import numpy as np
import matplotlib.pyplot as plt
import seaborn as sb
import pandas as pd
d1 = np.loadtxt("example_1.txt")
d2 = np.loadtxt("example_2.txt")
print(d1.shape, d2.shape)
# result
(500,) (500,)Histogram Plots
- 히스토그램은 데이터를 파악하고 1차원 분포를 표시하는 가장 일반적인 방법이다. 2차원 히스토그램은 거의 사용되지 않는다.
원본 결과
plt.hist(d1, label="D1")
plt.hist(d2, label="D2")
plt.legend()
plt.ylabel("Counts")
plt.show()
- 위 그래프 문제점
- D1의 데이터를 겹치는 부분에서 표현이 되지 않음
- bins의 수량이 적기 때문에 파악이 힘듬
- y축이 수량으로 표현되어 분포를 정확하게 판단 불가능
bins 수정
# bins값의 데이터 셋에 맞게 지정
# 두개의 값 d1,d2에서 최소, 최대값을 고르고 50개로 bin 수량을 설정
bins = np.linspace(min(d1.min(), d2.min()), max(d1.max(), d2.max()), 50)
plt.hist(d1, bins=bins, label="D1")
plt.hist(d2, bins=bins, label="D2")
plt.legend()
plt.ylabel("Counts")
plt.show()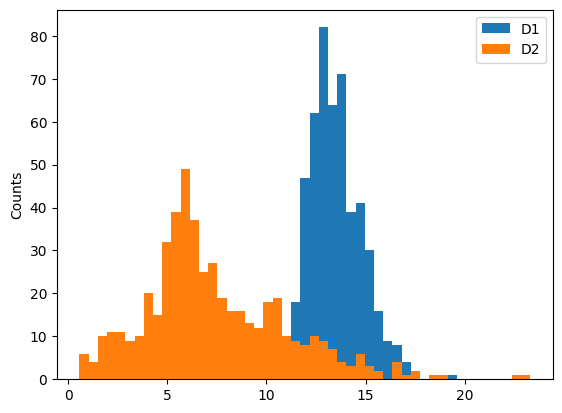
y축 수정 -> 확률 공간으로 이동
bins = np.linspace(min(d1.min(), d2.min()), max(d1.max(), d2.max()), 50)
plt.hist(d1, bins=bins, label="D1", density=True)
plt.hist(d2, bins=bins, label="D2", density=True)
plt.legend()
plt.ylabel("Probability")
plt.show()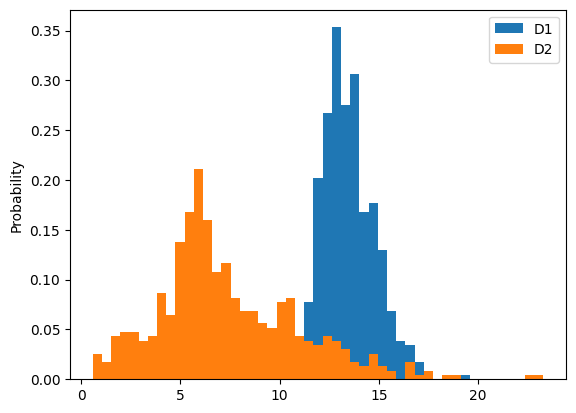
plt.hist에서 density = True로 설정시 확률 공간으로 이동
겹치는 부분 stack설정 -> 겹치는 부분 해소
bins = np.linspace(min(d1.min(), d2.min()), max(d1.max(), d2.max()), 50)
plt.hist([d1, d2], bins=bins, label="Stacked", density=True, histtype="barstacked", alpha=0.5)
plt.legend()
plt.ylabel("Probability")
plt.show()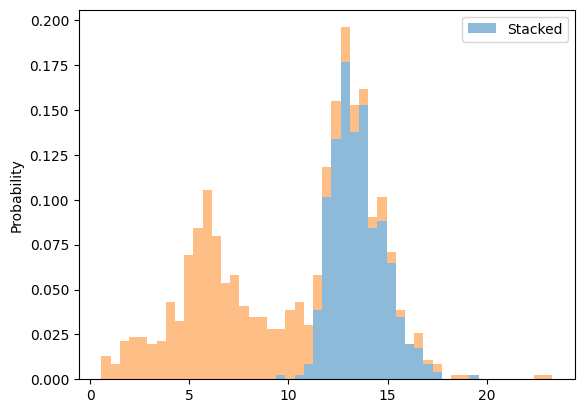
histtype="barstacked" -> 여러 데이터가 쌓인 형태의 막대 형태 히스토그램
확률 분포 추가
bins = np.linspace(min(d1.min(), d2.min()), max(d1.max(), d2.max()), 50)
plt.hist([d1, d2], bins=bins, label="Stacked", density=True, histtype="barstacked", alpha=0.5)
plt.hist(d1, bins=bins, label="D1", density=True, histtype="step", lw=1)
plt.hist(d2, bins=bins, label="D2", density=True, histtype="step", ls=":")
plt.legend()
plt.ylabel("Probability")
plt.show()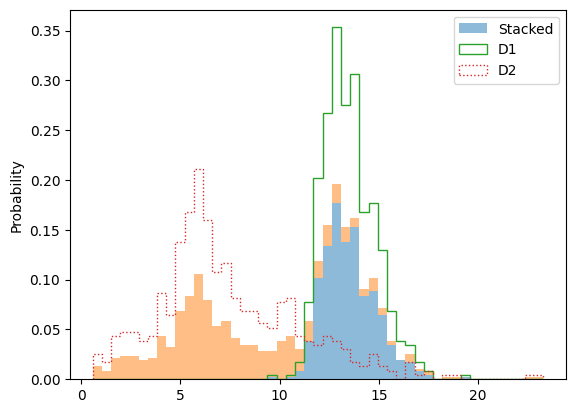
histtype="step" -> 내부가 비어있는 lineplot 생성
Swarm Plots
-
카테고리값에 따른 각 분포의 실제 데이터나 전체 형상을 보여준다는 장점이 존재한다.
- 시간별 일자별 유리 -> 매출 데이터의 경우
- 범주형에 유리
-
단점으로는 보기에는 좋아도 자료로 쓰기엔 한계가 존재하기 때문에 히스토그램이 좀 더 좋다.
-
Violin Plots를 사용할 수 있는 상황이라면 Swarm Plots을 사용하지 않는 것이 좋다. 왜냐하면 Violin Plots의 성능이 월들이 좋다.
dataset = pd.DataFrame({
"value": np.concatenate((d1, d2)),
"type": np.concatenate((np.ones(d1.shape), np.zeros(d2.shape)))
})범주화 X
sb.swarmplot(dataset["value"])
plt.show()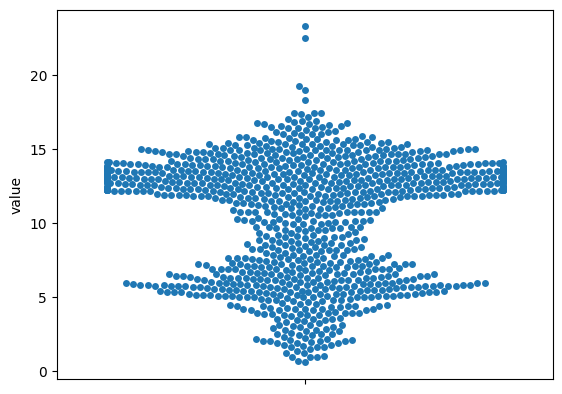
범주화 O
sb.swarmplot(x="type", y="value", data=dataset, size=2)
plt.show()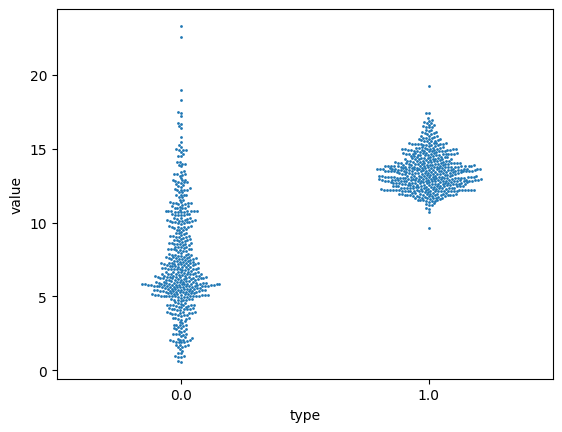
Box Plots
sb.boxplot(x="type", y="value", data=dataset, whis=3.0)
sb.swarmplot(x="type", y="value", data=dataset, size=2, color="k", alpha=0.3)
plt.show()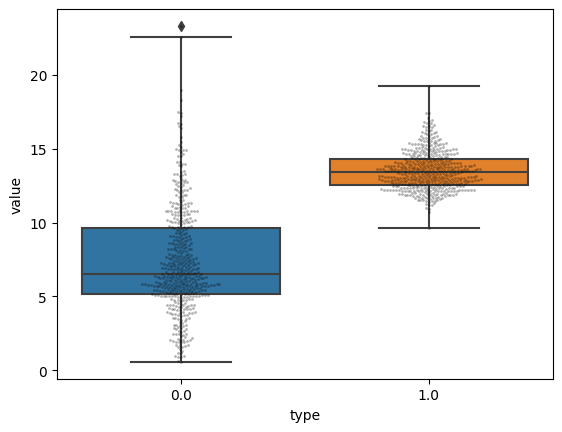
이전의 swarm plots와 box plot을 겹쳐둔 그래프
전체적으로 분포를 확인이 가능하다.
Violin Plots
- Box Plots에서는 많은 정보를 얻을 수 없다.
- Violin그래프는 박스플랏 정보와 더불어 더 많은 정보를 얻을 수 있다.
sb.violinplot(x="type", y="value", data=dataset)
sb.swarmplot(x="type", y="value", data=dataset, size=2, color="k", alpha=0.3)
plt.show()
sb.violinplot(x="type", y="value", data=dataset, inner="quartile", bw=0.2)
plt.show()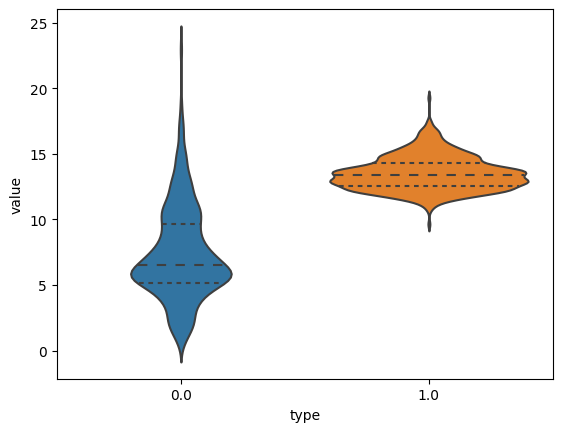
bw 파리미터는 평활화 용도
inner="quartile" 파라미터는 분위수 설정
Empirical Cumulative Distribution Functions
- 히스토그램에서 비닝(Binning)하는 것은 빈(Bin) 크기를 변경할 때 구조가 변경될 수 있고 각 빈에는 통계적 불확실성이 존재한다.
- CDF를 사용하면 이 문제를 해결할 수 있다.
- CDF를 볼 때 시각적으로 PDF의 기능을 보기가 더 어렵지만 일반적으로 여러 분포 사이에서 정량적 비교를 시도할 때 더 유용하다.
sd1 = np.sort(d1)
sd2 = np.sort(d2)
cdf = np.linspace(1/d1.size, 1, d1.size)
plt.plot(sd1, cdf, label="D1 CDF")
plt.plot(sd2, cdf, label="D2 CDF")
plt.hist(d1, histtype="step", density=True, alpha=0.3)
plt.hist(d2, histtype="step", density=True, alpha=0.3)
plt.legend()
plt.show()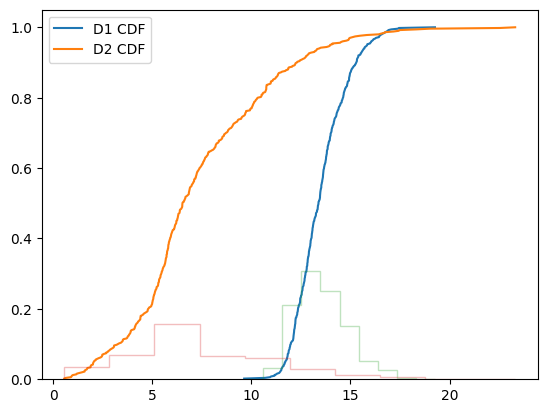
- 참고 : 유데미 - 【한글자막】 Python : 통계 분석을 위한 파이썬

데이터 분석하고 있습니다