ABSTRACT
-
광범위한 변수 변환을 통한 작업은 해석은 쉬우나 feature engineering에 많은 노력이 필요하다.
-
deep neural networks는 보이지 않는 변수 조합에 대한 일반화를 더 잘할 수 있다. -> 다만, sparse and high-rank일 경우 과적합 혹은 상관 없는 아이템이 추천될 수 있다.
-
Wide and deep learning - jointly trained wide linear models and deep neural network : 넓은 wide model과 deep model을 함께 훈련시킨 방법론을 제시
1. INTRODUCTION
-
추천 시스템의 한가지 어려운점은 memorization(암기)과 generalization(일반화)을 동시에 달성하는 것이다.
-
몇 가지 차이점을 나열하면 아래와 같다.
1. memorization은 동시에 발생하는 아이템이나 피처를 학습하고 사용 가능한 과거 데이터의 상관관계를 추출하는 작업으로 정의된다.
<-> 반면에 generalization은 상관관계의 이행성(A>=B & B>=C -> A>=C)에 기반하고 과거의 드문거나 존재하지 않았던 새로운 변수 조합을 탐구한다.
2. memorization의 경우에는 사용자의 행동과 관련있는 아이템에 관련이 있다.
<-> 반면에 generalization은 다양성을 향상시키려는 경향이 있다.
-
로지스틱 같은 일반적인 선형 모델이 간단하고 확장가능하고 해석하기 쉽기 때문에 널리 사용된다.
-
모델은 종종 이진화된 희소 피처를 활용해 훈련시킨다.
ex) user_installed_app=netflix -
memorization은 위의 예시를 cross-product transformations를 활용해 AND(user_installed_app=netflix, impression_app=pandora)와 같이 표현을 하며 이는 사용자가 netflix를 설치했고 이후 pandora에 노출되었다면 1로 표시된다.
-
generalization은 덜 세분화된 변수
(ex. AND(user_installed_category=video, impression_category=music))로 활용할 수 있지만, 수작업을 많이 요한다. -
따라서 교차곱 변수 변환의 한계 중 하나는 훈련데이터에 나타나지 않은 query-item feature 쌍은 일반화 할 수 없다.
-
Embeding-based models(ex. factorization machines or deep neural networks)의 경우
- 장점 : 이전에 볼 수 없었던 query-item feature를 피쳐 엔지니어링을 줄이면서 일반화를 할수 있다.
- 단점 : 특정 선호도를 가진 사용자나 희소하고 높은 차원의 경우 저차원 표현으로 효과적으로 학습하는 건 어렵다.
In this paper, we present the Wide & Deep learning framework to achieve both memorization and generalization in one mode, by jointly training a linear model component and a neural network component
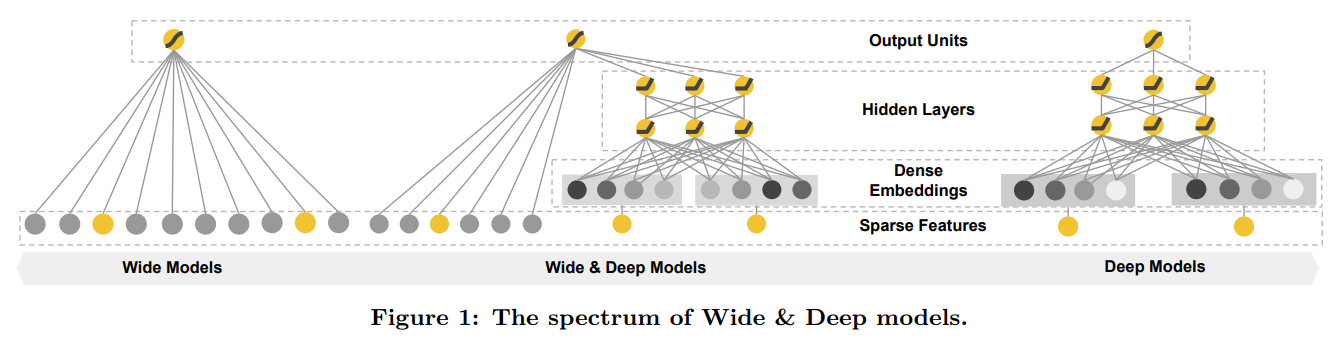
- 모델 구성을 보면 아이디어는 단순한데 Wide & Deep 프레임워크는 룬현과 서비스 스피드에 있어 모바일 앱스토어 가입률을 크게 향상 했다고 한다.
2. RECOMMENDER SYSTEM OVERVIEW
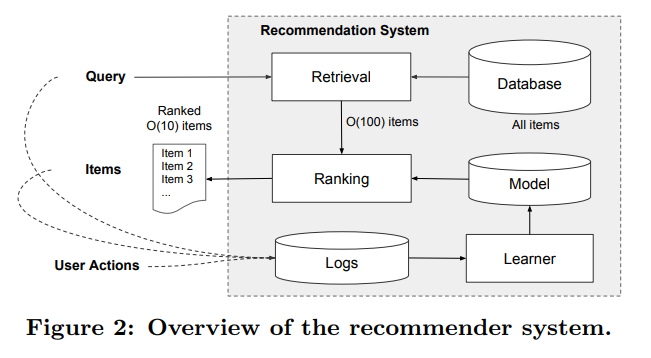
- 사용자가 앱 스토어를 방문하면 사용자 본인과 맥락에 관련된 다양한 피쳐가 포함되어 query(질의문)이 생성된다.
- 추천 시스템에서 (사용자가 클릭이나 구매 같은 특정 동작을 수행할 수 있는) 앱 리스트가 출력된다.
- 사용자 동작은 query와 impresstion 과 함께 학습을 위한 훈련 데이터로 로그에 기록된다.
** 앱의 수가 백만개가 넘기에 모든 query에 점수를 매기는 작업은 힘듬. -> 이를 해결 하기 위해 query를 받은 후 첫번째 작업은 검색(retieval)이다.
** 검색 시스템은 다양한 신호(일반적으로 기계 학습 모형과 사람이 정의한 규칙 조합)를 사용하여 매치가 잘된 상품의 짧은 목록을 반환한다.
** 후보의 범위(pool)를 줄인 후 순위 시스템은 모든 품목마다 점수 순위(조건부 확률)를 매긴다.
3. WIDE & DEEP LEARNING
3.1 The Wide Component
- 넓은 쪽 구성 요소는 위의 그려진 일반화 선형 모델(y=w^T*x+b)이다.
- x : vdtor of d feature
- w : the model parameters
- b : bias
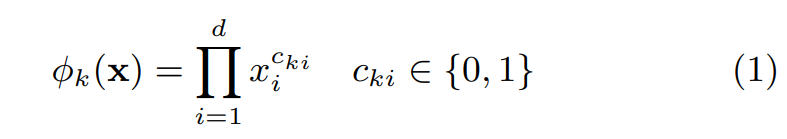
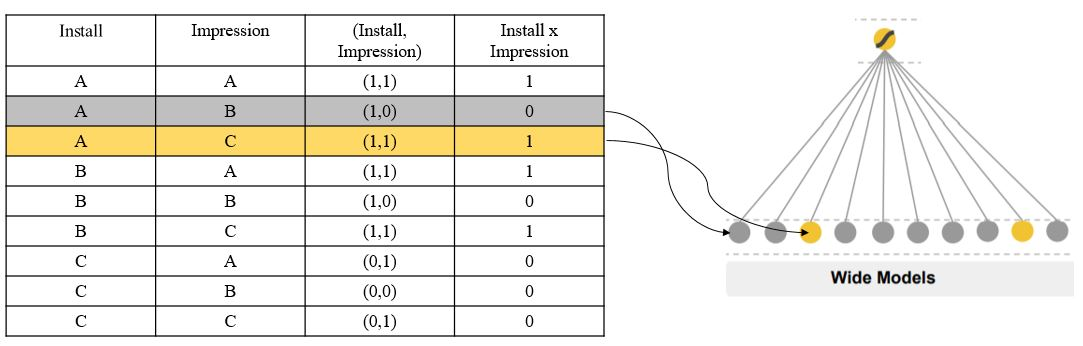
예를 들어 앱은 A, B, C 총 3개만 존재하며, user가 설치한 앱과 클릭한 앱은 아래와 같다고 하자.
- user_install_app = [A, B]
- user_impression_app = [A, C]
여기서 가능한 경우의 수는 총 4가지 뿐이며, 해당 방식은 1이 되는 경우를 학습하기 때문에 memorizaion에 강하고, user의 특이 취향이 반영된 niche combination을 학습하기에 탁월하지만, 0이 되는 경우엔 학습이 불가능하기에 단점이 존재한다.
3.2 The Deep Component
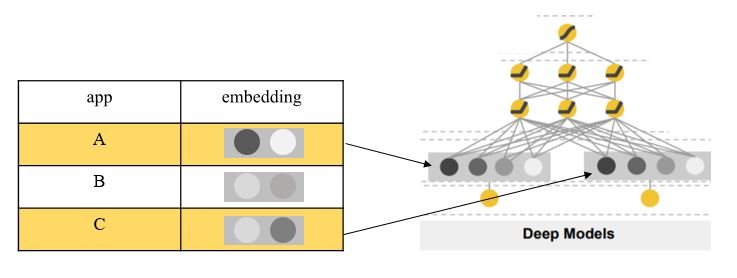
- deep component는 feed-forward neural network이다.
- 범주형 변수의 경우 원래 입력값은 문자열 변수(예: “language = en”)이다. 이런 희소하고 고차원인 범주형 변수 각각은 먼저 임베딩 벡터라고 하는 저 차원의 밀집한 실수 값 벡터로 종종 변환된다.
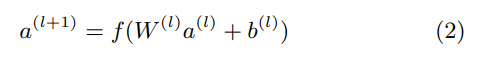
3.3 Joint Training of Wide & Deep Model
- wide component와 deep component는 결합되어 log odds 가중치 합계를 예측치로 사용하며 joint training(여러 개의 loss들을 하나의 값으로 더해서 최종 loss로 사용하는 훈련 방식)을 위해 하나의 공통 로지스틱 손실 함수에 제공된다.
** ensemble & joint traing 차이점 주의!!
-
훈련 방식 :
ensemble의 경우 개별 모델들이 다른 모델을 모를 때 개별적으로 훈련을 하고 예측할때 합쳐지는 것이다(훈련할때x)
<-> joint traing의 경우 wide와 deep 부분 모두와 그 합계 가중치들을 훈련을 통해 고려하면서 매개변수 모두를 동시에 최적화시킨다. -
사이즈 :
ensemble의 경우 훈련이 분리되어 있으므로 합리적인 정확도를 얻기 위해 개별 모형 커야 한다.(예: 더 많은 변수와 변수 변환)
<-> joint traing의 경우 wide부분은 전체 크기의 wide 모형보다 적은 수의 교차곱 변수 변환으로 깊은 쪽 약점을 보완하기만 하면 된다.
- Wide & Deep 모형 공동 훈련은 mini-batch stochastic optimization을 사용해 동시에 wide, deep부분을 역전파시킨다.
- wide part : Follow-the-regularized-leader(FTRL) 알고리즘
- deep part : AdaGrad
- 결합 모형
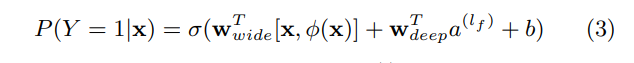
4. SYSTEM IMPLEMENTATION
- 앱 추천 파이프라인 구현은 데이터 생성, 모델 훈련 및 모델 서비스 3단계로 구성된다
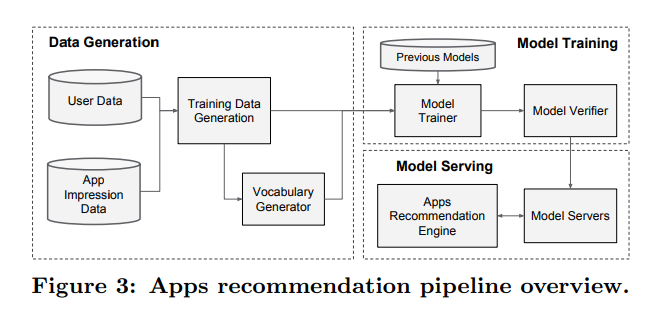
4.1 Data Generation
- 일정 기간 동안 사용자 및 앱 노출 데이터를 사용하여 훈련 데이터를 생성한다. 각 샘플은 노출 한 번에 해당한다.
- 레이블의 경우엔 노출된 앱을 설치하면 1이다.
- Categorical Feature Strings를 정수 ID로 매핑하는 테이블인 어휘(Vocabularies)도 이번 단계에서 생성된다.
- 시스템은 최소 횟수 이상으로 발생한 모든 String Feature에 대한 ID 공간을 계산한다.
- 연속적인 실수 값 변수는 변숫값 x를 누적 분포 함수 P(X <= x)에 연결하여 np 분위수로 나누어 [0,1]로 정규화 한다.
- 정규화한 값은 i번째 분위수에 대해 i-1/nq-1이다.
- 데이터 생성 동안 분위값 경계를 계산한다.
4.2 Model Training
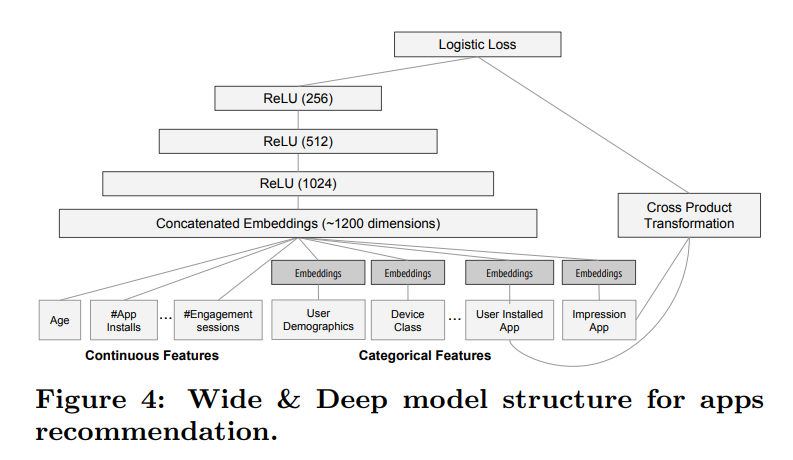
- 훈련 과정에서 입력층은 훈련 데이터와 어휘(Vocabularies)를 받아들여 레이블과 함께 sparse and dense 변수를 생성한다.
- 1. wide 부분의 구성 요소 : 사용자가 설치한 앱과 노출된 앱의 Cross-Product Transformation으로 구성
- 2. deep 부분의 구성 요소 : 32차원 임베딩 벡터가 각 범주형 변수에 대해 학습한다. - 모든 임베딩을 dense feature와 연결하여 약 1,200차원 dense 벡터를 생성한다.
- 연결한 벡터를 3개의 ReLU 층으로 전달하고 마지막으로 로지스틱 출력 단위로 전달한다.
- Wide & Deep 모형을 5천억 개가 넘는 샘플로 훈련시킨다.
- 여기서 새로운 훈련 데이터가 수집될 때마다 모형을 다시 훈련시켜야 하는데 매번 처음부터 재훈련시키는 건 비용이 크고 서비스까지 시간이 많이 소요된다.
-> 이 문제를 해결하기 위해 a warm-starting system(임베딩과 이전 모형의 선형 모형 가중치를 사용하여 새 모형 초기값을 설정)을 구현했다.
4.3 Model Serving
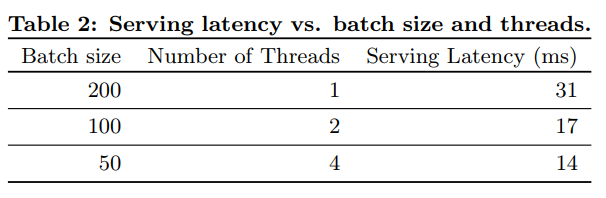
- 여기서의 특징은 10ms 단위로 각 요청을 처리하기 위해 추론 단계를 단일 배치로 후보 앱 전체에 점수를 매기는 대신 멀티스레딩 병렬 처리를 통해 미니 배치를 병렬로 돌려서 성능을 최적화했다.
5. EXPERIMENT RESULTS
5.1 App Acquisitions
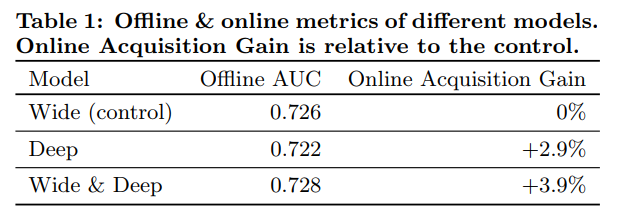
- wide & Deep 모형은 앱 스토어 방문 페이지 상의 앱 가입률이 대조군 대비 3.9% 향상했다.(통계적으로 유의)
- 또 다른 1% 그룹에 변수는 동일하고 신경망 구조의 깊은 쪽만 사용한 모형을 적용하여 결과를 비교했고 Wide & Deep 모형은 깊은 쪽만 사용한 모형 대비해서 가입률을 1% 증가시켰다.(통계적으로 유의미함)
- 오프라인 AUC 또한 Wide & Deep 모형이 다소 높지만 온라인 트래픽에서 영향력이 더 강하다.
- 오프라인 데이터셋 노출과 레이블은 고정되어있지만 온라인 시스템은 일반화와 암기를 혼합하여 탐색적으로 추천해볼 수 있고 그에 따라 사용자 응답으로 학습 가능하다는 점이 이유 중 하나일 것이다.
5.2 Serving Performance
참고 링크 :
https://aldente0630.github.io/data-science/2018/04/28/wide_and_deep_learning_for_RS.html
논문 링크 :
https://arxiv.org/abs/1606.07792
