
8장 고급 쿼리 (2)
이어서 계속
고급 SQL
- 여기서는 SQL 엔진마다 상당히 다르지만 빅쿼리에 포함할 가치가 있는 SQL 문법이 나온다. 배열 및 윈도우 함수는 쿼리 성능을 크게 높일 수 있따.
- 테이블 메타데이터는 리플렉션(테이블의 스키마를 기반으로 런타임에 SQL 쿼리의 자체 구조 및 작동을 수정할 수 있는 기능)을 가능하게 하며, 일반적인 문제에 대한 몇 가지 깔끔한 해결책을 제공한다.
- DDL/DML을 이용하면 SQL만으로 다양한 테이터베이스 유지 관리 작업을 수행할 수 있으므로 SQL 쿼리에서 사용하던 개발, 검토, 테스트 또는 지속적 통합/지속적 배포 프레임워크를 유지 보수 업무에도 그대로 사용할 수 있다.
배열 다루기
- 빅쿼리의 배결은 같은 데이터 타입으로 구성된 순서가 있는 리스트다. 정렬해야 하거나 단일 행에 반복되는 값들을 저장해야 할 때 배열을 사용한다.
데이터를 배열로 저장하면 스토리지의 오버헤드를 줄일 수 있으며, 카디널리티에 따라 필드를 반복할 필요가 없는 쿼리의 속도가 눈에 띄게 향상한다. 그러므로 배열의 특징을 잘 이해하고 익히는 것이 중요하다.
- 순서를 유지하며 배열 사용하기
- 다른 쿼리 또는 빅쿼리 외에서 나중에 사용할 수 있도록 100개의 행을 테이블에 저장할 수 있지만, 테이블에서 읽은 행이 같은 순서로 정렬될 것이라는 보장이 없다.
- 이를 위해 구체화된 뷰를 사용하는 것이다. 또 다른 방법은 결과를 하나의 배열로 모아 한 행으로 만든 후 ARRAY_AGG 함수 안에서 ORDER BY 및 LIMIT 절을 사용하는 것이다.
WITH numtrips AS (
SELECT
bike_id AS id,
COUNT(*) AS num_trips
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
GROUP BY
bike_id
)
SELECT
ARRAY_AGG(STRUCT(id,num_trips) ORDER BY num_trips DESC LIMIT 100) AS bike
FROM
numtrips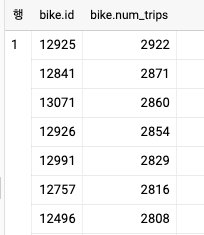
2. 반복되는 필드를 저장하기 위해 배열 사용하기
- 배열을 사용하는 또 다른 경우는 굳이 순서를 신경 쓰지 않더라도 반복되는 필드를 저장해야 하는 경우다.
- 원본데이터가 아래와 같을 때 배열을 활용한 것은 그 아래의 예제이다.
-- 원본 데이터
SELECT *
FROM `bigquery-public-data`.irs_990.irs_990_2015
LIMIT 3
-- 수정 데이터
SELECT
ein
, ARRAY_AGG(STRUCT(elf, tax_pd, subseccd)) AS filing
FROM `bigquery-public-data`.irs_990.irs_990_2015
WHERE ein BETWEEN '390' AND '399'
GROUP BY ein
LIMIT 3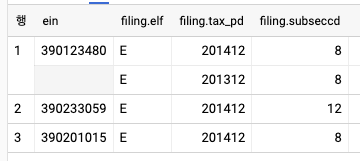
3. 데이터를 생성하기 위해 배열 사용하기
- 데이터를 생성해야할 경우에도 배열은 유용하다.
- 예시로 여름에 10일마다 잔디를 깍아야 하고 이 일을 대신해 줄 미니언이 3명있다고 가정하고 3명의 미니언이 돌아가게 잔디를 깍게 하려는 쿼리이다
SELECT
GENERATE_DATE_ARRAY('2019-06-23', '2019-08-22', INTERVAL 10 DAY) AS summer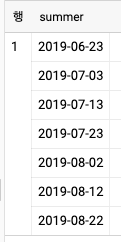
- 날짜의 목록을 생성하였는데 전부 하나의 행에 속해 있으므로 각 날짜를 개별 행에 저장하는 다중 행 테이블을 생성하려면 아래와 같이 UNNEST를 사용하면 된다.
WITH days AS (
SELECT
GENERATE_DATE_ARRAY('2019-06-23', '2019-08-22', INTERVAL 10 DAY) AS summer
)
SELECT summer_day
FROM days, UNNEST(summer) AS summer_day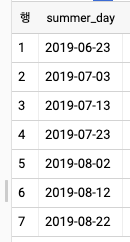
- 미니언 목록은 아래와 같이 하드 코딩할 수 있다.
SELECT ['Lak', 'Jordan', 'Graham'] AS minions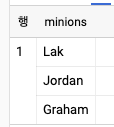
- 하지만 문제는 각 미니언을 앞서 생성한 날짜에 차례로 할당해야 한다. 그러려면 dayno 배열을 생성하고 모듈로 값을 minions 배열의 오프셋으로 사용할 수 있다.
WITH days AS (
SELECT
GENERATE_DATE_ARRAY('2019-06-23', '2019-08-22', INTERVAL 10 DAY) AS summer,
['Lak', 'Jordan', 'Graham'] AS minions
)
SELECT
summer[ORDINAL(dayno)] AS summer_day
, minions[OFFSET(MOD(dayno, ARRAY_LENGTH(minions)))] AS minion
FROM
days, UNNEST(GENERATE_ARRAY(1,ARRAY_LENGTH(summer),1)) dayno
ORDER BY summer_day ASC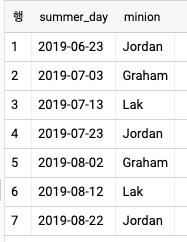
- 여기서 주목할 만한 것은 ORDINAL을 사용한 인덱싱은 1부터 시작하는 인덱스를 사용한 반면, OFFSET을 사용한 인덱싱은 0부터 시작하는 인덱스를 사용한다는 점이다. 또한 summer 배열의 길이를 얻기 위해 ARRAY_LENGTH를 사용했다.
- 배열 함수
- 배열이 2개일 때는 ARRAY_CONCAT 함수로 배열을 연결할 수 있다.
SELECT
ARRAY_CONCAT(
GENERATE_DATE_ARRAY('2019-03-23', '2019-06-22', INTERVAL 20 DAY)
, GENERATE_DATE_ARRAY('2019-08-23', '2019-11-22', INTERVAL 20 DAY)
) AS shoulder_season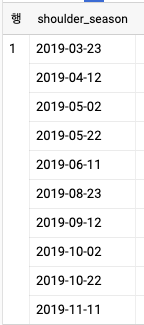
- 디버깅을 하다 보면 문자열 배열을 하나의 STRING 값으로 출력해야 할 때가 있다. 이때는 다음과 같이 ARRAY_TO_STRING 함수를 사용할 수 있다.
SELECT
ARRAY_TO_STRING(['A', 'B', NULL, 'D'], '*', 'na') AS arr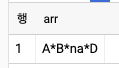
- ARRAY_TO_STRING 함수의 두 번째 파라미터는 문자열을 연결할 구분자이며, 세 번째 문자열은 NULL 요소가 기록되는 방식이다.
디버깅 목적으로 배열을 하나의 문자열로 출력하는 것은 도움이 될 수 있다. ARRAY_TO_STRING 함수는 STRING 타입의 배열만 처리하지만, TO_JSON_STRING 함수는 모든 타입의 배열을 처리 할 수 있다.
윈도우 함수
- 분석 윈도우 함수(분석 함수 또는 윈도우 함수)는 윈도우라고 부르는 행의 그룹에 대한 집계 분석(예를 들면 SUM, COUNT)을 계산한다. 분석 함수에는 집계 분석 함수, 탐색 함수, 번호 매기기 함수 등 세가지 종류가 있다.
- 집계 분석 함수
- 집계 함수는 전체 테이블에서 작동하며 단일 집계 값을 반환단다.
- 집계 분석 함수는 각 행에 대한 집계 통계를 반환한다. 여기서 집계는 결과가 계산되는 행의 '주변' 행에서 계산된다. 예를 들어 다음 쿼리는 특정 행으로부터 이전 100개 행까지의 대여 기록으로부터 대여 시간의 평균값을 계산한다.
SELECT
AVG(duration)
OVER(ORDER BY start_date ASC
ROWS BETWEEN 100 PRECEDING AND 1 PRECEDING) AS average_duration
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
LIMIT 5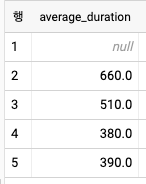
- 윈도우 자체는 특정 행 이전의 100개의 행으로 구성되며, 순서는 start_date 컬럼에 의해 지정된다. 이 쿼리는 각각의 행에 average_duration 컬럼을 생성하며, 가장 첫 번째 행은 이전 행이 없으므로 널 값을 가진다.
- 어느 특정 행의 이전 50개 행과 이후 50개 행의 평균 대여 시간을 계산하고 싶다면 다음 사항을 명시하면 된다.
ROWS BETWEEN 50 PRECEDING AND 50 FOLLOWING - 데이터셋의 첫 행부터 현재 행까지의 평균을 계산하려면 다음과 같이 지정하면 된다
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW - FOLLOWING을 생략하면, 윈도우 경계의 기본값이 현재 행으로 설정되므로 ROWS 50 PRECEDING은 ROWS BETWEEN 50 PRECEDING AND CURRENT ROW와 같은 표현이다.
- 탐색 함수
- 집계 분석 함수는 윈도우에 포함된 모든 행에 대한 집계 통계를 계산한다. 따라서 AVG(duration)는 윈도우 평균 대여 시간을 계산하고 MAX(duration)은 윈도우의 최대 대여 시간을 계산한다.
- 행의 위치를 나타내는 단일 값을 원한다는 탐색함수를 활용한다.
SELECT
start_date
, end_date
, LAST_VALUE(start_date)
OVER(PARTITION BY bike_id
ORDER BY start_date ASC
ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING) AS next_rental_start
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
LIMIT 5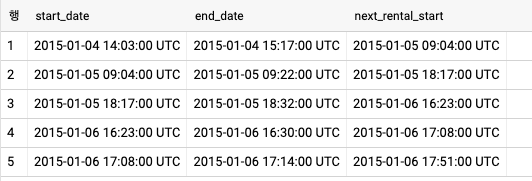
- 위의 쿼리에서 LEAD 함수를 사용하면 윈도우 프레임을 명시적으로 지정하지 않아도 된다.
SELECT
start_date
, end_date
, LEAD(start_date, 1)
OVER(PARTITION BY bike_id
ORDER BY start_date ASC) AS next_rental_start
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
LIMIT 5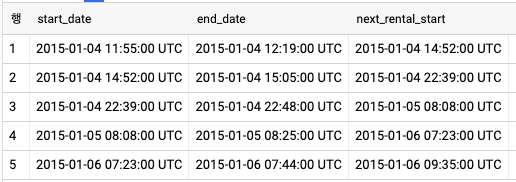
- 번호 매기기 함수
- 번호 매기기 함수는 윈도우의 행 정렬 방식에 따라 현재 행의 위치를 제공한다.
- 예를 들어 london_bicycles 데이터셋에서 각 데여소별로 대여 시간이 가장 긴 기록 5개를 찾는다고 가정할때, start_station_id 컬럼으로 파티션을 나눌 윈도우를 생성하고 윈도우 내부를 duration으로 정렬하면 각 대여의 순위를 계산해서 찾을 수 있다.
SELECT
start_station_id
, duration
, RANK()
OVER(PARTITION BY start_station_id ORDER BY duration DESC) AS nth_longest
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
LIMIT 5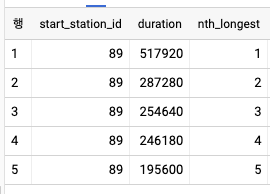
- 앞서 예제의 SELECT 절을 WITH 절에 배치하고 start_station_id 컬럼으로 그룹화한 후 ARRAY_AGG 함수를 사용하면 각 대여소에서 대여 시간이 긴 3개의 행을 얻을 수 있다.
WITH longest_trips AS (
SELECT
start_station_id
, duration
, RANK()
OVER(PARTITION BY start_station_id ORDER BY duration DESC) AS nth_longest
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
)
SELECT
start_station_id
, ARRAY_AGG(duration ORDER BY nth_longest LIMIT 3) AS durations
FROM
longest_trips
GROUP BY start_station_id
LIMIT 5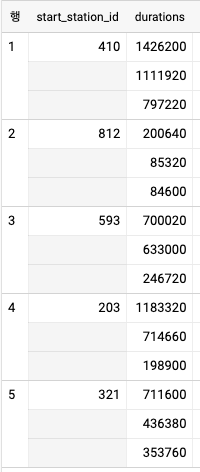
- RANK 함수는 순위가 중복되면 숫자를 건너뛰는 반면, DENSE_RANK 함수는 순위가 중복되어도 숫자를 연결해 할당하며, ROW_NUMBER 함수는 각 행마다 고유한 숫자를 할당한다.
테이블 메타 데이터
- 이전까지는 테이블에서 데이터를 쿼리하는 방법이다. 하지만 데이터에 대한 정보도 있는데 이를 메타데이터(metadata)라고 한다.
- 메타데이터에는 현재 테이블에 존재하는 컬럼, 테이블 생성 시기, 테이블 소유자, 접근할 수 있는 사람 등의 정보가 포함되어 있다.
- 쿼리를 동적으로 작성하기
- 데이터셋의 테이블에서 모든 컬럼 이름을 검색하려면 다음과 같은 쿼리를 활용 할 수 있다.
SELECT column_name
FROM `bigquery-public-data`.irs_990.INFORMATION_SCHEMA.COLUMNS
WHERE table_name = 'irs_990_2015'
- 모든 컬럼의 이름을 알아냈다면 CONCAT 함수를 사용해 필요한 쿼리 텍스트를 생성할 수 있다.
WITH columns AS (
SELECT column_name
FROM `bigquery-public-data`.irs_990.INFORMATION_SCHEMA.COLUMNS
WHERE table_name = 'irs_990_2015' AND column_name != 'ein'
)
SELECT CONCAT(
'SELECT ein, ARRAY_AGG(STRUCT(',
ARRAY_TO_STRING(ARRAY(SELECT column_name FROM columns), ',\n '),
'\n) FROM `bigquery-public-data`.irs_990.irs_990_2015\n',
'GROUP BY ein')
------ 위의 결과 값 ------
SELECT ein, ARRAY_AGG(STRUCT(elf,
tax_pd,
subseccd,
...
) FROM `bigquery-public-data`.irs_990.irs_990_2015
GROUP BY ein
--------------------------- 동적 SQL 기능이 제공한다면 단순히 쿼리 텍스트를 출력하는 것 이상의 작업이 가능하다.
- 레이블과 태그
- 앞에서 다룬 정보 스키마는 컬럼 이름 및 데이터 타입, 테이블 생성 시간 등 테이블에 대한 정보를 제공한다.
- 또한 레이블을 이용하면 자원을 생성한 애플리케이션, 자원을 소유한 팀, 자원을 사용하는 완경, 자원의 현재 수명 주기 단계 같은 사용자 지정 메타데이터를 지원에 추가할 수 있다.
- 각 레이블은 키와 값의 쌍이다. 특히 값이 지정되지 않은 레이블을 태그라고 하며 레이블과 유사하게 사용할 수 있다.
- 시간 여행
- 최대 7일 동안 테이블의 과거 상태를 조회할 수 있다.
- 예를 들어 6시간 전에 존재했던 테이블을 쿼리하려면 SYSTEM_TIME을 사용한다.
데이터 정의 언어와 데이터 조작 언어
- 데이터 정의 언어(DDL)는 테이블과 뷰를 생성, 변경, 삭제하기 위한 SQL 문이다. 데이터 조작 언어(DML)을 사용하면 테이블의 데이터를 갱신, 삽입, 삭제할 수 있다.
- 데이터 조작 언어
- 빅쿼리는 주로 데이터의 수정보다는 데이터를 로드하거나 스트리밍하는 데이터 웨어하우스다.
- 그러나 데이터를 수정하는 기능도 제공한다.
- 데이터 조작 언어(DML)을 사용하면 테이블에 데이터를 삽입, 갱선, 삭제 및 병합할 수 있다.
뒤에서 이어짐

데이터 분석하고 있습니다