[ 논문리뷰 ] Improving Cross-Modal Retrieval with Set of Diverse Embeddings
2023, Kim et al.
https://cvlab.postech.ac.kr/research/DivE/
1. 선행 연구의 동향 및 한계
Cross-modal Retrieval
-
주요 문제: 모호성(Ambiguity)
- 한 이미지에 여러 상황이 포함될 수 있음
- 하나의 캡션이 다양한 이미지를 설명할 수 있음

-
기존 접근 방식:
- Cross Attention Network
- 장점: 모달리티 간 연관성을 명확히 모델링 가능
- 단점: 계산량이 많아 대규모 데이터에서 비효율적
- Dual Encoder 방식
- 장점: 각 모달리티를 독립적으로 임베딩하며 사전 계산된 벡터 활용 → 계산량 적음
- 단점: 단일 임베딩 벡터로 인해 모호성을 충분히 표현하지 못함
- Cross Attention Network
-
기존 Dual Encoder 방식의 한계:
- Sparse Supervision: 데이터 대부분이 학습되지 않음
- Set Collapsing: 임베딩 벡터가 중복된 의미를 학습 → 다양성 상실
2. 연구 필요성 혹은 차별성
-
Smooth-Chamfer Similarity
- 데이터 쌍의 상대적 유사성을 고려한 새로운 유사도 함수
- Sparse Supervision과 Set Collapsing 문제를 동시에 해결
-
Slot Attention 기반 Set Prediction Module
- 입력 데이터를 세밀히 분리하고 학습해 모호성을 줄이고 다양한 의미 포착
3. 연구 질문
- Cross-modal Retrieval에서 ambiguity를 해결할 수 있는 효율적인 방식은 무엇인가?
- 텍스트와 이미지의 다양한 의미를 포착하며 redundancy를 줄이는 embedding method는 무엇인가?
4. 사용 이론
-
Slot Attention Mechanism
- 데이터를 여러 슬롯으로 나누고 경쟁 메커니즘(compete mechanism)으로 독립적 학습
- 기존 슬롯 방식은 랜덤 샘플링으로 인해 현실 이미지에서 실패
-
Smooth-Chamfer Similarity
- 모든 데이터 쌍에 서로 다른 가중치 부여 → 유사성 계산
-
Log-Sum-Exp (LSE)
- 상대적 유사성을 기반으로 가중치를 계산해 더 부드럽게 유사도 평가
5. 연구 방법
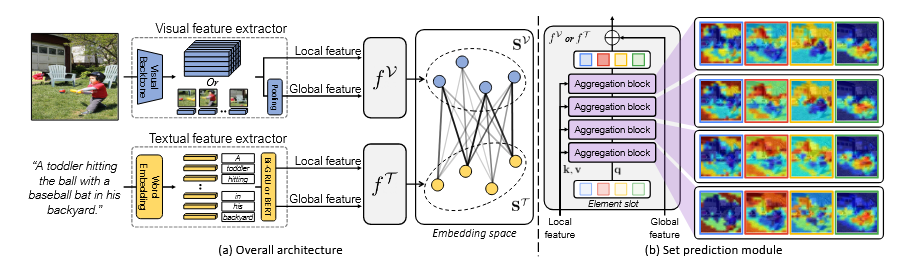
Model Architecture
-
Visual Feature Extractor
- 이미지의 Local Features와 Global Features를 추출
- ROI와 Convolutional Feature Map 기반 두 가지 방식 사용
-
Textual Feature Extractor
- bi-GRU 또는 BERT를 사용해 텍스트의 Local, Global Features 추출
-
Set Prediction Module
- Aggregation Block을 반복적으로 실행하며 슬롯을 업데이트
- 각 슬롯이 독립적으로 데이터를 학습하고 최종적으로 Global Feature와 결합
Set Prediction Module (Slot Attention 동작)
-
: 초기 슬롯. 번째 반복에서 는 아래와 같이 계산됨:
- : 입력 이미지에서 추출된 Local Features
-
AggBlock 내부 동작:
- 입력 처리 및 선형 변환:
- 입력 데이터를 정규화(Layer Normalize)하고 를 로 선형 변환
- 이전 단계 슬롯 도 선형 변환해 생성
- Attention Map 계산:
- : 입력 데이터와 슬롯 간 유사도를 계산한 값
- Slot 간 경쟁:
- Slot을 기준으로 맵 정규화:
- 정규화로 각 Slot이 다른 데이터 부분에 집중하도록 유도
- Slot을 기준으로 맵 정규화:
- Slot 업데이트:
- Attention Map으로 Local Features를 가중 평균 결합:
- 업데이트된 를 MLP에 통과시켜 학습 안정성 강화:
- Attention Map으로 Local Features를 가중 평균 결합:
- 입력 처리 및 선형 변환:
-
최종 Embedding Set 생성:
- 번 반복 후 최종 슬롯 에 Global Feature 추가:
- 번 반복 후 최종 슬롯 에 Global Feature 추가:
Smooth-Chamfer Similarity
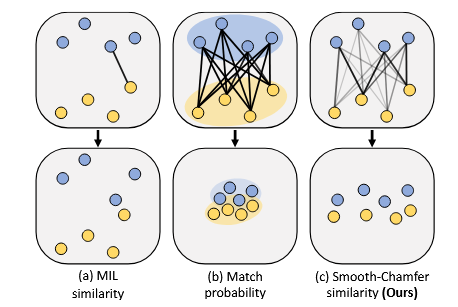
- 모든 가능한 쌍에 서로 다른 weight을 부여하고 LSE 방식으로 상대적 유사성에 따라 weight 결정
- 기존 방식들의 한계:
- MIL (Multiple Instance Learning): 가장 가까운 pair만 고려 → Sparse Supervision 문제
- MP (Match Probability): 모든 쌍의 평균을 사용 → Set Collapsing 문제
Training
- Hard Negative Mining Triplet Loss: Image-Text 임베딩 최적화
- Diversity Regularizer: 중복을 줄이고 다양한 임베딩 생성
6. 연구 핵심
-
Smooth-Chamfer Similarity:
- 기존 유사도 함수의 한계를 해결하며 더 효율적인 학습 가능
-
Slot Attention 기반 Set Prediction Module:
- 입력 데이터의 다양한 의미 학습, 중복 없는 Embedding Set 생성
-
효율성:
- 기존 Cross Attention 기반 방식보다 적은 계산량으로 더 나은 성능 달성
7. 연구 의의 및 한계
-
연구 의의:
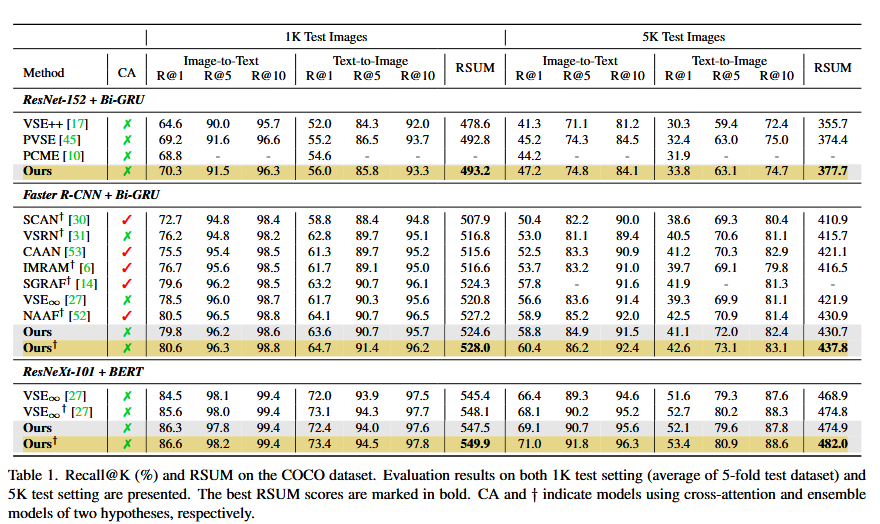
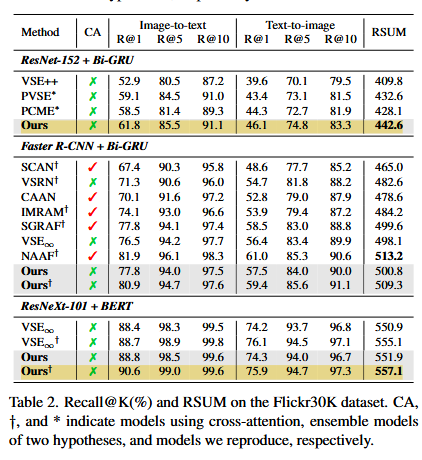
- COCO와 Flickr30K 데이터셋에서 기존 방식보다 뛰어난 성능과 효율성 확보
- Cross-modal Retrieval에서 모호성을 해결하며 대규모 데이터에 적합

-
연구 한계:
- Slot Attention 성능이 특정 데이터 크기나 구조에 따라 제한될 가능성
- 텍스트-이미지 외 다른 모달리티 확장 필요

반갑습니다!