Optimization
1.베이지안 확률론

확률(probability)은 모든 일어날 수 있는 경우의 수 가운데 어떤 일이 일어날 가능성, 즉 범위가 \[0,1]이다.확률 분포(Probability Distribution)는 모든 가능한 결과들과 각 결과에 대응하는 확률을 나타내는 함수이다.정리하면 확률은 단일
2024년 6월 1일
2.Iterative Optimization(점진적 최적화)
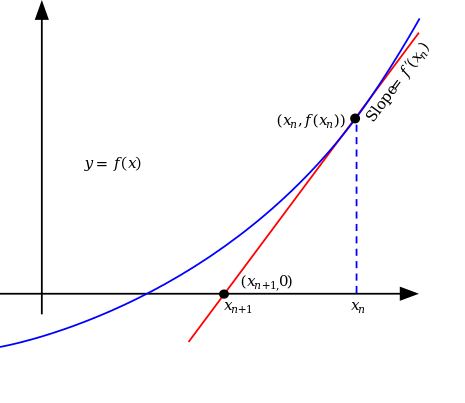
Newton's Method f(x) = 0을 만족하는 x 값을 찾는 것을 목적으로 하고 있다.
2024년 6월 2일
3.Lie Theory(리 이론, 회전의 최적화) - Basic in SO(n)
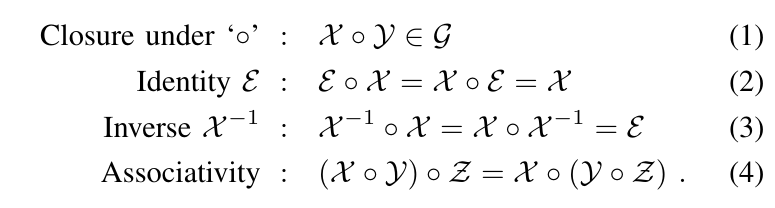
최적화는 여러 방법을 통해서 $\\Delta\\theta$를 구해서 기존 $\\theta$에 업데이트 해주는 방법이다.그렇지만 회전의 경우 제약 조건이 존재한다. $det(R)=1$, $RR^T=R^TR=I$ 다음과 같이 determinant가 1인 직교 행렬이어야 한
2024년 6월 20일
4.딥러닝에서의 Bayes rule (loss function)

딥러닝 loss에 대해서 증명을 할 때 일반적으로 Bayes rule을 이용해서 증명을 한다.하지만 나는 왜 딥러닝의 결과물은 input에 대해서 단일 값인데 어떻게 확률론 혹은 Bayes rule로 설명하는지 이해가 되지 않았다.이에 대해서 이해한 부분을 작성하려고
2025년 3월 11일