제공하여 문맥 학습 방식으로 클로닝합니다. 운율을 더 잘 보존하지만 추가 컨텍스트가 필요합니다.
5-2. 음성 설계 (Voice Design)
Qwen3 텍스트 모델 기반으로 구축되었기 때문에, 강력한 텍스트 이해 능력을 상속받습니다. "따뜻하고 신뢰감 있는 중저음의 남성 목소리"와 같은 자연어 설명을 제공하면, 모델이 해당 설명에 맞는 완전히 새로운 목소리를 생성할 수 있습니다. 복잡한 설명에 대한 지시 따르기 능력을 향상시키기 위해, 학습 중에 확률적으로 활성화되는 사고 패턴(probabilistically activated thinking pattern)을 도입했습니다.
5-3. 세밀한 제어 (Fine-grained Control)
음성 설계 능력을 기반으로, 사전 정의된 목소리에 원하는 스타일을 적용하는 것도 가능합니다. 예를 들어, 특정 화자의 목소리를 유지하면서 "뉴스 앵커 톤으로 전달해 주세요"와 같은 스타일 변경 지시를 따를 수 있습니다.
6. 효율성: 지연 시간과 스트리밍 성능
First-Packet Latency: 입력을 받은 후 첫 번째 오디오 조각이 나올 때까지의 시간. 작을수록 사용자가 "바로 대답한다"고 느낍니다.
RTF(Real-Time Factor): 1초 분량의 오디오를 생성하는 데 걸리는 실제 시간의 비율. RTF < 1이면 실시간보다 빠르게 생성 가능합니다.
모든 수치는 vLLM 엔진(V0 백엔드)에서 torch.compile + CUDA Graph 가속을 적용하여 단일 컴퓨팅 자원에서 측정한 엔드투엔드 지연입니다.
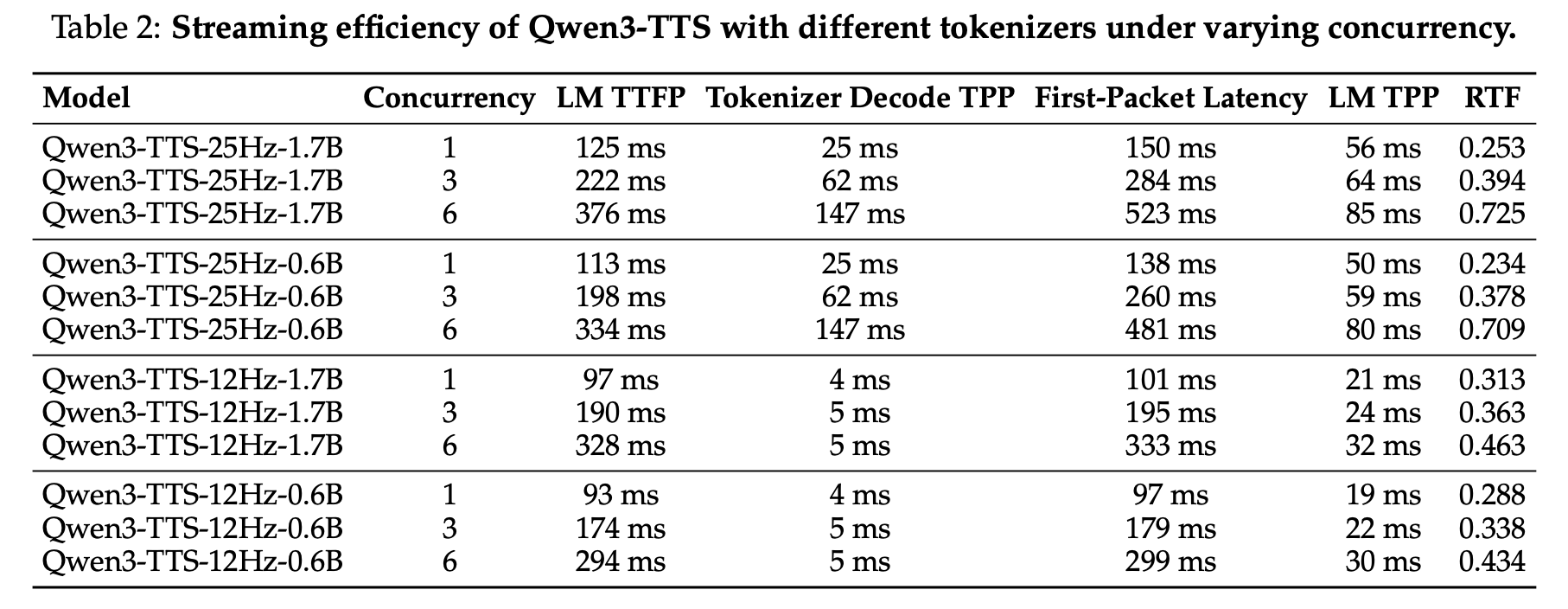
핵심 관찰:
- 12Hz 변형이 첫 패킷 지연에서 압도적으로 빠른 이유: 인과적 디코더 덕분에 미래 토큰을 기다릴 필요가 없기 때문입니다.
- 12Hz 토크나이저의 디코드 시간이 4~5ms로 일정한 반면, 25Hz는 25~147ms(동시접속에 따라 변동)입니다. 경량 인과적 ConvNet이 DiT + BigVGAN 파이프라인보다 훨씬 가볍고 배치 처리에 친화적(batch-friendly)입니다.
- 동시접속 6에서도 12Hz 토크나이저 디코드 시간은 거의 변하지 않습니다.
✔️ Dataset & Evaluation
학습 데이터
- 규모: 500만 시간 이상의 음성 데이터
- 언어: 10개 언어 (중국어, 영어, 독일어, 이탈리아어, 포르투갈어, 스페인어, 일본어, 한국어, 프랑스어, 러시아어)
- 품질 관리: S2 고품질 단계에서 전용 파이프라인으로 데이터 품질 계층화 후 고품질 데이터만 사용
평가 벤치마크 및 지표
토크나이저 평가:
- 25Hz: CommonVoice(C.V.)와 Fleurs 벤치마크의 영어·중국어 서브셋에서 ASR WER 측정. S3 Tokenizer 시리즈와 비교.
- 12Hz: LibriSpeech test-clean(2,620 발화)에서 음성 재구성 품질 측정. PESQ(WB/NB), STOI, UTMOS, SIM(WavLM 기반 화자 유사도).
음성 생성 평가 — 6가지 시나리오:
| 시나리오 | 벤치마크 | 주요 지표 | 비교 대상 |
|---|---|---|---|
| 제로샷 음성 생성 | Seed-TTS test set | WER↓ | Seed-TTS, CosyVoice 3, MiniMax 등 |
| 다국어 음성 생성 | TTS multilingual test set | WER↓, SIM↑ | MiniMax-Speech, ElevenLabs |
| 교차 언어 음성 생성 | CV3-Eval | WER/CER↓ | CosyVoice 시리즈 |
| 제어 가능한 음성 생성 | InstructTTSEval | APS↑, DSD↑, RP↑ | GPT-4o-mini-tts, Gemini, Hume 등 |
| 대상 화자 다국어 생성 | TTS multilingual test set | WER↓ | GPT-4o-Audio-Preview |
| 장문 음성 생성 | 내부 데이터셋 (100개 × 2언어) | WER↓ | Higgs-Audio-v2, VibeVoice, VoxCPM |
지표 설명:
- WER(Word Error Rate): 합성 음성을 ASR로 텍스트 변환 후 원본과 비교한 오류율. 낮을수록 좋음.
- CER(Character Error Rate): 문자 단위 오류율. 중국어 등 비알파벳 언어에 사용.
- SIM(Speaker Similarity): 화자 유사도. WavLM 기반 코사인 유사도. 높을수록 좋음.
- PESQ: 음성 품질의 객관적 측정 (WB=광대역, NB=협대역).
- STOI: 음성 명료도 (0~1, 높을수록 좋음).
- UTMOS: MOS(평균 의견 점수) 자동 추정. 인간이 느끼는 자연스러움을 예측.
- APS(Attribute Perception and Synthesis accuracy): 속성 인식·합성 정확도.
- DSD(Description-Speech Consistency): 설명과 음성 간 일관성.
- RP(Response Precision): 응답 정밀도.
✔️ Results
1. 토크나이저 평가 결과
25Hz 토크나이저 — ASR 성능
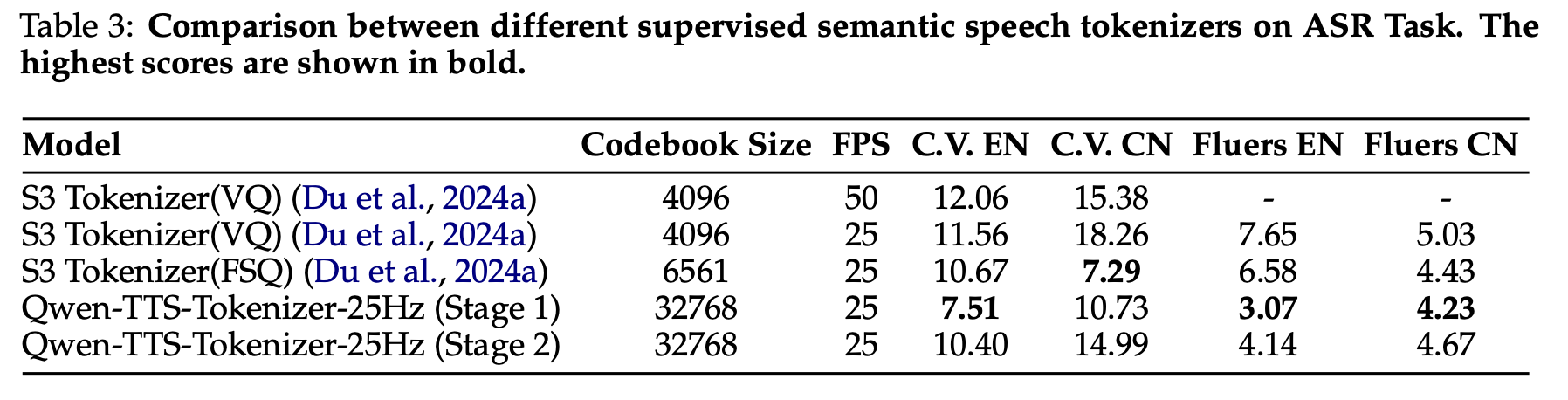
- S1 단계의 25Hz 토크나이저가 대부분의 데이터셋에서 S3 Tokenizer와 동등하거나 더 낮은 WER 달성
- S2 단계에서 ASR 성능이 약간 하락 → 의도된 트레이드오프: 음향 정보가 추가되면서 순수 의미적 변별력이 감소하지만, 하류 TTS 과제에는 이로움
12Hz 토크나이저 — 음성 재구성 (LibriSpeech test-clean)
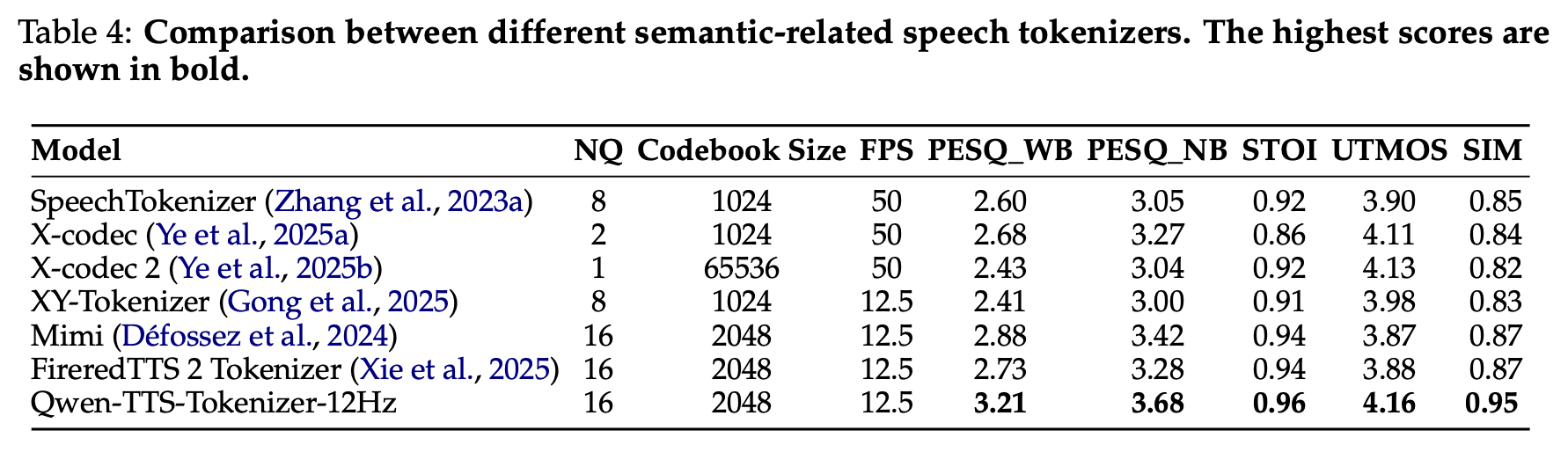
- 모든 지표에서 SOTA 달성, 특히 SIM(화자 유사도) 0.87 → 0.95로의 대폭 도약
- 12.5Hz라는 낮은 프레임 레이트에서 이 성능 → 품질과 효율성 양쪽 모두에서의 돌파구
2. 제로샷 음성 생성 (Seed-TTS test set)
핵심 발견 3가지:
1. 다양한 음향 데이터로의 사전학습과 CPT 덕분에 다국어에서 고르게 강건한 성능
2. 12Hz 변형이 25Hz보다 일관되게 더 낮은 WER → 더 거친 시간 해상도가 장기 의존성 모델링에 유리
3. 0.6B → 1.7B 스케일링이 일관된 성능 향상 제공
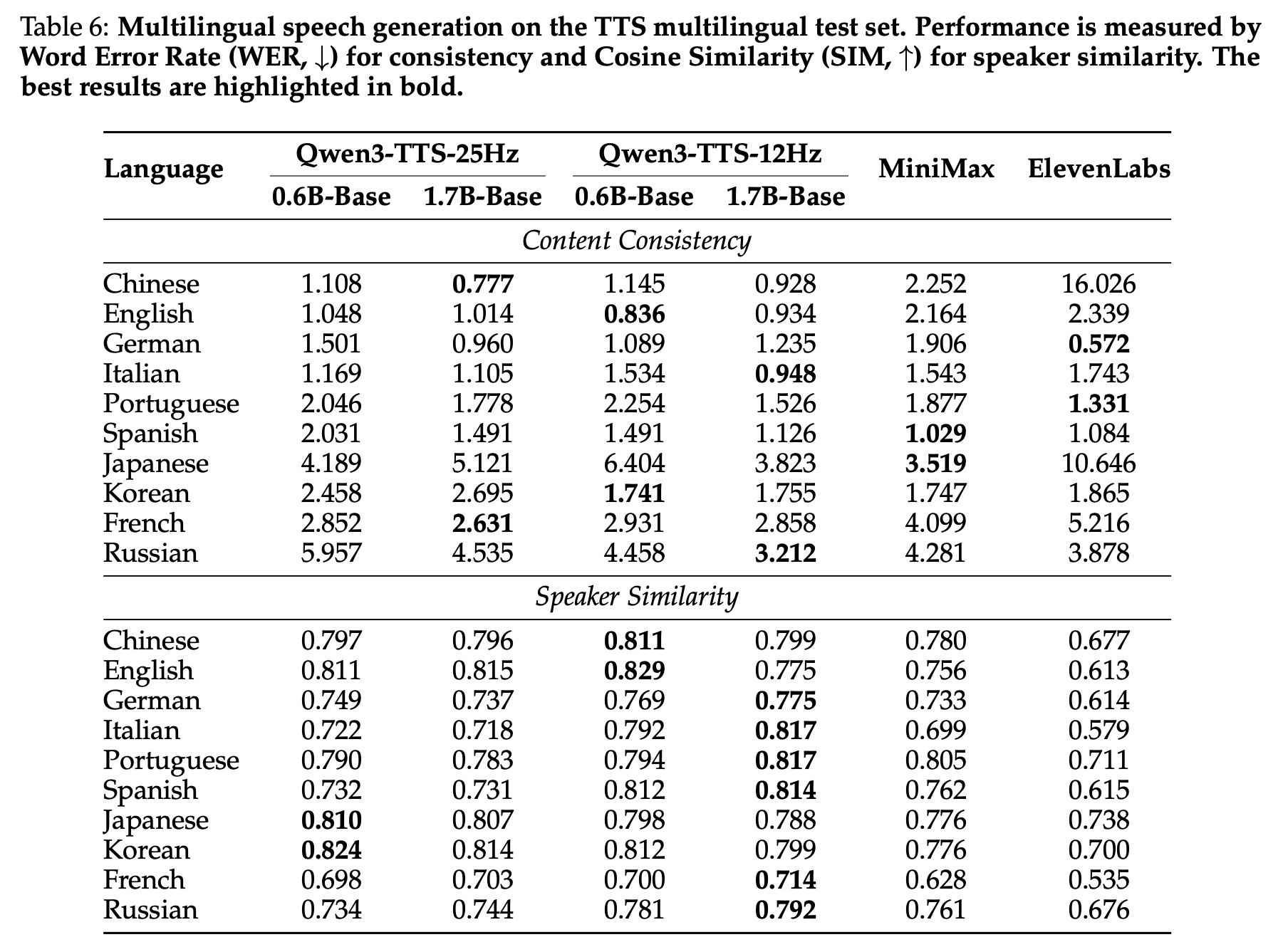
3. 다국어 음성 생성 (TTS multilingual test set)
콘텐츠 일관성 (WER↓) — 주요 결과 발췌:
- 10개 언어 중 6개에서 최저 WER, 나머지 4개에서도 SOTA 수준 경쟁력
- 특히 ElevenLabs의 중국어 WER 16.026 대비 Qwen3-TTS의 0.928은 압도적 차이
화자 유사도 (SIM↑): 모든 10개 언어에서 최고 화자 유사도 달성. MiniMax-Speech와 ElevenLabs를 전 언어에서 일관 능가.
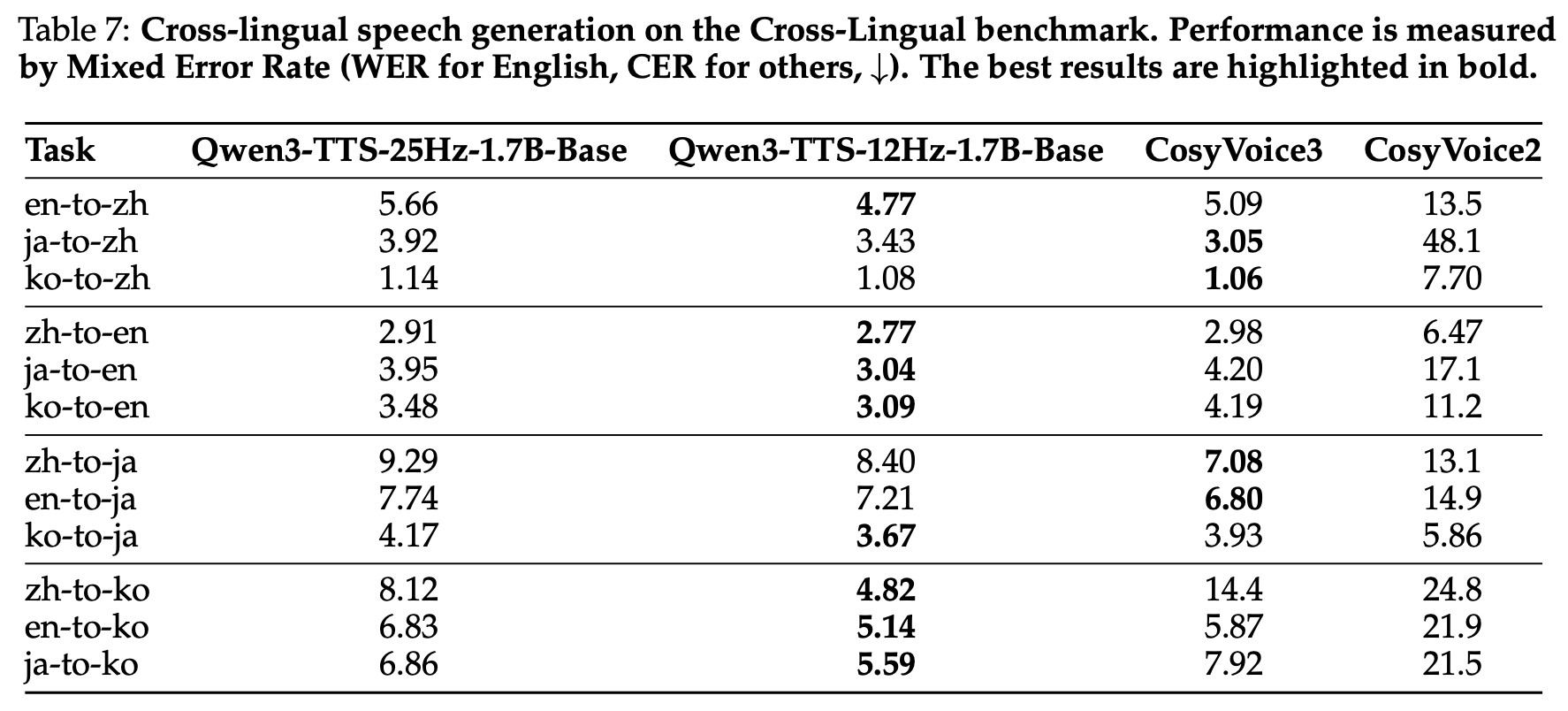
4. 교차 언어 음성 생성 (CV3-Eval)
- zh→ko에서 에러율 66% 감소 (4.82 vs 14.4) — 가장 눈에 띄는 교차 언어 일반화 성과
- CosyVoice2는 여러 쌍에서 불안정(ja→zh 48.1)한 반면, Qwen3-TTS는 모든 방향에서 일관되게 낮은 에러율 유지
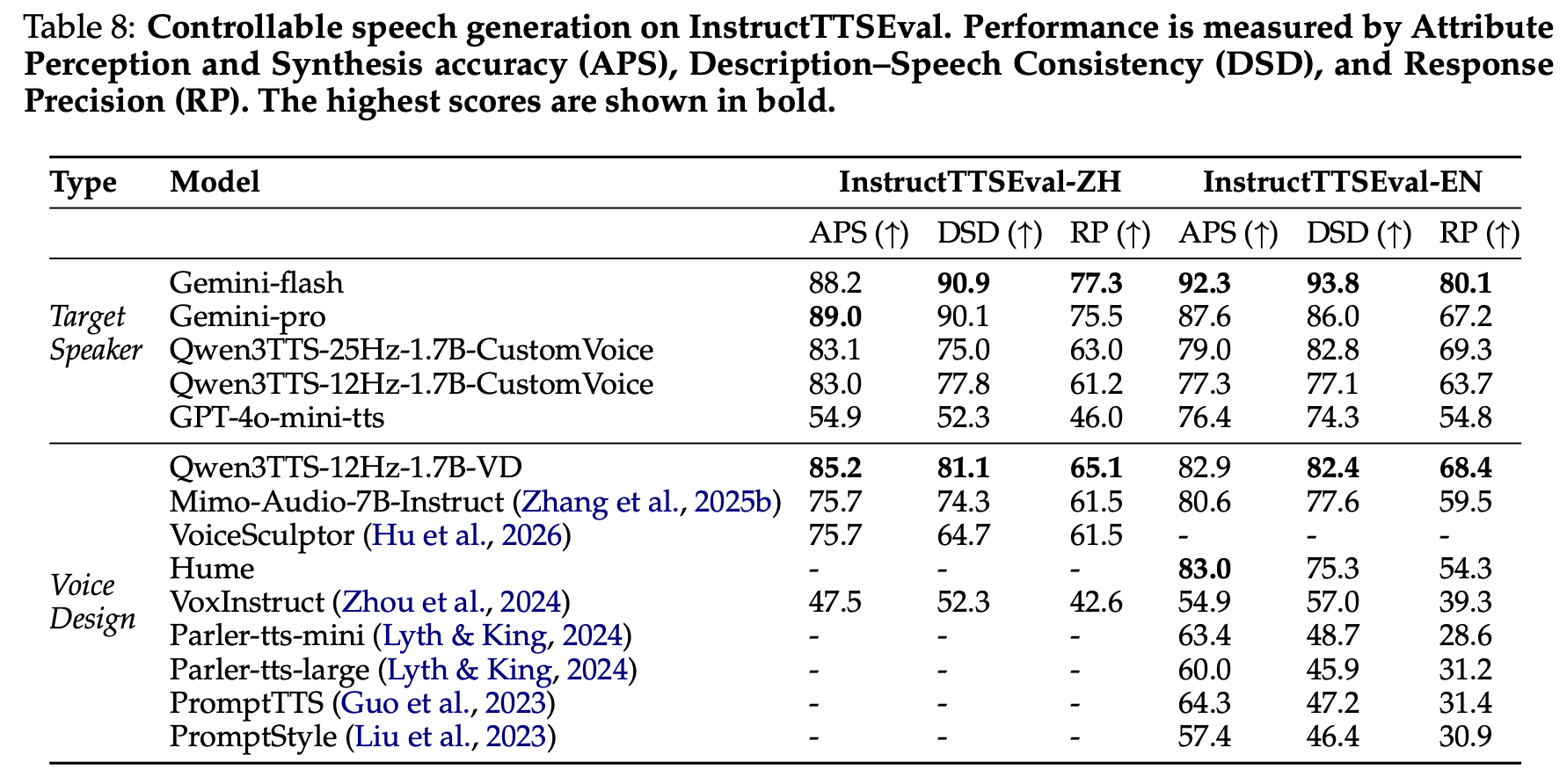
5. 제어 가능한 음성 생성 (InstructTTSEval)
음성 설계(Voice Design/Creation)
- 오픈소스 모델 중 SOTA, 상용 시스템 Hume보다 DSD·RP에서 우수
대상 화자 편집(Target Speaker Editing)
- Qwen3-TTS가 GPT-4o-mini-tts를 모든 지표에서 크게 능가 (중국어 APS +28%p)
- Gemini가 상한선이지만, Qwen3-TTS도 경쟁력 있는 성능 시현
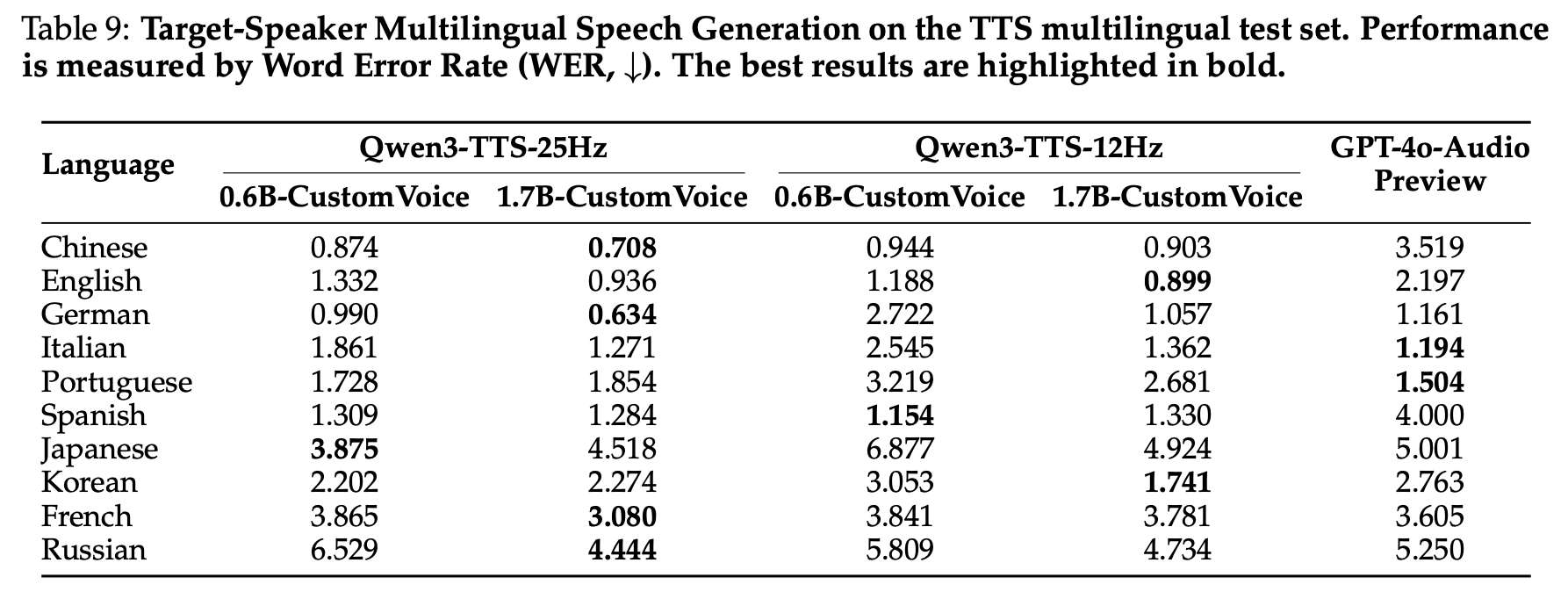
6. 대상 화자 다국어 생성 (TTS multilingual test set)
Aiden Voice에 파인 튜닝한 Qwen3-TTS vs GPT-4o-Audio-Preview(Ballad Voice):

- 단일 언어(monolingual) 파인 튜닝 데이터로만 학습했음에도 10개 언어 중 7개에서 GPT-4o 능가
- 도전적 언어에서 특히 큰 차이: 한국어(1.74 vs 2.76), 중국어(0.90 vs 3.52)
7. 장문 음성 생성 (내부 데이터셋, 200~2000 단어, 10분 이상)
- 25Hz 변형이 양쪽 언어 모두에서 최저 WER 달성
- VibeVoice는 중국어에서 WER 22.6으로 심각한 성능 저하, Higgs-Audio-v2는 청크 경계 아티팩트 문제
- Qwen3-TTS는 전체 길이에 걸쳐 끊김 없는 일관된 운율 생성
흥미로운 발견: 장문에서는 25Hz > 12Hz. 의미 토큰이 장기 시퀀스 안정성 유지에 유리할 수 있음 → 두 토크나이저가 서로 다른 강점을 가진다는 증거.
종합 시사점
두 토크나이저의 상보적 관계: 이 논문의 핵심 설계 결정 중 하나는 단일 토크나이저를 고르는 대신 두 개를 모두 개발하고 공개한 것입니다.
- 12Hz: 제로샷 클로닝, 다국어 생성, 교차 언어 전이에서 우수. 초저지연(97ms) 스트리밍에 최적. 화자 유사도 최고.
- 25Hz: 장문 생성에서 더 안정적. Qwen-Audio 에코시스템 통합에 유리. 음성 편집(VoiceEditing) 기능 지원.
스케일의 힘: 500만 시간의 학습 데이터가 다국어 성능, 교차 언어 일반화, 제로샷 클로닝의 기반. 단일 언어 파인 튜닝만으로도 10개 언어로 일반화되는 것은 사전학습의 다국어 표현 능력이 충분히 강력하다는 증거입니다.
LLM 기반 TTS의 방향성: 음성 합성을 언어 모델링 과제로 프레이밍하고, ChatML 형식, 자연어 지시, 확률적 사고 패턴 등을 통해 LLM의 텍스트 이해·생성 능력을 음성 도메인에 전이. TTS와 LLM이 궁극적으로 하나의 통합 모델로 수렴할 것이라는 업계 방향성과 맞닿아 있습니다.
✔️ Resources
