
8장 고급 쿼리 (1)
재사용 가능한 쿼리
- 빅쿼리는 쿼리 및 쿼리의 일부를 재사용할 수 있는 많은 기능을 지원한다.
- 쿼리를 파라미터화하거나 공통적으로 사용ㅚ는 코드를 함수, 서브쿼리 또는 WITH 절로 추출할 수 있다.
파라미터화된 쿼리
- 파라미터화된 쿼리는 실행하는 시점에 값이 정해지는 파라미터를 사용하는 쿼리다. 이렇게 하면 런타임에 문자열로 쿼리를 생성할 필요 없이 여러 컨텍스트에서 동일한 쿼리를 재사용할 수 있다.
- 이름이 지정된 파라미터
query = """
SELECT
start_station_name
, AVG(duration) as avg_duration
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
WHERE
start_station_name LIKE CONCAT('%', @STATION, '%') -- 중요
AND duration BETWEEN @MIN_DURATION AND @MAX_DURATION
GROUP BY start_station_name
"""- 쿼리에서 사용하는 파라미터 이름은 @ 기호로 정의한다.
- Like 부분에서 '%@STATION%'로 작성하면 빅쿼리는 작음 따옴표를 보고 @기호를 하나의 문자로 처리한다. 따라서 @기호로 정의한 파라미터를 와일드 카드 % 기호를 포함하는 문자열과 결합시켜야 한다.
query_params = [
bigquery.ScalarQueryParameter(
"STATION", "STRING", station_name),
bigquery.ScalarQueryParameter(
"MIN_DURATION", "FLOAT64", min_duration),
bigquery.ScalarQueryParameter(
"MAX_DURATION", "FLOAT64", max_duration),
]
def print_query_results(client,
station_name,
min_duration=0,
max_duration=84000):
job_config = bigquery.QueryJobConfig()
job_config.query_parameters = query_params
query_job = client.query(
query,
location="EU",
job_config=job_config,
)
for row in query_job:
print("{}: \t{}".format(
row.start_station_name, row.avg_duration))
client = bigquery.Client()
print_query_results(client, 'Kennington', 300)
print_query_results(client, 'Hyde Park', 600, 6000)- 빅쿼리에서 파라미터를 사용하면 몇 가지 장점은 SQL 주입 공격에 대한 보안 및 예방이다.
- 이름이 지정된 타임스탬프 파라미터
- 앞서 샃펴본 쿼리의 경우, 쿼리 파라미터는 문자열과 부동소수점이다. 타임스탬프는 적절한 파이썬 데이터 형식으로 전달한다면 같은 방식으로 작동한다.
- 파이썬의 경우 datetime.datetime 타입을 사용한다.
from google.cloud import bigquery
from datetime import datetime
from datetime import timedelta
import pytz
def print_query_results(client, mid_time):
start_time = mid_time - timedelta(minutes=30)
end_time = mid_time + timedelta(minutes=30)
query = """
SELECT
AVG(duration) as avg_duration
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
WHERE
start_date BETWEEN @START_TIME AND @END_TIME
"""
query_params = [
bigquery.ScalarQueryParameter(
"START_TIME", "TIMESTAMP", start_time),
bigquery.ScalarQueryParameter(
"END_TIME", "TIMESTAMP", end_time),
]
job_config = bigquery.QueryJobConfig()
job_config.query_parameters = query_params
query_job = client.query(
query,
location="EU",
job_config=job_config,
)
for row in query_job:
print(row.avg_duration)
print("______________________")
# 아래의 쿼리는 특정 날을 표현하는 datetime 객체를 전달해 함수를 호출하는 과정이다.
client = bigquery.Client()
print_query_results(client, datetime(2021, 6, 12, 18, 38, tzinfo=pytz.UTC)- 위치가 지정된 파라미터
- 빅쿼리는 위치 기반 파라미터를 지원하지만, 쿼리와 호출 코드의 가독성 향상을 위해서라도 쿼리에 이름이 지정된 파라미터를 사용할 것을 강력히 추천한다.
- 위치 기반 파라미터를 사용하려면, ?를 사용해 파라미터를 지정하고 순서대로 파라미터 값을 전달하면 된다.
def print_query_results(client, params):
query = """
SELECT
start_station_name
, AVG(duration) as avg_duration
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
WHERE
start_station_name LIKE CONCAT('%', ?, '%')
AND duration BETWEEN ? AND ?
GROUP BY start_station_name
"""
query_params = [
bigquery.ScalarQueryParameter(
None, "STRING", params[0]),
bigquery.ScalarQueryParameter(
None, "FLOAT64", params[1]),
bigquery.ScalarQueryParameter(
None, "FLOAT64", params[2]),
]
job_config = bigquery.QueryJobConfig()
job_config.query_parameters = query_params
query_job = client.query(
query,
location="EU",
job_config=job_config,
)
for row in query_job:
print("{}: \t{}".format(
row.start_station_name, row.avg_duration))
print("______________________")
client = bigquery.Client()
print_query_results(client, ['Kennington', 300, 84000])
print_query_results(client, ['Hyde Park', 600, 6000])- 배열과 구조체 파라미터
- 지금까지의 예제는 스칼라 쿼리 파라미터를 사용했지만, 빅쿼리는 배열 파라미터도 지원한다.
query = """
SELECT
start_station_id
, COUNT(*) AS num_trips
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
WHERE
start_station_id IN UNNEST(@STATIONS) # 이부분 설정
AND duration BETWEEN @MIN_DURATION AND @MAX_DURATION
GROUP BY start_station_id
"""
query_params = [
bigquery.ArrayQueryParameter( # 이부분 Array 설정
'STATIONS', "INT64", ids),
bigquery.ScalarQueryParameter(
'MIN_DURATION', "FLOAT64", min_duration),
bigquery.ScalarQueryParameter(
'MAX_DURATION', "FLOAT64", max_duration),
]
# station 파라미터에 ID가 저장된 파이썬 배열을 전달
print_query_results(client, [270, 235, 62, 149], 300, 600)SQL 사용자 정의 함수
- 쿼리 전체를 파라미터화해서 재사용하는 방법보다 조금 더 세분화해서 쿼리를 재사용하는 방법도 있다. 예를 들어 SQL 쿼리가 수행하는 연산을 사용자 정의 함수(UDF)로 리팩토링해서 재사용할 수 있다.
- 요일별 야간 대여 횟수를 찾고 싶을땐, 날짜를 빈번하게 조작해야 하므로 이를 임시 SQL UDF로 정의하는 것이 편리하다.
CREATE TEMPORARY FUNCTION dayOfWeek(x TIMESTAMP) AS
(
['Sun','Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat']
[ORDINAL(EXTRACT(DAYOFWEEK FROM x))]
);
CREATE TEMPORARY FUNCTION getDate(x TIMESTAMP) AS
(
EXTRACT(DATE FROM x)
);
WITH overnight_trips AS (
SELECT
duration
, dayOfWeek(start_date) AS start_day
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
WHERE
getDate(start_date) != getDate(end_date)
)
SELECT
start_day
, COUNT(*) AS num_overnight_rentals
, AVG(duration)/3600 AS avg_duration_hours
FROM
overnight_trips
GROUP BY
start_day
ORDER BY num_overnight_rentals DESC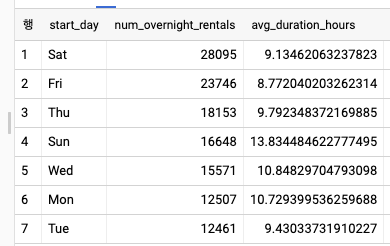
- 영구 UDF
-
이전 절의 함수는 임시 함수로 정의되었으므로 함수를 선언한 쿼리 내에서만 사용할 수 있다. 다른 쿼리에서 다시 사용하려면 함수를 복사해서 붙여넣어야 한다. 복사 후 붙여넣기는 본질적으로 오류가 발생하기 쉬운 작업이다.
-
함수를 여러 쿼리에서 재사용하고 싶다면 그 함수를 데이터셋에 저장하고 쿼리에서 참조하는 것이 바람직하다.
CREATE OR REPLACE FUNCTION ch08eu.dayOfWeek(x TIMESTAMP) AS
(
['Sun','Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat']
[ORDINAL(EXTRACT(DAYOFWEEK FROM x))]
);- 공개 UDF
- 특별한 빅쿼리의 능력을 근본적으로 확장하기 위해 AllAuthenticatedUsers 권한으로 공유한 데이터셋에 유용한 UDF를 정의할 수 있다. 예를 들어 빅쿼리에 AVG 함수가 있지만 MEDIAN 함수는 내장되어 있지 않다.
쿼리 일부 재사용하기
- 비정상적으로 긴 왕복 대여(평균 시간이 2배 이상인 대여)가 가장 많은 날을 찾으려고 할때, 쿼리에 세 단계가 필요하다.
- 왕복 대여를 찾는다.
- 런던의 자전거 대여소별 평균 왕복 대여 시간을 계산한다.
- 평균 대여 시간이 2배 이상인 대여 건을 찾는다.
- 상관 서브 쿼리
- 먼저 다음과 같이 '안에서 밖으로' 값을 전달하도록 필요한 쿼리르 작성한다.
SELECT
start_date,
COUNT(*) AS num_long_trips
FROM -- "첫 번째 FROM 절"
(SELECT
start_station_name
, duration
, EXTRACT(DATE FROM start_date) AS start_date
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
WHERE
start_station_name = end_station_name) AS roundtrips
WHERE -- "바깥쪽의 WHERE"
duration > 2*(
SELECT
AVG(duration) AS avg_duration
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
WHERE
start_station_name = end_station_name
AND roundtrips.start_station_name = start_station_name
)
GROUP BY start_date
ORDER BY num_long_trips DESC
LIMIT 5- WITH 절
- WITH 절을 사용하면 테이블 표현식을 재사용하고 쿼리를 더 읽기 쉽게 만들 수 있다. 앞서 작성한 쿼리를 2개의 WITH 절을 사용해 다시 작성한 부분이다.
WITH roundtrips AS (
SELECT
start_station_name
, duration
, EXTRACT(DATE FROM start_date) AS start_date
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
WHERE
start_station_name = end_station_name
),
station_avg AS (
SELECT
start_station_name
, AVG(duration) as avg_duration
FROM
roundtrips
GROUP BY start_station_name
)
SELECT
start_date,
COUNT(*) AS num_long_trips
FROM
roundtrips
JOIN station_avg USING(start_station_name)
WHERE duration > 2*avg_duration
GROUP BY start_date
ORDER BY num_long_trips DESC
LIMIT 5- WITH 절을 재사용하는 것은 가독성이 확보될 때만 주의해서 사용해야한다. 실제 데이터를 반드시 캐싱하거나 재사용할 필요는 없다.
- WITH 절은 쿼리 내에서만 재사용 할 수 있다. 여러 쿼리에서 결과 집합을 재사용하려면 중간 테이블을 사용하거나 구체화된 뷰를 만들 수 있다. 이 방법은 저장소 비용이 더 늘어나는 대신 연산이 더 빠르고 단순하게 되지만 실제로 추가 비용을 지급할 가치가 있는 성능 향상이 이루어지는지는 여러번 확인해야 한다.
- 특히 중간 테이블이 원본보다 큰 경우라면 WITH 절이 더 빠르다.
- 상수 정의하기
- WITH 절을 사용하면 상수를 정의하고 그 값을 한곳에서만 변경하도록 할 수 있다.
WITH params AS (
SELECT 600 AS DURATION_THRESH
)
SELECT
start_station_name
, COUNT(duration) AS num_trips
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
, params
WHERE duration >= DURATION_THRESH
GROUP BY start_station_name
ORDER BY num_trips DESC
LIMIT 5- 상수를 표현하는 또 다른 방법은 스크립팅 구문을 사용해 변수로 선언하는 것이다.(이후 등장)
뒤에서 이어짐

데이터 분석하고 있습니다