
YOLO(You Only Look Once)는 논문 본문에서 R-CNN계열 모델보다 성능이 좋다고 알려져 있다.
It outperforms other detection methods, including DPM and R-CNN, when generalizing from natural images to other domains like artwork.
또한, YOLO의 가장 큰 특징은 Object detection을 이미지 픽셀 좌표에 대응되는 bounding box을 찾고 그것에 대한 class확률을 구하는 Single Regression Problem으로 진행된다.
*(Mask R-CNN의 경우 region proposal methods로 잠재적인 바운딩 박스를 생성한후 proposed 박스의 분류를 실시한다. 이러한 복잡한 파이프라인은 개개인의 요소가 분리되어 학습되어야 하므로 느리고 최적화하기 어려운 단점이 존재한다.)
과정
YOLO의 경우 아래의 이미지처럼 하나의 convolutional network 가 한번에 여러개의 bounding boxes를 예측하고, 각 bounding box에 대해 class probabilities 를 예측한다.

- 이미지를 448 * 448 로 크기 변경
- 이미지에 단일 convolution network를 시행
- 모델의 신뢰도에 의한 결과 detection의 thresholds를 정한다.
특징
- YOLO is extremely fast
- 복잡한 파이프라인 필요X
- 45 fps(frame per second)(빠른 버전의 경우 150fps) -> 실시간 활용이 가능
- YOLO reasons globally about the image when
making predictions.
- sliding window 와 region proposal-based와 달리 yolo는 전체 이미지를 보기 때문에 class에 대한 맥락적 이해도가 높다.
- Fast R-CNN같은 탐지 방법은 이미지를 배경으로 범하는 오류를 범하지만, YOLO의 경우 절반 이하의 오류가 발생한다.
- YOLO learns generalizable representations of objects
Unified Detection
: 네트워크의 큰 특징 중 하나는 이미지 전부로부터 features를 뽑아서 각 bounding box를 예측한다는 것이다.
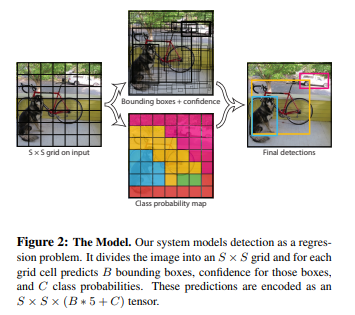
-
Input image를 S X S grid로 나눔
-
각각의 grid cell은 B개의 bounding box와 bounding box의 confidence score를 갖는다. (confidence score은 박스가 객체를 보유하고 있다고 생각하는 모델의 신뢰도와 예측하는 박스의 정확도를 반영한다.)
-
Confidence Score = Pr(Object)∗IOU
(object가 없다면 confidence score = 0) -
Conditional Class Probability: Pr(Classi|Object)
-
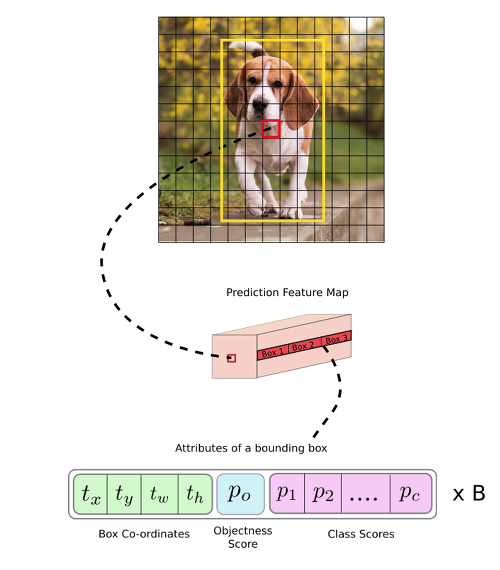
각각의 bounding box는 x, y, w, h, confidence로 구성된다.
-
bounding box 구성 : x, y, w, h, confidence
- (x,y): Bounding box의 중심점
- (w,h): 전체 이미지의 width, height
-
각각의 grid cell은 C개의 conditional class probability를 가지게 된다.
-
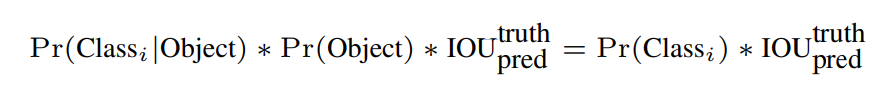
Network Design

- YOLO의 architecture는 GoogLeNet model에서 영감을 받았다. YOLO는 24개의 convolutional layers과 2개의 fully connected layers로 구성되어 있다.
-
이 계산을 각 bounding box에 대해 하게되면 총 98개(7x7x2(grid x bounding box))의 class specific confidence score를 얻을 수 있다.
-
이 98개의 class specific confidence score에 대해 각 20개의 클래스를 기준으로 non-maximum suppression을 하여, Object에 대한 Class 및 bounding box Location를 결정한다.
Training
-
ImageNet 1000-class competition dataset을 이용하여 convolutional layer를 미리 학습
-
마지막 layer은 bounding box의 좌표와 class의 확률 모두를 예측한다. image의 width와 height와 bounding box의 width, height의 비율로 파라미터를 정규화고, 그 결과로 해당 값들은 0과 1사이로 오도록 한다. 또한 bounding box의 x와 y의 좌표를 특정한 grid cell 의 위치에 offset되도록 매개변수화하여 0과 1사이의 오도록 한다.
-
마지막 layer에는 linear activation function을 사용하였고 나머지 다른 layer에는 leaky를 사용함.
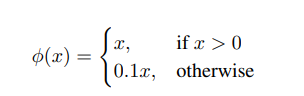

- 첫번째줄 : Object가 존재하는 grid cell i의 predictor bounding box j에 대해, x와 y의 loss를 계산.
- 두번째줄 : Object가 존재하는 grid cell i의 predictor bounding box j에 대해, w와 h의 loss를 계산. 큰 box에 대해서는 small deviation을 반영하기 위해 제곱근을 취한 후, sum-squared error를 한다.(같은 error라도 larger box의 경우 상대적으로 IOU에 영향을 적게 준다.)
- 세번째줄 : Object가 존재하는 grid cell i의 predictor bounding box j에 대해, confidence score의 loss를 계산. (Ci = 1)
- 네번째줄 : Object가 존재하지 않는 grid cell i의 bounding box j에 대해, confidence score의 loss를 계산. (Ci = 0)
- 다섯번째줄 : Object가 존재하는 grid cell i에 대해, conditional class probability의 loss 계산. (Correct class c: pi(c)=1, otherwise: pi(c)=0)
- λcoord: coordinates(x,y,w,h)에 대한 loss와 다른 loss들과의 균형을 위한 balancing parameter
- λnoobj: obj가 있는 box와 없는 box간에 균형을 위한 balancing parameter. (일반적으로 image내에는 obj가 있는 cell보다는 obj가 없는 cell이 훨씬 많기에 활용함)
Limitations of YOLO
- 각각의 grid cell이 하나의 클래스만을 예측 -> 작은 object 붙으면 제대로 예측이 정확하지 않음.
- bounding box의 형태가 training data를 통해서만 학습되므로, 새로운/독특한 형태의 bouding box의 경우 정확히 예측하지 못한다.
- 몇 단계의 layer를 거쳐서 나온 feature map을 대상으로 bouding box를 예측하므로 localization이 다소 정확하지 않은 경우가 있다.
- 참고 링크 :
1. https://curt-park.github.io/2017-03-26/yolo/
2. https://wingnim.tistory.com/56
3. https://docs.google.com/presentation/d/1aeRvtKG21KHdD5lg6Hgyhx5rPq_ZOsGjG5rJ1HP7BbA/pub?start=false&loop=false&delayms=3000&slide=id.g137784ab86_4_484
- 논문 링크 : https://arxiv.org/abs/1506.02640
