벡터 미분에서, 일반적인 분자중심표현이 아닌 분모중심표현으로 작성하였다. 혼동에 주의바란다.
Newton's method (Newton-Raphson method)
f(x) = 0을 만족하는 x 값을 찾는 것을 목적으로 하고 있다. 일반적으로 비선형 방정식의 해를 찾기 위해 사용된다.
대수학적으로 바로 구하면 안되냐 싶을 수 있지만, 확률 변수 x에 대한 f(x) 함수가 현실 세계의 함수라고 생각하면 이는 노이즈가 가득하고, 특정 시점의 데이터만 얻을 수 있다. 따라서 특정 데이터만 갖고 비선형 함수 f(x) = 0을 만족하는 x를 찾으려고 한다.
예제
- 로봇의 위치 x와 환경의 지도(point cloud) M의 위치 추정
- z는 센서의 측정 값, h(x, mi)는 x와 지도 상의 위치 mi까지의 예상 측정 값
x∗,m∗=x,margmini=1∑n∣∣zi−h(x,mi)∣∣2
뉴턴법을 설명하는 방식은 2가지가 있다. 기울기를 이용한 방식과, 테일러 급수를 이용한 방식이다.
각각 살펴보고자 한다.
기울기를 이용한 설명 방식
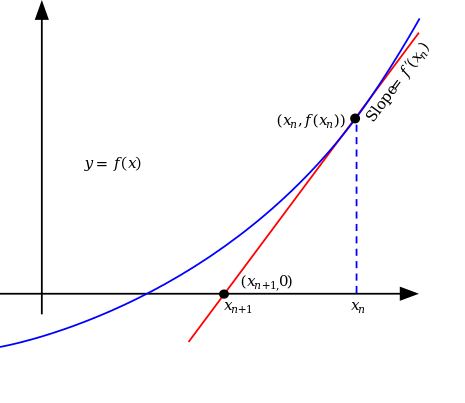
뉴턴법은 초기 값에서부터 접선으로 근사화 하고 이 접선의 x 절편(y=0)을 계산하는 것이다.
이를 반복하면 점점 f(x) 값이 0에 가까워진다.
f′(xn)=xn−xn+1f(xn)−0
초기 값에서부터 x절편으로의 접선의 기울기 공식을 쓰면 위와 같다. y′=ΔxΔy
여기서 xn+1이 1회 진행했을 때, f(x)=0에 (n)번째에 비해서 가까운 (n+1)번째 x값을 알 수 있는 것이다.
위의 식을 정리하면 아래와 같이 정리가 된다.
xn+1=xn−f′(xn)f(xn)
이를 반복하면 f(x) = 0에 가까워진다. 이해가 안되면 아래 움짤을 보면 이해가 될 것이다.
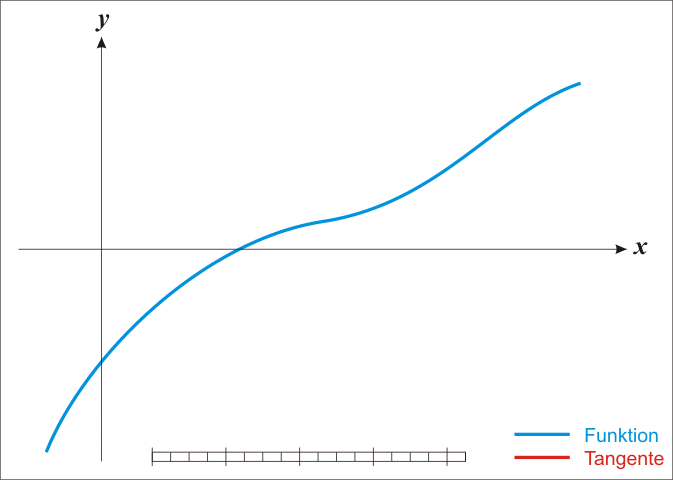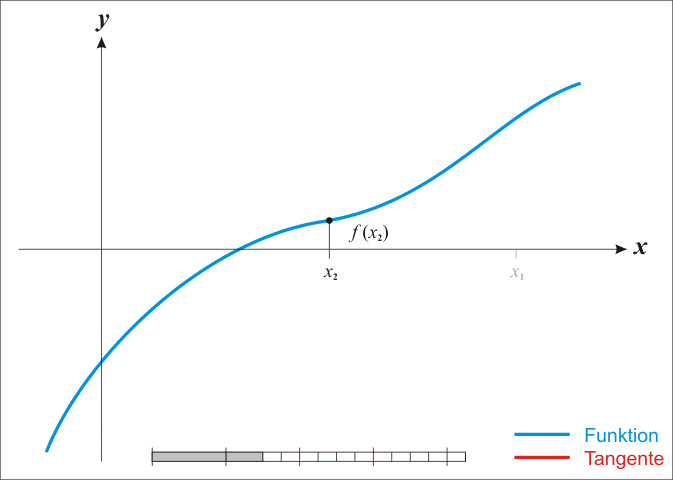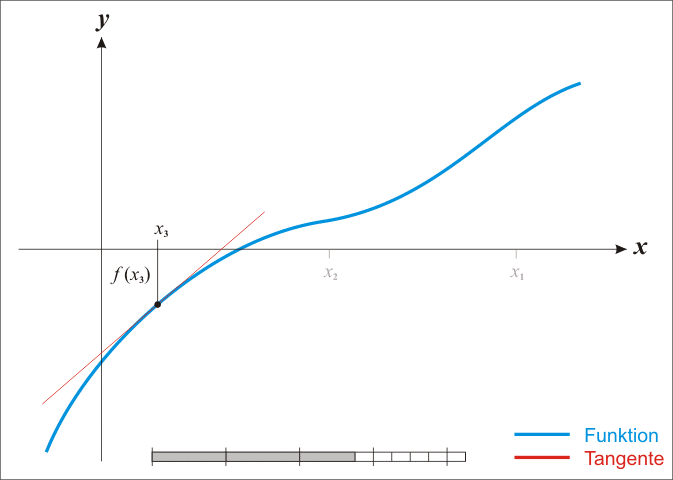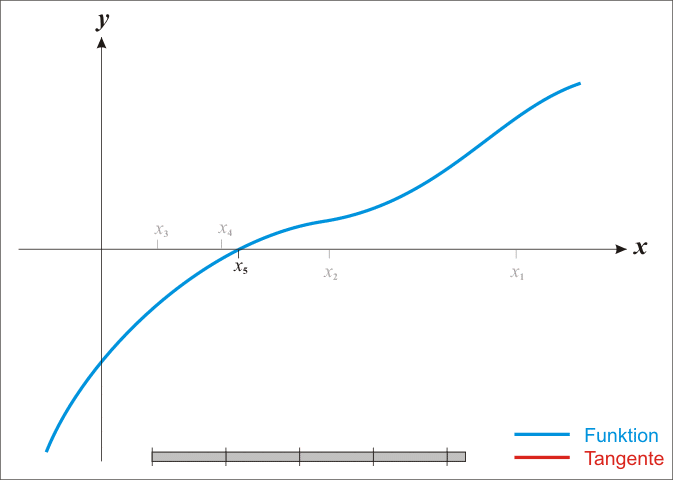
테일러 급수를 이용한 설명 방식
f(x)≈f(xn)+f′(xn)(x−xn)+2!f′′(xn)(x−xn)2+...
xn 부근에서 테일러 급수로 f(x)를 근사시켰다.
f(x)를 1차항까지로 고려하면 다음과 같다.
f(x)≈f(xn)+f′(xn)(x−xn)
그리고 f(x) = 0으로 x 절편의 값을 찾으려고 하기 때문에 다음과 같다.
0=f(xn)+f′(xn)(xn+1−xn)
이 식을 정리하면 결국 기울기 접근 방법과 같은 식이 나온다.
xn+1=xn−f′(xn)f(xn)
최적화 문제에서의 뉴턴법
주로 최적화 문제는 E=e2로 2차식에서의 최적점을 찾으려고 한다. (L2 loss, e는 error)
에러의 제곱에서 최적점을 찾으려고 하는 이유는 cost function이 볼록성(convexity)을 지켜야 되기 때문이다. (L1 loss를 써도 됨)
여기서는 L2 loss를 가정한다.
error의 제곱이 0이 되게끔 하려고한다.
먼저 E를 2차 테일러 급수로 근사화한다. (분모중심표현)
E(x+Δx)≈E(x)+E′(x)TΔx+2!1ΔxTE′′(x)Δx
테일러 급수를 이용한 설명 방식과 마찬가지로 E의 미분 값이 0이 되게 한다.
E′(x+Δx)=E′(x)+2!1(E′′(x)+E′′(x)T)Δx=E′(x)+E′′(x)Δx=0
L2 loss의 2차 미분은 symmetric matrix이기 때문에 2번째 항에서 3번째 항은 똑같다.
xn+1=xn−E′′(xn)−1E′(xn)
이렇게 하면 결국 뉴턴법의 식과 유사한 형태가 된다.
여기서 E'은 자코비안(Jacobian), E''은 헤시안(Hessian) 행렬이라고 부른다.
(정확히는 분자중심 표현에서의 E'이 자코비안이므로, 현재 분모중심표현에서는 E′T가 자코비안이다.)
그런데 뉴턴법은 연산이 느리다는 문제가 있다. 그 이유는 헤시안 행렬 때문이다.
2차 미분을 진행하기 때문인데, 단순한 함수면 2차 미분이 얼마 안걸릴지 몰라도 E가 여러 함수로 결합되어있다면 chain rule에 의해서 많은 연산이 필요하다.
따라서 가우스-뉴턴법으로 유사 헤시안 행렬을 구하여 해결한다.
가우스 뉴턴법(Gauss-Newton method)
앞서 얘기했듯이 가우스-뉴턴법은 비선형 최소 제곱 문제를 해결하기 위해 뉴턴법의 변형된 형태로, 비선형 함수의 최소 제곱 문제를 선형화하여 근사적으로 해결하는 방법이다.
뉴턴법에서는 L2 loss, E를 테일러 급수로 근사화하였다면, 가우스 뉴턴법은 error, e를 테일러 급수로 근사한다. ( E=e2 )
e를 테일러 급수로 1차 근사해보자. (분모중심표현)
e(x+Δx)≈e(x)+e′(x)TΔx
그리고 원래 cost function E를 테일러 급수로 1차 근사한 r로 구성한다.
E(x+Δx)≈e(x+Δx)Te(x+Δx)=(e(x)+e′(x)TΔx)T(e(x)+e′(x)TΔx)=(e(x)T+ΔxTe′(x))(e(x)+e′(x)TΔx)=e(x)Te(x)+e(x)e′(x)TΔx+ΔxTe′(x)e(x)+ΔxTe′(x)e′(x)TΔx
테일러 근사를 한 e로 이루어진 E를 Δx로 미분하고, L2 loss가 0에 가까운 것을 원하므로 기울기 값이 0이 되게 한다. (뉴턴법)
E′(x+Δx)=2e′(x)e(x)+2e′(x)e′(x)TΔx=0
위의 식을 아래처럼 다시 정리한다.
Δx=xn+1−xn=−(e′(x)e′(x)T)−1(e′(x)e(x))
그럼 e′(x)e′(x)T 는 뉴턴법에서의 헤시안 행렬(E'')과 유사하게 나온다. 즉, 유사 헤시안 행렬이 되면서 2차 미분이 없이 자코비안만으로 계산하므로 연산이 빨라진다.
주의 : e은 error이라고 했다.
따라서 e=f(x)−y라고 볼 수 있으므로 e′=f′(x)이고 아래와 같이 정리된다.
E′(x+Δx)=2f′(x)(y−f(x))+2f′(x)f′(x)TΔx=0Δx=−(f′(x)f′(x)T)−1(f′(x)(y−f(x)))=−(f′(x)f′(x)T)(f′(x)e)wheree=f(x)−y
e는 residual이라고도 불린다.
Marginal Covariance (Uncertainty of the estimated values)
이렇게 추정한 estimation의 불확실성을 측정할 수 있다.
cost function : E(x)=r(x)2 where r(x)=f(x)−z
최적화가 완료 된 경우 다음과 같이 쓸 수 있다.
r(x)≈r(x∗)+Jδx
where x∗ is optimial point
따라서 우리는 다음과 같이 가정할 수 있다.
r(x∗)=0, 왜냐하면 x∗는 optimial point이기 때문에 최적점이기에 error가 없다고 생각할 수 있기 때문이다.
따라서 r(x) ~ N(0,∑r)으로 가우시안 분포 형태라고 확장 시킬 수 있다.
r(x∗)=0 이기에 r≈Jδx 이다.
그럼 error function의 불확실성(covariance)는 다음과 같이 구할 수 있다.
∑r=rrT=(Jδx)(Jδx)T=JδxδxTJT=J(δxδxT)JT=J∑xJT
여기서 ∑r은 error에 대한 공분산이고, 우리가 원하는 것은 추정된 값의 공분산(∑x)이다.
∑x=J−1∑rJ−T=(JT∑r−1J)−1
이렇게 추정된 값에 대한 공분산을 구할 수 있게 된다.
이를 marginal covariance라고 부른다.
다른 말로는 Backward propagation of covariance라고도 부르는데 오차의 크기와 전파를 다룰 때 자주 쓰는 도구다.
backward propagation이라고 이름이 붙은 이유는 forward가 pose(관심 변수) to 측정인 것이고, 반대로 측정으로부터 pose(관심 변수)로 backward로 전달되기 때문이다.
Reference
https://en.wikipedia.org/wiki/Newton%27s_method
