Abstarct
- 추천 시스템에서는 CTR(click through rate)를 극대화 하기 위해 유저 행동에 숨겨진 정교한 피쳐들의 상호 관계를 학습하는 것이 중요하다.
- 많은 발전이 있었지만 기존에는 low-order 또는 high-order 중 하나에만 치우쳐 학습하거나 피쳐 엔지니어링이 필요하다.
- 이 논문에서는 low-order과 high-order의 피처 관계를 end-to-end 모델로 학습할 수 있음을 보였다.
- 제안한 모델 DeepFM은 Factorization Model이 추천에서 갖는 강점과 Deep Learning이 Feature학습에서 갖는 강점을 결합한 새로운 Neural Network 구조이다.
- 구글에서 발표한 Wide & Deep Model(참고자료)과 비교해했을때, DeepFM은 Wide 부분과 Deep 부분이 공통된 입력을 받고 Feature Engineering이 필요하지 않다.
- DeepFM의 학습 효율성(efficiency)과 성능 효율성(effectiveness)이 기존의 CTR 예측 모델보다 좋은 성능을 보임을 benchmark data와 commercial data를 통해 보였다.
1. Introduction
-
CTR값도 중요하지만, 온라인 광고 같은 다른 시나리오에서는 수입(revenue)의 증가 또한 중요하다. -> 이러한 경우에는 전략은 CTR X bid(유저가 아이템을 클릭할 때마다 받는 보상) 값으로 조정된다.
-
어떤 경우에, CTR을 정확하게 예측이 핵심이다.
-
CTR을 정확히 예측하기 위해서는 Implicit Feature간의 상호 작용을 학습하는 게 중요하다.
** Implicit feature : 리뷰에는 나타나지 않는 묵시정인 특징이다.
- ex1. 배달 앱의 Category와 시간대의 상호작용(order-2 : feature가 두 개)이 CTR 예측을 위한 신호로 쓸 수 있음을 암시한다. -> 식사 시간에 배달 앱 다운로드
- ex2. 10대 남자들이 슈팅 게임과 RPG 게임을 좋아한다는 점인데 이는 앱의 category, 사용자의 성별과 나이대의 상호작용(order-3)이 또 다른 CTR 신호임을 의미한다. 이 경우에는 보통 유저 행동에 숨겨진 이런 상호 작용은 매우 복잡하고, 저차원 & 고차원 상호작용 전부 중요한 역할을 한다. 구글이 발표한 Wide & Deep Model 논문의 관찰에 의하면 저차원, 고차원 상호작용을 동시에 고려하는 경우가 하나씩만 고려하는 경우보다 더 좋은 성능을 나타낸다. -
key challenge는 효율적으로 피쳐들 간의 상호작용을 Modeling하는 것이다. 어떤 피쳐 상호작용은 쉽게 이해할 수 있어서 앞선 예시처럼 전문가가 수작업할 수 있다. 그러나 대부분의 피쳐 상호작용은 데이터 속에 숨겨져 있고 선험적(priori)으로 알기 어려워서 머신러닝을 통해 자동적으로 발견할 수 있다. 이해하기 쉬운 상호작용 또한 전문가가 피쳐의 수가 많을때에는 전부 모델링하기는 불가능해 보인다.
-
선형 모델은 피쳐 상호작용을 학습하기는 부족하다. -> 피쳐 벡쳐들간의 pairwise interaction을 직접 feature로 넣는다. 이러한 방법은 고차원의 피처의 상호작용 또는 훈련 데이터에 존재하지 않는 경우를 일반화하기 어렵다.
- Factorization Machine(FM)은 pairwise 피쳐 상호작용을 피쳐의 latent vector 끼리의 내적을 통해 모델링했고 매우 괜찮을 결과를 냈다. FM모델이 높은 차원의 피쳐 상호작용을 모델링할 수 있지만 실제로는 높은 복잡도 때문에 거의 order-2 상호작용만 고려한다. -
feature representation 학습하는 강략힌 접근법인 deep neural networks는 정교한 피처 상호관계를 학습할 수 있는 가능성을 가지고 있다.
-1. Factorization-machine supported Neural Network(FNN)
-2. Product-based Neural Network(PNN) -
기존의 모델을 낮은 차원 혹은 높은 차원의 피쳐 상호작용을 모델링하는데 치우쳐 있다. 이 논문에서 모든 차원의 피쳐 상호 작용을 end-to-end 방식으로, feature engineering 없이 학습하는 모델을 유도할 수 있음을 보인다.
-
Contribution 요약
-1. FM과 DNN의 구조를 결합한 새로운 신경망 모델DeepFM(FM을 통해 낮은 차원의 피쳐 상호작용을 학습하고 DNN을 통해서는 높은 차원의 피쳐 상호작용을 학습)을 제시한다. Wide & Deep 모델과는 달리 DeepFM은 end-to-end로 feature engineering이 필요 없이 학습할 수 있다.
-2. DeepFM은 Wide & Deep과는 다르게 같은 input과 embedding layer를 공유하기 때문에 효율적으로 학습할 수 있다.
-3. DeepFM을 benchmark data와 commercial data에 평가해본 결과 기존 모델보다 좋은 결과를 보였다.
2. Our Approach
-
DeepFM의 데이터 구조는 총 n개의 데이터가 있다고 할 때, 각 row는 user와 item 정보를 담고 있는 x와 특정 아이템 클릭여부를 나타내는 y로 이루어져 있다.

-
x : m개의 필드로 이뤄져 있으며 각 필드는 다양한 정보를 담고있다. ex. user 필드에는 user의 id, 성별, 나이 등의 정보가, item 필드에는 특정 item의 구매 정보 등이 포함된다. 각 필드에는 카테고리 피처일 경우 one-hot 벡터로, 연속적인 피처일 경우 해당 값을 그대로 사용할 수 있다. 일반적으로 x는 굉장히 sparse 하며 고차원이다.
-
y : user의 특정 item에 대한 클릭여부를 나타낸다. 만약 user가 특정 item을 클릭 했을 경우 y=1, 클릭하지 않았을 경우 y=0이 된다.
-
위와 같은 데이터 구조를 고려할 때, DeepFM의 목표는
x 가 주어졌을 때, user가 특정 item을 클릭할 확률을 예측하는 것이 된다.

2.1 DeepFM
- 목표 : 낮은 차원과 높은 차원의 피쳐 상호작용 둘 다를 학습하는 것

-
Figure 1에서 보듯이 DeepFM은 같은 input을 공유하는 FM component와 deep component로 구성되어 있다.
-
피쳐 i에 대해서, 스칼라 값 w_i는 order-1 중요도 가중치로 사용되고 잠재 벡터(latent vector) V_i는 다른 피쳐와 상호작용 정도를 측정하는 데 사용된다.
-
V_i는 order-2 상호작용을 모델링하기 위해서 FM component로 들어가는 반면 높은 차원의 피쳐 상호작용을 모델링하기 위해서 Deep Component로 들어간다.
-
w_i 와 V_i 그리고 network 변수(W^{l}, b^{l})을 포함한 모든 변수는 아래 수식과 같이 결합된 예측 모델에서 같이 학습된다.
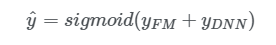
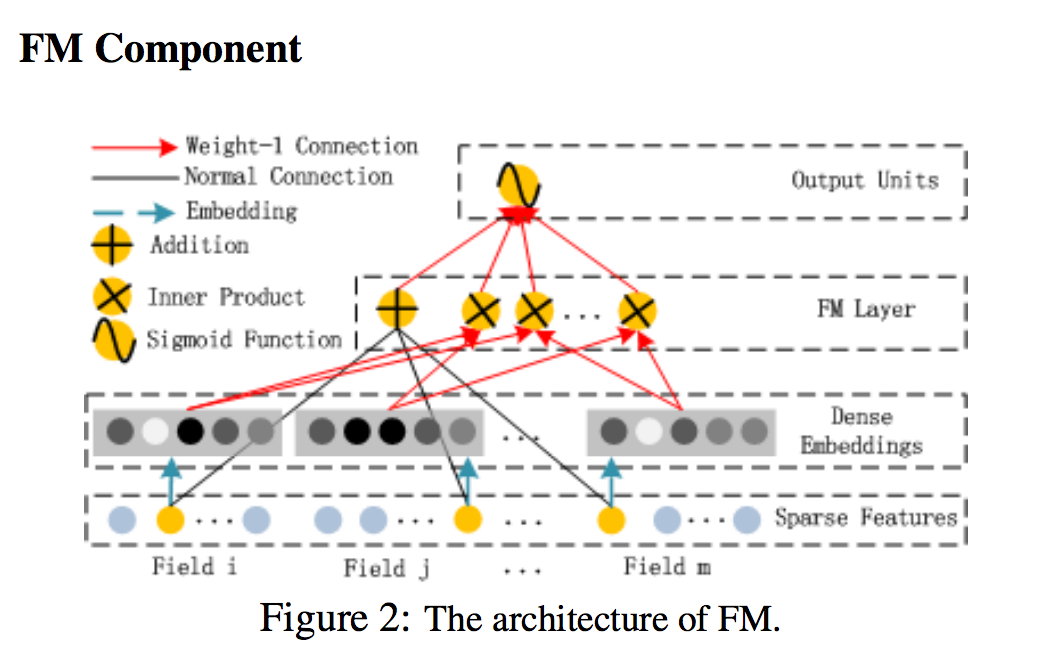
FM Component
-
FM components는 추천 시스템을 위해서 기능 상호 작용을 배우기 위해 제안된 factorization machine이다.
-
선형(order-1) 상호 작용 외에도 FM 모델은 쌍방향(order-2) 상호 작용을 각각의 피쳐 잠재 벡터의 내부 곱이다.
- 이 방법은 데이터 세트가 희박할 때 이전 접근법보다 훨씬 효과적으로 주문 order 2 Feature 상호 작용을 캡처할 수 있다.- 이전 접근법에서 feature i와 feature j의 상호 작용 매개 변수는 feature i와 feature j가 모두 동일한 데이터 레코드에 나타날 때만 훈련 될 수 있다.
- FM에서 latent 벡터 Vi와 Vj의 내부 곱을 통해 측정될 수 있다. - 이 유연한 디자인으로 인해 FM은 데이터 레코드에 i (또는 j)가 나타날 때마다 잠재 벡터 V_i(V_j)를 훈련시킬 수 있음
- 훈련 데이터에 나타나지 않거나 거의 나타나지 않는 기능 상호 작용은 FM에서 더 잘 학습된다.
- 이전 접근법에서 feature i와 feature j의 상호 작용 매개 변수는 feature i와 feature j가 모두 동일한 데이터 레코드에 나타날 때만 훈련 될 수 있다.
-
Figure 2가 보여 주듯이, FM의 출력은 추가 단위와 다수의 내부 제품 단위의 합
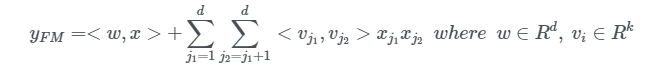
Deep Component
- DNN 요소는 feed-forward neural network으로 고차 기능 상호 작용을 배우는 데 사용된다.

-
Figure 3에서 볼 수 있듯이 데이터 레코드(벡터)가 신경망에 학습된다. (FM 모델에서는 embedding 벡터가 interaction 텀의 가중치의 역할을 했다면, DNN 모델에서는 input으로 사용된다.)
-
순전히 연속적이고 밀도가 높은 입력으로 이미지 또는 오디오 데이터를 가진 신경망과 비교할 때 CTR 예측의 입력은 매우 다르므로 새로운 네트워크 아키텍처 설계를 요구한다.
-
특히, CTR 예측을 위한 raw feature input vector은 일반적으로 매우 희박하고, 초고차원, 범주형 연속 혼합 및 필드(예 : 성별, 위치, 연령)로 그룹화된다.
-
이것은 입력 벡터를 첫 번째 숨겨진 레이어로 저차원의 고밀도 실수 값 벡터로 압축하기 위한 임베딩 레이어로 제안했다. 그렇지 않다면 이 네트워크는 학습하기 버거울 것이라 한다.

-
Embedding Layer 구조에서 두 가지 흥미로운 점.
- 1) 다른 field의 input vector의 길이는 다를 수 있지만 embedding은 같은 크기(k)이다.
- 2) FM에서의 latent feature vector(V)가 이 네트워크의 가중치로 사용되고 input field vector를 압축하는 데 사용되고 학습된다. -
[Zhang et al., 2016]에서는 V가 FM에 의해 pre-trained되고 이 값을 초기값으로 사용한다. 이번 논문에서는 이런 방법을 사용하는 대신 FM을 DNN과 별개로 학습 구조에 포함한다. 이렇게 함으로써 pre-training을 할 필요가 없어지고 전체 네트워크를 end-to-end로 학습할 수 있게 된다. Embedding Layer의 output을 다음과 같이 표현하면 아래와 같다.
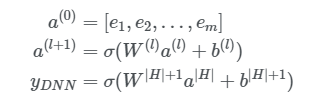
- FM 구성 요소와 딥 구성 요소는 동일한 기능 임베딩을 공유하므로 두 가지 중요한 이점을 제공한다.
1) raw features로 부터 low 및 high 기능 상호 작용을 배운다.
2) Wide & Deep에서 요구되는대로 입력의 전문가의 기능 엔지니어링이 필요하지 않다.
2.2 Relationship with the other Neural Networks
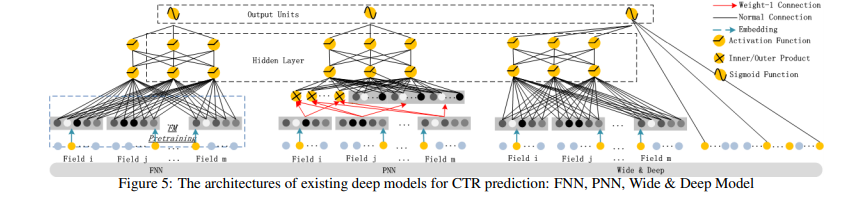
-
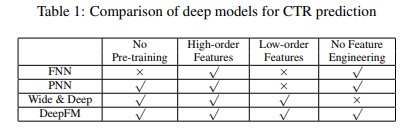
FNN : DNN component만을 활용하고 Embedding시에 FM Pre-Trained된 값으로 initialization한다. High-Order를 상호작용을 학습할 수는 있지만 Low-Order학습은 불가능하다.
-
PNN : DNN Component구조에서 Product Layer를 추가한 형태이다. Inner Product를 활용할 수도 있고 Outer Product를 활용할 수도 있고 둘 다 활용할 수도 있다. Outer Product를 활용하는 경우 근사법을 사용하기 때문에 feature 정보를 많이 잃어버리고 이 때문에 unstable해진다. Inner Product의 경우 더 reliable하지만 Product Layer 이후에 Hidden Layer의 모든 neuron에 연결되기 때문에 High Computational Complexity가 요구된다. PNN과 다르게 DeemFM은 오직 마지막 output layer(하나의 neuron)에만 연결된다. FNN과 같이 Low-Order학습은 불가능하다.
-
Wide & Deep : DeepFM과 다르게 Wide Part의 Input을 직접 feature engineering 해야 한다. 이 모델의 Linear Regression(LR)부분을 FM으로 바꾸면 DeepFM과 비슷하지만 DeepFM은 Feature Embedding을 Share한다는 점이 다르다. Embedding을 share하는 방식은 low-order, high-order 상호작용을 표현하는 feature representation에 영향을 미쳐 더 정교하게 만든다.
-> 요약 : DeepFM는 pre-training, feature engineering를 요구하지 않으며 low and high order featuer의 상호 작용을 포착할 수 있다. -> 성능이 기본의 것들보다 더 좋다.
3. Experiment - 생략
3.1 Experiment Setup - 생략
3.2 Performance Evaluation - 생략
3.3 Hyper-Parameter Study - 생략
4. Related Work - 생략
5. Conclusions
- 이 논문에서 CTR 예측을 위한 Factorization-Machine 기반 신경망인 DeepFM을 제안하여 최첨단 모델의 단점을 극복하고 더 나은 성능을 달성했다.
- DeepFM은 딥러닝 구성 요소와 FM 구성 요소를 공동으로 학습한다.
- 아래의 이점을 통해 향상된 효과를 보여준다.
1) pre-training 필요 없음
2) high-order 및 low-order 기능 상호 작용을 모두 학습
3) feature engineering을 피하기 위해 피쳐 임베딩전략을 소개합니다.
- Deep FM과 최첨단 모델의 효율성과 효율성을 비교하기 위해 두 개의 실제 데이터 세트(크리테오 데이터셋과 상업용 앱 스토어 데이터 세트)에 대한 광범위한 실험을 실시하였다.
1) DeepFM이 두 데이터 세트에서 AUC 및 Logloss 측면에서 최첨단 모델보다 성능이 뛰어났다는 것을 보여준다.
2) DeepFM의 효율성은 최첨단에서 가장 효율적인 딥 모델과 비교할 수 있습니다
- 미래 연구를 위한 두 가지 흥미로운 방향:
- 1. 가장 유용한 고차원 기능 상호 작용을 학습하는 능력을 강화하기 위해 일부 전략 (예 : 풀링 레이어를 도입하는 것)을 탐구하는 것
- 2. 다른 하나는 대규모 문제를 위해 GPU 클러스터에서 DeepFM을 훈련시키는 것
논문 링크 : https://www.ijcai.org/Proceedings/2017/0239.pdf
참고 링크 :
1. https://orill.tistory.com/entry/%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-DeepFM-A-Factorization-Machine-based-Neural-Network-for-CTR-Prediction
2. https://leehyejin91.github.io/post-deepfm/
