
✏️ 09. 앙상블 학습 : 부스팅
앙상블 학습
-
앙상블 학습을 통한 분류는 여러 개의 분류기(Classifier)를 생성하고 그 예측을 결합함으로써 보다 정확한 최종 예측을 도출하는 기법을 일컫는다.
-
복합적이고 어려운 문제의 결론을 내기 위해 각 분야 별 전문가들의 다양한 의견을 수렴하고 결정하듯이 앙상블 학습의 목표는 다양한 분류기의 예측 결과를 결합함으로써 단일 분류기보다 신뢰성이 높은 예측값을 얻는 것이다
앙상블의 유형
-
앙상블의 유형은
보팅(Voting),배깅(Bagging),부스팅(Boosting)으로 구분할 수 있으며 이외에스태킹(Stacking)등의 기법이 있다. -
대표적인 배깅 방식은 랜덤 포레스트 알고리즘이 있으며,
부스팅은 에이다 부스팅, 그라디언트 부스팅, XGBoost, LightGBM 등이 존재한다. -
정형 데이터의 분류나 회귀에서는 GBM 부스팅 계열의 앙상블이 전반적으로 높은 예측 성능을 나타낸다.
-
넓은 의미로는 서로 다른 모델을 결합한 것들을 앙상블로 지칭하기도 한다.
앙상블의 특징
-
단일 모델의 약점을 다수의 모델들을 결합하여 보완
-
뛰어난 성능을 가진 모델들로만 구성하는 것보다 성능이 떨어지더라도 서로 다른 유형의 모델을 섞는 것이 오히려 전체 성능에 도움이 됨
-
랜덤 포레스트 및 뛰어난 부스팅 알고리즘들은 모두 결정 트리 알고리즘을 기반 알고리즘으로 적용함
-
결정 트리의 단점인 과적합(오버피팅)을 수십~수천개의 많은 분류기를 결합해 보완하고
장점인 직관적인 분류 기준은 강화됨
부스팅(Boosting)
-
부스팅 알고리즘은 여러 개의 약한 학습기(Weak Learner)를 순차적으로 학습 - 예측한 데이터나
학습 트리에 가중치 부여를 통해 오류를 개선해 나가면서 학습하는 방식 -
부스팅의 대표적인 구현은
AdaBoost(Adaptive Boosting)과그라디언트 부스트가 있음
에이다 부스팅의 학습/예측 프로세스
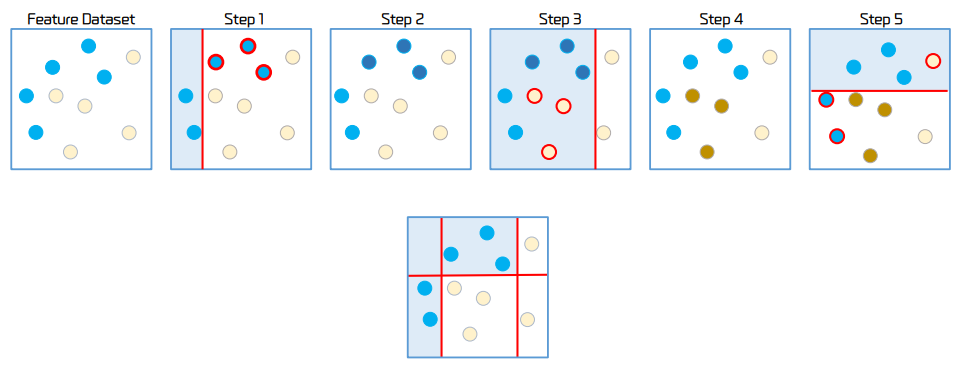
-
Step 1: 첫 번째 분류 기준에서 2개의 동그라미는 잘 예측 했으나, 3개의 동그라미는 잘 예측하지 못함
-
Step 2: 잘못 예측된 3개의 파란색 동그라미에 가중치를 부여. 중요한 값이라고 알려줌
- 근데 그러다 보니 또다시 노란색 데이터에서는 오류가 발생함.
따라서 이전과 마찬가지로 노란색 데이터를 잘 분류할 수 있도록 가중치를 부여
- 근데 그러다 보니 또다시 노란색 데이터에서는 오류가 발생함.
-
Step 3: 그 다음 학습기에서는 이전 단계에서 잘못 분류된 데이터를 맞추려고 노력함
-
Step 4: 노란색 데이터에 가중치가 부여됨
-
Step 5: 가중치가 부여된 노란색 원을 분류하기 위한 분류 기준이 만들어짐
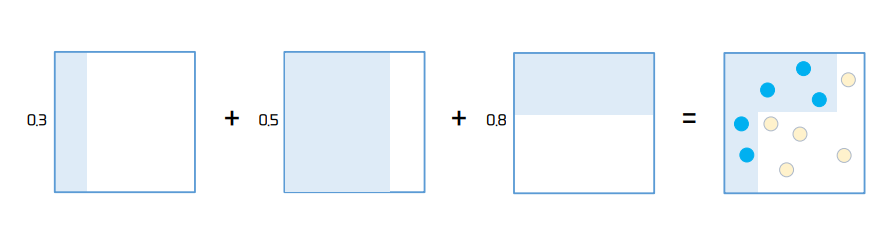
- Step 1, Step 3, Step 5 즉, 분류기준 1, 2, 3에 의해 결과물이 도출 된다.
GBM(Gradient Boost Machine) 개요
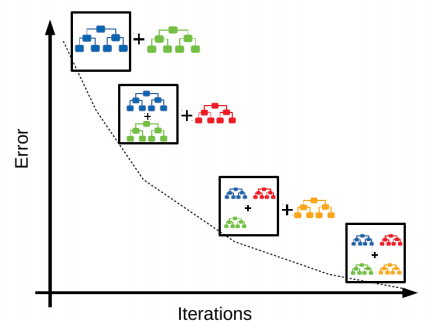
-
GBM도 AdaBoost와 유사하나, 가중치 업데이터를 경사 하강법을 이용한다.
-
feature(x)를 입력했을 때 모델의 예측 함수를 F(x), 실제 타깃값을 y라고 한다면 오류식 h(x) = y – F(x)가 된다.
이 h(x)를 최소화 하는 방향성을 가지고 반복적으로 가중치 값을 갱신하는 것이 경사하강법이다. -
경사 하강법은 반복 수행을 통해 오류를 최소화 할 수 있도록 가중치의 업데이트 값을 도출하는 기법으로서 머신러닝에서 매우 중요한 기법 중 하나이다
사이킷런 GBM 주요 하이퍼 파라미터 및 튜닝
-
loss: 경사 하강법에서 사용할 손실 함수 지정. 기본은 deviance -
learning_rate: GBM이 학습을 진행할 때 마다 적용하는 학습률. Weak Learner가 순차적으로 오류 값을 보정해 나가는데 적용하는 계수로서, 0 ~ 1 사이의 값을 지정한다.-
너무 작은 값을 적용하면 업데이트 되는 값이 작아져서 최소 오류 값을 찾아 예측 성능이 높아질 가능성이 높으나, 많은 Weak Learner는 순차적인 반복이 필요해서 수행 시간이 오래 걸리고, 또 너무 작게 설정하면 모든 Weak Learner의 반복이 완료되어도 최소 오류 값을 찾지 못할 가능성이 생긴다.
-
반대로 너무 큰 값을 적용하면 최소 오류 값을 찾지 못하고 그냥 지나쳐 버려 예측 성능이 떨어질 가능성이 높아지지만 빠른 수행이 가능하다.
-
-
n_estimators: Weak Learner의 개수.- Weak Learner가 순차적으로 오류를 보정하므로 개수가 많을 때는 예측 성능이 일정 수준까지는 좋아질 수는 있으나 개수가 많을수록 수행 시간이 오래 걸린다. 기본값은 100
-
subsample: Weak Learner가 학습에 사용하는 데이터의 샘플링 비율로서 기본값은 1이다.- 기본적으로 전체 학습 데이터를 기반으로 학습하는데, 과적합이 염려되는 경우 subsample을 1보다 작은 값으로 설정하면 된다.
XGBoost(eXtra Gradient Boost) 개요
-
주요 장점
-
뛰어난 예측 성능
-
GBM 대비 빠른 수행 시간. CPU 병렬 처리, GPU 지원
-
다양한 성능 향상 기능
-
규제(Regularization) 기능 탑재
-
Tree Pruning (가지치기)
-
다양한 편의 기능
-
조기 중단(Early Stopping)
-
자체 내장된 교차 검증
-
결손값 자체 저리
-
XGBoost 조기 중단 기능(Early Stopping)
-
XGBoost는 특정 반복 횟수 만큼 더 이상 손실함수가 감소하지 않으면 지정된 반복횟수를 다 완료하지 않고 수행을 종료할 수 있다.
-
학습을 위한 시간을 단축시킨다. 특히 최적화 튜닝 단계에서 적절하게 사용이 가능하다.
-
너무 반복 횟수를 단축할 경우 예측 성능 최적화가 안된 상태에서 학습이 종료될 수 있으므로 유의해야 한다.
-
조기중단 설정 파라미터
-
early_stopping_rounds: 더 이상 손실 평가 지표가 감소하지 않는 최대 반복 횟수 -
eval_metric: 반복 수행 시 사용하는 비용 평가 지표 -
eval_set: 평가를 수행하는 별도의 검증 데이터 세트 설정. 일반적으로 검증 데이터 세트에서 반복적으로 손실 감소 성능을 평가
-
XGboost Python Wrapper 와 Scikit Learn Wrapper 하이퍼 파라미터 비교
| 항목 | 파이썬 Wrapper | 사이킷런 Wrapper |
|---|---|---|
| 사용 모듈 | from xgboost as xgb | from xgboost import XGBClassifier |
| 학습용과 테스트용 데이터 세트 | DMatrix 객체를 별도 생성 train = xgb.DMatrix(data=X_train, label=y_train) DMatrix 생성자로 피처 데이터 세트와 레이블 데이터 세트를 입력 | Numpy 또는 Pandas 사용 |
| 학습 API | xgb_model = xgb.train() xgb_model은 학습된 객체를 반환 받음 | XGBClassifier.fit() |
| 예측 API | xgb.train()으로 학습된 객체에서 predict() 호출. 즉, xgb_model.predict() 이때 반환 결과는 예측 결과가 아닌 예측 결과를 추정하는 확률값 | XGBClassifier.predict() 예측 결과값 반환 |
| 피처 중요도 시각화 | plot_importance() 함수 이용 | plot_importance() 함수 이용 |
| 파이썬 Wrapper | 사이킷런 Wrapper | 하이퍼 파라미터 설명 |
|---|---|---|
| eta | learning_rate | GBM의 학습률과 같은 파라미터. 파이썬 래퍼 기반의 xgboost를 사용할 때의 기본값은 0.3, 사이킷런 래퍼 클래스를 사용할 때는 0.1 |
| num_boost_rounds | n_estimators | 사이킷런 앙상블의 n_estimators와 동일. 약한 학습기의 개수(반복 수행 횟수) |
| min_child_weight | min_child_weight | 결정트리의 min_child_leaf와 유사 |
| max_depth | max_depth | 결정트리의 max_depth와 동일. 트리의 최대 깊이 |
| sub_sample | subsample | GBM의 subsample과 동일. 트리가 커져서 과적합 되는 것을 방지하기 위해 데이터를 샘플링할 비율을 지정. 일반적으로 0.5 ~ 1 사이의 값을 사용 |
| lambda | reg_lambda | L2 규제(regularization) 적용 값. 기본값은 1로서 값이 클 수록 규제 값이 커진다. 과적합 제어 |
| alpha | reg_alpha | L1 규제(regularization) 적용 값. 기본값은 0으로서 값이 클 수록 규제 값이 커진다. 과적합 제어 |
| colsample_bytree | colsample_bytree | GBM의 max_features와 유사함. 트리 생성에 필요한 피처를 임의로 샘플링 하는 데 사용된다. 매우 많은 피처가 있는 경우 과적합을 조정하는 데 적용한다. |
| scale_pos_weight | scale_pos_weight | 특정 값으로 치우친 비대칭한 클래스로 구성된 데이터 세트의 균형을 유지하기 위한 파라미터. 기본값은 1 |
| gamma | gamma | 트리의 리프 노드를 추가적으로 나눌지를 결정하는 최소 손실 감소 값. 해당 값보다 큰 손실이 감소된 경우에 리프 노드를 분리. 값이 커질수록 과적합 감소 효과가 있음. |
LightGBM 개요
-
XGBoost 대비 장점
-
더 빠른 학습과 예측 수행 시간
-
더 작은 메모리 사용량
-
카테고리 피처의 자동 변환과 최적 분할(One Hot Encoding)을 사용하지 않고도 카테고리형 피처를 최적으로 변환하고 이에 따른 분할 노드 수행)
-
LightGBM 작동 방식
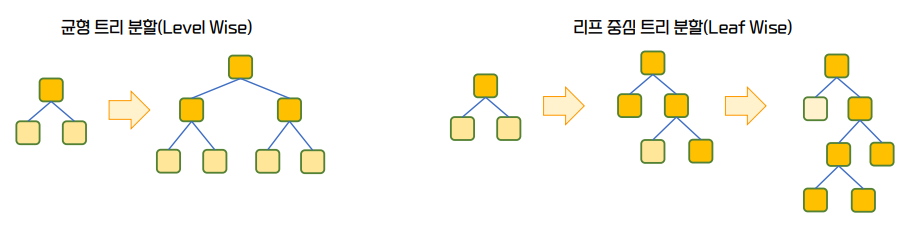
-
균형 트리 분할(Lavel Wise)
- XGBoost를 포함한 일반적인 GBM 방식. 균형잡힌 트리를 만들어 Depth를 최소화 할 수 있다. 한쪽으로만 트리가 뻗어 나가게 되면 과대적합 될 수 있다! 라는 것이 이론적 근거가 있다.
-
리프 중심 트리 분할(Leaf Wise)
- 한쪽 방향으로 예측을 했을 때 예측 오류를 줄여줄 수 있으면 그 노드
쪽으로 계속 리프 노드를 생성하면 조금 더 정확하겠다고 판단
- 한쪽 방향으로 예측을 했을 때 예측 오류를 줄여줄 수 있으면 그 노드
LightGBM Python Wrapper 와 Scikit Learn Wrapper 하이퍼 파라미터 비교
| 파이썬 Wrapper | 사이킷런 Wrapper | 하이퍼 파라미터 설명 |
|---|---|---|
| num_iterations | num_eatimators | 약한 학습기의 개수(반복 수행 회수 |
| learning_rate | learning_rate | 학습률(learning rate). 0 에서 1 사이의 값을 지정하며 부스팅 스텝을 반복적으로 수행할 때 업데이트 되는 학습률 값 |
| max_depth | max_depth | 결정트리의 max_depth와 동일. 트리의 최대 깊이 |
| min_data_in_leaf | min_child_samples | 리프 노드가 될 수 있는 최소 데이터 건수(Sample 수) |
| bagging_fraction | subsample | 트리가 커져서 과적합되는 것을 제엏가ㅣ 위해 데이터를 샘플링 하는 비율을 지정. sub_sample=0.5로 지정하면 전체 데이터의 절반을 트리를 생성하는데 사용한다 |
| feature_fraction | colsample_bytree | GBM의 max_features와 유사하다. 트리 생성에 필요한 피처를 임의로 샘플링하는데 사용된다. 매우 많은 피처가 있는 경우 과적합을 조정하는데 적용한다. |
| lambda | reg_lambda | L2 규제(regularization) 적용 값. 기본값은 1로서 값이 클 수록 규제 값이 커진다. 과적합 제어 |
| alpha | reg_alpha | L1 규제(regularization) 적용 값. 기본값은 0으로서 값이 클 수록 규제 값이 커진다. 과적합 제어 |
| early_stopping_round | early_stopping_rounds | ds 학습 조기 종료를 위한 early stopping interval 값 |
| num_leaves | num_leaves | 최대 리프 노드 개수 |
| min_sum_hessian_in_leaf | min_child_weight | t 결정트리의 min_child_leaf와 유사. 과적합 조절용 |
num_leaves의 개수를 중심으로min_child_samples(min_data_in_leaf),max_depth를 함께 조정하면서 모델의 복잡도를 줄이는 것이 기본 튜닝 방안
📌 참고 문헌
-
책
- 📕 파이썬 머신러닝 완벽 가이드 / 권철민
-
참조 자료
-
해당 챕터의 실습 및 예제 코드는 아래 링크의 Machine Learning 참조 해주시면 됩니다.
