[Paper Review] – StreamFlow: Streaming Audio Generation from Discrete Tokens via Streaming Flow Matching
Speech & Audio
#streaming_decoder(≈vocoder)
✔️ 배경
최근 많은 기업들이 실시간 음성 대화 서비스를 만들겠다는 목표를 내세우고 있습니다. 구글은 말하는 즉시 다른 언어로 통역해주는 실시간 음성 번역을 선보였고, 프랑스 연구팀이 만든 Moshi는 사람처럼 말을 주고받으며 심지어 상대방 말 중간에 끼어들 수도 있는 양방향(full-duplex) 대화 시스템을 공개했습니다. 음성 AI의 패러다임이 근본적으로 바뀌고 있는 것이죠.
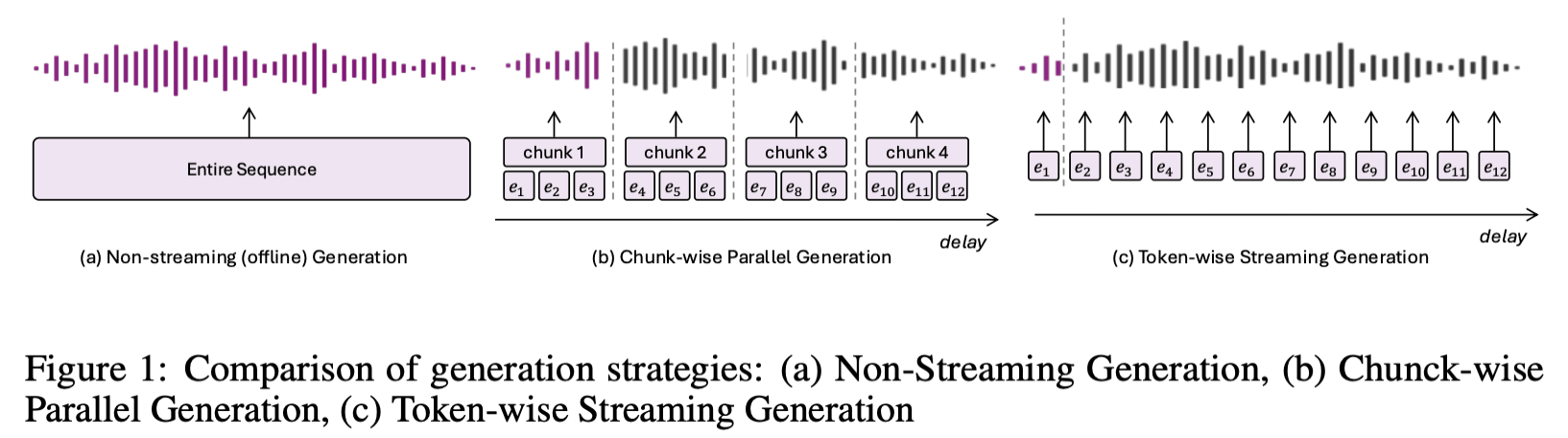
그런데 "실시간 음성 대화"라는 한마디 안에는 사실 여러 기술 방식이 숨어 있습니다. 논문 리뷰에 앞서, 현재 음성 AI가 어떤 구조로 동작하는지 세 가지 방식을 비교하면서 살펴보겠습니다.
방식 1: STT → LLM → TTS (전통적인 파이프라인)
가장 이해하기 쉬운 구조입니다. 세 단계를 순서대로 거칩니다.
- STT (Speech-to-Text): 사용자의 음성을 텍스트로 변환합니다. "오늘 날씨 어때?"라고 말하면, 이 단계에서 글자로 바꿔줍니다.
- LLM (Large Language Model): 변환된 텍스트를 AI가 읽고, 답변 텍스트를 생성합니다. ChatGPT 같은 대형 언어 모델이 여기에 해당합니다.
- TTS (Text-to-Speech): AI가 만든 답변 텍스트를 다시 사람 목소리로 읽어줍니다.
이 방식의 장점은 각 단계가 독립적이라 개발하고 교체하기 쉽다는 것입니다. 하지만 치명적인 단점이 있습니다. AI가 답변 텍스트를 전부 다 만들 때까지 기다린 후에야 음성 변환이 시작됩니다. 긴 답변이라면 사용자는 몇 초간 침묵을 견뎌야 하죠.
방식 2: STT → LLM → Streaming TTS (스트리밍 음성 합성)
위 문제를 해결하기 위해 등장한 방식이 스트리밍 TTS입니다.
핵심 아이디어는 간단합니다. LLM이 답변 텍스트를 한 글자, 한 단어씩 만들어내는 즉시 TTS가 바로바로 음성으로 변환하기 시작하는 것입니다. 전체 문장이 완성될 때까지 기다리지 않습니다.
스트리밍 방식은 사용자 입장에서는 질문하자마자 거의 곧바로 음성 답변이 흘러나오기 시작하므로, 훨씬 자연스러운 대화 경험을 얻을 수 있습니다.
다만 이 방식에도 기술적 어려움이 있습니다. TTS 엔진이 아직 생성되지 않은 뒤쪽 문맥을 모른 채 음성을 만들어야 하기 때문에, 억양이나 발음의 자연스러움이 떨어질 수 있습니다. 문장 전체를 보고 만드는 것과 앞부분만 보고 만드는 것의 품질 차이가 존재하는 것이죠.
방식 3: Speech-to-Speech (음성 직통 방식)
마지막 방식은 최근 활발히 연구되고 있는 분야 입니다. 중간에 텍스트를 거치지 않고, 음성이 들어오면 곧바로 음성으로 대답하는 모델입니다.
기존 방식이 "듣기 → 받아적기 → 생각하기 → 글쓰기 → 낭독하기"였다면, Speech-to-Speech는 사람의 뇌처럼 "듣기 → 바로 말하기"에 가깝습니다. 텍스트 변환이라는 중간 단계가 사라지니 속도가 빨라지는 것은 물론이고, 말투, 감정, 억양같은 비언어적 정보까지 더 잘 살릴 수 있습니다.
앞서 언급한 구글의 실시간 번역이나 Moshi의 양방향 대화가 바로 이 방식을 지향합니다. 특히 Moshi는 사람의 대화처럼 상대가 말하는 중에도 반응할 수 있는 full-duplex 통신을 구현했는데, 이는 기존의 "한 명이 말하면 다른 쪽은 듣기만 하는" 구조에서 크게 벗어난 것입니다.
세 방식 한눈에 비교
| 구분 | STT → LLM → TTS | STT → LLM → Streaming TTS | Speech-to-Speech |
|---|---|---|---|
| 응답 속도 | 느림 (전부 생성 후 변환) | 빠름 (생성과 동시에 변환) | 가장 빠름 (텍스트 단계 없음) |
| 음성 품질 | 높음 (전체 문맥 활용) | 약간 저하 가능 | 약간 저하 가능 |
| 감정·억양 전달 | 제한적 | 제한적 | 유리함 |
| 구조 복잡도 | 단순 (부품 교체 쉬움) | 보통 | 복잡 (통합 모델 필요) |
| 대표 사례 | 현재 많은 상용 서비스 | 현재 많은 상용 서비스 | 구글 번역, Moshi |
그래서 핵심 기술 과제는 무엇인가?
위의 어떤 방식을 쓰든, 결국 마지막에는 AI 내부의 숫자 데이터(discrete token)를 사람이 들을 수 있는 소리 파형(waveform)으로 변환하는 디코더가 필요합니다. 그리고 실시간 대화를 위해서는 이 디코더가 즉각적으로 동작해야 합니다.
여기서 근본적인 딜레마가 발생합니다.
품질을 높이려면 전체 데이터를 한꺼번에 봐야 합니다. 문장 전체의 흐름을 파악해야 자연스러운 억양을 만들 수 있으니까요.
속도를 높이려면 데이터가 들어오는 즉시 음성을 만들어야 합니다.
현재 대부분의 스트리밍 디코더는 causal convolution(이전 정보만 참고하고 미래 정보는 보지 않는 구조)을 사용하는데, 이 방식은 빠르지만 전체를 보고 만드는 방식에 비해 음질이 떨어지는 것이 불가피합니다.
Flow Matching, 그게 뭔가요?
그러면 위에서 말한 디코더에는 어떤 기술이 사용될까요? 최근 음성 합성 분야에서는 Flow Matching이라는 기법이 최종 음성을 만들어내는 핵심 기술로 자리 잡고 있습니다. 이 기술을 이해하고, 스트리밍 환경에 맞게 개선할 수 있다면 실시간 음성 서비스가 가능해집니다. 바로 그것을 해결한 것이 오늘 리뷰할 StreamFlow입니다.
그러므로 StreamFlow를 이해하려면 먼저 그 기반 기술인 Flow Matching을 알아야 합니다. 핵심 아이디어는 생각보다 단순합니다. 노이즈(잡음)로 가득 찬 상태에서 출발해서, 깨끗한 데이터에 도달하는 "길"을 학습하는 것입니다.
좀 더 풀어서 설명하겠습니다. AI가 음성을 생성할 때, 처음에는 아무 의미 없는 잡음에서 시작합니다. 여기서 "이 잡음을 어느 방향으로, 얼마나 움직이면 진짜 음성에 가까워질까?"를 알려주는 것이 velocity field(속도장)입니다. 내비게이션이 "여기서 북쪽으로 가세요"라고 안내하듯, velocity field가 "이 잡음을 이 방향으로 바꾸세요"라고 알려주는 것이라고 생각하면 됩니다. AI는 이 안내를 따라 한 걸음씩 이동하면서(이 과정을 수학적으로는 ODE를 푼다고 합니다), 최종적으로 자연스러운 음성 데이터를 만들어냅니다.
기존 CFM의 한계: 왜 스트리밍이 안 되었을까?
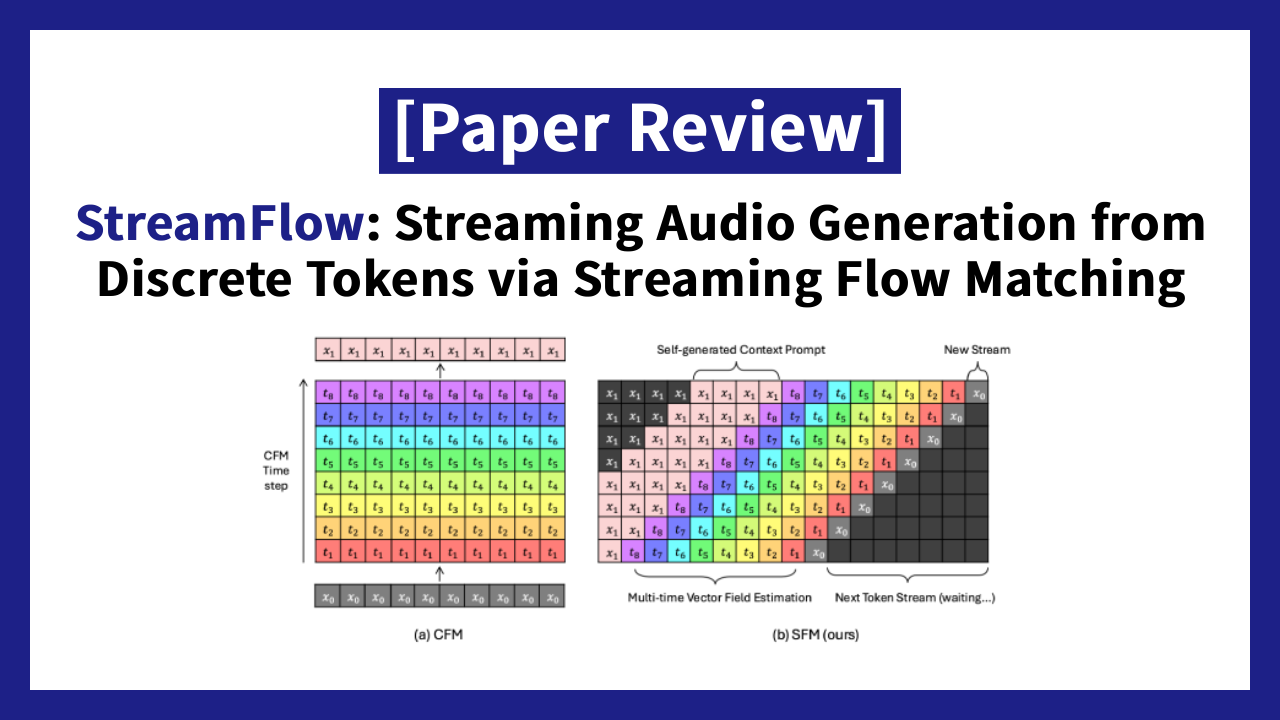
문제는 기존의 Conditional Flow Matching(CFM)이 전체 시퀀스를 한꺼번에 처리하는 구조라는 점입니다.
CFM에서는 잡음에서 깨끗한 음성으로 바꾸는 과정을 시간 단계(timestep)로 나눕니다. t=0이 "완전한 잡음", t=1이 "완성된 음성"이라고 할 때, 문장의 모든 부분이 동시에 처리됩니다. 즉, 문장의 앞부분이든 뒷부분이든 동시에 t=0에서 출발해서, 동시에 t=1에 도착합니다.
이것이 왜 문제가 되냐면, 스트리밍에서는 앞부분을 먼저 완성해서 내보내야 하기 때문입니다. 하지만 기존 구조에서는 앞부분만 먼저 t=1(완성)에 도달하게 하는 것이 원리적으로 불가능합니다. 마치 단체 마라톤에서 모든 주자가 반드시 동시에 출발하고 동시에 결승선을 통과해야 하는 규칙이 있는 것과 같습니다. 빠른 주자가 먼저 골인하는 것을 허용하지 않는 것이죠. 이는 음성이나 비디오처럼 시간 순서대로 흘러나와야 하는 스트리밍 상황에서는 치명적인 제약이 됩니다.
물론 우회 방법이 아예 없는 것은 아닙니다. 음성을 여러 덩어리(청크)로 잘라서 각각 따로 생성하는 방식을 쓸 수도 있습니다. 하지만 이 경우 덩어리와 덩어리가 이어지는 경계에서 소리가 뚝 끊기거나 부자연스러워지는 문제가 생기고, 청크를 나누고 합치는 과정에서 추가적인 지연도 발생합니다.
StreamFlow
StreamFlow는 바로 이 구조적 제약 자체를 근본적으로 재설계합니다. 모든 부분이 같은 시간표를 따를 필요 없이, 앞부분은 먼저 완성하고 뒷부분은 나중에 완성할 수 있도록 시간 축의 구조를 바꾼 것입니다.
다시 마라톤 비유로 돌아가면, StreamFlow는 "출발 시간을 주자마다 다르게 해도 되고, 먼저 준비된 주자는 먼저 결승선을 통과해도 된다"는 새로운 규칙을 도입한 것입니다. 덕분에 CFM 특유의 높은 음질은 그대로 유지하면서도, 토큰(데이터 조각)이 하나씩 들어올 때마다 바로바로 음성을 생성할 수 있게 됩니다.
서론이 길었는데... 본격적으로 논문을 리뷰하도록 하겠습니다.
✔️ Paper Info
-
Title: StreamFlow: Streaming Audio Generation from
Discrete Tokens via Streaming Flow Matching -
Authors: Ha-Yeong Choi · Sang-Hoon Lee
-
Affiliation: KT, 아주대
-
Conference: NeurIPS 2025
-
Keywords: Streaming flow matching, real-time audio generation, discrete tokens, diffusion transformer, Scale-DiT, neural audio codec, waveform generation, causal noising, EnCodec, Mimi
✔️ Main Problem and Key Approach
위에서 말했듯이, 기존 Flow Matching 모델은 오디오를 생성할 때 전체 시퀀스를 한꺼번에 처리해야 해서, 실시간 스트리밍이 불가능했습니다. StreamFlow는 이 문제를 해결하기 위해 Streaming Flow Matching(SFM)이라는 새로운 프레임워크를 제안합니다.
뒤에서 설명하겠지만 미리 말씀 드리자면, 핵심 아이디어는 시퀀스의 각 위치마다 서로 다른 (noise) timestep을 부여하는 것입니다. 이미 생성된 앞부분은 깨끗한 상태로 두고, 새로 생성할 뒷부분에만 점진적으로 노이즈를 줄여나가는 방식입니다. 덕분에 토큰이 하나씩 들어올 때마다 바로바로 오디오를 생성할 수 있습니다.
여기에 Scale-DiT라는 새로운 Transformer 구조도 함께 제안하는데, 고해상도 파형을 학습할 때 생기는 불안정성을 파라미터 증가 없이 해결합니다. 결과적으로, 실시간 스트리밍 모델임에도 기존 병렬 생성 모델보다 더 좋은 음질을 달성했고, Moshi의 디코더를 대체하는 데도 성공했습니다.
⭐ 요약 TL;DR
- Causal denoising training framework로 스트리밍 생성 능력 확보
- Scale-DiT로 고해상도 파형 학습 안정화
- EnCodec과 Mimi 토큰으로 실험, 스트리밍임에도 병렬 모델 능가
- Full-duplex model(Moshi)에서 Mimi decoder 대신 활용 가능
✔️ Architecture & Mehod
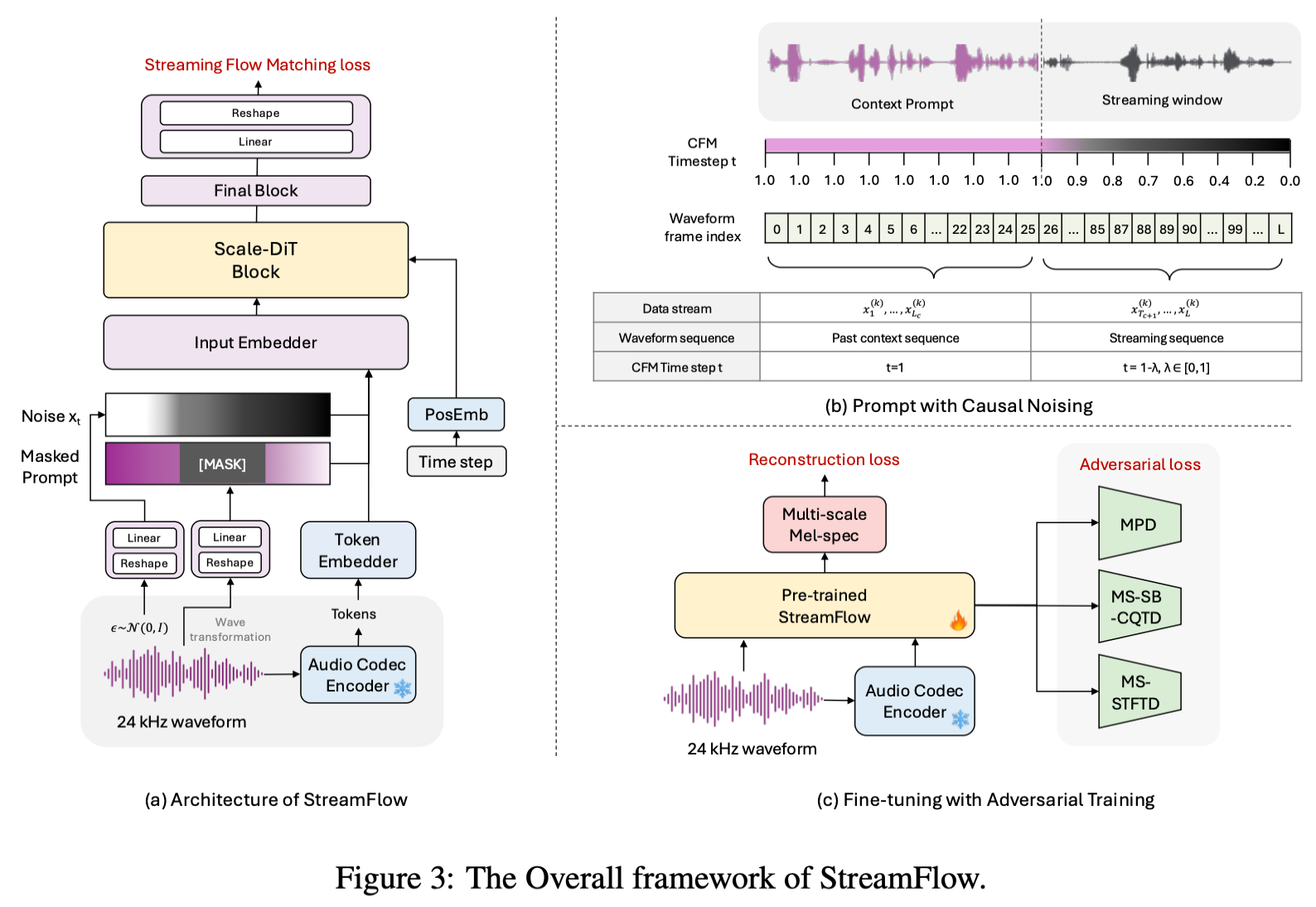
Streaming Flow Matching
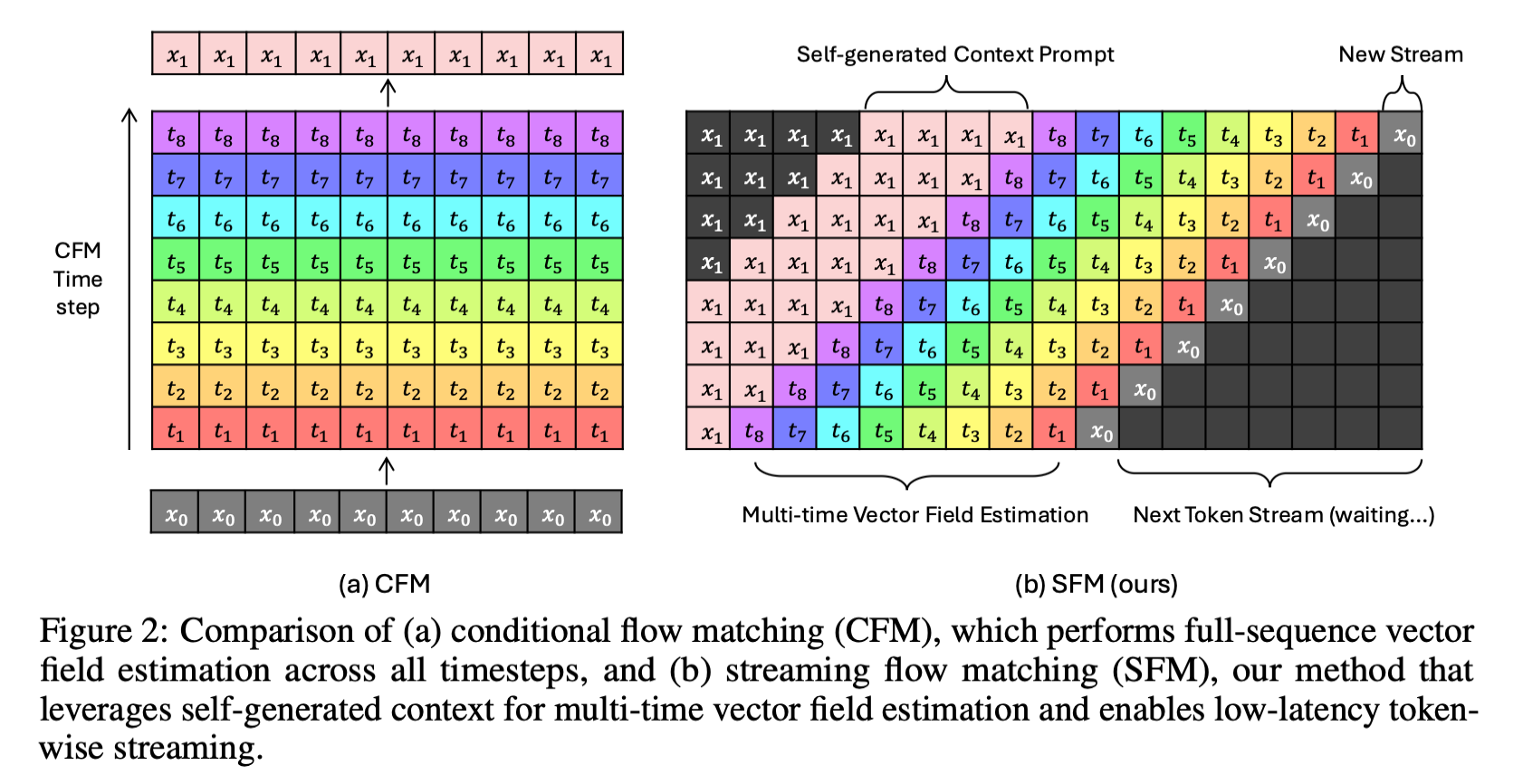
StreamFlow의 가장 핵심적인 발상은 시퀀스 내 위치마다 서로 다른 CFM timestep을 할당하는 것입니다.
Data Stream
SFM은 입력 시퀀스 x를 여러 개의 data stream으로 분할합니다. 각 stream은 두 가지 수치로 정의됩니다: streaming window size Ls(새로 생성할 프레임 수)와 context prompt ratio γ(과거 문맥의 비율)입니다. 전체 길이는 L = Lc + Ls이고, 여기서 Lc = γ · Ls입니다.
실제 설정에서는 Ls=8토큰, γ=3이므로 Lc=24토큰입니다. 즉 모델은 한 번에 24개의 과거 토큰을 참조하면서 8개의 새 토큰을 생성하는 것입니다.
각 data stream은 두 영역으로 나뉩니다.
첫 번째는 Context Prompt(문맥 프롬프트)입니다. 이미 생성이 완료된 과거 프레임들로, timestep이 t=1로 고정되어 깨끗한 데이터 상태를 유지합니다. 쉽게 말해 "이미 완성된 앞부분"입니다.
두 번째는 Streaming Window(스트리밍 창)입니다. 새로 생성할 프레임들로, timestep이 t=1에서 t=0으로 점진적으로 감소합니다. 수식으로는 t = 1 − λ, λ ∈ [0, 1]입니다. 과거에 가까운 프레임은 거의 완성된 상태(t≈1)이고, 미래로 갈수록 아직 노이즈가 많은 상태(t≈0)입니다.
이 구조 덕분에 모델은 한 번의 계산(forward pass)으로 streaming window 내의 여러 시간 단계에 대한 velocity field를 동시에 추정할 수 있습니다. 기존 CFM이 "전체를 동시에, 같은 속도로" 정제했다면, StreamFlow는 "앞부분은 거의 완성, 뒷부분은 아직 노이즈"라는 비대칭 구조를 학습하는 것입니다.
새로운 토큰이 들어오면, 직전에 생성한 프레임을 context prompt 쪽으로 밀어 넣고 새로운 streaming window를 열면 됩니다. Transformer의 in-context learning 능력 덕분에 과거 context로부터 장기적인 의존성을 자연스럽게 활용할 수 있습니다.
Causal Noising
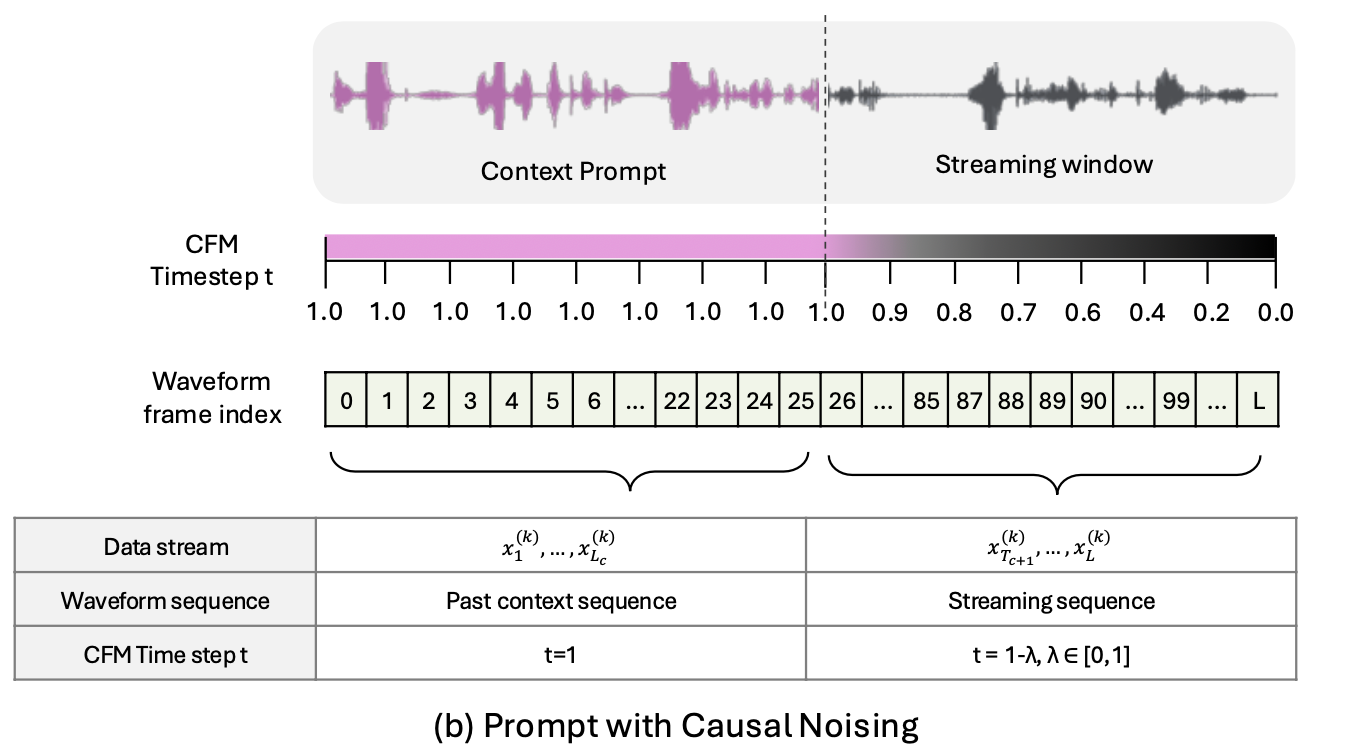
스트리밍 생성에서 가장 주의해야 할 점이 있습니다. 미래 정보가 현재 생성에 영향을 미치면 안 된다는 것입니다. 아직 도착하지 않은 토큰의 내용을 미리 알고 음성을 만들면, 실제 스트리밍 상황에서는 해당 정보가 없기 때문에 품질이 급격히 떨어지게 됩니다.
StreamFlow는 causal noising을 통해 이 문제를 해결합니다.
경로
각 stream k에서, 초기 상태 x₀⁽ᵏ⁾는 가우시안 노이즈 N(0, I)(완전한 잡음)이고, 목표 데이터 x₁⁽ᵏ⁾은 깨끗한 원본 음성입니다. 이 둘 사이의 보간 경로(interpolation path)는 다음과 같이 정의됩니다:
xₜ⁽ᵏ⁾ = (1 − t) · x₀⁽ᵏ⁾ + t · x₁⁽ᵏ⁾ ... (Eq.5)
직관적으로 이해하면 이렇습니다. t=0이면 100% 잡음, t=1이면 100% 깨끗한 데이터, t=0.5이면 잡음과 데이터가 반반 섞인 상태입니다. Streaming window 내에서 t가 1에서 0으로 점진적으로 감소하도록 설정하면, 앞쪽 프레임은 거의 깨끗하고 뒤쪽 프레임은 잡음이 많은 상태가 자연스럽게 만들어집니다.
Training Objective
SFM의 학습 목표는 이상적인 velocity field u⁽ᵏ⁾를 예측하는 것입니다. 이 velocity field는 보간 경로 xₜ⁽ᵏ⁾의 시간 미분으로, 매우 단순한 형태가 됩니다:
uₜ⁽ᵏ⁾ = dx⁽ᵏ⁾/dt = x₁⁽ᵏ⁾ − x₀⁽ᵏ⁾ ... (Eq.6)
즉, "깨끗한 데이터에서 잡음을 빼면, 잡음에서 데이터로 가는 방향이 나온다"는 것입니다. 내비게이션 비유로 돌아가면, 출발지(잡음)와 목적지(깨끗한 데이터)를 알면 이동 방향이 자동으로 결정되는 것과 같습니다.
최종 loss function은 모델이 예측한 velocity field v⁽ᵏ⁾와 이상적인 velocity field u⁽ᵏ⁾의 차이를 최소화하는 것입니다:
L_SFM(θ) = Σₖ E[ ‖ v⁽ᵏ⁾(x̃ₜ⁽ᵏ⁾; c⁽ᵏ⁻¹⁾; θ) − (x₁⁽ᵏ⁾ − x₀⁽ᵏ⁾) ‖² ] ... (Eq.7)
여기서 x̃ₜ⁽ᵏ⁾는 causal noising이 적용된 보간 상태(앞쪽은 깨끗하고 뒤쪽은 노이즈가 많은 비대칭 상태)이고, c⁽ᵏ⁻¹⁾는 이전 stream에서 생성된 context prompt입니다. 모델은 이 context를 참조하면서 현재 stream의 velocity field를 예측합니다.
쉽게 말해, "과거에 생성한 음성(context)을 참고하면서, 현재 노이즈 상태에서 깨끗한 음성으로 가는 방향을 맞춰라"는 것이 이 loss의 의미입니다.
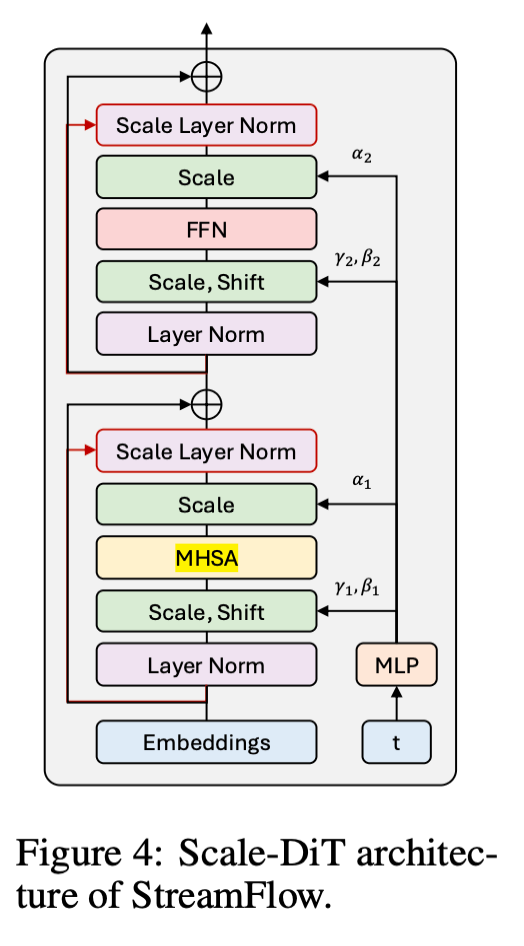
Scale-DiT
고해상도 음성 파형(24kHz)을 Diffusion Transformer(DiT)로 직접 모델링하면 학습이 불안정해지는 문제가 있습니다. 해상도가 높을수록 모델이 다뤄야 할 정보의 세밀함이 극적으로 증가하기 때문입니다. StreamFlow는 이 문제를 해결하기 위해 Scale-DiT라는 새로운 블록 구조를 제안합니다.
전체 흐름을 먼저 봅니다
Scale-DiT 블록 하나는 크게 MHSA(Multi-Head Self-Attention) 단계와 FFN(Feed-Forward Network) 단계를 거칩니다. 각 단계마다 동일한 패턴이 반복됩니다: "AdaLN으로 정규화 → 연산 수행 → Scale-DiT 방식으로 잔차 연결". 하나씩 살펴보겠습니다.
MHSA 단계
Step 1 — AdaLN (Adaptive Layer Normalization):
입력 x를 먼저 Layer Normalization(σ)으로 정규화한 뒤, 학습 가능한 스케일(γ₁)과 시프트(β₁) 파라미터를 적용합니다.
x̂ = σ(x) · (1 + γ₁) + β₁ ... (Eq.8)
여기서 γ₁과 β₁은 timestep t로부터 MLP를 통해 생성되는 조건부 파라미터입니다. 즉, "지금이 노이즈 제거 과정에서 어느 단계인지"에 따라 정규화 방식이 달라집니다.
Step 2 — Attention 연산:
정규화된 x̂를 Multi-Head Self-Attention에 통과시키고, gating factor α₁을 곱합니다.
A = α₁ · MHSA(x̂) ... (Eq.9)
α₁도 timestep에서 생성되는 학습 가능한 값으로, attention 출력의 크기를 조절하는 역할을 합니다.
Step 3 — Scale-DiT 잔차 연결 (핵심 차이점):
여기서 기존 DiT와 Scale-DiT가 갈라집니다.
기존 vanilla DiT의 잔차 연결: x ← x + A
Scale-DiT의 잔차 연결: x ← x + ρ₁ · σ(A − x) ... (Eq.10)
단순히 A를 더하는 대신, 세 가지 과정을 거칩니다. 첫째, attention 출력 A와 현재 feature x의 차이(A − x)를 계산합니다. 둘째, 이 차이를 LayerNorm(σ)으로 정규화하여 값이 극단적으로 커지거나 작아지는 것을 방지합니다. 셋째, 학습 가능한 adaptive scaling rate ρ₁(10⁻⁴에서 1 사이로 제한)로 업데이트 크기를 조절합니다.
FFN 단계
MHSA 단계와 완전히 동일한 패턴이 반복됩니다.
x̂ = σ(x) · (1 + γ₂) + β₂ ... (Eq.11) — 두 번째 AdaLN
F = α₂ · FFN(x̂) ... (Eq.12) — FFN 연산 + gating
x ← x + ρ₂ · σ(F − x) ... (Eq.13) — Scale-DiT 잔차 연결 (별도의 ρ₂ 사용)
왜 이렇게 하면 좋은가?
한번에 A를 다 넣는 것이 아니라, 그 차이를 일정한 범위로 조절한 뒤, 소량씩 추가하는 방식입니다. 이렇게 하면 값이 급격히 변해서 망치는 일을 방지할 수 있습니다.
이 설계의 효과는 두 가지입니다. 첫째, 차이(A − x 또는 F − x)를 LayerNorm으로 정규화함으로써 gradient가 극단적으로 커지는 것을 방지합니다. 둘째, ρ₁과 ρ₂가 학습 초기에 매우 작은 값(10⁻⁴ 근처)에서 시작하므로, residual 업데이트가 점진적으로 이루어져 최적화가 안정적입니다. 추가 파라미터는 ρ₁과 ρ₂ 단 두 개뿐이므로 모델 크기는 사실상 동일합니다.
Linear-Reshape Transformation
이 부분을 이해하려면 먼저 왜 음성 데이터를 쪼개서 사용하는 지부터 알아야 합니다.
24kHz 음성은 1초에 24,000개의 숫자로 이루어져 있습니다. 이 긴 1차원 숫자열을 그대로 모델에 넣으면 처리가 너무 무겁기 때문에, 적절한 단위로 묶어서 다루기 쉬운 형태로 바꿔주는 과정이 필요합니다. 이 변환 방식에 따라 스트리밍 가능 여부가 결정됩니다.
기존 방식: STFT (Short-Time Fourier Transform)
기존 모델들은 STFT를 사용합니다. STFT는 음성 신호를 짧은 구간(window)으로 잘라서 각 구간의 주파수 성분을 분석하는 방식입니다.
문제는 이 "분석 창(window)"의 크기가 "이동 간격(hop size)"보다 크다는 점입니다. 구체적인 숫자로 설명하겠습니다. StreamFlow에서 hop size는 160이고, STFT의 window size는 640입니다. 즉, 160칸씩 이동하면서 640칸짜리 창으로 분석하는 것입니다.
이것이 왜 스트리밍에서 문제가 되냐면, 현재 위치에서 분석하려면 앞으로 480개(640-160)의 데이터가 더 필요하기 때문입니다. 아직 도착하지 않은 미래 데이터를 봐야 한다는 뜻이죠. 또한 CFM처럼 여러 번 반복(multi-step sampling)하는 모델에서는 매 step마다 STFT를 다시 계산해야 해서 연산 비용도 커집니다.
StreamFlow의 방식: Linear-Reshape
StreamFlow는 이 대신 훨씬 단순한 linear-reshape 변환을 채택합니다. 과정은 두 단계입니다.
1단계 — Reshape: 1차원 음성 파형을 hop size(h=160) 기준으로 잘라서 2차원 표 형태로 재배열합니다. 예를 들어, 길이 1,600의 음성 신호가 있다면 이것을 160개씩 10묶음으로 잘라 10행 × 160열의 2차원 텐서로 만드는 것입니다.
원본 (1차원): [s₁, s₂, s₃, ... s₁₅₉, s₁₆₀, s₁₆₁, ... s₃₂₀, s₃₂₁, ...]
Reshape (2차원):
행1: [s₁, s₂, ... s₁₆₀] ← 토큰 1에 대응
행2: [s₁₆₁, s₁₆₂, ... s₃₂₀] ← 토큰 2에 대응
행3: [s₃₂₁, s₃₂₂, ... s₄₈₀] ← 토큰 3에 대응
...2단계 — Linear Projection: 각 행(160차원)을 linear layer를 통해 모델이 사용하는 feature 차원(예: 1024차원)으로 변환합니다.
핵심은 각 행이 정확히 자기 자신의 160개 샘플만 참조한다는 점입니다. 앞 행도, 뒷 행도 볼 필요가 없습니다. 따라서 미래 프레임을 전혀 참조하지 않고, 매 sampling step마다 STFT를 재계산할 필요도 없어서 스트리밍 추론에서 훨씬 효율적입니다.
다만 병렬 생성(한꺼번에 전체를 만드는 경우)에서는 STFT/iSTFT가 더 좋은 성능을 보이므로, 논문에서는 병렬 모델에는 STFT, 스트리밍 모델에는 linear-reshape를 사용합니다.
2단계 학습
StreamFlow는 한 번에 모든 것을 학습하지 않고 2단계로 나눠서 학습합니다.
1단계 — SFM 사전학습
앞에서 설명한 Streaming Flow Matching 목적함수로 모델을 학습합니다. 이 단계에서 스트리밍 생성의 기본 능력이 형성됩니다. 이 사전학습이 왜 중요하냐면, 이 단계 없이 바로 2단계(적대적 학습)를 시도하면 ODE sampling 초기 단계에서 discriminator collapse(판별기 붕괴)가 발생하여 학습 자체가 실패하기 때문입니다.
2단계 — Adversarial Fine-tuning(적대적 미세조정)
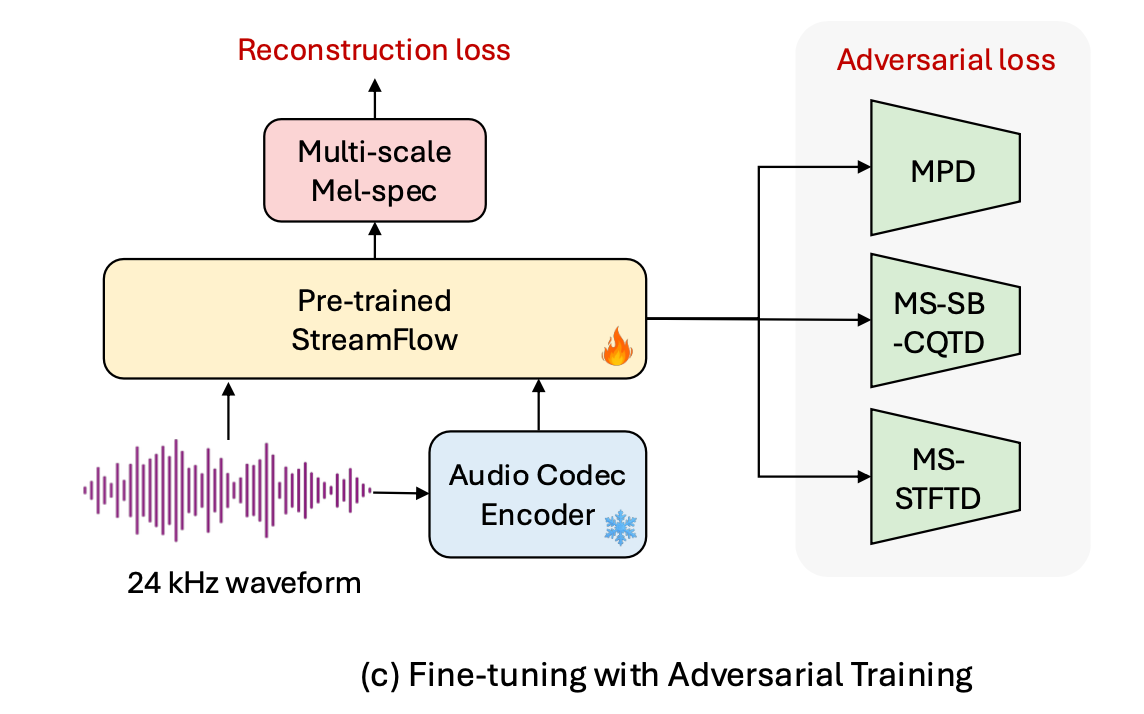
사전학습된 모델을 MPD, MS-STFTD, MS-SB-CQTD 등 다양한 discriminator(판별기)로 미세조정합니다. 판별기란 "이 음성이 진짜인지 가짜인지"를 판단하는 모델로, 생성 모델이 판별기를 속일 수 있을 만큼 좋은 음성을 만들도록 경쟁시키는 방식입니다.
이 2단계 미세조정을 겨우 0.25M steps만 수행해도 PESQ(음성 품질 점수)와 UTMOS(자연스러움 점수)가 꽤 향상됩니다.
-
Discriminator collapse란: GAN 학습에서 생성 모델이 초기에 너무 형편없는 출력을 내놓으면, 판별 모델이 너무 쉽게 진짜/가짜를 구분해버려서 생성 모델에게 유용한 피드백(gradient)을 줄 수 없게 되는 현상입니다. 결과적으로 생성 모델의 학습이 멈추거나 극소수 패턴만 반복 생성하게 됩니다.
-
StreamFlow에서의 해법: SFM 사전학습으로 생성 모델이 먼저 괜찮은 수준의 음성을 만들 수 있게 한 뒤 적대적 학습을 시작하므로, 판별 모델이 유의미한 피드백을 줄 수 있는 균형 상태에서 학습이 진행됩니다.
추론
학습이 끝난 후, 실제로 음성을 실시간 생성할 때의 동작을 단계별로 설명하겠습니다.
Step 1 — 첫 번째 토큰 도착, 첫 stream 생성
LLM에서 첫 번째 토큰이 들어옵니다. 아직 과거에 생성한 음성이 없으므로, context prompt 없이 streaming window만으로 음성 프레임을 생성합니다. 8개의 프레임이 만들어지고, 이 중 앞쪽 프레임(t≈1에 가까운, 가장 깨끗한 것)을 스피커로 출력합니다.
Step 2 — Causal Shift, 생성된 프레임을 과거로 편입
방금 생성한 프레임들을 context prompt 쪽으로 밀어 넣습니다. 이것이 causal shift 연산입니다. 즉, "방금 만든 음성"이 "이미 완성된 과거 음성"으로 바뀌게 되는 것입니다. 이제 모델은 다음 stream을 생성할 때 이 과거 음성을 참고자료로 활용할 수 있습니다.
Step 3 — 다음 토큰 도착, 반복
새 토큰이 들어오면, Step 2에서 축적된 context prompt(최대 24토큰 분량)를 시퀀스 앞에 붙이고, 새로운 streaming window를 열어 다음 프레임을 생성합니다. 모델은 앞에 붙은 과거 음성을 참고해서 자연스럽게 이어지는 음성을 만들어냅니다. (Transformer의 in-context learning — 별도의 추가 학습 없이, 입력으로 주어진 과거 데이터의 패턴을 파악해서 활용)
✔️ Dataset & Evaluation
Training Set
| 항목 | 내용 |
|---|---|
| 데이터셋 | LibriTTS (고품질 영어 낭독체) |
| 샘플링 레이트 | 24,000 Hz |
| 음성 토크나이저 | EnCodec, Mimi (둘 다 causal conv 기반, 스트리밍 가능) |
| RVQ 코드북 수 | 8개 |
모든 모델은 LibriTTS로 학습했습니다. EnCodec과 Mimi 모두 causal convolutional layer로 구성되어 있어 스트리밍 인코딩/디코딩이 가능합니다.
학습 설정
| 단계 | Learning Rate | Batch Size | Steps | Segment Size | GPU |
|---|---|---|---|---|---|
| 1단계 (SFM 사전학습) | 2×10⁻⁴ | 512 | 1M | 10,240 frames | A6000 ×4 |
| 2단계 (Adversarial FT) | 2×10⁻⁵ | 64 | 0.25M | 20,480 frames | A6000 ×4 |
1단계에서 스트리밍 생성의 기본 능력을 형성하고, 2단계에서 다중 판별기(MPD, MS-STFTD, MS-SB-CQTD)를 활용한 적대적 미세조정으로 음질을 끌어올리는 구조입니다.
Test Set
| 데이터셋 | 용도 | 구성 |
|---|---|---|
| LibriTTS-dev (clean + test) | 개발 단계 검증, Ablation 실험 | LibriTTS 내부 분할 |
| Universal Speech Test Set | 범용 성능 평가 | Expresso, HiFiTTS, LibriTTS, Aishell3, JVS, CML-TTS에서 총 300샘플 |
Evaluation Metrics
| 지표 | 정식 명칭 | 측정 대상 | 방향 | 설명 |
|---|---|---|---|---|
| WER / CER | Word / Character Error Rate | 음성 인식 정확도 | ↓ 낮을수록 좋음 | 생성 음성의 인식 정확도를 측정합니다 |
| M-STFT | Multi-resolution STFT distance | 스펙트럼 유사도 | ↓ 낮을수록 좋음 | 여러 해상도에서 원본과 생성 음성의 주파수 거리를 측정합니다 |
| PESQ | Perceptual Evaluation of Speech Quality | 음성 품질 | ↑ 높을수록 좋음 | 사람의 청각 특성을 반영한 품질 점수입니다. 16kHz 다운샘플링 후 측정합니다 |
| Periodicity | Periodicity RMSE | 주기성 오류 | ↓ 낮을수록 좋음 | 생성 음성이 원본의 주기적 패턴을 얼마나 정확히 재현하는지 측정합니다 |
| V/UV F1 | Voiced/Unvoiced F1 Score | 유성음/무성음 분류 | ↑ 높을수록 좋음 | 유성음과 무성음 구간을 정확히 구분하는지 평가합니다 |
| UTMOS | UTokyo-SaruLab MOS Predictor | 자연스러움 | ↑ 높을수록 좋음 | 참조 음성 없이 자연스러움을 예측하는 neural MOS 모델입니다 |
| MOS | Mean Opinion Score | 주관적 음질 | ↑ 높을수록 좋음 | Amazon MTurk에서 20명의 원어민 평가자가 5점 척도로 직접 평가한 점수입니다 |
✔️ Results
EnCodec 토큰 복원
가장 주목할 만한 결과는 스트리밍 모델이 기존 병렬 모델을 능가한다는 점입니다.
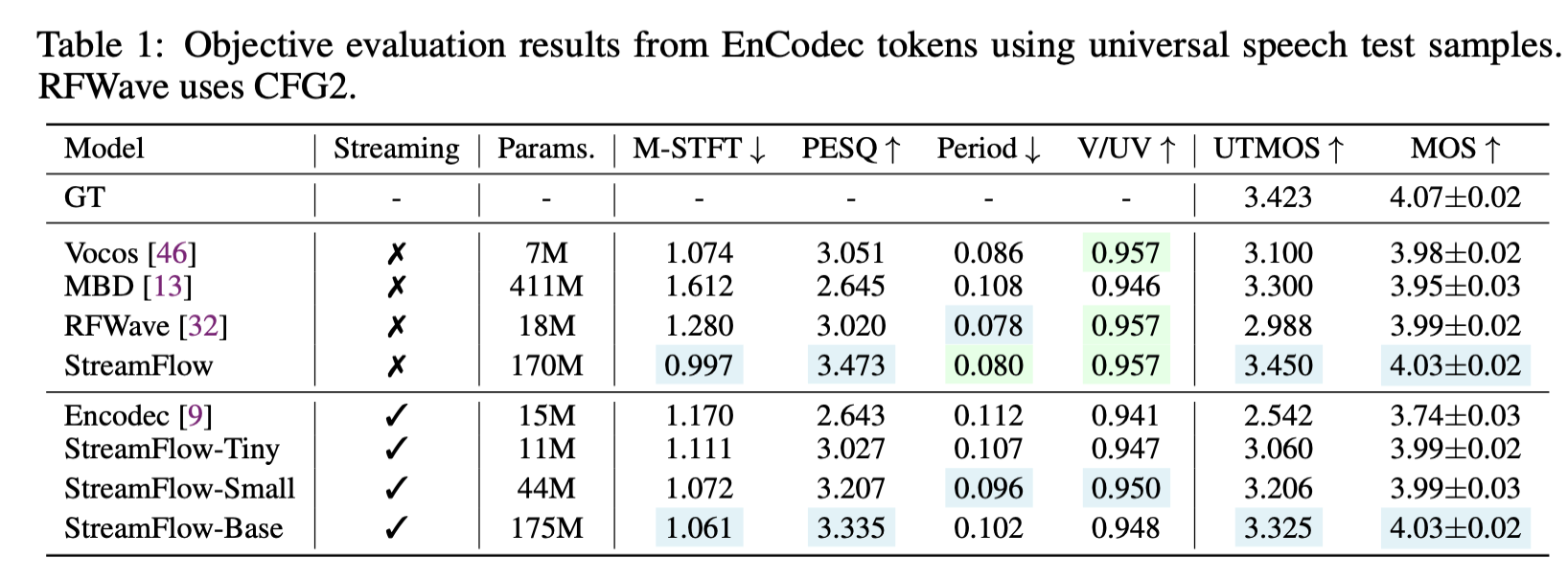
StreamFlow-Base(175M, 스트리밍)는 PESQ 3.335, MOS 4.03으로, 병렬 모델인 Vocos, RFWave, MBD를 모두 상회합니다.
Mimi 토큰 복원과 Moshi 통합
Moshi의 Mimi decoder를 StreamFlow로 교체하는 실험도 수행했습니다. LLM 출력은 동일하게 유지한 채 디코더만 교체한 결과입니다.
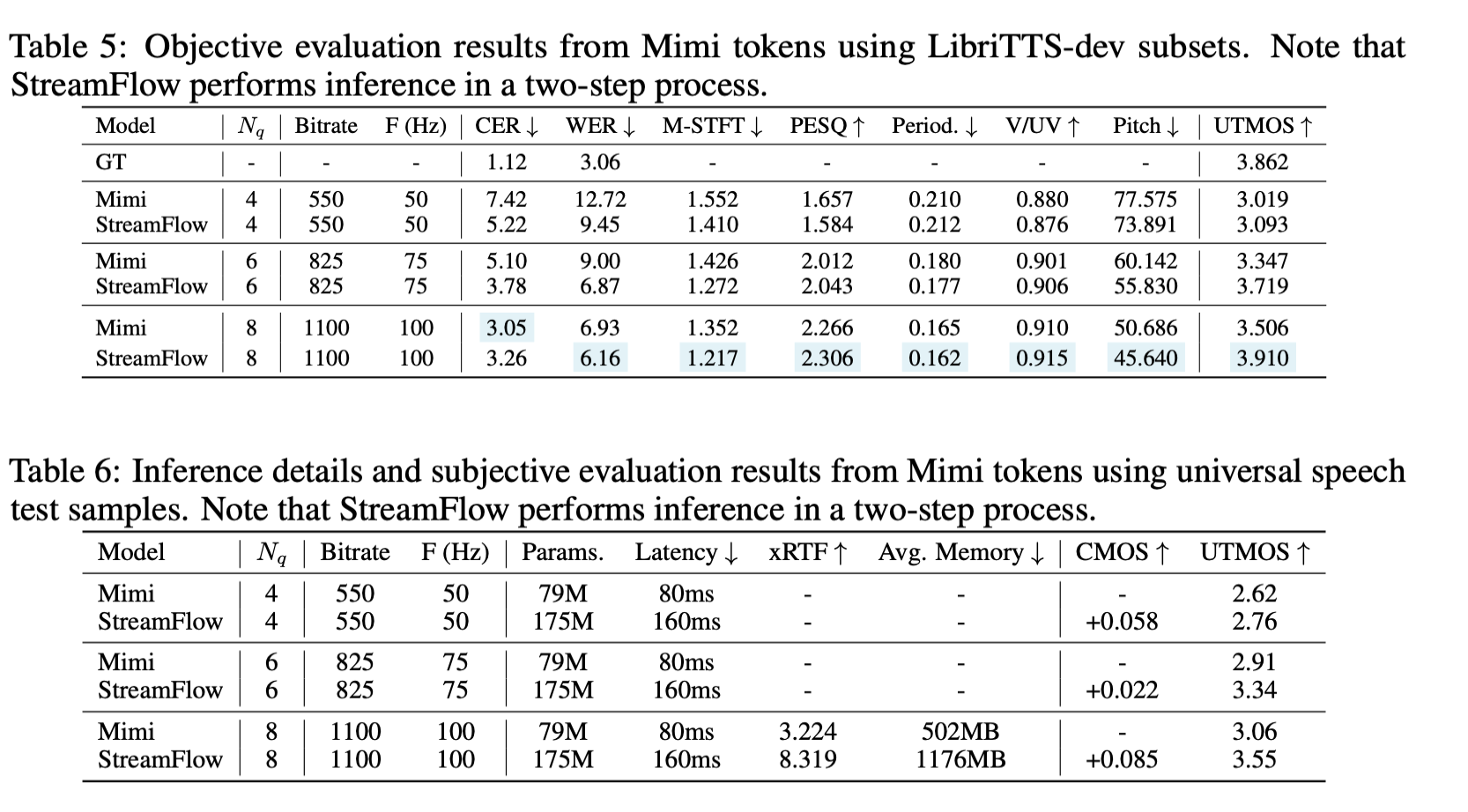
디코더 하나만 바꿔도 WER과 UTMOS가 모두 개선되었습니다. 기존 시스템에 바로 끼워 넣을 수 있는 실용성이 입증된 결과입니다.
하나 의문인 점은... RTF 값이 원래 저렇게 높나요???
Ablation
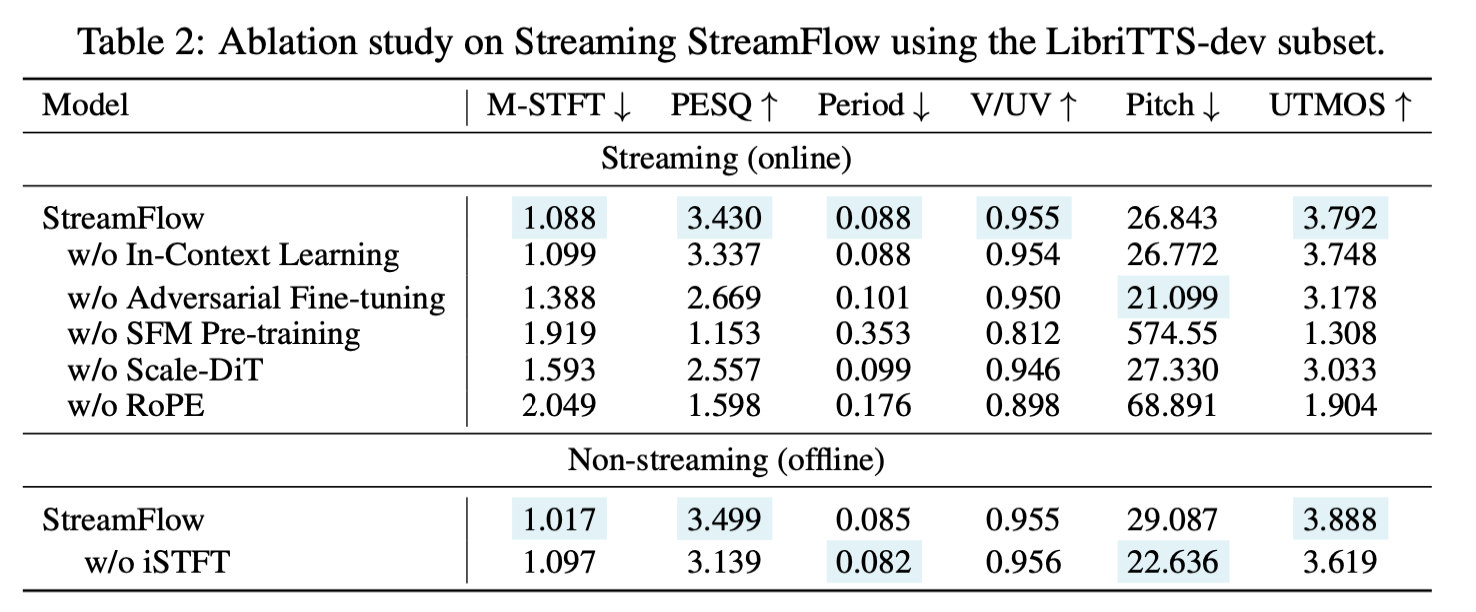
각 구성 요소의 기여를 간단히 요약하면 다음과 같습니다.
-
In-Context Learning: 생성된 샘플을 프롬프트로 붙이면 성능 향상.
-
Adversarial Fine-tuning: SFM 사전학습 후 소량의 적대적 미세조정만으로 큰 성능 향상. 2단계 학습의 효율성 입증.
-
SFM Pre-training: 가장 핵심. 없으면 스트리밍 생성 능력 미형성 → discriminator collapse
-
Scale-DiT: vanilla DiT 대비 성능 향상 + 학습 안정화.
-
RoPE: 스트리밍 생성에 필수. 없으면 위치 정보 학습 실패.
-
Linear-Reshape Transformation: 병렬은 STFT/iSTFT가 우수하나 스트리밍에 부적합. 병렬 → STFT/iSTFT, 스트리밍 → linear-reshape 사용.

- Scalability: Tiny(11M) → Small(44M) → Base(175M)로 모델 크기를 키울수록 모든 평가 지표에서 일관되게 성능이 향상
✔️ Resources
