
✏️ 08. 앙상블 학습 : 보팅, 배깅
앙상블 학습
-
앙상블 학습을 통한 분류는 여러 개의 분류기(Classifier)를 생성하고 그 예측을 결합함으로써 보다 정확한 최종 예측을 도출하는 기법을 일컫는다.
-
복합적이고 어려운 문제의 결론을 내기 위해 각 분야 별 전문가들의 다양한 의견을 수렴하고 결정하듯이 앙상블 학습의 목표는 다양한 분류기의 예측 결과를 결합함으로써 단일 분류기보다 신뢰성이 높은 예측값을 얻는 것이다
앙상블의 유형
-
앙상블의 유형은
보팅(Voting),배깅(Bagging),부스팅(Boosting)으로 구분할 수 있으며 이외에스태킹(Stacking)등의 기법이 있다. -
대표적인 배깅 방식은 랜덤 포레스트 알고리즘이 있으며,
부스팅은 에이다 부스팅, 그라디언트 부스팅, XGBoost, LightGBM 등이 존재한다. -
정형 데이터의 분류나 회귀에서는 GBM 부스팅 계열의 앙상블이 전반적으로 높은 예측 성능을 나타낸다.
-
넓은 의미로는 서로 다른 모델을 결합한 것들을 앙상블로 지칭하기도 한다.
앙상블의 특징
-
단일 모델의 약점을 다수의 모델들을 결합하여 보완
-
뛰어난 성능을 가진 모델들로만 구성하는 것보다 성능이 떨어지더라도 서로 다른 유형의 모델을 섞는 것이 오히려 전체 성능에 도움이 됨
-
랜덤 포레스트 및 뛰어난 부스팅 알고리즘들은 모두 결정 트리 알고리즘을 기반 알고리즘으로 적용함
-
결정 트리의 단점인 과적합(오버피팅)을 수십~수천개의 많은 분류기를 결합해 보완하고
장점인 직관적인 분류 기준은 강화됨
보팅(Voting), 배깅(Bagging)
-
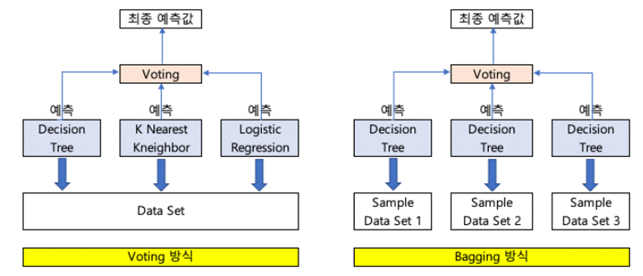
보팅과 배깅은 여러 개의 분류기가 투표를 통해 최종 예측 결과를 결정하는 방식
-
보팅과 배깅의 차이
-
보팅은 서로 다른 알고리즘을 가진 분류기를 결합
-
배깅은 같은 알고리즘을 가진 분류기를 결합하지만
데이터 샘플링을 서로 다르게 수행하면서 학습을 수행해 보팅을 수행
-
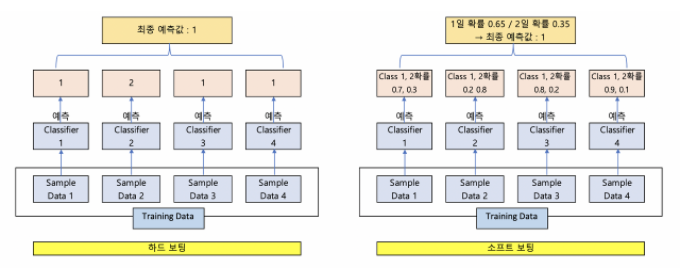
Hard Voting, Soft Voting
-
Hard Voting은 다수의 Classifier 간 다수결로 최종 class 결정
-
Soft Voting은 다수의 Classifier 들의 class 확률을 평균하여 결정
일반적으로 많이 사용된다.
배깅(Bagging) - 랜덤 포레스트(RandomForest)
-
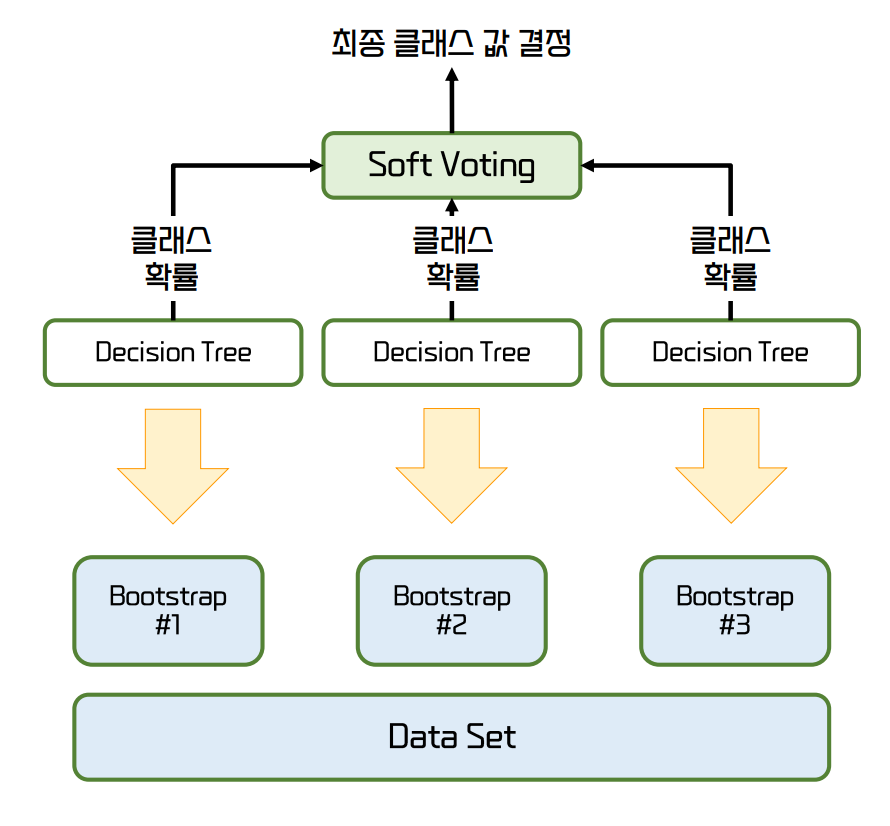
Bagging은 Bootstrap Sampling의 줄임말
-
Bootstrap이란 기존 학습 데이터 세트로 부터 랜덤하게 복원추출 하여 동일한 사이즈의 데이터 세트를 여러 개 만드는 것을 의미한다.
-
배깅의 대표적인 알고리즘은 랜덤 포레스트
-
랜덤 포레스트는 여러 개의 결정 트리 분류기가 전체 데이터에서 배깅 방식으로 각자의 데이터를 샘플링해 개별적으로 학습을 수행한 뒤 최종적으로 모든 분류기가 보팅을 통해 예측 결정을 한다.
-
Bootstrap을 통해 데이터를 Random하게, Tree를 모아 놓은 구조이기 때문에 숲(Forest)이 붙어 RandomForest가 되었다.
랜덤 포레스트 주요 하이퍼 파라미터
-
n_estimators: 랜덤 포레스트에서 결정 트리의 개수를 지정. 기본은 100개-
많이 설정할수록 좋은 성능을 기대할 수 있지만 무조건 향상 되는 것은 아미
-
트리의 개수가 많아질수록 학습 수행 시간이 오래 걸리는 것도 감안해야 한다.
-
-
max_features: 결정 트리에 사용된max_features파라미터와 같다.-
기본
max_features는 ‘auto’ 로서 ‘sqrt’를 사용한다. -
랜덤 포레스트의 트리를 분할하는 피처를 참조할 때 전체 피처가 아니라 sqrt(전체 피처 개수)만큼 참조한다.
-
-
max_depth나min_samples_leaf와 같이 결정 트리에서 과적합을 개선하기 위해 사용되는 파라미터가 랜덤 포레스트에도 똑같이 적용될 수 있다
📌 참고 문헌
-
책
- 📕 파이썬 머신러닝 완벽 가이드 / 권철민
-
참조 자료
-
해당 챕터의 실습 및 예제 코드는 아래 링크의 Machine Learning 참조 해주시면 됩니다.
